Reasoning4Sciences: Bridging Reasoning Language Models to All Scientific Branches
Pith reviewed 2026-06-28 17:33 UTC · model grok-4.3
The pith
Reasoning language models show concentrated adoption in hard sciences with widening maturity gaps across 28 disciplines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
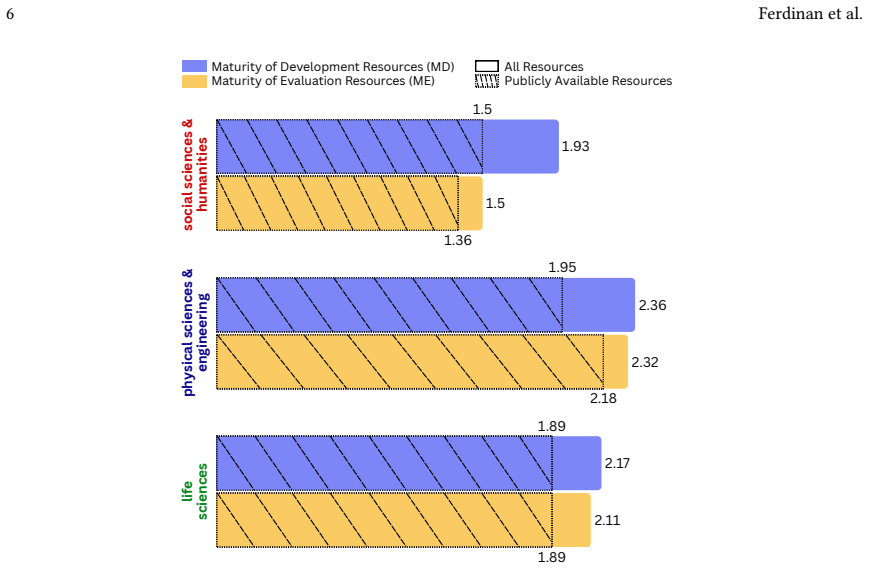
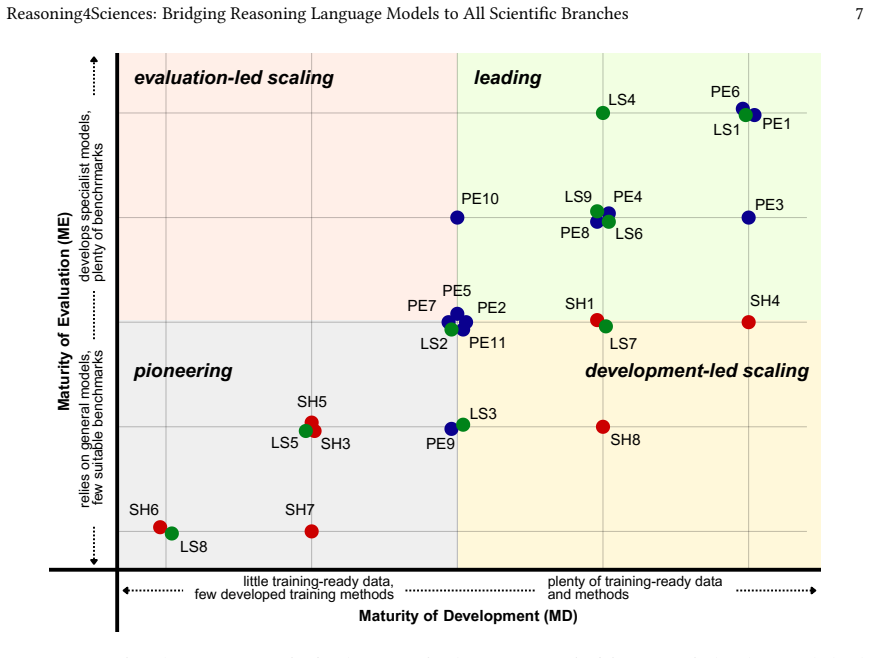
RLM adoption is concentrated in hard science fields with substantial disparities in maturity across the 28 ERC disciplines; these disparities become even more pronounced when only publicly available resources are considered.
