Not All Explanations Simulate Equally: Comparing Verbalized Feature Attributions and Self-Generated Rationales
Pith reviewed 2026-06-28 17:06 UTC · model grok-4.3
The pith
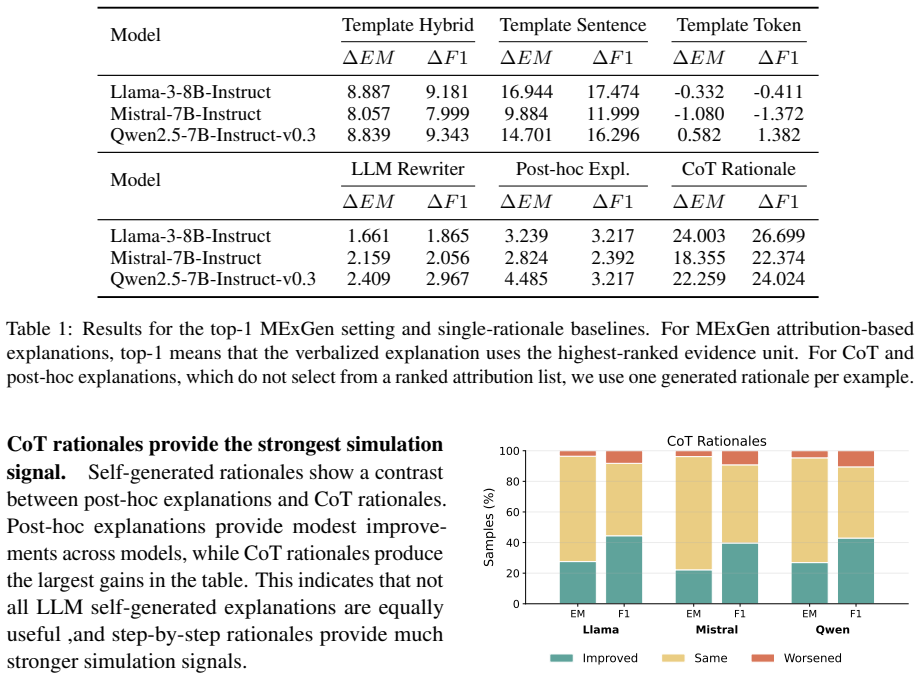
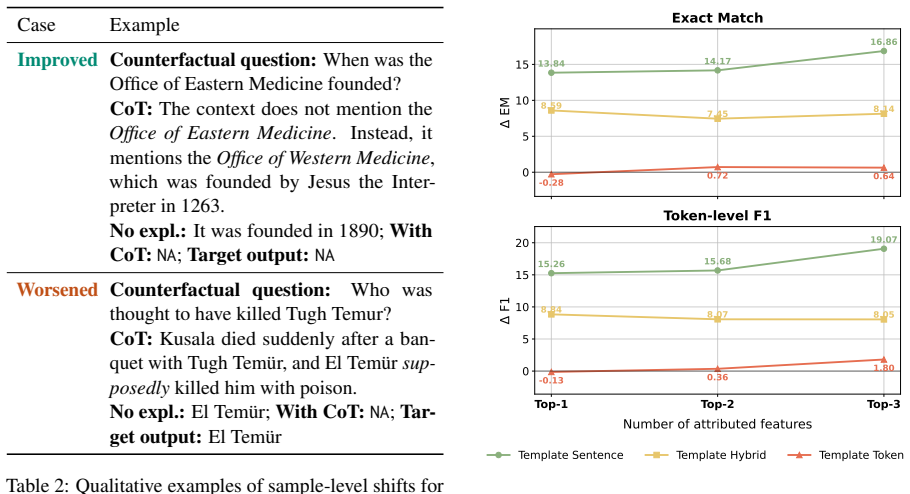
Explanation format and granularity affect how well models can be simulated on counterfactual questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
