Dual-Route Top-K Retrieval with 1v1 VLM Reranking for the CoVR-R
Pith reviewed 2026-06-28 17:47 UTC · model grok-4.3
The pith
A dual-route retrieval pipeline with 1v1 VLM reranking reaches 95.28 R@1 on the CoVR-R hidden test split by separating candidate recall from final selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
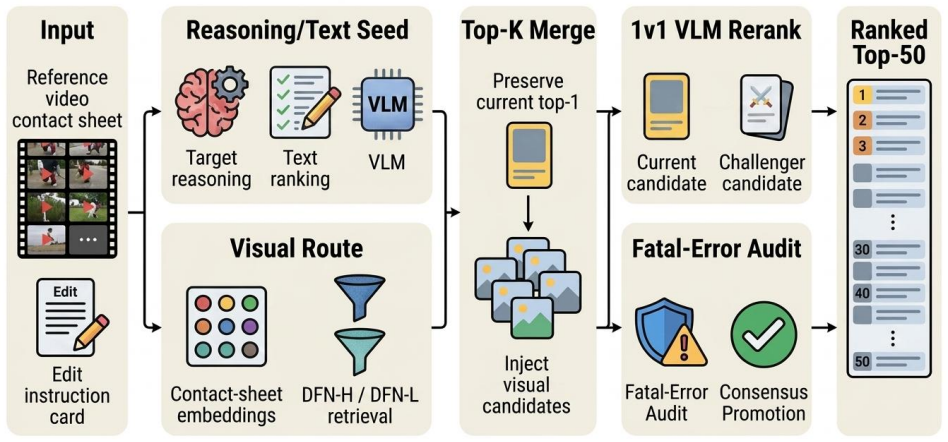
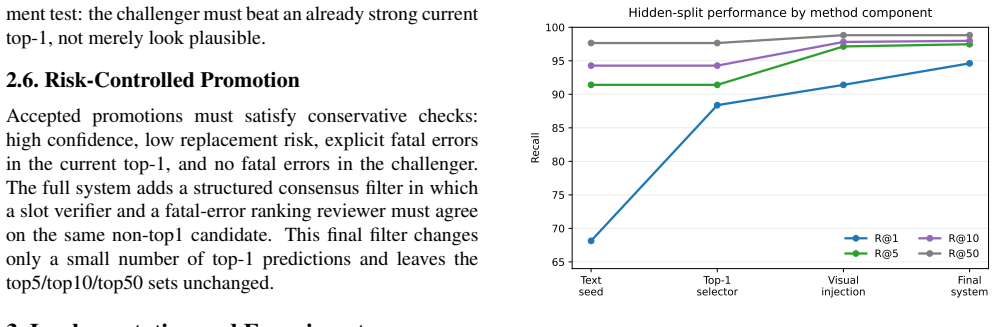
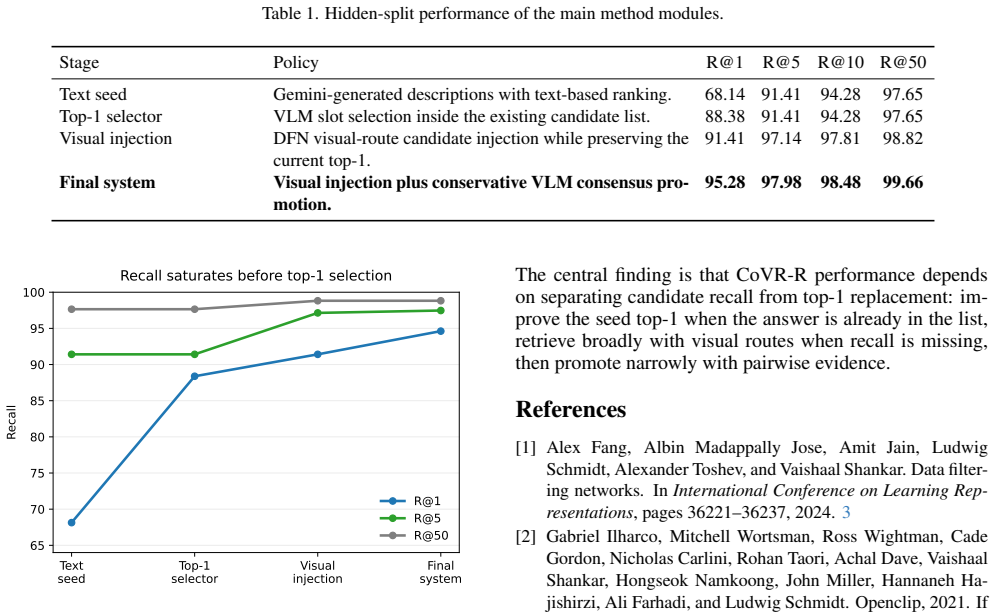
The method frames composed video retrieval as two coupled problems of generating a sufficiently complete top-k candidate set and then safely deciding whether any candidate should replace the current top-1. A VLM slot selector refines the reasoning/text seed without DFN visual retrieval, a visual route is added from contact-sheet embeddings using DFN-H/DFN-L, and the routes are merged into a top-10 set. A VLM reranker then performs conservative 1v1 comparisons between the top-1 and each challenger, producing 95.28 R@1, 97.47 R@5, 98.48 R@10 and 99.66 R@50 on the hidden test split, with the reported lesson that recall-selection decoupling benefits CoVR-R more than broad text reranking or direc
What carries the argument
Dual-route top-k candidate generation merged to a top-10 set followed by conservative 1v1 VLM reranking between the current top-1 and challengers.
If this is right
- The system achieves 95.28 R@1, 97.47 R@5, 98.48 R@10 and 99.66 R@50 on the hidden test split.
- Recall-selection decoupling improves performance more than broad text reranking or direct multi-candidate VLM classification on CoVR-R.
- A VLM slot selector can refine the text route without adding DFN visual retrieval.
- A visual route from contact-sheet embeddings can be merged with the text route to enlarge the candidate pool.
- Conservative 1v1 comparisons allow the VLM to decide replacements safely after the top-10 merge.
Where Pith is reading between the lines
- The same recall-then-1v1 pattern could be tested on other retrieval benchmarks where VLMs are currently used for direct multi-way ranking.
- If the merged top-10 set often misses the target, expanding the merge size or adding a third route would be a direct next step.
