PairedGTA: Generating Driving Datasets for Controlled Photometric Shift Analysis
Pith reviewed 2026-06-28 17:21 UTC · model grok-4.3
The pith
A GTA-based framework produces perfectly paired driving images that differ only in weather and lighting to isolate photometric effects on perception models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
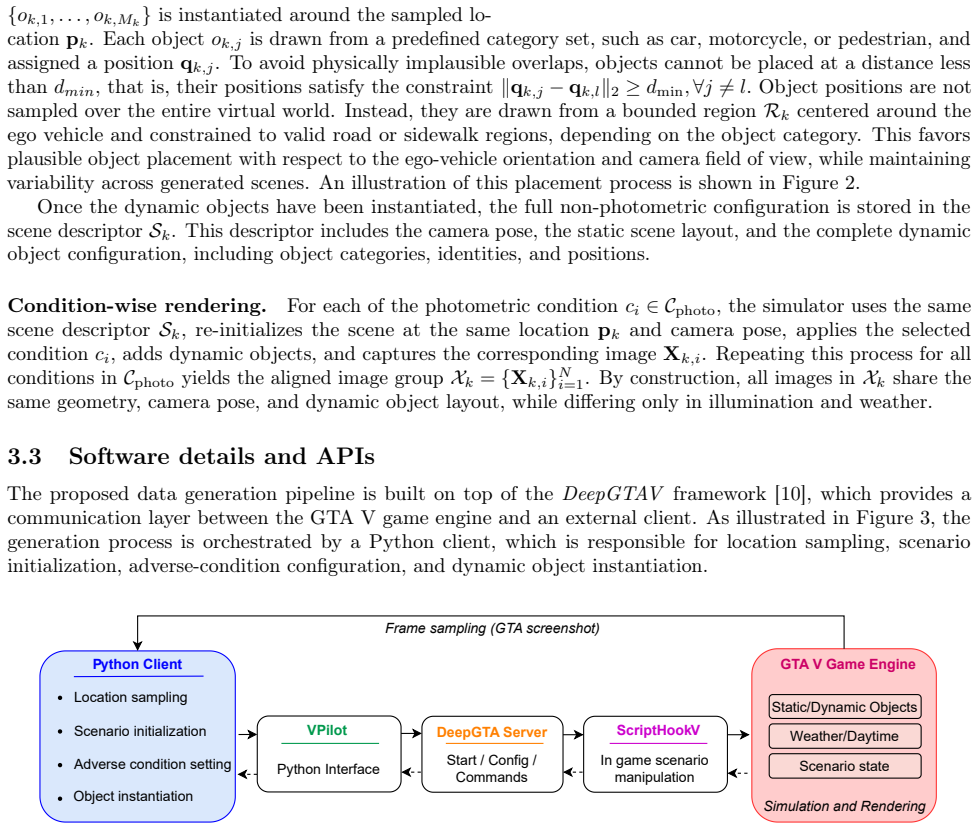
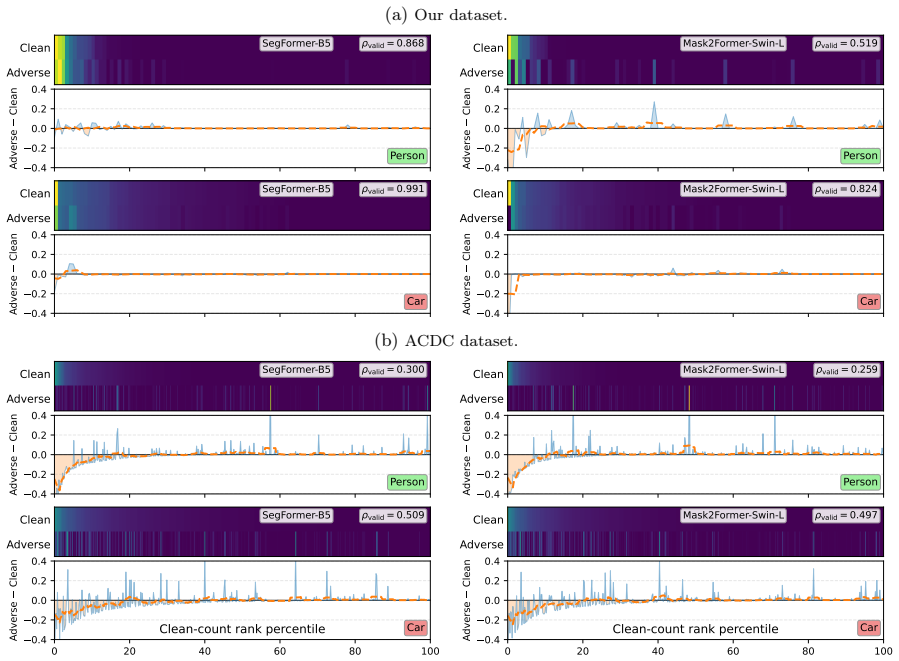
By leveraging software APIs that communicate with the GTA game engine, the framework modifies illumination and weather conditions while preserving scene geometry, camera pose, and the identity and placement of dynamic objects. For each sampled location, it procedurally instantiates dynamic entities and renders pixel-aligned images under diverse adverse conditions. The benefit of the proposed generation framework in driving scenarios is demonstrated through a systematic analysis of semantic segmentation models, whose output degradation can be attributed more directly to photometric shifts rather than to uncontrolled semantic or geometric factors.