What carries the argument
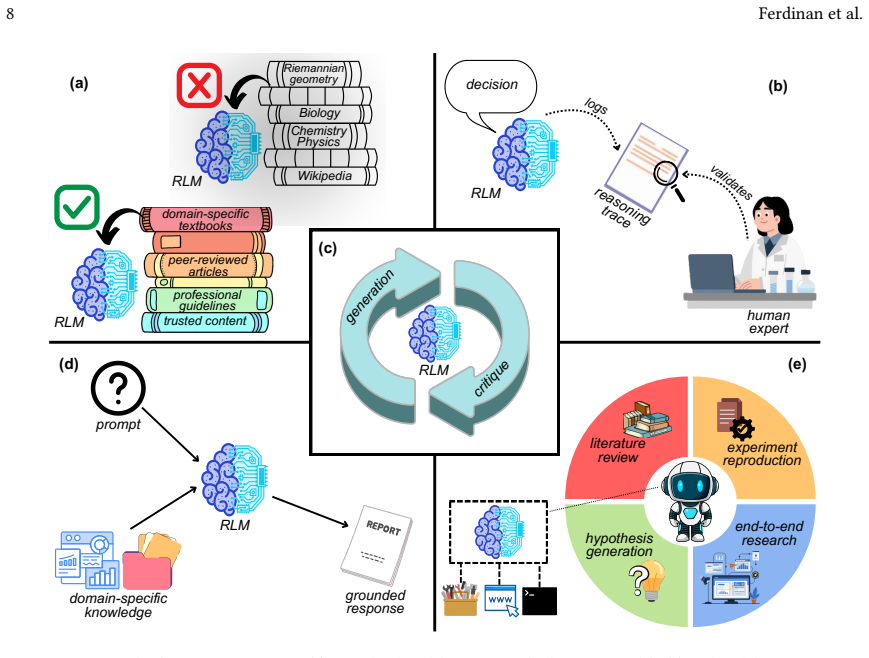
A maturity-oriented assessment framework that scores each discipline according to the quantity and accessibility of domain-specific development and evaluation resources for reasoning language models.
If this is right
- Disciplines rated low in maturity will continue to experience slower productivity gains from reasoning language models unless targeted resources appear.
- Implementation patterns that succeed in high-maturity fields can be tested for transfer to lower-maturity fields.
- Public-only resource gaps imply that open data and benchmark releases would be high-leverage actions for closing divides.
- Future work should focus on the specific challenges of data scarcity and evaluation standards identified for lagging disciplines.
Where Pith is reading between the lines
- If the maturity gaps persist, overall scientific progress could become more uneven as hard-science fields pull further ahead.
- Prioritizing public datasets and shared benchmarks for under-served disciplines offers a direct lever to reduce the observed divides.
- The same maturity lens could be reapplied in two or three years to test whether policy or community efforts have narrowed the differences.
Load-bearing premise
The 28 ERC discipline categories together with the authors' resource-based maturity ratings give a faithful picture of real differences in how ready each scientific branch is for reasoning language models.
What would settle it
A direct count of reasoning-language-model usage or resource creation per ERC discipline that finds roughly equal activity across hard sciences, life sciences, and social sciences and humanities would undermine the reported concentration and disparity.
Figures


read the original abstract
While Reasoning Language Models (RLMs) are rapidly emerging as powerful tools for scientific research, their impact is primarily concentrated in "hard science" fields. The slow -- or lack of -- adoption of RLMs in other branches of science is causing a widening gap in research productivity. In this survey, we provide the first comprehensive analysis of RLM adoption across 28 scientific disciplines following the classification used by the European Research Council (ERC), spanning the Social Sciences and Humanities, Physical Sciences and Engineering, and Life Sciences. We examine how RLMs are developed, evaluated, and applied across disciplines. Furthermore, we introduce a maturity-oriented assessment framework based on available domain-specific development and evaluation resources, revealing substantial disparities in RLM maturity that become even more pronounced when only publicly available resources are considered. Finally, we highlight current implementation paradigms that are gaining popularity across disciplines, current challenges, and future directions in enabling RLM adoption across science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys Reasoning Language Model (RLM) adoption across the 28 ERC disciplines spanning Social Sciences and Humanities, Physical Sciences and Engineering, and Life Sciences. It claims RLM use is concentrated in hard sciences, introduces a maturity-oriented assessment framework based on domain-specific development and evaluation resources, and reports substantial maturity disparities that widen when restricted to public resources. The work also reviews implementation paradigms, challenges, and future directions for broader adoption.
Significance. If the survey methodology and maturity framework can be made reproducible, the quantification of adoption gaps across all ERC branches would provide a useful reference for prioritizing RLM resource development in underrepresented fields and could help close the described productivity gap.
major comments (3)
- [Abstract] Abstract and the section defining the maturity-oriented assessment framework: no explicit search methodology, inclusion/exclusion criteria, or quantitative rules for resource counting and maturity-level thresholding are provided, so the central claim of discipline-level disparities rests on an unvalidated classification procedure whose reproducibility is not demonstrated.
- [Maturity framework section] The section presenting the maturity framework and associated tables/figures: without inter-rater reliability checks or a reproducible scoring rubric, the reported widening of disparities under the public-resources restriction cannot be distinguished from classification artifacts.
- [Literature review section] The literature-selection description (likely §2 or §3): absence of a documented protocol for identifying domain-specific RLM papers and resources undermines the claim that the analysis is the 'first comprehensive' survey across all 28 ERC disciplines.
minor comments (2)
- Clarify notation for maturity levels and ensure every table or figure is explicitly referenced in the surrounding text.
- Add a limitations subsection that explicitly discusses potential biases in ERC classification and resource availability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater methodological transparency. We agree that reproducibility is essential for a survey of this scope and will revise the manuscript to include explicit documentation of the survey process, thereby strengthening the central claims regarding RLM adoption disparities.
read point-by-point responses
-
Referee: [Abstract] Abstract and the section defining the maturity-oriented assessment framework: no explicit search methodology, inclusion/exclusion criteria, or quantitative rules for resource counting and maturity-level thresholding are provided, so the central claim of discipline-level disparities rests on an unvalidated classification procedure whose reproducibility is not demonstrated.
