Can we trust LLM Self-Explanations for Entity Resolution?
Pith reviewed 2026-06-28 16:11 UTC · model grok-4.3
The pith
LLM self-explanations for entity resolution are often unstable, weakly faithful, and poorly aligned with counterfactual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that LLM self-explanations for entity resolution are often unstable, weakly faithful, and poorly aligned with counterfactual evidence, revealing a substantial gap between plausibility and causal relevance. The work further demonstrates that a hybrid explanation framework leveraging self-explanations as priors to guide post-hoc exploration achieves explanation quality comparable to established post-hoc methods while reducing cost by up to an order of magnitude.
What carries the argument
The hybrid explanation framework that treats self-explanations as priors to guide post-hoc exploration of feature attributions and counterfactuals at attribute and token levels.
If this is right
- Self-explanations generated by prompting alone cannot be trusted as reliable indicators of why an LLM made a particular entity resolution decision.
- Post-hoc methods remain the more trustworthy option but are too expensive for routine use with large language models.
- The hybrid framework provides a concrete way to obtain higher-quality explanations without paying the full post-hoc cost.
- Both attribute-level and token-level analysis are required to expose the gaps between generated text and actual decision factors.
Where Pith is reading between the lines
- The same stability and alignment problems may appear when LLMs produce explanations for other structured matching or classification tasks.
- Refinements to how self-explanations are used as priors could further reduce cost or improve performance on specific entity resolution datasets.
- Applying the hybrid approach to newer or larger language models would test whether the cost-quality trade-off holds as model scale increases.
Load-bearing premise
The chosen quantitative metrics for stability, faithfulness, and alignment with counterfactual evidence are valid proxies for the actual trustworthiness of explanations in the entity resolution setting.
What would settle it
A new evaluation on the same models and datasets in which self-explanations show high stability scores and strong quantitative alignment with counterfactual changes would falsify the main claim.
Figures



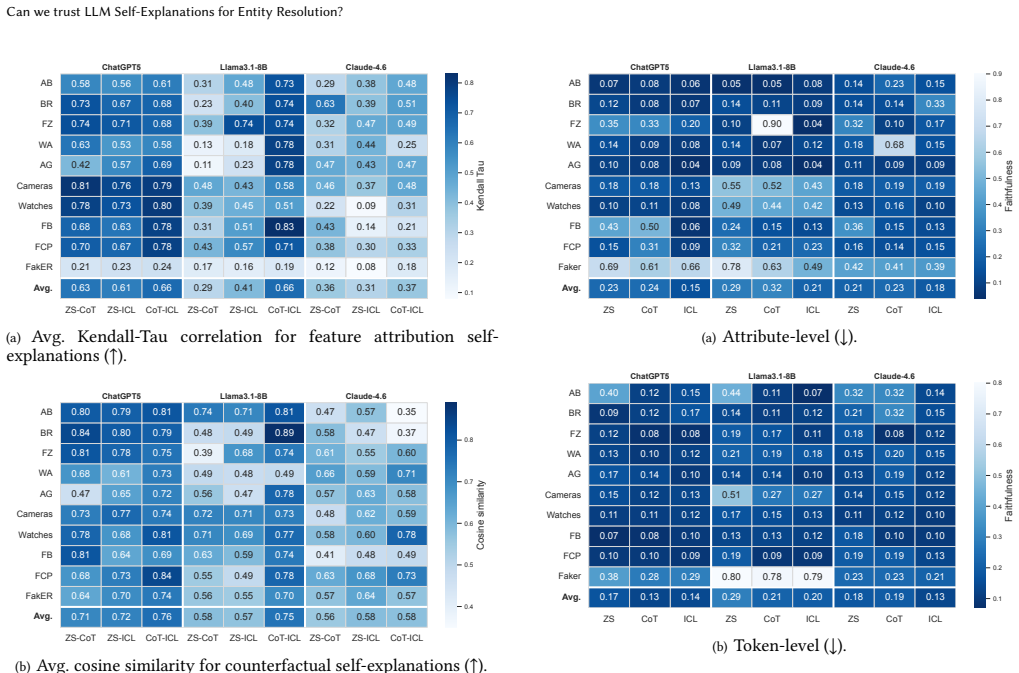
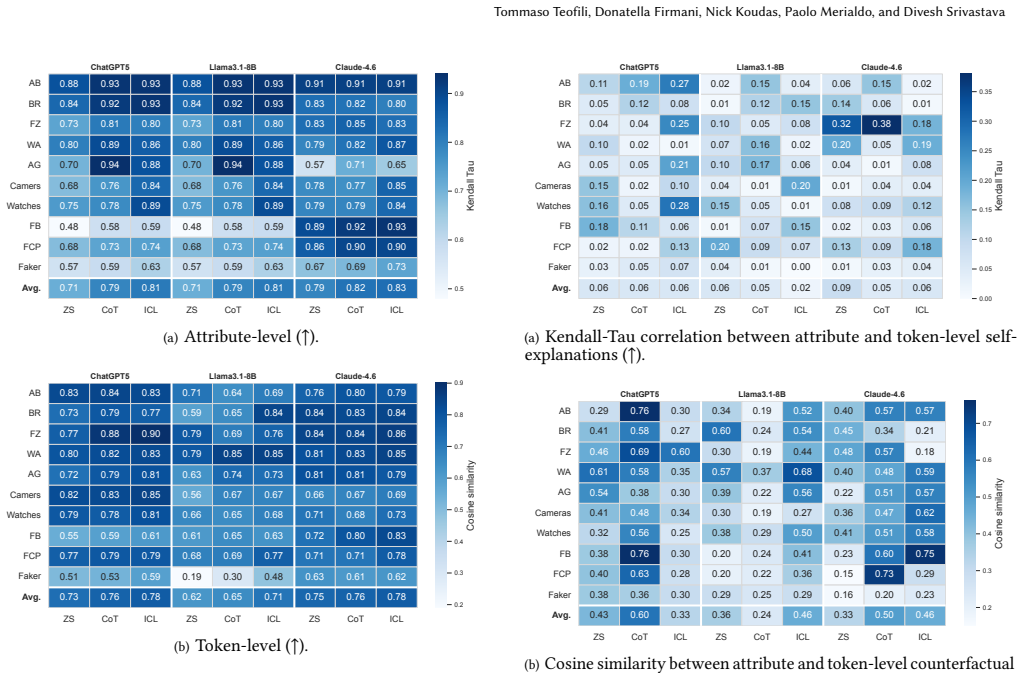
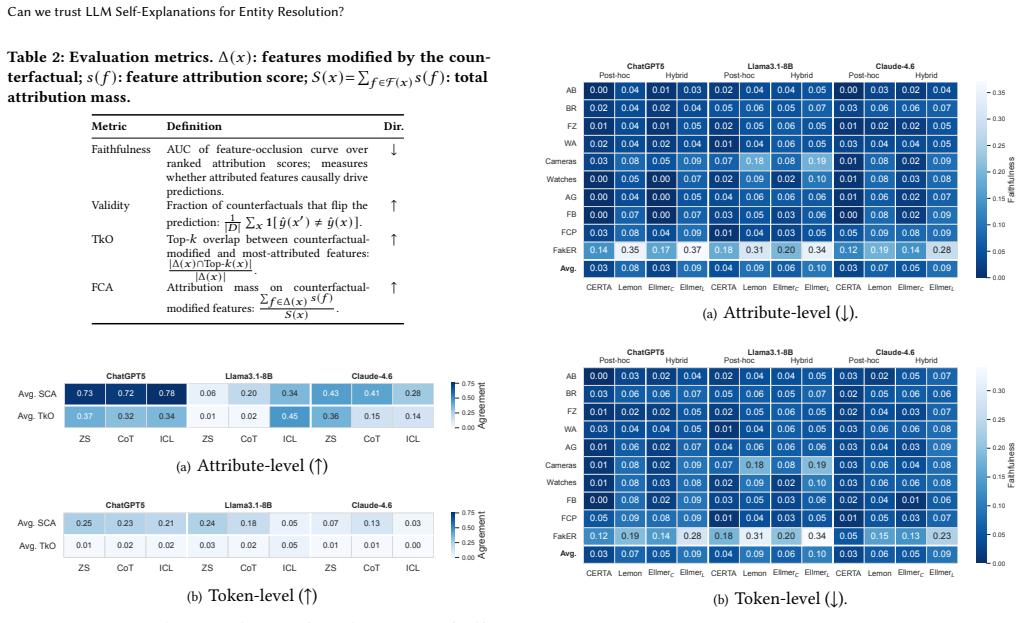
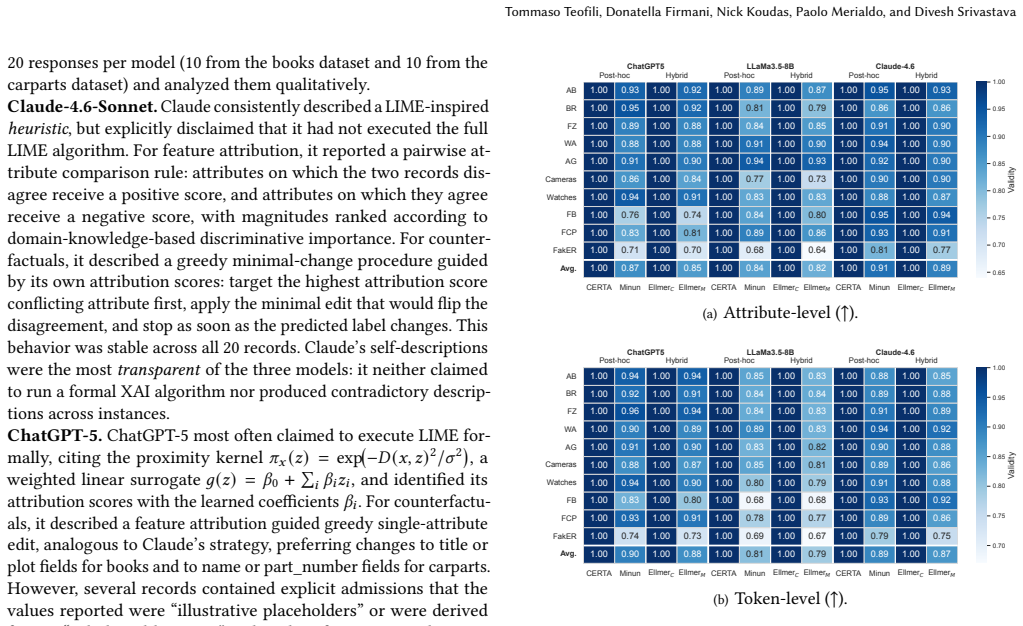



read the original abstract
Large Language Models (LLMs) have recently shown strong performance on Entity Resolution (ER). Additionally, akin to their prowess in providing accurate predictions, these models often generate self-explanations alongside their predictions through prompting. While such self-explanations are appealing due to their negligible computational cost, their actual reliability remains largely unexplored. In this paper, we present the first large-scale systematic evaluation of LLM self-explanations for ER, focusing on feature attribution and counterfactual explanations at both the attribute and token levels. Across three LLMs, ten datasets, and multiple prompting strategies, we show that self-explanations are often unstable, weakly faithful, and poorly aligned with counterfactual evidence, revealing a substantial gap between plausibility and causal relevance. We further demonstrate that established post-hoc explanation methods provide significantly higher trustworthiness, but at a prohibitive computational cost when applied to LLMs. To bridge this gap, we introduce \uncerta{}, a hybrid explanation framework that leverages self-explanations as priors to guide post-hoc exploration. \uncerta{} achieves explanation quality comparable to post-hoc methods while reducing cost by up to an order of magnitude.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first large-scale empirical evaluation of LLM self-explanations for entity resolution (ER), assessing stability, faithfulness (via feature attribution and counterfactuals at attribute/token levels), and alignment across three LLMs, ten datasets, and multiple prompting strategies. It concludes that self-explanations are often unstable, weakly faithful, and poorly aligned with counterfactual evidence. The authors introduce 춮rta{}, a hybrid framework that uses self-explanations as priors to guide post-hoc methods, claiming comparable quality at up to 10x lower cost.
