Diagnosing LLM Arbitration Behavior over Pre-evidence Epistemic States in RAG-based Fact-Checking
Pith reviewed 2026-06-28 17:38 UTC · model grok-4.3
The pith
LLM verifiers in RAG fact-checking arbitrate unreliably between their pre-evidence knowledge and retrieved evidence in a model-dependent manner.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
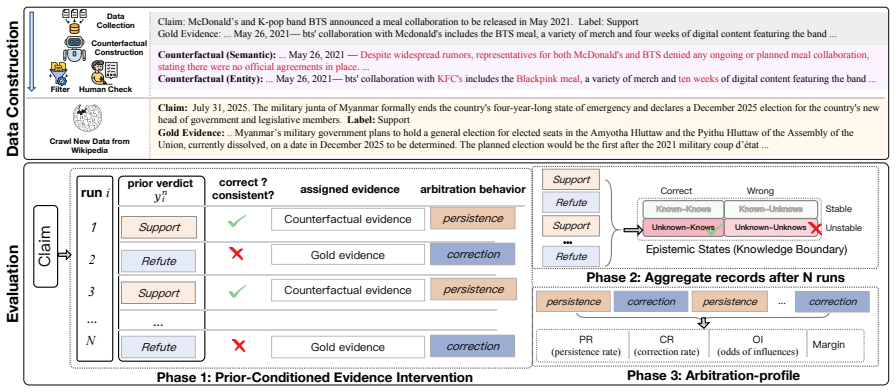
Stratifying verifiers by the correctness and of their pre-evidence priors allows diagnosis of arbitration behavior: whether an LLM persists with a correct prior against misleading evidence and whether it revises an incorrect prior when accurate evidence arrives. Experiments show this behavior is unreliable and highly model-dependent. A JSD-based test-time arbitration procedure improves factual reliability across diverse LLM families without any model modification.
What carries the argument
PAVE testbed that defines four epistemic states from pre-evidence prior correctness and confidence to measure arbitration between parametric knowledge and contextual evidence.
If this is right
- Verifier selection becomes a necessary step for reliable RAG fact-checking systems.
- The JSD-based method raises factual accuracy without retraining or architectural changes.
- Model-specific calibration of arbitration may be required for production deployments.
- The four-state diagnostic can be used to compare future LLMs on prior-context handling.
Where Pith is reading between the lines
- Standard RAG pipelines may benefit from an explicit arbitration layer even when using strong base models.
- The same epistemic-state approach could be applied to other retrieval-augmented tasks such as question answering or summarization.
- Test-time methods like the JSD adjustment might generalize to settings where evidence quality varies dynamically.
Load-bearing premise
The four epistemic states defined by pre-evidence correctness and confidence of parametric knowledge are sufficient to characterize and diagnose the arbitration behavior that occurs in actual RAG-based fact-checking deployments.
What would settle it
A replication of the PAVE experiments on an independent set of LLMs that finds arbitration outcomes to be consistent across models rather than model-dependent would falsify the central claim.
Figures






read the original abstract
In RAG-based fact-checking, LLMs are increasingly used as verifiers to check given claims against retrieved evidence. Their parametric knowledge can induce pre-evidence tendencies that may conflict with the retrieved context, yet existing evaluation frameworks do not characterize such prior-context discrepancy or measure how verifiers arbitrate between parametric and contextual signals. We introduce \textsc{PAVE} (\emph{Prior-Aware Verifier Evaluation}), a diagnostic testbed that stratifies an LLM verifier into four epistemic states based on the correctness and confidence of its pre-evidence prior and evaluates its arbitration behavior on this new benchmark, i.e., whether it persists in correct prior under misleading evidence, and whether it corrects wrong prior when accurate evidence is provided. Experiments across seven LLMs reveal unreliable and highly model-dependent prior-context arbitration, highlighting the importance of verifier selection for real-world RAG-based fact-checking applications. Based on these findings, we propose a lightweight JSD-based test-time arbitration method that improves factual reliability without modifying the underlying model, achieving competitive performance across diverse LLM families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PAVE, a diagnostic testbed that stratifies LLM verifiers into four epistemic states (pre-evidence correctness × confidence) to evaluate how they arbitrate between parametric knowledge and retrieved evidence in RAG fact-checking. Experiments on seven LLMs show unreliable, model-dependent arbitration behavior. The authors propose a lightweight JSD-based test-time arbitration method that improves factual reliability without model changes.