Authors: We agree that the manuscript would benefit from an explicit methods description. In the revision we will insert a new 'Survey Methodology' subsection that details the literature search strategy across databases, the keywords and time bounds employed, inclusion/exclusion criteria for papers and resources, and the quantitative thresholds used to assign maturity levels. This addition will make the classification procedure reproducible and directly support the reported discipline-level disparities. revision: yes
-
Referee: [Maturity framework section] The section presenting the maturity framework and associated tables/figures: without inter-rater reliability checks or a reproducible scoring rubric, the reported widening of disparities under the public-resources restriction cannot be distinguished from classification artifacts.
Authors: We acknowledge the value of a documented rubric and consistency checks. The revised maturity-framework section will present the full scoring rubric used to evaluate domain-specific development and evaluation resources, together with the procedure followed for assigning levels. Where formal inter-rater reliability statistics were not computed, we will state this limitation and describe the steps taken to maintain classification consistency; any feasible post-hoc checks will be added. revision: yes
-
Referee: [Literature review section] The literature-selection description (likely §2 or §3): absence of a documented protocol for identifying domain-specific RLM papers and resources undermines the claim that the analysis is the 'first comprehensive' survey across all 28 ERC disciplines.
Authors: We will expand the literature-review section with a dedicated protocol subsection that records how domain-specific RLM papers and resources were identified for each of the 28 ERC disciplines. This documentation will clarify the breadth of coverage underlying the 'first comprehensive' characterization while remaining transparent about any practical constraints of the broad disciplinary scope. revision: yes
Circularity Check
Descriptive survey with no derivation chain, equations, or fitted predictions
full rationale
The paper is a survey providing analysis of RLM adoption across 28 ERC disciplines and introducing a maturity-oriented assessment framework based on domain-specific resources. It contains no equations, derivations, model parameters, or predictions that could reduce to inputs by construction. The framework is presented as an original contribution for classifying maturity levels from resource availability, with disparities reported as direct observations rather than any self-referential or fitted result. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way. This is a standard descriptive survey whose central claims rest on external resource enumeration and ERC classification, making it self-contained with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The European Research Council classification accurately partitions all scientific disciplines into 28 categories suitable for uniform comparison.
invented entities (1)
-
maturity-oriented assessment framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Suhaib Abdurahman, Alireza Salkhordeh Ziabari, Alexander K. Moore, Daniel M. Bartels, and Morteza Dehghani. 2025. A Primer for Evaluating Large Language Models in Social-Science Research.Advances in Methods and Practices in Psychological Science8, 2 (2025), 25152459251325174. arXiv:https://doi.org/10.1177/25152459251325174 doi:10.1177/25152459251325174
-
[2]
Muntasir Adnan and Carlos C. N. Kuhn. 2025. Measuring and mitigating debugging effectiveness decay in code language models.Scientific Reports 15, 1 (18 Dec 2025), 44120. doi:10.1038/s41598-025-27846-5
-
[3]
Said Al Faraby, Ade Romadhony, and Adiwijaya. 2024. Analysis of LLMs for educational question classification and generation.Computers and Education: Artificial Intelligence7 (2024), 100298. doi:10.1016/j.caeai.2024.100298
-
[4]
Nourah Alangari and Nouf AlShenaifi. 2025. N&N at QIAS 2025: Chain-of-Thought Ensembles with Retrieval-Augmented framework for Classical Arabic Islamic. InProceedings of The Third Arabic Natural Language Processing Conference: Shared Tasks, Kareem Darwish, Ahmed Ali, Ibrahim Abu Farha, Samia Touileb, Imed Zitouni, Ahmed Abdelali, Sharefah Al-Ghamdi, Sakha...
work page doi:10.18653/v1/2025.arabicnlp-sharedtasks.121 2025
-
[5]
Asma Musabah Alkalbani, Ahmed Salim Alrawahi, Ahmad Salah, Venus Haghighi, Yang Zhang, Salam Alkindi, and Quan Z. Sheng. 2025. A Systematic Review of Large Language Models in Medical Specialties: Applications, Challenges and Future Directions.Information16, 6 (2025). doi:10.3390/info16060489
-
[6]
Santiago Alonso Sousa, Syed Saad Ul Hassan Bukhari, Paulo Vinicius Steagall, Paweł M Bęczkowski, Antonio Giuliano, and Kate J Flay. 2025. Performance of large language models on veterinary undergraduate multiple-choice examinations: a comparative evaluation.Front Vet Sci12 (Aug. 2025), 1616566
2025
-
[7]
Maryam Amirizaniani, Elias Martin, Maryna Sivachenko, Afra Mashhadi, and Chirag Shah. 2024. Can LLMs Reason Like Humans? Assessing Theory of Mind Reasoning in LLMs for Open-Ended Questions. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Computing Machinery, New York...