What carries the argument
Procedural instantiation and rendering inside the GTA engine that changes only photometric parameters while fixing all other scene elements.
If this is right
- Semantic segmentation output changes can be attributed more directly to photometric shifts.
- Systematic evaluation of perception models becomes possible across many adverse conditions without confounding geometric or semantic variation.
- Pixel-aligned image sets allow controlled measurement of model robustness to illumination and weather alone.
- The generated data supports analysis that separates photometric from layout-related sources of error in autonomous driving perception.
Where Pith is reading between the lines
- The same paired-generation technique could be applied to other perception tasks such as object detection or optical flow to check whether photometric sensitivity is task-dependent.
- If the synthetic shifts prove close enough to real ones, the datasets could serve as a cheap way to augment scarce real paired data for robustness training.
- The framework implicitly suggests that game-engine control over rendering parameters offers a route to test camera-invariant features without collecting new physical footage.
Load-bearing premise
The assumption that photometric shifts produced inside the GTA engine affect perception models in ways that represent real-world camera behavior.
What would settle it
A side-by-side test in which the same segmentation model is run on both PairedGTA pairs and any real-world driving pairs captured under matching condition changes; if degradation patterns diverge sharply, the claim that the synthetic pairs isolate representative photometric effects would be weakened.
Figures




read the original abstract
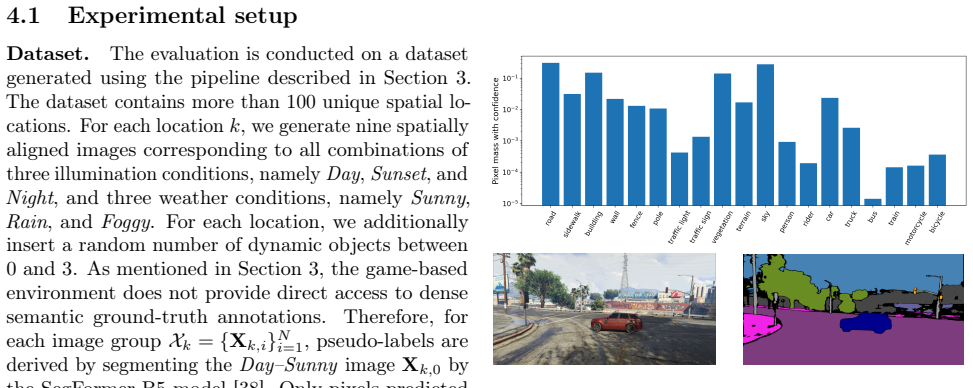
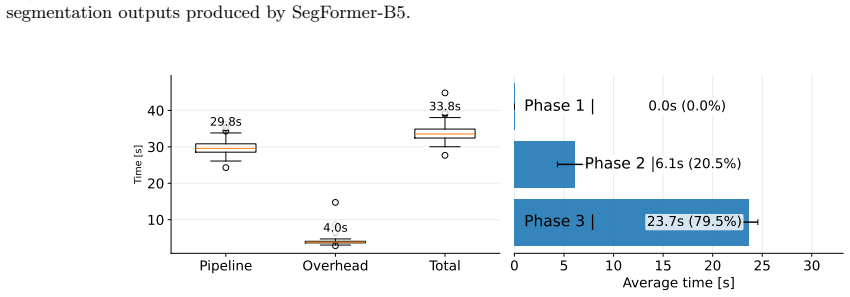
Evaluating the performance of visual perception systems for autonomous driving is essential to ensure reliable operation across diverse environmental scenarios. Ideally, a balanced and fair analysis across different adverse conditions would require perfectly paired images of the same scene under different weather or illumination changes. This would allow evaluating the effect of photometric shifts independently of geometry and semantic changes. Unfortunately, real-world datasets rarely provide images of the same scene under different environmental conditions, because, normally, camera pose, traffic, and locations of dynamic objects (vehicles, pedestrians, etc.) vary over time, thus yielding only coarsely paired data. To address this challenge, this work introduces a data generation framework based on a high-fidelity game engine for extracting perfectly paired images. By leveraging software APIs that communicate with the GTA game engine, the framework modifies illumination and weather conditions while preserving scene geometry, camera pose, and the identity and placement of dynamic objects. For each sampled location, it procedurally instantiates dynamic entities and renders pixel-aligned images under diverse adverse conditions. The benefit of the proposed generation framework in driving scenarios is demonstrated through a systematic analysis of semantic segmentation models, whose output degradation can be attributed more directly to photometric shifts rather than to uncontrolled semantic or geometric factors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PairedGTA, a framework that uses GTA game engine APIs to generate perfectly paired driving-scene images under controlled changes in illumination and weather. The method procedurally instantiates dynamic objects at sampled locations and renders multiple pixel-aligned images while holding scene geometry, camera pose, and object identities/placements fixed, enabling analysis of semantic segmentation degradation attributable to photometric shifts rather than geometric or semantic confounders.