Significance. If the evaluation metrics validly proxy causal relevance in ER, the results would document a clear gap between plausible self-explanations and actual decision drivers, cautioning against their standalone use in production ER systems. The scale (multiple models/datasets/prompts) and the hybrid efficiency claim are strengths; the work also contrasts self-explanations against established post-hoc methods. However, the significance hinges on whether the chosen quantitative proxies (stability across runs, sufficiency/comprehensiveness via perturbations, counterfactual alignment) correctly capture ER-specific causal structure such as attribute interactions and similarity thresholds.
major comments (3)
- [Abstract, §3] Abstract and §3 (Experimental Setup): The central claims of instability and weak faithfulness rest on quantitative metrics whose exact definitions, statistical tests, variance reporting, and data exclusion rules are not detailed enough in the abstract or high-level setup to allow verification that they are ER-specific rather than generic XAI imports; this directly affects whether the 'substantial gap between plausibility and causal relevance' conclusion is load-bearing.
- [§4.2] §4.2 (Faithfulness Metrics): The sufficiency and comprehensiveness scores are computed via feature/token removal, but the manuscript does not validate that these perturbations align with the LLM's internal ER logic (e.g., thresholded similarity scores or cross-attribute interactions); if the metrics flag non-causal tokens as unfaithful without such grounding, the 'weakly faithful' claim may not hold for the ER setting.
- [Table 3, §5] Table 3 / §5 (Counterfactual Alignment): The reported poor alignment with counterfactual evidence lacks an explicit comparison to ER-specific counterfactual generation (e.g., minimal attribute edits that flip the match decision); without this, the misalignment result risks being an artifact of the chosen counterfactual construction rather than a general property of self-explanations.
minor comments (2)
- [Abstract] Notation for the hybrid framework is introduced as \uncerta{} without an expanded acronym or clear expansion on first use.
- [Figures in §4] Figure captions for stability plots should explicitly state the number of runs and prompt variants used to compute variance.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive feedback on our manuscript. The comments have prompted us to clarify several aspects of our evaluation methodology. We provide point-by-point responses below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Experimental Setup): The central claims of instability and weak faithfulness rest on quantitative metrics whose exact definitions, statistical tests, variance reporting, and data exclusion rules are not detailed enough in the abstract or high-level setup to allow verification that they are ER-specific rather than generic XAI imports; this directly affects whether the 'substantial gap between plausibility and causal relevance' conclusion is load-bearing.
Authors: We appreciate this observation. The detailed definitions of the metrics, including stability (measured by variance in explanations across multiple runs with different seeds), faithfulness (sufficiency and comprehensiveness via feature removal), and their statistical significance testing are provided in Sections 4.1 and 4.2. To make this more accessible, we have revised the abstract to include concise definitions and expanded Section 3 with explicit descriptions of the statistical tests used (Wilcoxon signed-rank tests for comparisons), variance reporting standards, and data exclusion rules (e.g., instances where the model abstains from a decision). These elements are tailored to ER by applying them at attribute and token levels critical for matching. revision: yes
-
Referee: [§4.2] §4.2 (Faithfulness Metrics): The sufficiency and comprehensiveness scores are computed via feature/token removal, but the manuscript does not validate that these perturbations align with the LLM's internal ER logic (e.g., thresholded similarity scores or cross-attribute interactions); if the metrics flag non-causal tokens as unfaithful without such grounding, the 'weakly faithful' claim may not hold for the ER setting.
Authors: The feature and token removal approach for computing sufficiency and comprehensiveness is intended to probe causal influence on the prediction, independent of internal model details. In the ER context, this tests whether highlighted attributes or tokens affect the match/non-match decision, which is the core causal structure. We recognize the value of additional grounding and have added to the revised manuscript a discussion and illustrative examples showing how the perturbations impact attribute similarity computations and interactions as modeled by the LLM prompts. Full access to internal activations would enable more direct validation, but this is outside the scope of the current black-box evaluation. revision: partial
-
Referee: [Table 3, §5] Table 3 / §5 (Counterfactual Alignment): The reported poor alignment with counterfactual evidence lacks an explicit comparison to ER-specific counterfactual generation (e.g., minimal attribute edits that flip the match decision); without this, the misalignment result risks being an artifact of the chosen counterfactual construction rather than a general property of self-explanations.