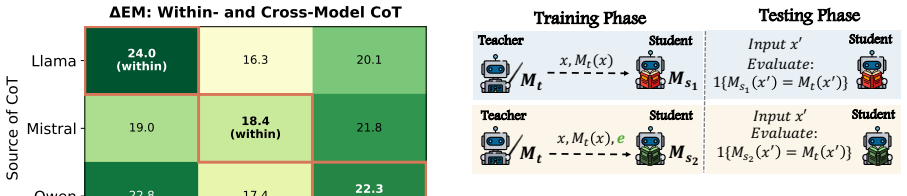
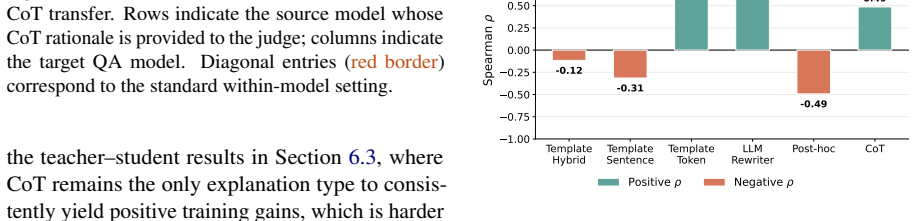
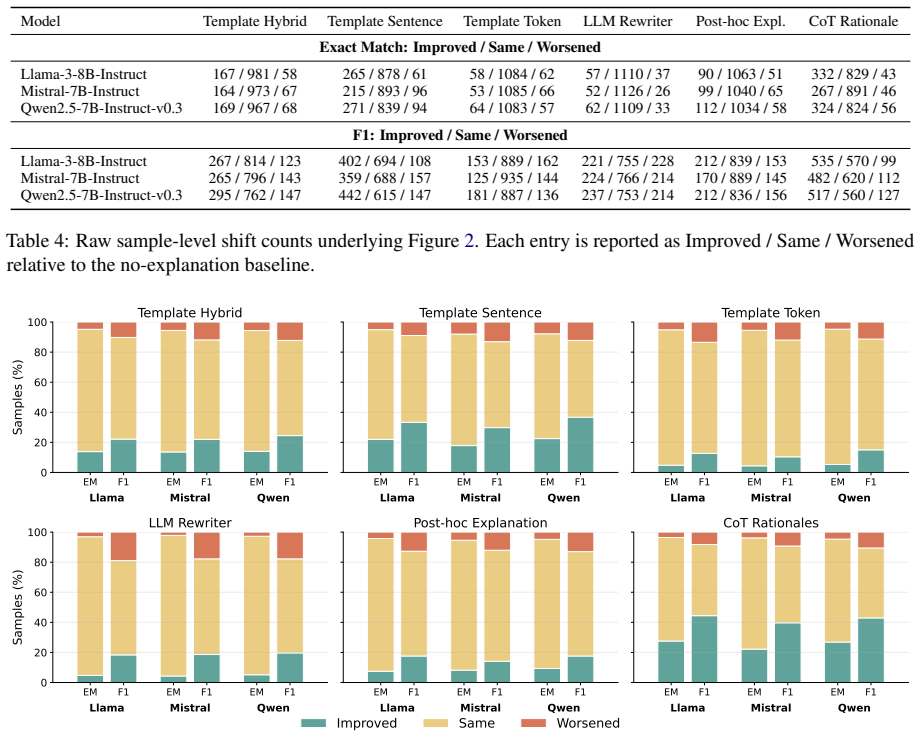
Across multiple instruction-tuned models, verbalized feature attributions and self-generated rationales differ in the amount they improve an LLM judge's ability to predict the target model's answers to counterfactual follow-up questions, with the difference depending on verbalization strategy and feature granularity.