Significance. If the experimental results hold under more varied evidence conditions, the work would usefully highlight risks of prior-context conflicts in LLM verifiers and supply a practical, model-agnostic mitigation. The new benchmark and JSD method are concrete contributions to RAG reliability evaluation.
major comments (2)
- [PAVE testbed] PAVE testbed definition: the central diagnostic and the proposed JSD method rest on the claim that the four epistemic states (correctness and confidence of pre-evidence prior) suffice to characterize arbitration. Real RAG evidence varies continuously in relevance, completeness, and internal consistency; the benchmark uses only fully correct or fully misleading evidence, so observed unreliability and JSD gains may not transfer.
- [Abstract / Experiments] Abstract and experimental description: the reported findings on seven LLMs supply no details on dataset construction, sample sizes per state, statistical tests, or controls for evidence quality, preventing assessment of whether the unreliability claims are supported.
minor comments (1)
- [JSD method] Notation: the JSD-based arbitration procedure is described at a high level; a precise algorithmic statement or pseudocode would clarify how the divergence is computed from the verifier outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the PAVE testbed and experimental reporting. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [PAVE testbed] PAVE testbed definition: the central diagnostic and the proposed JSD method rest on the claim that the four epistemic states (correctness and confidence of pre-evidence prior) suffice to characterize arbitration. Real RAG evidence varies continuously in relevance, completeness, and internal consistency; the benchmark uses only fully correct or fully misleading evidence, so observed unreliability and JSD gains may not transfer.
Authors: PAVE is intentionally constructed as a controlled diagnostic that isolates arbitration behavior under the four pre-evidence epistemic states by employing fully correct versus fully misleading evidence. This binary design enables clear measurement of persistence versus correction tendencies without confounding factors from partial relevance. We agree that real-world evidence exhibits continuous variation and will add an explicit limitations paragraph discussing this scope and outlining planned extensions to graded evidence conditions. revision: partial
-
Referee: [Abstract / Experiments] Abstract and experimental description: the reported findings on seven LLMs supply no details on dataset construction, sample sizes per state, statistical tests, or controls for evidence quality, preventing assessment of whether the unreliability claims are supported.
Authors: The full manuscript contains a dedicated Experiments section that specifies dataset construction (synthetic claim-evidence pairs generated from verified sources for each epistemic state), sample sizes (200 instances per state per model), statistical tests (paired t-tests with p<0.01 thresholds), and evidence-quality controls (manual verification that misleading evidence is factually false). To address the concern, we will expand the abstract with a concise summary of these parameters and include a new experimental-setup table in the revision. revision: yes
Circularity Check
No circularity: diagnostic framework and JSD method are self-contained
full rationale
The paper defines four epistemic states from first principles (pre-evidence correctness × confidence) to create the PAVE testbed, runs experiments across seven LLMs to observe arbitration patterns, and proposes a JSD-based arbitration method derived from those observations. No equations, fitted parameters, or self-citation chains are present that reduce any claimed prediction or result to the inputs by construction. The derivation chain relies on external LLM evaluations and is not equivalent to renaming or refitting the benchmark data itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs possess pre-evidence parametric knowledge whose correctness and confidence can be measured to define four distinct epistemic states
invented entities (2)
-
PAVE testbed
no independent evidence
-
JSD-based test-time arbitration method
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InInternational conference on machine learning, pages 2206–2240
Improving language models by retrieving from trillions of tokens. InInternational conference on machine learning, pages 2206–2240. PMLR. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners.Advances...
-
[2]
InProceedings of the 2021 Conference on Empirical Methods in Natural Language Process- ing, pages 7052–7063, Online and Punta Cana, Do- minican Republic
Entity-based knowledge conflicts in question answering. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Process- ing, pages 7052–7063, Online and Punta Cana, Do- minican Republic. Association for Computational Linguistics. Kelvin Luu, Daniel Khashabi, Suchin Gururangan, Kar- ishma Mandyam, and Noah A Smith. 2022. Time waits f...
2021
-
[3]
the moon is made of marshmallows
Factual confidence of llms: on reliability and robustness of current estimators.arXiv preprint arXiv:2406.13415. Sara Vera Marjanovic, Haeun Yu, Pepa Atanasova, Maria Maistro, Christina Lioma, and Isabelle Augen- stein. 2024. DYNAMICQA: Tracing internal knowl- edge conflicts in language models. InFindings of the Association for Computational Linguistics: ...
-
[4]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8420–8436, Bangkok, Thailand
Competition of mechanisms: Tracing how language models handle facts and counterfactuals. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8420–8436, Bangkok, Thailand. Association for Computational Linguistics. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pame...
2022
-
[5]
Yuxi Sun, Aoqi Zuo, Wei Gao, and Jing Ma
Conflictbank: A benchmark for evaluating the influence of knowledge conflicts in llm.arXiv preprint arXiv:2408.12076. Yuxi Sun, Aoqi Zuo, Wei Gao, and Jing Ma. 2025. Causalabstain: Enhancing multilingual llms with causal reasoning for trustworthy abstention. InFind- ings of the Association for Computational Linguistics: ACL 2025, pages 14060–14076. Yuxi S...