Authors: Our counterfactual generation procedure, detailed in Section 5, involves systematically editing attributes and tokens to identify minimal changes that flip the ER decision, which is precisely the ER-specific approach suggested. To further strengthen this, we have included in the revision an explicit side-by-side comparison of alignment results using our method versus alternative minimal edit strategies, confirming that the poor alignment finding is robust and not an artifact of the construction. revision: yes
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The paper performs a large-scale experimental study comparing LLM self-explanations against post-hoc methods on ER tasks, using stability, faithfulness, and counterfactual alignment metrics across three LLMs, ten datasets, and multiple prompts. All central claims are grounded in direct experimental results rather than any derivation, first-principles prediction, or self-referential definition. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the reported chain. The hybrid framework is introduced as an empirical engineering contribution. This is a standard self-contained empirical paper whose results can be externally verified or falsified against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantitative metrics of stability, faithfulness, and counterfactual alignment are appropriate measures of explanation trustworthiness for entity resolution.
invented entities (1)
-
촎rta{} hybrid explanation framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aberbach, M
A. Aberbach, M. Kejriwal, and K. Shen. Multipartite entity resolution: Motivating a k-tuple perspective (student abstract).Proceedings of the AAAI Conference on Artificial Intelligence, 38(21):23434–23435, 2024
2024
-
[2]
Claude 4.6 sonnet, 2026
Anthropic. Claude 4.6 sonnet, 2026. Last accessed, April 30th 2026
2026
-
[3]
Atanasova, J
P. Atanasova, J. G. Simonsen, C. Lioma, and I. Augenstein. A diagnostic study of explainability techniques for text classification. In B. Webber, T. Cohn, Y. He, and Y. Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 3256–3274. Association for Computationa...
2020
-
[4]
Baraldi, F
A. Baraldi, F. Del Buono, F. Guerra, M. Paganelli, M. Vincini, et al. An intrinsically interpretable entity matching system. InAdvances in Database Technology-EDBT, volume 26, pages 645–657. OpenProceedings. org, 2023
2023
-
[5]
Baraldi, F
A. Baraldi, F. Del Buono, M. Paganelli, and F. Guerra. Landmark explanation: An explainer for entity matching models. InProceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 4680–4684, 2021
2021
-
[6]
N. Barlaug. LEMON: explainable entity matching.IEEE Trans. Knowl. Data Eng., 35(8):8171–8184, 2023
2023
-
[7]
Benassi, F
R. Benassi, F. Guerra, M. Paganelli, and D. Tiano. Explaining entity matching with clusters of words. In2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 2325–2337. IEEE, 2024
2024
-
[8]
L. Berglund, M. Tong, M. Kaufmann, M. Balesni, A. C. Stickland, T. Korbak, and O. Evans. The reversal curse: Llms trained on "a is b" fail to learn "b is a".CoRR, abs/2309.12288, 2023
-
[9]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakan- tan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[10]
Cífka and A
O. Cífka and A. Liutkus. Black-box language model explanation by context length probing. In A. Rogers, J. L. Boyd-Graber, and N. Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 1067–1079. Association for Computational Lingui...
2023
-
[11]
Coroama and A
L. Coroama and A. Groza. Evaluation metrics in explainable artificial intelligence (xai). InInternational conference on advanced research in technologies, information, innovation and sustainability, pages 401–413. Springer, 2022
2022
-
[12]
DeYoung, S
J. DeYoung, S. Jain, N. F. Rajani, E. Lehman, C. Xiong, R. Socher, and B. C. Wallace. Eraser: A benchmark to evaluate rationalized nlp models. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4443– 4458, 2020
2020
-
[13]
di Cicco, D
V. di Cicco, D. Firmani, N. Koudas, P. Merialdo, and D. Srivastava. Interpreting deep learning models for entity resolution: an experience report using LIME. In R. Bordawekar and O. Shmueli, editors,Proceedings of the Second International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, aiDM@SIGMOD 2019, Amsterdam, The Nether...