-
[8]
Richardson, Austin C
Jacy Reese Anthis, Ryan Liu, Sean M. Richardson, Austin C. Kozlowski, Bernard Koch, James Evans, Erik Brynjolfsson, and Michael Bernstein
-
[9]
arXiv:2504.02234 [cs.HC] https://arxiv.org/abs/2504.02234
LLM Social Simulations Are a Promising Research Method. arXiv:2504.02234 [cs.HC] https://arxiv.org/abs/2504.02234
-
[10]
2026.System Card: Claude Opus 4.6
Anthropic. 2026.System Card: Claude Opus 4.6. Technical Report. Anthropic. https://www-cdn.anthropic.com/ 14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf Accessed: 2026-04-14
2026
-
[11]
Luis M. Antunes, Keith T. Butler, and Ricardo Grau-Crespo. 2024. Crystal structure generation with autoregressive large language modeling. Nature Communications15, 1 (06 Dec 2024), 10570. doi:10.1038/s41467-024-54639-7
-
[12]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=hSyW5go0v8
2024
-
[13]
Muhammad Ayoub, Hai Zhao, Lifeng Li, Dongjie Yang, Shabir Hussain, and Junaid Abdul Wahid. 2026. Structured clinical approach to enable large language models to be used for improved clinical diagnosis and explainable reasoning.Communications Medicine6, 1 (Jan. 2026), 86. doi:10.1038/s43856-025-01348-x
-
[14]
Chaithanya Bandi, Ben Hertzberg, Geobio Boo, Tejas Polakam, Jeff Da, Sami Hassaan, Manasi Sharma, Andrew Park, Ernesto Hernandez, Dan Rambado, Ivan Salazar, Rafael Cruz, Chetan Rane, Ben Levin, Brad Kenstler, and Bing Liu. 2026. MCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers. arXiv:2602.00933 [cs.SE] https://arxiv.org/abs...
Pith/arXiv arXiv 2026
-
[15]
Barman, Sascha Caron, Emily Sullivan, Henk W
Kristian G. Barman, Sascha Caron, Emily Sullivan, Henk W. de Regt, Roberto Ruiz de Austri, Mieke Boon, Michael Färber, Stefan Fröse, Tobias Golling, Luis G. Lopez, Faegheh Hasibi, Lukas Heinrich, Andreas Ipp, Rukshak Kapoor, Gregor Kasieczka, Daniel Kostić, Michael Krämer, Jesus Marco, Sydney Otten, Pawel Pawlowski, Pietro Vischia, Erik Weber, and Christo...
-
[16]
Armin Berger, Sarthak Khanna, David Berghaus, and Rafet Sifa. 2025. Reasoning LLMs in the Medical Domain: A Literature Survey.arXiv preprint arXiv:2508.19097(2025)
arXiv 2025
-
[17]
Eloise Berson, Philip Chung, Camilo Espinosa, Thomas J. Montine, and Nima Aghaeepour. 2024. Unlocking human immune system complexity through AI.Nature Methods21 (2024), 1400–1402. doi:10.1038/s41592-024-02351-1
-
[18]
Randolph, Matthew Muhoberac, Palak Manchanda, Katherine A
Connor Beveridge, Sanjay Iyer, Caitlin E. Randolph, Matthew Muhoberac, Palak Manchanda, Katherine A. Walker, Shane Tichy, and Gaurav Chopra. 2025. CLAW-MRM: Comprehensive Lipidomics Automation Workflow for Multiple Reaction Monitoring Using Large Language Models. Analytical Chemistry97, 36 (2025), 19409–19418. arXiv:https://doi.org/10.1021/acs.analchem.4c...
-
[19]
Nathan Bigaud, Vincent Cabeli, Meltem Gürel, Arthur Pignet, John Klein, Gilles Wainrib, and Eric Durand. 2025. OwkinZero: Accelerating Biological Discovery with AI. arXiv:2508.16315 [cs.LG] https://arxiv.org/abs/2508.16315
arXiv 2025
-
[20]
Bran, Sam Cox, Oliver Schilter, et al
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. 2024. Augmenting large language models with chemistry tools.Nature Machine Intelligence(2024). doi:10.1038/s42256-024-00832-8
-
[21]
Fan Bu et al. 2025. An Investigation into Value Misalignment in LLM-Generated Texts for Cultural Heritage.arXiv preprint arXiv:2501.02039(2025). https://arxiv.org/abs/2501.02039
arXiv 2025
-
[22]
Spears, Derya Unutmaz, Kevin Weil, Steven Yin, and Nikita Zhivotovskiy
Sébastien Bubeck, Christian Coester, Ronen Eldan, Timothy Gowers, Yin Tat Lee, Alexandru Lupsasca, Mehtaab Sawhney, Robert Scherrer, Mark Sellke, Brian K. Spears, Derya Unutmaz, Kevin Weil, Steven Yin, and Nikita Zhivotovskiy. 2025. Early science acceleration experiments with GPT-5. arXiv:2511.16072 [cs.CL] https://arxiv.org/abs/2511.16072
arXiv 2025
-
[23]
Quintina Campbell, Sam Cox, Jorge Medina, Brittany Watterson, and Andrew D White. 2025. MDCrow: Automating Molecular Dynamics Workflows with Large Language Models.arXiv preprint arXiv:2502.09565(2025)
arXiv 2025
-
[24]
Jeffrey A. Cardille, Renee Johnston, Simon Ilyushchenko, Johan Kartiwa, Zahra Shamsi, Matthew Abraham, Khashayar Azad, Kainath Ahmed, Emma Bergeron Quick, Nuala Caughie, Noah Jencz, Karen Dyson, Andrea Puzzi Nicolau, Maria Fernanda Lopez-Ornelas, David Saah, Michael Brenner, Subhashini Venugopalan, and Sameera S Ponda. 2025. The Cloud-Based Geospatial Ben...
