A Multiscale Network with Supervised Contrastive Learning for Real-Time Facial Emotion Recognition
Pith reviewed 2026-06-28 17:06 UTC · model grok-4.3
The pith
A multiscale network with supervised contrastive learning models continuous changes in facial expressions for real-time video emotion recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present a deep learning-based system that detects emotional changes in real-time video of a person by modeling the change in facial expressions. The current study is conducted on a standard dataset for training of the deep learning system and the system has provided very satisfactory outcomes in this respect.
What carries the argument
Multiscale network combined with supervised contrastive learning that captures continuous, individual-specific shifts in facial expressions over video frames.
Load-bearing premise
Performance on one standard dataset will generalize to the continuous, individual-specific variations in facial expressions that occur in real counseling or video scenarios.
What would settle it
A test on new video sequences from unseen individuals or actual counseling sessions that shows accuracy dropping substantially below the level reported on the standard training dataset.
Figures


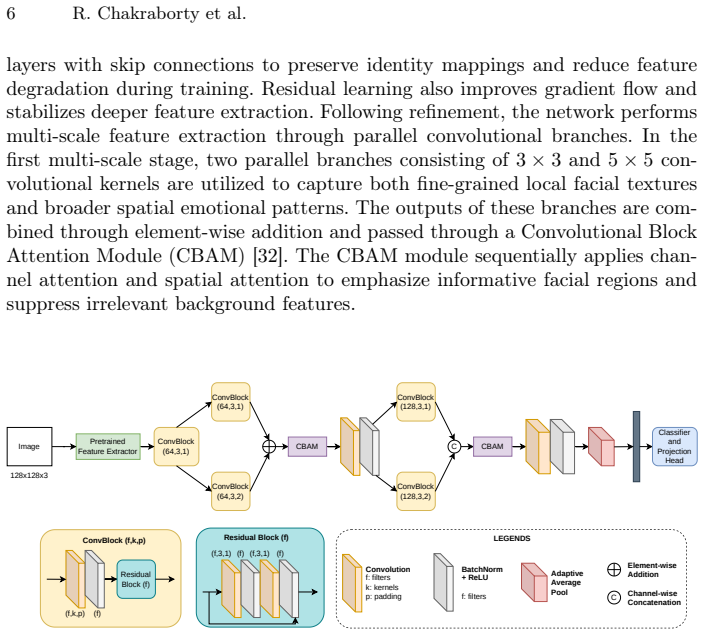
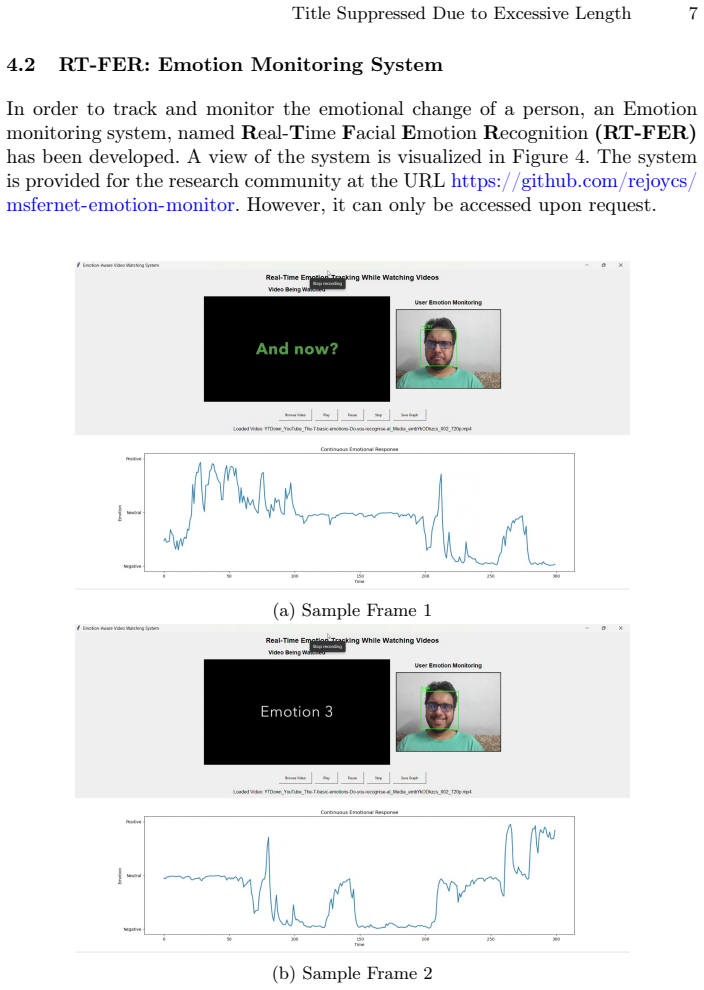
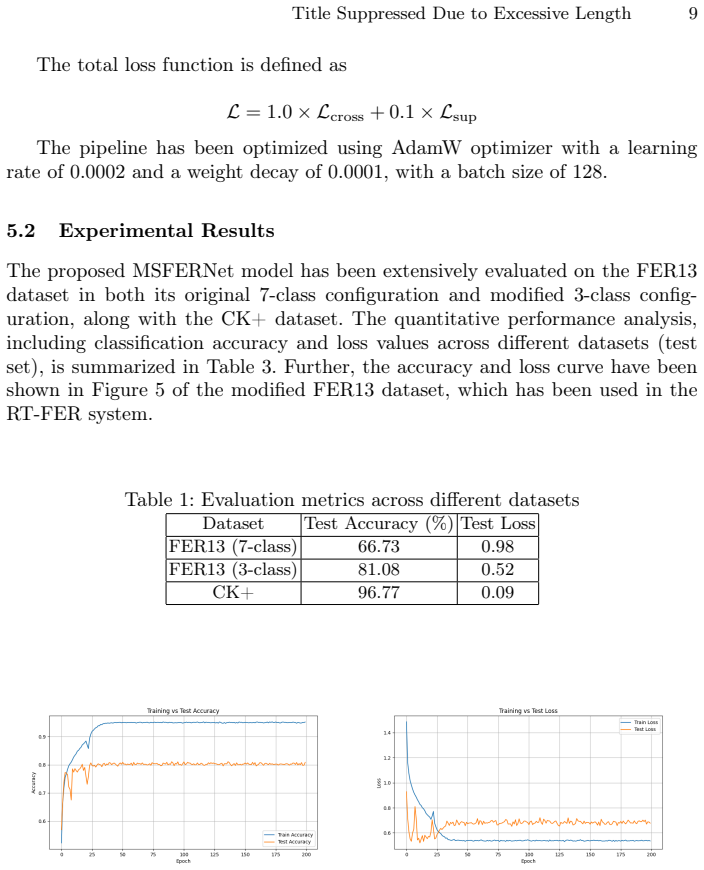
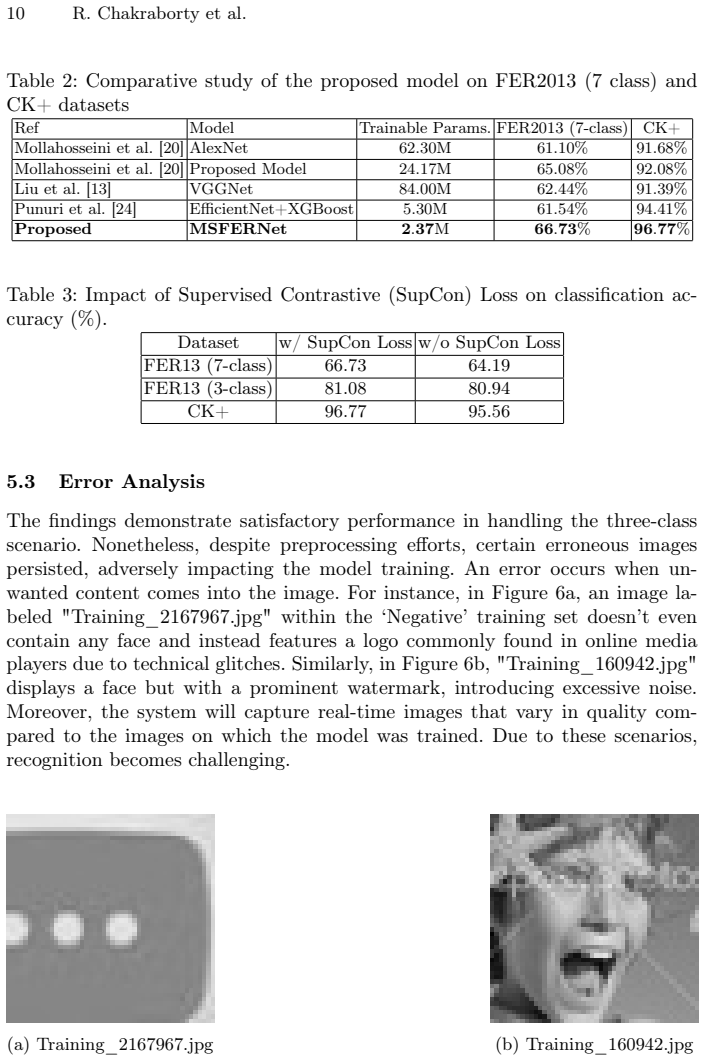
read the original abstract
Real-time emotion recognition from facial expressions is a challenging task, particularly in video-based scenarios where multiple emotional states may occur over time. The difficulty increases further due to the fact that each emotional state is associated with facial expressions that vary significantly across individuals. The change of facial expressions portraying emotional state is not discrete, but rather continuous, which is very challenging to represent through computational aids. A system with the ability to detect variations in facial expressions can have a significant impact on determining the emotional state of an individual. Such a system can be very beneficial for psychologists during counseling by providing additional insights into the emotional state of a subject. In this paper, a deep learning-based system is presented to detect emotional changes in real-time video of a person by modeling the change in facial expressions. The current study is conducted on a standard dataset for training of the deep learning system and the system has provided very satisfactory outcomes in this respect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multiscale network combined with supervised contrastive learning for real-time facial emotion recognition from video. It is trained on a standard dataset and claims to achieve very satisfactory outcomes, with potential utility for psychologists in counseling by detecting changes in facial expressions that reflect continuous emotional states varying across individuals.