2019
-
[14]
Ebaid, S
A. Ebaid, S. Thirumuruganathan, W. G. Aref, A. Elmagarmid, and M. Ouzzani. Ex- plainer: entity resolution explanations. In2019 IEEE 35th International Conference on Data Engineering (ICDE), pages 2000–2003. IEEE, 2019
2000
-
[15]
M. Fan, X. Han, J. Fan, C. Chai, N. Tang, G. Li, and X. Du. Cost-effective in-context learning for entity resolution: A design space exploration. In2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 3696–3709. IEEE, 2024
2024
-
[16]
Freire, G
J. Freire, G. Fan, B. Feuer, C. Koutras, Y. Liu, E. Peña, A. S. Santos, C. T. Silva, and E. Wu. Large language models for data discovery and integration: Challenges Tommaso Teofili, Donatella Firmani, Nick Koudas, Paolo Merialdo, and Divesh Srivastava and opportunities.IEEE Data Eng. Bull., 49(1):3–31, 2025
2025
-
[17]
Guidotti, A
R. Guidotti, A. Monreale, S. Ruggieri, F. Turini, F. Giannotti, and D. Pedreschi. A survey of methods for explaining black box models.ACM computing surveys (CSUR), 51(5):1–42, 2018
2018
-
[18]
Y. Guo, L. Chen, Z. Zhou, B. Zheng, Z. Fang, Z. Zhang, Y. Mao, and Y. Gao. Camper: An effective framework for privacy-aware deep entity resolution. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 626–637, 2023
2023
-
[19]
S. Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979
1979
-
[20]
Jacovi and Y
A. Jacovi and Y. Goldberg. Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness? In58th Annual Meeting of the Asso- ciation for Computational Linguistics, ACL 2020, pages 4198–4205. Association for Computational Linguistics (ACL), 2020
2020
-
[21]
Jesus, C
S. Jesus, C. Belém, V. Balayan, J. Bento, P. Saleiro, P. Bizarro, and J. Gama. How can i choose an explainer? an application-grounded evaluation of post-hoc explanations. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 805–815, 2021
2021
-
[22]
J. V. Jeyakumar, J. Noor, Y.-H. Cheng, L. Garcia, and M. Srivastava. How can i explain this to you? an empirical study of deep neural network explanation methods.Advances in neural information processing systems, 33:4211–4222, 2020
2020
-
[23]
Z. Ji, X. Wang, Z. Luo, Z. Xie, and M. Zhang. Optimized batch prompting for cost-effective llms.Proceedings of the VLDB Endowment, 18(7):2172–2184, 2025
2025
-
[24]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Karimi, B
A.-H. Karimi, B. Schölkopf, and I. Valera. Algorithmic recourse: from counter- factual explanations to interventions. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 353–362, 2021
2021
-
[26]
M. G. Kendall. Rank correlation methods. 1948
1948
-
[27]
Kommiya Mothilal, D
R. Kommiya Mothilal, D. Mahajan, C. Tan, and A. Sharma. Towards unifying feature attribution and counterfactual explanations: Different means to the same end. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’21, page 652–663, New York, NY, USA, 2021. Association for Computing Machinery
2021
-
[28]
Krishna, J
S. Krishna, J. Ma, D. Slack, A. Ghandeharioun, S. Singh, and H. Lakkaraju. Post hoc explanations of language models can improve language models.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[29]
G. Li, X. Zhou, and X. Zhao. Llm for data management.Proceedings of the VLDB Endowment, 17(12):4213–4216, 2024
2024
-
[30]
H. Li, S. Li, F. Hao, C. J. Zhang, Y. Song, and L. Chen. Booster: Leveraging large language models for enhancing entity resolution. InCompanion Proceedings of the ACM on Web Conference 2024, pages 1043–1046, 2024
2024
-
[31]
Y. Li. A practical survey on zero-shot prompt design for in-context learning. In R. Mitkov and G. Angelova, editors,Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing, pages 641–647, Varna, Bulgaria, Sept. 2023. INCOMA Ltd., Shoumen, Bulgaria
2023
-
[32]
Y. Li, J. Li, Y. Suhara, A. Doan, and W.-C. Tan. Deep entity matching with pre-trained language models.Proceedings of the VLDB Endowment, 14(1):50–60, 2020
2020
-
[33]
Z. C. Lipton. The mythos of model interpretability.Commun. ACM, 61(10):36–43, Sept. 2018
2018
-
[34]
P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM Computing Surveys, 55(9):1–35, 2023
2023
-
[35]
Y. