Thinking Economically: A Hierarchical Framework for Adaptive-Complexity Reasoning in LLMs
Pith reviewed 2026-06-28 17:03 UTC · model grok-4.3
The pith
Hierarchical Adaptive Budgeter (HAB) lets LLMs allocate reasoning effort adaptively across problems and steps, outperforming uniform Chain-of-Thought in both accuracy and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
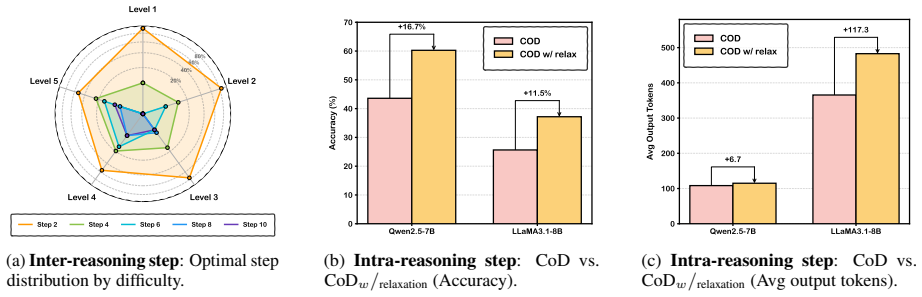
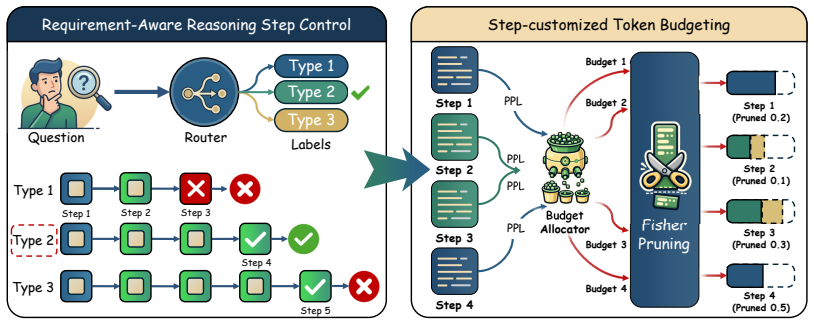
HAB is a training framework that predicts optimal reasoning depth for each problem at the inter-step level and learns step-specific token budgets at the intra-step level from PPL-derived comparisons together with an adaptive Pareto optimization objective, while a Fisher Information-based pruner supplies fine-grained guidance; this allows the generator to internalize economical reasoning and produces stronger accuracy-token trade-offs than standard CoT on GSM8K and MATH500.
What carries the argument
Hierarchical Adaptive Budgeter (HAB) with inter-step depth prediction and intra-step token budgeting driven by PPL comparisons, adaptive Pareto optimization, and Fisher Information pruning.
If this is right
- Models trained this way surpass standard CoT in accuracy on math benchmarks while using fewer tokens.
- The adaptive Pareto objective captures local quality-efficiency trade-offs at each step.
- Fisher Information pruning provides training-time signals that encourage economical reasoning patterns.
- Coarse-to-fine budgeting avoids the uniform compression used in prior efficiency methods.
Where Pith is reading between the lines
- Adaptive budgeting principles could extend to non-math reasoning tasks where overthinking also occurs.
- Integrating such mechanisms might lower the overall computational cost of deploying reasoning LLMs at scale.
- The two-granularity heterogeneity assumption suggests that single-level compression methods will remain suboptimal.
Load-bearing premise
Reasoning complexity is heterogeneous at two distinct granularities and PPL-derived step comparisons plus the adaptive Pareto objective can reliably capture the local quality-efficiency trade-off.
What would settle it
Running HAB on a dataset of problems with uniform reasoning complexity and finding no accuracy gain or token reduction relative to standard CoT.
Figures


read the original abstract
Chain-of-Thought (CoT) has significantly enhanced LLM reasoning, yet often incurs substantial computational overhead due to "overthinking": generating excessively long rationales without commensurate accuracy gains. Existing efficiency methods typically apply uniform compression, which overlooks a critical observation that reasoning complexity is heterogeneous at two distinct granularity: across different problems and within individual reasoning steps. This motivates our principle of Thinking Economically: intelligently allocating computational resources based on intrinsic task and step demands rather than pursuing uniform brevity. We propose Hierarchical Adaptive Budgeter (HAB), a training framework that operationalizes this principle through coarse-to-fine budgeting. At the inter-step level, HAB predicts the optimal reasoning depth for each problem. At the intra-step level, HAB learns step-specific token budgeting signals from PPL-derived step comparisons and an adaptive Pareto optimization objective that captures the local quality-efficiency trade-off, while a Fisher Information-based pruner further provides fine-grained training-time guidance, thereby encouraging the generator to internalize more economical reasoning patterns. Experiments on GSM8K and MATH500 show that HAB not only surpasses standard CoT in accuracy but also reduces token usage, achieving a stronger performance-efficiency trade-off than the compared baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hierarchical Adaptive Budgeter (HAB), a training framework for LLMs that implements 'Thinking Economically' by allocating compute via coarse-to-fine budgeting: inter-step prediction of optimal reasoning depth per problem, and intra-step token budgeting learned from PPL-derived step comparisons plus an adaptive Pareto optimization objective (with Fisher Information pruner for training guidance). Experiments on GSM8K and MATH500 claim that HAB exceeds standard CoT in accuracy while reducing token usage and achieving a superior accuracy-token trade-off versus baselines.
Significance. If the empirical gains are robust and the PPL-based intra-step signals are shown to track reasoning utility rather than mere predictability, the hierarchical budgeting principle could meaningfully advance efficiency methods beyond uniform compression. The work explicitly targets heterogeneity at both problem and step granularities, which is a plausible source of overthinking; reproducible code or ablations isolating the Pareto objective would strengthen its contribution.
major comments (2)
- [Abstract / intra-step budgeting description] Abstract and methods (intra-step component): the central attribution of accuracy gains plus token reduction to the hierarchical principle rests on PPL-derived step comparisons serving as a reliable proxy for local quality-efficiency trade-offs. Perplexity measures next-token predictability under the model distribution, not logical validity or contribution to final answer correctness; without explicit correlation analysis or ablations on GSM8K/MATH500 showing that lower-PPL steps improve downstream accuracy, the Pareto optimization may be optimizing the wrong objective, undermining the claim that HAB internalizes more economical patterns.
- [Abstract / adaptive Pareto optimization] Abstract (adaptive Pareto objective): parameters of the adaptive Pareto optimization are learned from the same data used to evaluate the final performance-efficiency trade-off. This creates a potential circularity that must be resolved by describing the exact optimization procedure, whether validation splits are held out, or how the objective avoids post-hoc selection; otherwise the reported stronger trade-off cannot be confidently attributed to the budgeting principle rather than fitting artifacts.
minor comments (2)
- [Abstract] The abstract states 'reasoning complexity is heterogeneous at two distinct granularity' (should be 'granularities').
- [Experiments] No error bars, number of runs, or statistical significance tests are mentioned for the accuracy and token-usage claims; these should be added to support the 'surpasses' and 'stronger trade-off' statements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the two major comments point-by-point below and will revise the manuscript to provide the requested clarifications and analyses.
read point-by-point responses
-
Referee: [Abstract / intra-step budgeting description] Abstract and methods (intra-step component): the central attribution of accuracy gains plus token reduction to the hierarchical principle rests on PPL-derived step comparisons serving as a reliable proxy for local quality-efficiency trade-offs. Perplexity measures next-token predictability under the model distribution, not logical validity or contribution to final answer correctness; without explicit correlation analysis or ablations on GSM8K/MATH500 showing that lower-PPL steps improve downstream accuracy, the Pareto optimization may be optimizing the wrong objective, undermining the claim that HAB internalizes more economical patterns.
Authors: We acknowledge that perplexity fundamentally reflects next-token predictability rather than logical validity. In the current manuscript, the PPL-derived comparisons are used to identify lower-cost step variants that preserve answer correctness in aggregate, as evidenced by the reported accuracy gains alongside token reductions. However, we agree that an explicit correlation study between PPL signals and downstream accuracy would strengthen the justification. In the revision we will add such an analysis (including step-level accuracy correlations and ablations removing the PPL component) on both GSM8K and MATH500. revision: yes
-
Referee: [Abstract / adaptive Pareto optimization] Abstract (adaptive Pareto objective): parameters of the adaptive Pareto optimization are learned from the same data used to evaluate the final performance-efficiency trade-off. This creates a potential circularity that must be resolved by describing the exact optimization procedure, whether validation splits are held out, or how the objective avoids post-hoc selection; otherwise the reported stronger trade-off cannot be confidently attributed to the budgeting principle rather than fitting artifacts.
Authors: We agree that a clear description of the optimization procedure and data splits is required. The adaptive Pareto objective is optimized on a held-out validation portion of the training data, with final performance reported on the standard test splits of GSM8K and MATH500. We will expand the methods section to specify the exact training/validation split ratios, the optimization schedule, and confirmation that no test-set information influences the Pareto parameters. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes HAB as a new training framework that uses PPL-derived step comparisons and an adaptive Pareto objective for intra-step token budgeting, alongside inter-step depth prediction and Fisher pruning. It then reports empirical results on GSM8K and MATH500 showing accuracy gains and token reductions versus CoT baselines. No load-bearing derivation step is exhibited that reduces by construction to its own inputs via equations, fitted parameters renamed as predictions, or self-citation chains. The central performance-efficiency claims rest on external experimental measurements rather than tautological redefinitions, so the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[3]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Graph of thoughts: Solving elaborate problems with large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[7]
arXiv preprint arXiv:2412.16964 , year=
System-2 Mathematical Reasoning via Enriched Instruction Tuning , author=. arXiv preprint arXiv:2412.16964 , year=
-
[8]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Do not think that much for 2+ 3=? on the overthinking of o1-like llms , author=. arXiv preprint arXiv:2412.21187 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Stop overthinking: A survey on efficient reasoning for large language models , author=. arXiv preprint arXiv:2503.16419 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2501.12570 , year=
O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reasoning Pruning , author=. arXiv preprint arXiv:2501.12570 , year=
-
[11]
arXiv preprint arXiv:2503.10460 , year=
Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond , author=. arXiv preprint arXiv:2503.10460 , year=
-
[12]
arXiv preprint arXiv:2502.12067 , year=
Tokenskip: Controllable chain-of-thought compression in llms , author=. arXiv preprint arXiv:2502.12067 , year=
-
[13]
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Codi: Compressing chain-of-thought into continuous space via self-distillation , author=. arXiv preprint arXiv:2502.21074 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2502.12134 , year=
Softcot: Soft chain-of-thought for efficient reasoning with llms , author=. arXiv preprint arXiv:2502.12134 , year=
-
[15]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Compressed chain of thought: Efficient reasoning through dense representations , author=. arXiv preprint arXiv:2412.13171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Training Large Language Models to Reason in a Continuous Latent Space
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[18]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Navigate through Enigmatic Labyrinth A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Towards Reasoning in Large Language Models: A Survey , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[20]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2402.10400 , year=
Chain of logic: Rule-based reasoning with large language models , author=. arXiv preprint arXiv:2402.10400 , year=
-
[22]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Symbolic Chain-of-Thought Distillation: Small Models Can Also “Think” Step-by-Step , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[24]
Advances in Neural Information Processing Systems , volume=
Lst: Ladder side-tuning for parameter and memory efficient transfer learning , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:2503.04472 , year=
Dast: Difficulty-adaptive slow-thinking for large reasoning models , author=. arXiv preprint arXiv:2503.04472 , year=
-
[26]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Demystifying Long Chain-of-Thought Reasoning in LLMs
Demystifying Long Chain-of-Thought Reasoning in LLMs , author=. arXiv preprint arXiv:2502.03373 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
arXiv preprint arXiv:2502.15589 , year=
Lightthinker: Thinking step-by-step compression , author=. arXiv preprint arXiv:2502.15589 , year=
-
[29]
arXiv preprint arXiv:2503.01422 , year=
Sampling-efficient test-time scaling: Self-estimating the best-of-n sampling in early decoding , author=. arXiv preprint arXiv:2503.01422 , year=
-
[30]
arXiv preprint arXiv:2411.01855 , year=
Can language models learn to skip steps? , author=. arXiv preprint arXiv:2411.01855 , year=
-
[31]
Efficient Reasoning with Hidden Thinking
Efficient Reasoning with Hidden Thinking , author=. arXiv preprint arXiv:2501.19201 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2310.05393 , year=
Hierarchical side-tuning for vision transformers , author=. arXiv preprint arXiv:2310.05393 , year=
-
[33]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[34]
IEEE Access , volume=
Symbiotic Tuning: A Simple Approach for Enhancing Task Performance of Side-Tuning , author=. IEEE Access , volume=. 2025 , publisher=
2025
-
[35]
Procedia Computer Science , volume=
Ladder fine-tuning approach for sam integrating complementary network , author=. Procedia Computer Science , volume=. 2024 , publisher=
2024
-
[36]
The eleventh international conference on learning representations , year=
Automatic chain of thought prompting in large language models , author=. The eleventh international conference on learning representations , year=
-
[37]
Eric Zelikman and Yuhuai Wu and Jesse Mu and Noah Goodman , booktitle=
-
[38]
Advances in Neural Information Processing Systems , volume=
Can Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales? , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Iteration head: A mechanistic study of chain-of-thought , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
arXiv preprint arXiv:2501.09804 , year=
Enhancing Generalization in Chain of Thought Reasoning for Smaller Models , author=. arXiv preprint arXiv:2501.09804 , year=
-
[41]
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Multimodal chain-of-thought reasoning: A comprehensive survey , author=. arXiv preprint arXiv:2503.12605 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
The Thirteenth International Conference on Learning Representations , year=
Unicott: A unified framework for structural chain-of-thought distillation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[43]
Proceedings of the National Academy of Sciences , volume=
Origins of the brain networks for advanced mathematics in expert mathematicians , author=. Proceedings of the National Academy of Sciences , volume=. 2016 , publisher=
2016
-
[44]
NeuroImage , volume=
A distinct cortical network for mathematical knowledge in the human brain , author=. NeuroImage , volume=. 2019 , publisher=
2019
-
[45]
arXiv preprint arXiv:2411.19943 , year=
Critical Tokens Matter: Token-Level Contrastive Estimation Enhence LLM's Reasoning Capability , author=. arXiv preprint arXiv:2411.19943 , year=
-
[46]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
arXiv preprint arXiv:2502.20122 , year=
Self-training elicits concise reasoning in large language models , author=. arXiv preprint arXiv:2502.20122 , year=
-
[49]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
From explicit cot to implicit cot: Learning to internalize cot step by step , author=. arXiv preprint arXiv:2405.14838 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Token-budget-aware llm reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[51]
arXiv preprint arXiv:2505.15778 , year=
Soft thinking: Unlocking the reasoning potential of llms in continuous concept space , author=. arXiv preprint arXiv:2505.15778 , year=
-
[52]
arXiv preprint arXiv:2502.18600 , year=
Chain of draft: Thinking faster by writing less , author=. arXiv preprint arXiv:2502.18600 , year=
-
[53]
arXiv preprint arXiv:2503.01141 , year=
How well do llms compress their own chain-of-thought? a token complexity approach , author=. arXiv preprint arXiv:2503.01141 , year=
-
[54]
2024 2nd International Conference on Foundation and Large Language Models (FLLM) , pages=
The benefits of a concise chain of thought on problem-solving in large language models , author=. 2024 2nd International Conference on Foundation and Large Language Models (FLLM) , pages=. 2024 , organization=
2024
-
[55]
Advances in Neural Information Processing Systems , volume=
Unlocking the capabilities of thought: A reasoning boundary framework to quantify and optimize chain-of-thought , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
arXiv preprint arXiv:2307.15337 , year=
Skeleton-of-thought: Prompting llms for efficient parallel generation , author=. arXiv preprint arXiv:2307.15337 , year=
-
[57]
arXiv preprint arXiv:2503.05179 , year=
Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching , author=. arXiv preprint arXiv:2503.05179 , year=
-
[58]
arXiv preprint arXiv:2502.13260 , year=
Stepwise perplexity-guided refinement for efficient chain-of-thought reasoning in large language models , author=. arXiv preprint arXiv:2502.13260 , year=
-
[59]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
C3ot: Generating shorter chain-of-thought without compromising effectiveness , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[60]
arXiv preprint arXiv:2010.02180 , year=
Pareto probing: Trading off accuracy for complexity , author=. arXiv preprint arXiv:2010.02180 , year=
-
[61]
Advances in neural information processing systems , volume=
Pareto multi-task learning , author=. Advances in neural information processing systems , volume=
-
[62]
Transactions of the Association for Computational Linguistics , volume=
Autopeft: Automatic configuration search for parameter-efficient fine-tuning , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[63]
International Conference on Machine Learning , pages=
Group fisher pruning for practical network compression , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[64]
Quantum Machine Intelligence , volume=
Adaptive pruning algorithm using a quantum Fisher information matrix for parameterized quantum circuits , author=. Quantum Machine Intelligence , volume=. 2024 , publisher=
2024
-
[65]
Neural computation , volume=
Mutual information, Fisher information, and population coding , author=. Neural computation , volume=. 1998 , publisher=
1998
-
[66]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[67]
Advances in neural information processing systems , volume=
Multi-task learning as multi-objective optimization , author=. Advances in neural information processing systems , volume=
-
[68]
arXiv preprint arXiv:2007.08124 , year=
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning , author=. arXiv preprint arXiv:2007.08124 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.