Significance. If the generated pairs function as described, the framework supplies a controlled testbed for isolating photometric effects on perception models, addressing a practical limitation of real-world driving datasets that rarely contain exact scene matches across conditions. The procedural instantiation step is a concrete engineering contribution that could support reproducible robustness studies in autonomous driving.
major comments (1)
- [Abstract] Abstract: the claim that the framework 'demonstrates' the benefit for semantic segmentation analysis is unsupported by any quantitative results, error metrics, or comparison to real data in the provided description, leaving the utility claim only partially substantiated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the framework's utility for controlled photometric analysis. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the framework 'demonstrates' the benefit for semantic segmentation analysis is unsupported by any quantitative results, error metrics, or comparison to real data in the provided description, leaving the utility claim only partially substantiated.
Authors: We agree that the abstract, as a concise summary, does not itself contain quantitative metrics or direct comparisons. The manuscript body (Sections 4–5) presents the systematic analysis with mIoU and per-class degradation metrics across controlled photometric conditions on multiple segmentation models. To resolve the concern, we will revise the abstract wording to state that the benefit 'is demonstrated through systematic analysis' (removing any implication that metrics appear in the abstract) and will ensure the claim is fully supported by the experiments section. No comparison to real data is claimed or required, as the contribution is the controlled synthetic pairs themselves. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a procedural framework for generating paired driving images via GTA engine APIs that control illumination/weather while fixing geometry, pose, and object placement. No equations, fitted parameters, predictions, or derivation chain exist in the provided text; the central mechanism is a direct engineering construction whose correctness does not reduce to self-definition or self-citation. External validity of the generated shifts is a separate question outside the pairing mechanism itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The GTA game engine rendering produces photometric shifts whose impact on perception models is representative of real-world conditions.
Reference graph
Works this paper leans on
-
[1]
Night-to-Day Image Translation for Retrieval-based Localization
A. Anoosheh, T. Sattler, R. Timofte, M. Pollefeys, and L. Van Gool. Night-to-day image translation for retrieval-based localization.arXiv preprint arXiv:1809.09767, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
S. Baik, S. Kim, and E. Kim. Weatherflux: Universal weather translation with diffusion models.ICLR, 2025
2025
-
[3]
Ben-David, J
S. Ben-David, J. Blitzer, K. Crammer, and F. Pereira. A theory of learning from different domains.Machine Learning, 79(1–2):151–175, 2010
2010
-
[4]
Cao and R
M. Cao and R. Ramezani. Data generation using simulation technology to improve perception mechanism of autonomous vehicles, 2022
2022
-
[5]
L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. InECCV, 2018
2018
-
[6]
Cheng, I
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar. Masked-attention mask transformer for universal image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022
2022
-
[7]
Cordts, M
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[8]
B. H. K. Czarnecki and S. Waslander. Precise synthetic image and lidar (presil) dataset for autonomous vehicle perception.Computer Vision and Pattern Recognition, arXiv:1905.00160, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[9]
D’Amico, F
G. D’Amico, F. Nesti, G. Rossolini, M. Marinoni, S. Sabina, and G. Buttazzo. Syndra: Synthetic dataset for railway applications. InProceedings of the Winter Conference on Applications of Computer Vision (WACV), pages 3437–3446, February 2025
2025
-
[10]
aitorzip: https://github.com/aitorzip/DeepGTAV
-
[11]
Dosovitskiy, G
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun. Carla: An open urban driving simulator. CoRL, 2017
2017
-
[12]
Gaidon, Q
A. Gaidon, Q. Wang, Y. Cabon, and E. Vig. Virtual worlds as proxy for multi-object tracking analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