2025
-
[25]
Alejandro Carrasco, Victor Rodriguez-Fernandez, and Richard Linares. 2025. Large language models as autonomous spacecraft operators in kerbal space program.Advances in Space Research76, 6 (2025), 3480–3497. doi:10.1016/j.asr.2025.06.034
-
[26]
Santiago Casas, Christian Fidler, Boris Bolliet, Francisco Villaescusa-Navarro, and Julien Lesgourgues. 2025. CLAPP: The CLASS LLM Agent for Pair Programming. arXiv:2508.05728 [astro-ph.IM] https://arxiv.org/abs/2508.05728
arXiv 2025
-
[27]
Harry Caufield, Harshad Hegde, Vincent Emonet, et al
J. Harry Caufield, Harshad Hegde, Vincent Emonet, et al. 2024. Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES): a method for populating knowledge bases using zero-shot learning.Bioinformatics40, 3 (2024), btae104. doi:10.1093/bioinformatics/btae104
-
[28]
Ajenifujah, Janghoon Ock, and Amir Barati Farimani
Achuth Chandrasekhara, Omid Barati Farimani, Olabode T. Ajenifujah, Janghoon Ock, and Amir Barati Farimani. 2025. NANOGPT: A Query- Driven Large Language Model Retrieval-Augmented Generation System for Nanotechnology Research.arXiv preprint arXiv:2502.20541(2025). doi:10.48550/arXiv.2502.20541
-
[29]
Sreejato Chatterjee, Linh Tran, Quoc Duy Nguyen, Roni Kirson, Drue Hamlin, Harvest Aquino, Hanjia Lyu, Jiebo Luo, and Timothy Dye. 2025. Assessing Historical Structural Oppression Worldwide via Rule-Guided Prompting of Large Language Models.arXiv preprint arXiv:2509.15216 (2025)
arXiv 2025
-
[30]
Bokai Chen, Weiwei Zheng, Liang Zhao, and Xiaojun Ding. 2025. Leveraging large language models to assist philosophical counseling: prospective techniques, value, and challenges.Humanities and Social Sciences Communications(2025). doi:10.1057/s41599-025-04657-7
-
[31]
Chuke Chen, Nan Li, Jianchuan Qi, Huimin Chang, Wenjie Shi, Jinliang Xie, Jiayi Yuan, Hang Yang, Jing Guo, Changqing Xu, and Ming Xu
-
[32]
Leveraging LLMs for Environmental Complexity: Structured Fine-Tuning Data Sets and Deployment Strategies.Environmental Science & Technology60, 1 (2025)
2025
-
[33]
Cheng-Yeh Chen and Raghupathy Sivakumar. 2026. The Mind’s Transformer: Computational Neuroanatomy of LLM-Brain Alignment. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=PgIlCCNxdB
2026
-
[34]
Danlu Chen et al. 2024. LogogramNLP: Comparing Visual and Textual Representations of Ancient Logographic Writing Systems for NLP. In Findings of the Association for Computational Linguistics: EMNLP 2024. https://arxiv.org/abs/2408.04628
arXiv 2024
-
[35]
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, and Benyou Wang. 2025. Towards Medical Complex Reasoning with LLMs through Medical Verifiable Problems. InFindings of the Association for Computational Linguistics: ACL 2025 / preprint arXiv:2412.18925, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.findings-acl.751 2025
-
[36]
Liuqing Chen, Qianzhi Jing, Yixin Tsang, Qianyi Wang, Lingyun Sun, and Jianxi Luo. 2024. DesignFusion: Integrating Generative Models for Conceptual Design Enrichment.Journal of Mechanical Design146, 11 (05 2024), 111703. doi:10.1115/1.4065487
-
[37]
Mouxiang Chen, Lei Zhang, Yunlong Feng, Xuwu Wang, Wenting Zhao, Ruisheng Cao, Jiaxi Yang, Jiawei Chen, Mingze Li, Zeyao Ma, Hao Ge, Zongmeng Zhang, Zeyu Cui, Dayiheng Liu, Jingren Zhou, Jianling Sun, Junyang Lin, and Binyuan Hui. 2026. SWE-Universe: Scale Real-World Verifiable Environments to Millions. arXiv:2602.02361 [cs.SE] https://arxiv.org/abs/2602....
arXiv 2026
-
[38]
Wei Chen, Han Ding, Meng Yuan, Zhao Zhang, Deqing Wang, and Fuzhen Zhuang. 2025. Bridging Social Psychology and LLM Reasoning: Conflict-Aware Meta-Review Generation via Cognitive Alignment.arXiv preprint arXiv:2503.13879(2025). https://arxiv.org/pdf/2503.13879
arXiv 2025
-
[39]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. 2022. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.arXiv preprint arXiv:2211.12588(2022)
Pith/arXiv arXiv 2022
-
[40]
Zhiyu Chen, Yujie Lu, and William Wang. 2023. Empowering Psychotherapy with Large Language Models: Cognitive Distortion Detection through Diagnosis of Thought Prompting. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 4295–4304....