-
[6]
Benchmarking knowledge boundary for large language models: A different perspective on model evaluation. InProceedings of the 62nd Annual Meet- ing of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 2270–2286, Bangkok, Thailand. Association for Computational Linguistics. Jifan Yu, Xiaozhi Wang, Shangqing Tu, Shulin Cao, Danie...
-
[7]
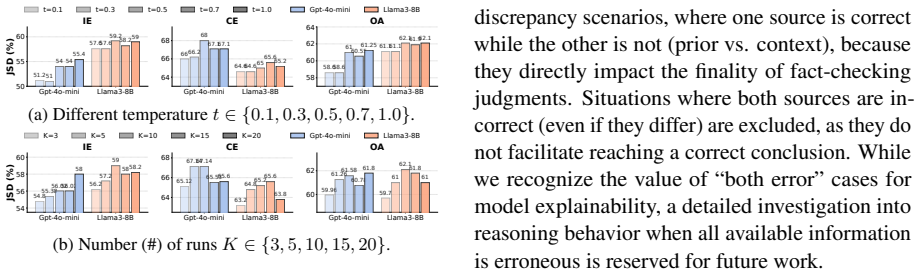
More observation.Observation A compares counter-semantic and counter-entity conflicts, showing that semantic-level discrepancies are more challenging for models to resist
-
[8]
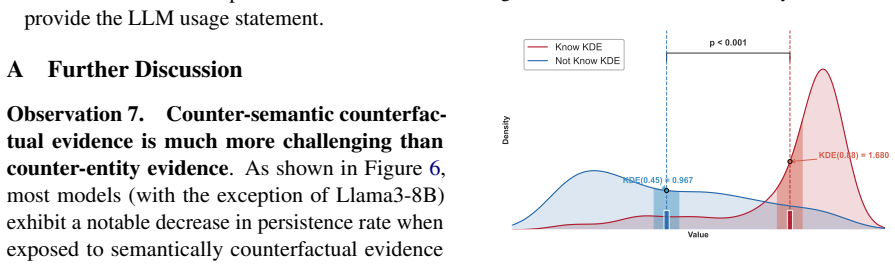
Experimental settings discussion.Ap- pendix A.1 analyzes the effects of tem- perature and the number of independent runs, while Appendix A.2 validates the KNOWN/UNKNOWNsplit through confidence and class-token probability distributions
-
[9]
Stability and generality of the evaluation. Appendix A.3 reports variance and standard deviation statistics for correction and per- sistence behaviors across models, and Ap- pendix A.4 extends the analysis to multi-label verdict prediction on PUBHEALTH
-
[10]
Appendix A.5 presents hallucination cases where models over-confidently extrapolate be- yond their verified knowledge boundaries, fur- ther motivating prior-aware arbitration
Failure analysis on temporally novel claims. Appendix A.5 presents hallucination cases where models over-confidently extrapolate be- yond their verified knowledge boundaries, fur- ther motivating prior-aware arbitration
-
[11]
Sup- port
Robustness to Output Variation.Ap- pendix A.6 examines whether different output- token choices affect the evaluation results and shows that our findings remain stable across semantically equivalent verbalizers. • Appendix B: Related Works.This section posi- tions our benchmark and our arbitration setting with respect to prior work on prior-context dis- cr...
2023
-
[12]
complete college
demonstrate that this sequential structure increases the model’s reliance on prior knowl- edge, thereby reducing its vulnerability to mis- Claim (c) High school students arrested on campus are twice as likely not to graduate and four times less likely to graduate if they’ve appeared in court. External Evidencee high school dropouts are three and one-half ...
2017
-
[13]
Break down your reasoning process and assess the confidence level of your original answer, explaining why you believe your answer is correct
Internal Reasoning: Reflect on how you arrived at your internal answer using your own knowl- edge. Break down your reasoning process and assess the confidence level of your original answer, explaining why you believe your answer is correct
-
[14]
Determine whether the evidence contains deceptive or unreliable information, considering possible contradictions or inconsistencies
Evidence Evaluation: Analyze the evidence and cross-reference the information provided with the known facts you used to form your internal answer. Determine whether the evidence contains deceptive or unreliable information, considering possible contradictions or inconsistencies
-
[15]
True" if the model’s answer is correct, and
Final Judgment: Based on your analysis, decide which answer (your internal answer or the evidence’s answer) is more likely to be correct. Clearly state your final answer. Question:{question} Your answer:{internal answer} The evidence to judge:{evidence} The evidence answer:{evidence answer} Please provide a detailed reasoning process, followed by your fin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.