Significance. If the multiscale architecture and contrastive objective demonstrably improve feature discriminability and the model generalizes beyond the training distribution, the work could add to affective computing methods for handling inter-subject variability in expressions. However, the absence of any reported metrics prevents assessment of whether these components deliver meaningful gains over standard FER pipelines.
major comments (2)
- [Abstract] Abstract: The central claim that the system 'has provided very satisfactory outcomes' on a standard dataset is unsupported by any quantitative evidence. No accuracy, precision, recall, F1, confusion matrices, baselines, error bars, dataset name, or ablation results on the multiscale components or contrastive loss are mentioned, rendering the performance assertion impossible to evaluate.
- [Abstract] Abstract: The application claim for real-time counseling video requires capturing continuous, person-specific temporal dynamics, yet the described training occurs only on a standard (typically discrete-label, posed) FER dataset. No cross-dataset, longitudinal, spontaneous-expression, or in-the-wild evaluation is referenced, so the generalization step from discrete training labels to continuous real-video detection is not demonstrated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions to the manuscript will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the system 'has provided very satisfactory outcomes' on a standard dataset is unsupported by any quantitative evidence. No accuracy, precision, recall, F1, confusion matrices, baselines, error bars, dataset name, or ablation results on the multiscale components or contrastive loss are mentioned, rendering the performance assertion impossible to evaluate.
Authors: We agree that the abstract as written does not contain quantitative metrics, dataset details, or ablation results, which makes the performance claim difficult to assess. The full manuscript reports experimental results including accuracy, comparisons to baselines, and component ablations on the standard FER dataset; however, these were not summarized in the abstract. We will revise the abstract to include key metrics (e.g., overall accuracy and F1), the dataset name, and a brief statement on the contribution of the multiscale architecture and contrastive loss. revision: yes
-
Referee: [Abstract] Abstract: The application claim for real-time counseling video requires capturing continuous, person-specific temporal dynamics, yet the described training occurs only on a standard (typically discrete-label, posed) FER dataset. No cross-dataset, longitudinal, spontaneous-expression, or in-the-wild evaluation is referenced, so the generalization step from discrete training labels to continuous real-video detection is not demonstrated.
Authors: The referee correctly notes that the abstract references potential utility for counseling videos involving continuous emotional states, while training and evaluation are performed on a standard discrete-label dataset. The manuscript does not include cross-dataset, spontaneous, or longitudinal evaluations. We will revise the abstract to clarify that the current results are on the standard posed dataset for real-time frame-level detection and that extension to continuous in-the-wild scenarios remains future work, without overstating generalization. revision: yes
Circularity Check
No derivation chain or equations present; empirical training on labeled dataset with no self-referential reductions.