- [13]
-
[14]
Gurbindo, A
U. Gurbindo, A. Brando, J. Abella, and C. König. Object detection in adverse weather conditions for autonomous vehicles using instruct pix2pix. In2025 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2025
2025
-
[15]
H. Ha, X. Jin, J. Kim, J. Liu, Z. Wang, K. D. Nguyen, A. Blume, N. Peng, K.-W. Chang, and H. Ji. Synthia: Novel concept design with affordance composition.CVPR, 2021
2021
-
[16]
Benchmarking neural network robustness to common corruptions
Hendrycks and Dietterich. Benchmarking neural network robustness to common corruptions. InICLR, 2019
2019
-
[17]
FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation
J. Hoffman, D. Wang, F. Yu, and T. Darrell. FCNs in the wild: Pixel-level adversarial and constraint-based adaptation.arXiv:1612.02649, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Y. Hong, H. Pan, W. Sun, and Y. Jia. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. InCVPR, 2021
2021
-
[19]
Rockstar Games: Policy on posting copyrighted Rockstar Games material: http:// tinyurl.com/pjfoqo5r. 11
-
[20]
Isola, J.-Y
P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1125–1134, 2017
2017
-
[21]
Y. Jia, L. Hoyer, S. Huang, T. Wang, L. Van Gool, K. Schindler, and A. Obukhov. Dginstyle: Domain- generalizable semantic segmentation with image diffusion models and stylized semantic control. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[22]
Kiefer, D
B. Kiefer, D. Ott, and A. Zell. Leveraging synthetic data in object detection on unmanned aerial vehicles, 2021
2021
-
[23]
Martinez, C
M. Martinez, C. Sitawarin, K. Finch, L. Meincke, A. Yablonski, and A. Kornhauser. Beyond grand theft auto v for training, testing and enhancing deep learning in self driving cars, 2017
2017
-
[24]
Michaelis, B
C. Michaelis, B. Mitzkus, R. Geirhos, E. Rusak, O. Bringmann, A. S. Ecker, M. Bethge, and W. Brendel. Benchmarking robustness in object detection: Autonomous driving when winter is coming. InNeurIPS Workshop on Machine Learning for Autonomous Driving, 2019
2019
-
[25]
Neuhold, T
G. Neuhold, T. Ollmann, S. Rota Bulò, and P. Kontschieder. The mapillary vistas dataset for semantic understanding of street scenes. InICCV, 2017
2017
-
[26]
S. R. Richter, Z. Hayder, and V. Koltun. Playing for benchmarks. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017
2017
-
[27]
S. R. Richter, V. Vineet, S. Roth, and V. Koltun. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision (ECCV), pages 102–118, 2016
2016
-
[28]
Sakaridis, D
C. Sakaridis, D. Dai, and L. Van Gool. Semantic foggy scene understanding with synthetic data.International Journal of Computer Vision, 126(9):973–992, 2018
2018
-
[29]
Sakaridis, D
C. Sakaridis, D. Dai, and L. Van Gool. Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[30]
Sakaridis, D
C. Sakaridis, D. Dai, and L. Van Gool. Acdc: The adverse conditions dataset with correspondences for semantic driving scene understanding. InICCV, 2021
2021
-
[31]
Sankaranarayanan, Y
S. Sankaranarayanan, Y. Balaji, A. Jain, S. Nam Lim, and R. Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3752–3761, 2018
2018
-
[32]
Alexander Blade: http://www.dev-c.com/gtav/scripthookv/
-
[33]
T. Sun, M. Segu, J. Postels, Y. Wang, L. Van Gool, B. Schiele, F. Tombari, and F. Yu. Shift: A synthetic driving dataset for continuous multi-task domain adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21371–21382, 2022
2022
-
[34]
Taori et al
R. Taori et al. Measuring robustness to natural distribution shifts in image classification. InNeurIPS, 2020
2020
-
[35]
Torralba and A
A. Torralba and A. A. Efros. Unbiased look at dataset bias. InCVPR, 2011
2011
-
[36]
Tsai, W.-C
Y.-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[37]
aitorzip: https://github.com/aitorzip/VPilot
-
[38]
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
2021
-
[39]
J. Xu, E. Xie, X. Liu, W. Chen, D. Liang, and P. Luo. Pidnet: A real-time semantic segmentation network inspired from pid controller. InCVPR, 2023
2023
-
[40]
F. Yu, H. Chen, X. Wang, W. Xian, Y. Chen, F. Liu, V. Madhavan, and T. Darrell. BDD100K: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[41]
Zendel, M
O. Zendel, M. Murschitz, M. Zeilinger, D. Steininger, and C. Beleznai. Analyzing computer vision data - the good, the bad and the ugly. InCVPR Workshops, 2018
2018
-
[42]
J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 12
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.