What carries the argument
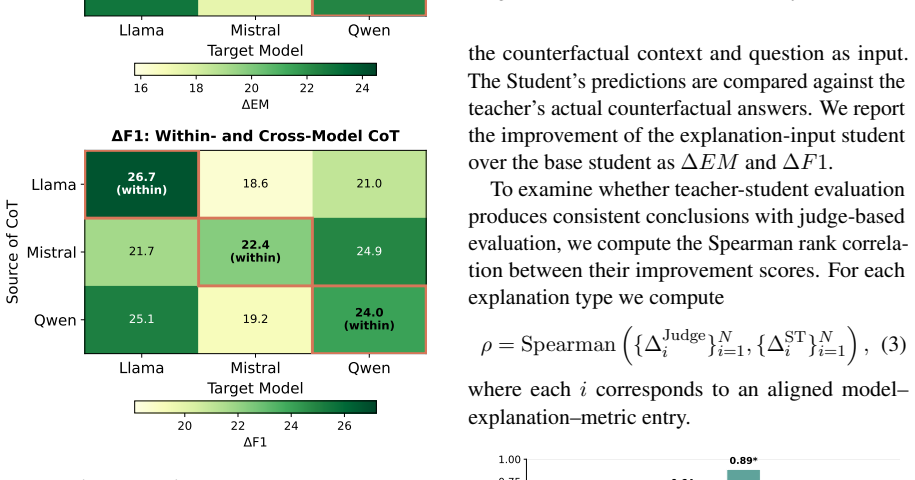
Counterfactual simulation measured by whether an LLM judge can better predict the target model's answers to follow-up questions when given the explanation.
If this is right
- Attribution-based explanations and self-generated rationales are not interchangeable for simulation tasks.
- Feature granularity changes how much an explanation helps counterfactual prediction.
- The relative usefulness of each explanation type varies across different instruction-tuned models.
- Evaluation of explanations should test their effect on simulation rather than treating all natural-language forms as equivalent.
Where Pith is reading between the lines
- Developers may need separate evaluation protocols for attribution-style versus rationale-style explanations.
- The differences could be tested directly with human simulators instead of relying on an LLM judge.
- Hybrid explanations that combine both formats might produce more consistent simulation gains.
Load-bearing premise
An LLM judge gives a valid and reliable measure of whether an explanation lets a reader accurately simulate the target model's answers.
What would settle it
Human participants given the same explanations and follow-up questions achieve prediction accuracy that does not match the LLM judge's accuracy.
Figures

read the original abstract
Natural-language explanations are often treated as a unified interface for understanding model behavior, but different explanation sources may support simulation in different ways. This paper compares two families of explanations for question answering models: verbalized feature attributions and self-generated rationales. We evaluate them under a shared counterfactual simulation setting, using an LLM judge as predictor and measuring whether it can better predict a model's answers to follow-up questions when given its explanation. Across multiple instruction-tuned models, we analyze how explanation source, verbalization strategy, and feature granularity affect the simulatability of explanations. Our results show that explanation format and granularity affect simulatability: attribution-based explanations and self-generated rationales differ in how much they improve counterfactual prediction, with effects that vary across models and formats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares two families of natural-language explanations for question-answering models—verbalized feature attributions and self-generated rationales—under a shared counterfactual simulation protocol. Using an LLM judge as the predictor, it measures whether providing an explanation improves the judge’s accuracy at forecasting the target model’s answers to follow-up questions, and reports that explanation source, verbalization strategy, and feature granularity produce measurable differences in simulatability that vary across instruction-tuned models.
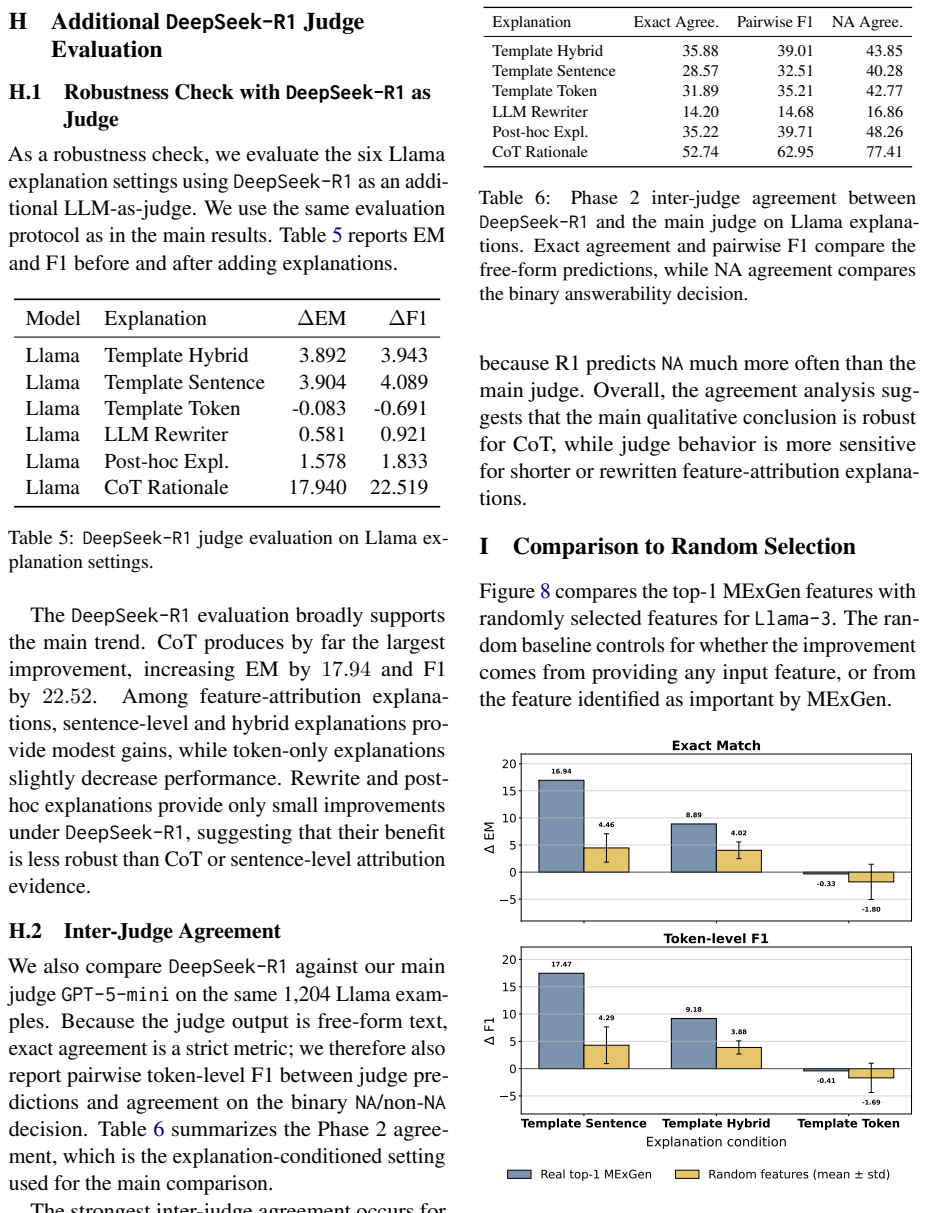
Significance. If the reported differences are shown to be robust to the choice of judge, the work would usefully demonstrate that explanation formats are not interchangeable for simulation-based interpretability tasks and would supply concrete guidance on granularity and source selection. The absence of any validation of the LLM-judge metric against human performance or direct model access, however, leaves the practical significance of the format/granularity effects uncertain.
major comments (1)
- [Abstract] Abstract (and the evaluation protocol described therein): the central claim that attribution-based explanations and self-generated rationales differ in simulatability rests on accuracy differences produced by an LLM judge. No calibration against human judges, no inter-judge agreement statistics, and no direct-model-access baseline are mentioned, so it is impossible to determine whether the observed format effects track genuine simulation improvement or judge-specific artifacts.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the evaluation protocol. We address the concern regarding validation of the LLM judge below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the evaluation protocol described therein): the central claim that attribution-based explanations and self-generated rationales differ in simulatability rests on accuracy differences produced by an LLM judge. No calibration against human judges, no inter-judge agreement statistics, and no direct-model-access baseline are mentioned, so it is impossible to determine whether the observed format effects track genuine simulation improvement or judge-specific artifacts.
Authors: We acknowledge that the manuscript does not include calibration of the LLM judge against human performance, inter-judge agreement statistics, or an explicit direct-model-access baseline, which limits claims about the metric's fidelity to human simulation. This is a genuine gap. We will revise the abstract to clarify that the LLM judge serves as a scalable proxy for simulation-based evaluation and add a dedicated limitations subsection discussing the risk of judge-specific artifacts. We will also report results using a second, distinct LLM judge to provide an initial robustness check on whether format and granularity effects persist. The no-explanation condition already functions as a baseline measuring the judge's unaided predictive accuracy. A direct-model-access baseline is not applicable to the simulation protocol, whose purpose is to assess how well explanations enable prediction without querying the target model; however, we will note in the revision that future work could correlate judge predictions against actual target-model outputs on held-out counterfactuals. The fact that explanation effects vary systematically across different target models (while using the same judge) provides some evidence that the differences are not solely judge artifacts, but we agree this does not substitute for human validation. revision: partial
Circularity Check
No significant circularity in empirical comparison study
full rationale
This is an empirical comparison of explanation formats (attribution-based vs. self-generated rationales) evaluated via counterfactual simulation with an LLM judge. No equations, fitted parameters, or self-citations are described that reduce any result to its inputs by construction. The central claims rest on experimental outcomes across models rather than definitional or self-referential reductions, so the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics
Leakage-adjusted simulatability: Can models generate non-trivial explanations of their behavior in natural language? InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4351–4367, Online. Association for Computational Linguistics. Pingjun Hong and Benjamin Roth. 2026. Do LLM self-explanations help users predict model behavior? E...
-
[2]
Tim Miller
A positive case for faithfulness: LLM self- explanations help predict model behavior. Tim Miller. 2018. Explanation in artificial intelligence: Insights from the social sciences. Lucas Monteiro Paes, Dennis Wei, Hyo Jin Do, Hendrik Strobelt, Ronny Luss, Amit Dhurandhar, Manish Na- gireddy, Karthikeyan Natesan Ramamurthy, Prasanna Sattigeri, Werner Geyer, ...
2018
-
[3]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Show your work: Scratchpads for interme- diate computation with language models.ArXiv, abs/2112.00114. Dong Huk Park, Lisa Anne Hendricks, Zeynep Akata, Anna Rohrbach, Bernt Schiele, Trevor Darrell, and Marcus Rohrbach. 2018. Multimodal explanations: Justifying decisions and pointing to the evidence. 2018 IEEE/CVF Conference on Computer Vision and Pattern...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Evaluating explanations: How much do expla- nations from the teacher aid students? 10:359–375. Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, ...
2025
-
[5]
Why should I trust you?
“Why should I trust you?”: Explaining the pre- dictions of any classifier. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demon- strations, pages 97–101, San Diego, California. As- sociation for Computational Linguistics. Alexis Ross, Ana Marasovi´c, and Matthew Peters. 2021. Explaining...
2016
-
[6]
Faithcot-bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning.ArXiv, abs/2510.04040. Aaditya Singh, Adam Fry, Adam Perelman, and et al
-
[7]
Openai gpt-5 system card. Miles Turpin, Julian Michael, Ethan Perez, and Sam Bowman. 2023. Language models don’t always say what they think: Unfaithful explanations in chain-of- thought prompting.ArXiv, abs/2305.04388. Dennis Wei, Ronny Luss, Xiaomeng Hu, Lucas Mon- teiro Paes, Pin-Yu Chen, Karthikeyan Natesan Rama- murthy, Erik Miehling, Inge Vejsbjerg, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
The model appears to rely on
Measuring association between labels and free-text rationales. InProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, pages 10266–10284, Online and Punta Cana, Dominican Republic. Association for Compu- tational Linguistics. Tongshuang Wu, Marco Tulio Ribeiro, Jeffrey Heer, and Daniel Weld. 2021. Polyjuice: Generating ...
2021
-
[9]
{selected sentence 1}
-
[10]
{selected sentence 2, if used}
-
[11]
{selected sentence 3, if used} Important tokens/phrases:
-
[12]
{selected token or phrase 1}
-
[13]
{selected token or phrase 2, if used}
-
[14]
answer":
{selected token or phrase 3, if used} Task: Write one fluent explanation of why the model predicted the answer, grounding it in the important sentence evi- dence and highlighting the important tokens or phrases. Output: EXPLANATION: <one concise rewritten explanation> C Prompts for Self-Generated Explanations We use two prompting strategies to collect sel...
2014
-
[15]
The same experimental setting is used for the robustness evaluation withDeepSeek-R1
The default OpenAI-compatible backend uses GPT-5-mini with a maximum generation length of 512 tokens. The same experimental setting is used for the robustness evaluation withDeepSeek-R1. The judge output is parsed by extracting the first non-empty line after the string PREDICTION:. We normalize common no-answer strings such as NA, N/A, not answerable , un...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.