- The conservative replacement rule may limit error propagation in any ranking pipeline that already has a strong initial top-1.
- Contact-sheet embeddings as a visual route may transfer to other video tasks that already use frame-based features.
Load-bearing premise
The merged top-10 candidate set will reliably contain the correct video and the VLM 1v1 reranker can accurately decide replacements without introducing new errors.
What would settle it
A case where the correct video lies outside the merged top-10 set or where the 1v1 VLM comparison replaces the top-1 with a lower-ranked match would show the approach fails to improve results.
Figures
read the original abstract
We describe \emph{Dual-Route Top-K Retrieval with 1v1 VLM Reranking} for the CoVR-R challenge. The method treats composed video retrieval as two coupled problems: finding a sufficiently complete top-k candidate set, and then safely deciding whether any candidate should replace a strong current top-1. We first improve the reasoning/text seed with a VLM slot selector over existing candidates, without introducing DFN visual retrieval. We then add a visual route from contact-sheet embeddings using DFN-H/DFN-L. The routes are merged into a top-10 candidate set, after which a VLM final reranker performs conservative 1v1 comparisons between the current top-1 and each challenger. On the hidden test split, the final system reaches 95.28 R@1, 97.47 R@5, 98.48 R@10, and 99.66 R@50. The main lesson is that CoVR-R benefits more from recall-selection decoupling than from broad text reranking or direct multi-candidate VLM classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes a Dual-Route Top-K Retrieval with 1v1 VLM Reranking method for the CoVR-R challenge. It improves a text seed via VLM slot selector, adds a DFN visual route, merges routes to a top-10 candidate set, and applies conservative 1v1 VLM reranking between the current top-1 and challengers. On the hidden test split the system reports 95.28 R@1, 97.47 R@5, 98.48 R@10 and 99.66 R@50; the central lesson is that recall-selection decoupling benefits CoVR-R more than broad text reranking or direct multi-candidate VLM classification.