full rationale
The paper describes a multiscale network using supervised contrastive learning for facial emotion recognition, trained on a standard dataset with reported satisfactory outcomes. No equations, first-principles derivations, or predictive claims that reduce to fitted parameters or self-citations are present in the abstract or described content. The work is a standard supervised ML pipeline on discrete labels, with no load-bearing steps that could exhibit circularity by construction. Central claims rest on empirical performance rather than any mathematical reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial Intelligence Review43, 155–177 (2015)
Anagnostopoulos, C.N., Iliou, T., Giannoukos, I.: Features and classifiers for emo- tion recognition from speech: a survey from 2000 to 2011. Artificial Intelligence Review43, 155–177 (2015)
2000
-
[2]
Dhall, A., Goecke, R., Lucey, S., Gedeon, T.: Static facial expression analysis in toughconditions:Data,evaluationprotocolandbenchmark.In:2011IEEEinterna- tional conference on computer vision workshops (ICCV workshops). pp. 2106–2112. IEEE (2011)
2011
-
[3]
In: International conference on neural information processing
Goodfellow, I.J., Erhan, D., Carrier, P.L., Courville, A., Mirza, M., Hamner, B., Cukierski, W., Tang, Y., Thaler, D., Lee, D.H., et al.: Challenges in representation learning: A report on three machine learning contests. In: International conference on neural information processing. pp. 117–124. Springer (2013)
2013
-
[4]
Image and vision computing28(5), 807–813 (2010)
Gross, R., Matthews, I., Cohn, J., Kanade, T., Baker, S.: Multi-pie. Image and vision computing28(5), 807–813 (2010)
2010
-
[5]
Pattern Recognition Letters120, 69–74 (2019)
Jain, D.K., Shamsolmoali, P., Sehdev, P.: Extended deep neural network for facial emotion recognition. Pattern Recognition Letters120, 69–74 (2019)
2019
-
[6]
Pattern Recognition Letters115, 101–106 (2018)
Jain, N., Kumar, S., Kumar, A., Shamsolmoali, P., Zareapoor, M.: Hybrid deep neural networks for face emotion recognition. Pattern Recognition Letters115, 101–106 (2018)
2018
-
[7]
Advances in neural information processing systems33, 18661–18673 (2020) 12 R
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. Advances in neural information processing systems33, 18661–18673 (2020) 12 R. Chakraborty et al
2020
-
[8]
IEEE Transactions on Affective Computing10(2), 223–236 (2017)
Kim, D.H., Baddar, W.J., Jang, J., Ro, Y.M.: Multi-objective based spatio- temporal feature representation learning robust to expression intensity variations for facial expression recognition. IEEE Transactions on Affective Computing10(2), 223–236 (2017)
2017
-
[9]
Emotion15(5), 625 (2015)
Koval, P., Brose, A., Pe, M.L., Houben, M., Erbas, Y., Champagne, D., Kuppens, P.: Emotional inertia and external events: The roles of exposure, reactivity, and recovery. Emotion15(5), 625 (2015)
2015
-
[10]
Cognition and emotion24(8), 1377–1388 (2010)
Langner, O., Dotsch, R., Bijlstra, G., Wigboldus, D.H., Hawk, S.T., Van Knip- penberg, A.: Presentation and validation of the radboud faces database. Cognition and emotion24(8), 1377–1388 (2010)
2010
-
[11]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Li, S., Deng, W., Du, J.: Reliable crowdsourcing and deep locality-preserving learn- ing for expression recognition in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2852–2861 (2017)
2017
-
[12]
IEEE Transactions on Image Processing 28(5), 2439–2450 (2018)
Li, Y., Zeng, J., Shan, S., Chen, X.: Occlusion aware facial expression recogni- tion using cnn with attention mechanism. IEEE Transactions on Image Processing 28(5), 2439–2450 (2018)
2018
-
[13]
In: 2016 international conference on cyberworlds (CW)
Liu, K., Zhang, M., Pan, Z.: Facial expression recognition with cnn ensemble. In: 2016 international conference on cyberworlds (CW). pp. 163–166. IEEE (2016)
2016
-
[14]
In: 2010 ieee computer society conference on computer vision and pattern recognition-workshops
Lucey, P., Cohn, J.F., Kanade, T., Saragih, J., Ambadar, Z., Matthews, I.: The ex- tendedcohn-kanadedataset(ck+):Acompletedatasetforactionunitandemotion- specified expression. In: 2010 ieee computer society conference on computer vision and pattern recognition-workshops. pp. 94–101. IEEE (2010)
2010
-
[15]
The Images Are Provided at No Cost for Non-Commercial Scientific Re- search Only
Lyons, M., Kamachi, M., Gyoba, J.: The japanese female facial expression (jaffe) dataset. The Images Are Provided at No Cost for Non-Commercial Scientific Re- search Only. If You Agree to the Conditions Listed Below, You May Request Access to Download (1998)
1998
-
[16]