-
[41]
Zhou Chen, Xiao Wang, Xinan Zhang, Ming Lin, Yuanhong Liao, Juanzi Li, and Yuqi Bai. 2025. GeoFactory: an LLM performance enhancement framework for geoscience factual and inferential tasks.Big Earth Data9, 4 (2025), 714–746. doi:10.1080/20964471.2025.2506291
-
[42]
Zi-Yi Chen, Fan-Kai Xie, Meng Wan, Yang Yuan, Miao Liu, Zong-Guo Wang, Sheng Meng, and Yan-Gang Wang. 2023. MatChat: A large language model and application service platform for materials science.Chinese Physics B32, 11 (nov 2023), 118104. doi:10.1088/1674-1056/ad04cb
-
[43]
Yuheng Cheng, Huan Zhao, Xiyuan Zhou, Junhua Zhao, Yuji Cao, Chao Yang, and Xinlei Cai. 2025. A large language model for advanced power dispatch.Scientific Reports15, 1 (2025), 8925
2025
-
[44]
Byounggook Cho, Gi-Young Lee, Junghyun Jung, Junyeop Kim, GunHo Park, Patrick C. N. Martin, Hyobin Kim, Jeein Oh, Jong-Soo Kim, Jongpil Kim, Tae-Hyung Kim, and Kyoung-Jae Won. 2026. PersonaAI: An Interactive Agentic-AI Framework for Autonomous Hypothesis Generation and Validation in Aging.bioRxiv(2026). doi:10.64898/2026.01.16.699755
-
[45]
Kamal Choudhary. 2025. DiffractGPT: Atomic Structure Determination from X-ray Diffraction Patterns Using a Generative Pretrained Transformer. Journal of Physical Chemistry Letters(2025). doi:10.1021/acs.jpclett.4c03137
-
[46]
Zhendong Chu, Shen Wang, Jian Xie, Tinghui Zhu, Yibo Yan, Jingheng Ye, Aoxiao Zhong, Xuming Hu, Jing Liang, Philip S. Yu, and Qingsong Wen. 2025. LLM Agents for Education: Advances and Applications. InFindings of the Association for Computational Linguistics: EMNLP 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.)...
-
[47]
Daniel J H Chung, Zhiqi Gao, Yurii Kvasiuk, Tianyi Li, Moritz Münchmeyer, Maja Rudolph, Frederic Sala, and Sai Chaitanya Tadepalli. 2025. Theoretical physics benchmark (TPBench)—a dataset and study of AI reasoning capabilities in theoretical physics.Machine Learning: Science and Technology6, 3 (sep 2025), 030505. doi:10.1088/2632-2153/adfcb0
-
[48]
Sergio Cruzes. 2025. Revolutionizing optical networks: The integration and impact of large language models.Optical Switching and Networking57 (2025), 100812
2025
-
[49]
Hao Cui, Zahra Shamsi, Gowoon Cheon, Xuejian Ma, Shutong Li, Maria Tikhanovskaya, Peter Norgaard, Nayantara Mudur, Martyna Plomecka, Paul Raccuglia, Yasaman Bahri, Victor V. Albert, Pranesh Srinivasan, Haining Pan, Philippe Faist, Brian Rohr, Ekin Dogus Cubuk, Muratahan Aykol, Amil Merchant, Michael J. Statt, Dan Morris, Drew Purves, Elise Kleeman, Ruth A...
arXiv 2025
-
[50]
Yiming Cui, X Yao, Y Qin, et al. 2025. Evaluating large language models on multimodal chemistry olympiad exams.Communications Chemistry (2025). doi:10.1038/s42004-025-01782-x
-
[51]
Chongyuan Dai, Jinpeng Hu, Hongchang Shi, Zhuo Li, Xun Yang, and Meng Wang. 2025. Psyche-R1: Towards Reliable Psychological LLMs through Unified Empathy, Expertise, and Reasoning. arXiv:2508.10848 [cs.CL] https://arxiv.org/abs/2508.10848
arXiv 2025
-
[52]
Xi Dai, Yu Xi, Yong Hu, Qingyan Zhao, and Chaoxue Zhang. 2025. LLM Evaluation for Thyroid Nodule Assessment: Comparing ACR-TIRADS, C-TIRADS, and Clinician-AI Trust Gap.Frontiers in Endocrinology16 (2025), 1667809. doi:10.3389/fendo.2025.1667809
-
[53]
Anurag Das, David Kerr, Namino Glantz, Wendy Bevier, Rony Santiago, Ricardo Gutierrez-Osuna, and Bobak Mortazavi. 2025. CGMacros: a pilot scientific dataset for personalized nutrition and diet monitoring.Scientific Data12 (09 2025). doi:10.1038/s41597-025-05851-7
-
[54]
Mattia De Cao et al. 2024. Deep Learning Meets Egyptology: a Hieroglyphic Transformer for Translating Ancient Egyptian. InProceedings of the 1st Workshop on Machine Learning for Ancient Languages. Association for Computational Linguistics. https://aclanthology.org/2024.ml4al-1.9v1.pdf
2024
-
[55]
Tijmen de Haan, Yuan-Sen Ting, Tirthankar Ghosal, Tuan Dung Nguyen, Alberto Accomazzi, Emily Herron, Vanessa Lama, Rui Pan, Azton Wells, and Nesar Ramachandra. 2025. AstroMLab 4: Benchmark-Topping Performance in Astronomy Q&A with a 70B-Parameter Domain-Specialized Reasoning Model. arXiv:2505.17592 [astro-ph.IM] https://arxiv.org/abs/2505.17592
arXiv 2025
-
[56]
Andrea Gregor de Varda, Ferdinando Pio D’Elia, Hope Kean, Andrew Lampinen, and Evelina Fedorenko. 2025. The cost of thinking is similar between large reasoning models and humans.Proceedings of the National Academy of Sciences122, 47 (2025), e2520077122
2025
-
[57]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, et al. 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv:2512.02556 [cs.CL] https://arxiv.org/abs/2512.02556
Pith/arXiv arXiv 2025
-
[58]
Cheng Deng, Tianhang Zhang, Zhongmou He, Yi Xu, Qiyuan Chen, Yuanyuan Shi, Luoyi Fu, Weinan Zhang, Xinbing Wang, Chenghu Zhou, Zhouhan Lin, and Junxian He. 2023. K2: A Foundation Language Model for Geoscience Knowledge Understanding and Utilization. arXiv:2306.05064 doi:10.48550/arXiv.2306.05064 Project page notes acceptance to WSDM 2024 (ACM DOI may be 1...
-
[59]
Gebauer, Henry Alexander Bradley, Dawid Maciorowski, Bria Persaud, Jordan Despanie, et al
Sunishchal Dev, Charles Teague, Grant Ellison, Kyle Brady, Jeffrey Lee, Sarah L. Gebauer, Henry Alexander Bradley, Dawid Maciorowski, Bria Persaud, Jordan Despanie, et al. 2025.Toward Comprehensive Benchmarking of the Biological Knowledge of Frontier Large Language Models. Research Report RRA3797-1. RAND Corporation. 20 Ferdinan et al
2025
-
[60]
Francisco de Arriba Pérez, Silvia García-Méndez, Javier Otero-Mosquera, and Francisco J. González-Castaño. 2024. Explainable cognitive decline detection in free dialogues with a Machine Learning approach based on pre-trained Large Language Models.Applied Intelligence54, 24 (Sept. 2024), 12613–12628. doi:10.1007/s10489-024-05808-0
-
[61]
Mehak Preet Dhaliwal, Andong Hua, Laya Pullela, Ryan Burke, and Yao Qin. 2025. NutriBench: A Dataset for Evaluating Large Language Models in Nutrition Estimation from Meal Descriptions. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/ forum?id=6LtdZCyuZR
2025
-
[62]
Zhehao Dong, Zhen Lu, and Yue Yang. 2025. Fine-tuning a large language model for automating computational fluid dynamics simulations. Theoretical and Applied Mechanics Letters15, 3 (may 2025), 100594. doi:10.1016/j.taml.2025.100594
-
[63]
Filip Dorm, Joseph Millard, Drew Purves, Michael Harfoot, and Oisin Mac Aodha. 2025. Large language models possess some ecological knowledge, but how much?bioRxiv(2025). doi:10.1101/2025.02.10.637097
-
[64]
Dornath, Aditya Balu, Adarsh Krishnamurthy, Asheesh K
A. Dornath, Aditya Balu, Adarsh Krishnamurthy, Asheesh K. Singh, Arti Singh, Baskar Ganapathysubramanian, Chinmay Hegde, and Soumik Sarkar. 2025. Towards Large Reasoning Models for Agriculture.arXiv preprint arXiv:2505.19259(2025). https://arxiv.org/abs/2505.19259
arXiv 2025
-
[65]
Hongru Du, Yang Zhao, Jianan Zhao, Shaochong Xu, Xihong Lin, Yiran Chen, Lauren M. Gardner, and Hao ‘Frank’ Yang. 2025. Advancing real-time infectious disease forecasting using large language models.Nature Computational Science5, 6 (01 Jun 2025), 467–480. doi:10.1038/s43588-025-00798-6
-
[66]
Mengge Du, Yuntian Chen, Zhongzheng Wang, Longfeng Nie, and Dongxiao Zhang. 2024. Large language models for automatic equation discovery of nonlinear dynamics.Physics of Fluids36, 9 (09 2024), 097121. doi:10.1063/5.0224297
-
[67]
Plasek, Ya-Wen Chuang, Liqin Wang, Gad A
Xinsong Du, John Novoa-Laurentiev, Joseph M. Plasek, Ya-Wen Chuang, Liqin Wang, Gad A. Marshall, Stephanie K. Mueller, Frank Chang, Surabhi Datta, Hunki Paek, Bin Lin, Qiang Wei, Xiaoyan Wang, Jingqi Wang, Hao Ding, Frank J. Manion, Jingcheng Du, David W. Bates, and Li Zhou. 2024. Enhancing early detection of cognitive decline in the elderly: a comparativ...