Significance. If the performance numbers hold under full method disclosure and the decoupling lesson is substantiated, the work supplies a strong baseline for the CoVR-R challenge and illustrates a practical separation of candidate generation from final selection. The use of a hidden test split and explicit numerical results constitute a clear, falsifiable contribution.
major comments (3)
- [Abstract] Abstract: the claim that CoVR-R 'benefits more from recall-selection decoupling than from broad text reranking or direct multi-candidate VLM classification' is unsupported; no comparative results, ablation tables, or performance numbers for the alternative strategies are supplied.
- [Method description] Method description (dual-route merge paragraph): no recall@10 (or higher) is reported for the merged top-10 candidate set, leaving the key assumption that the ground-truth video is reliably present before reranking unverified and load-bearing for the final R@1 figure.
- [Method description] Method description (1v1 reranker paragraph): no count or analysis is given of how often the conservative 1v1 VLM comparisons actually replace the top-1, nor any error analysis showing net improvement rather than introduction of new errors.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CoVR-R 'benefits more from recall-selection decoupling than from broad text reranking or direct multi-candidate VLM classification' is unsupported; no comparative results, ablation tables, or performance numbers for the alternative strategies are supplied.
Authors: We agree that the interpretive claim in the abstract lacks direct supporting evidence such as comparative results or ablations against broad text reranking or multi-candidate VLM classification. This statement was based on our development experience but is not substantiated in the manuscript. We will revise the abstract to remove the unsupported claim, ensuring all assertions are directly backed by the reported experiments. revision: yes
-
Referee: [Method description] Method description (dual-route merge paragraph): no recall@10 (or higher) is reported for the merged top-10 candidate set, leaving the key assumption that the ground-truth video is reliably present before reranking unverified and load-bearing for the final R@1 figure.
Authors: We acknowledge that the recall@10 (or higher) for the merged top-10 candidate set is not reported, leaving the assumption about ground-truth presence unverified. We will add this metric to the dual-route merge paragraph in the revised method description to substantiate the candidate set quality before reranking. revision: yes
-
Referee: [Method description] Method description (1v1 reranker paragraph): no count or analysis is given of how often the conservative 1v1 VLM comparisons actually replace the top-1, nor any error analysis showing net improvement rather than introduction of new errors.
Authors: We agree that the manuscript provides no counts of top-1 replacements by the 1v1 reranker or error analysis demonstrating net benefit. We will incorporate these statistics and a brief error analysis into the 1v1 reranker paragraph in the revised manuscript to quantify the reranker's impact. revision: yes
Circularity Check
No circularity; engineering pipeline on hidden test split
full rationale
The paper presents a retrieval pipeline (VLM slot selector + DFN visual route merged to top-10, followed by 1v1 VLM reranker) and reports metrics on a hidden test split. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All components are described as independent engineering choices without reduction to their own inputs by construction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Multi-agent system for comprehensive soccer understanding , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[2]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[3]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
You only look once: Unified, real-time object detection , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[4]
2026 , url =
The 1st BlackSwan Challenge: Evaluating Abductive and Defeasible Reasoning in Unpredictable Events , author =. 2026 , url =
2026
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chinchure, Aditya and Ravi, Sahithya and Ng, Raymond and Shwartz, Vered and Li, Boyang and Sigal, Leonid , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[6]
arXiv preprint arXiv:2603.20190 , year=
Covr-r: Reason-aware composed video retrieval , author=. arXiv preprint arXiv:2603.20190 , year=
-
[7]
doi:10.5281/zenodo.5143773 , url =
Ilharco, Gabriel and Wortsman, Mitchell and Wightman, Ross and Gordon, Cade and Carlini, Nicholas and Taori, Rohan and Dave, Achal and Shankar, Vaishaal and Namkoong, Hongseok and Miller, John and Hajishirzi, Hannaneh and Farhadi, Ali and Schmidt, Ludwig , title =. doi:10.5281/zenodo.5143773 , url =
-
[8]
International Conference on Learning Representations , volume=
Data filtering networks , author=. International Conference on Learning Representations , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.