Emotion Review4(4), 380–381 (2012)
Majid, A.: The role of language in a science of emotion. Emotion Review4(4), 380–381 (2012)
2012
-
[17]
High-performance modelling and simulation for big data appli- cations11400, 307–324 (2019)
Marechal, C., Mikolajewski, D., Tyburek, K., Prokopowicz, P., Bougueroua, L., Ancourt, C., Wegrzyn-Wolska, K.: Survey on ai-based multimodal methods for emotion detection. High-performance modelling and simulation for big data appli- cations11400, 307–324 (2019)
2019
-
[18]
IEEE Transactions on Affective Computing 4(2), 151–160 (2013)
Mavadati,S.M.,Mahoor,M.H.,Bartlett,K.,Trinh,P.,Cohn,J.F.:Disfa:Asponta- neous facial action intensity database. IEEE Transactions on Affective Computing 4(2), 151–160 (2013)
2013
-
[19]
In: 2017 IEEE 4th international conference on knowledge-based engineering and innovation (KBEI)
Mohammadpour, M., Khaliliardali, H., Hashemi, S.M.R., AlyanNezhadi, M.M.: Facial emotion recognition using deep convolutional networks. In: 2017 IEEE 4th international conference on knowledge-based engineering and innovation (KBEI). pp. 0017–0021. IEEE (2017)
2017
-
[20]
In: 2016 IEEE Winter conference on ap- plications of computer vision (WACV)
Mollahosseini, A., Chan, D., Mahoor, M.H.: Going deeper in facial expression recognition using deep neural networks. In: 2016 IEEE Winter conference on ap- plications of computer vision (WACV). pp. 1–10. IEEE (2016)
2016
-
[21]
IEEE Transactions on Affec- tive Computing10(1), 18–31 (2017)
Mollahosseini, A., Hasani, B., Mahoor, M.H.: Affectnet: A database for facial ex- pression, valence, and arousal computing in the wild. IEEE Transactions on Affec- tive Computing10(1), 18–31 (2017)
2017
-
[22]
IEEE/ACM transactions on computational biology and bioinformatics17(6), 2131–2140 (2019)
Ogunleye, A., Wang, Q.G.: Xgboost model for chronic kidney disease diagno- sis. IEEE/ACM transactions on computational biology and bioinformatics17(6), 2131–2140 (2019)
2019
-
[23]
In: 2005 IEEE international conference on multimedia and Expo
Pantic, M., Valstar, M., Rademaker, R., Maat, L.: Web-based database for facial expression analysis. In: 2005 IEEE international conference on multimedia and Expo. pp. 5–pp. IEEE (2005) Title Suppressed Due to Excessive Length 13
2005
-
[24]
Mathematics11(3), 776 (2023)
Punuri, S.B., Kuanar, S.K., Kolhar, M., Mishra, T.K., Alameen, A., Mohapatra, H., Mishra, S.R.: Efficient net-xgboost: an implementation for facial emotion recog- nition using transfer learning. Mathematics11(3), 776 (2023)
2023
-
[25]
IEEE transactions on pattern analysis and machine intelligence37(6), 1113–1133 (2014)
Sariyanidi, E., Gunes, H., Cavallaro, A.: Automatic analysis of facial affect: A sur- vey of registration, representation, and recognition. IEEE transactions on pattern analysis and machine intelligence37(6), 1113–1133 (2014)
2014
-
[26]
Sensors18(7), 2074 (2018)
Shu, L., Xie, J., Yang, M., Li, Z., Li, Z., Liao, D., Xu, X., Yang, X.: A review of emotion recognition using physiological signals. Sensors18(7), 2074 (2018)
2074
-
[27]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[28]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1–9 (2015)
2015
-
[29]
In: International conference on machine learning
Tan, M., Le, Q.: Efficientnet: Rethinking model scaling for convolutional neural networks. In: International conference on machine learning. pp. 6105–6114. PMLR (2019)
2019
-
[30]
Tan, M., Le, Q.V.: Efficientnet: Rethinking model scaling for convolutional neural networks (2020), https://arxiv.org/abs/1905.11946
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[31]
In: 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG)
Valstar, M.F., Jiang, B., Mehu, M., Pantic, M., Scherer, K.: The first facial expres- sion recognition and analysis challenge. In: 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG). pp. 921–926. IEEE (2011)
2011
-
[32]
In: Proceedings of the European conference on computer vision (ECCV)
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: Cbam: Convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018)
2018
-
[33]
PloS one9(1), e86041 (2014)
Yan, W.J., Li, X., Wang, S.J., Zhao, G., Liu, Y.J., Chen, Y.H., Fu, X.: Casme ii: An improved spontaneous micro-expression database and the baseline evaluation. PloS one9(1), e86041 (2014)
2014
-
[34]
Multimedia Tools and Applications78, 31581–31603 (2019)
Yolcu, G., Oztel, I., Kazan, S., Oz, C., Palaniappan, K., Lever, T.E., Bunyak, F.: Facial expression recognition for monitoring neurological disorders based on convolutional neural network. Multimedia Tools and Applications78, 31581–31603 (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.