-
[68]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130 [cs.CL] https://arxiv.org/abs/2404.16130
Pith/arXiv arXiv 2025
-
[69]
Ehrlich-Sommer, B
F. Ehrlich-Sommer, B. Eberhard, and A. Holzinger. 2025. ForestGPT and Beyond: A Trustworthy Domain-Specific Large Language Model Paving the Way to Forestry 5.0.Electronics14, 18 (2025), 3583. https://www.mdpi.com/2079-9292/14/18/3583
2025
-
[70]
Zachary Englhardt, Chengqian Ma, Margaret E. Morris, Chun-Cheng Chang, Xuhai "Orson" Xu, Lianhui Qin, Daniel McDuff, Xin Liu, Shwetak Patel, and Vikram Iyer. 2024. From Classification to Clinical Insights: Towards Analyzing and Reasoning About Mobile and Behavioral Health Data With Large Language Models.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol...
-
[71]
European Research Council. 2025. Panel Chairs – ERC Starting Grant 2026. https://erc.europa.eu/system/files/2025-10/Panel_Chairs_ERC_ Starting_Grant_2026.pdf. Accessed: 2026-02-11
2025
-
[72]
Maddison, and BO WANG
Adibvafa Fallahpour, Andrew Magnuson, Purav Gupta, Shihao Ma, Jack Naimer, Arnav Shah, Haonan Duan, Omar Ibrahim, Hani Goodarzi, Chris J. Maddison, and BO WANG. 2025. BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?i...
2025
-
[73]
Ka Siu Fan, Jeffrey Gan, Isabelle Zou, Maja Kaladjiska, Monique Borg Inguanez, and Gillian Garden. 2025. Poor Performance of Large Language Models Based on the Diabetes and Endocrinology Specialty Certificate Examination of the United Kingdom.Cureus17 (10 2025). doi:10.7759/ cureus.93960
2025
-
[74]
Yin Fang, Qiao Jin, Guangzhi Xiong, Bowen Jin, Xianrui Zhong, Siru Ouyang, Aidong Zhang, Jiawei Han, and Zhiyong Lu. 2025. Cell-o1: Training LLMs to Solve Single-Cell Reasoning Puzzles with Reinforcement Learning. arXiv:2506.02911 [cs.CL] https://arxiv.org/abs/2506.02911
arXiv 2025
-
[75]
Dennis Fast, Lisa C. Adams, Felix Busch, Conor Fallon, Marc Huppertz, Robert Siepmann, Philipp Prucker, Nadine Bayerl, Daniel Truhn, Marcus Makowski, Alexander Löser, and Keno K. Bressem. 2024. Autonomous medical evaluation for guideline adherence of large language models.npj Digital Medicine7 (2024), 358. doi:10.1038/s41746-024-01356-6
-
[76]
Daniel Fein, Sebastian Russo, Violet Xiang, Kabir Jolly, Rafael Rafailov, and Nick Haber. 2025. LitBench: A Benchmark and Dataset for Reliable Evaluation of Creative Writing.arXiv preprint arXiv:2507.00769(2025). doi:10.48550/arXiv.2507.00769
-
[77]
Kaiyue Feng, Yilun Zhao, Yixin Liu, Tianyu Yang, Chen Zhao, John Sous, and Arman Cohan. 2025. Physics: Benchmarking Foundation Models on University-Level Physics Problem Solving. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computa...
-
[78]
Yichun Feng, Lu Zhou, Chao Ma, Yikai Zheng, Ruikun He, and Yixue Li. 2025. Knowledge graph–based thought: a knowledge graph–enhanced LLM framework for pan-cancer question answering.GigaScience14 (2025). doi:10.1093/gigascience/giae082
-
[79]
Jingru Gan, Peichen Zhong, Yuanqi Du, Yanqiao Zhu, Chenru Duan, Haorui Wang, Daniel Schwalbe-Koda, Carla P Gomes, Kristin A Persson, and Wei Wang. 2025. MatLLMSearch: Crystal Structure Discovery with Evolution-Guided Large Language Models.arXiv preprint arXiv:2502.20933 (2025)
arXiv 2025
-
[80]
Kanishk Gandhi, J.-Philipp Fränken, Tobias Gerstenberg, and Noah D. Goodman. 2023. Understanding social reasoning in language models with language models. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 595, 12 pages. Reasoning4S...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.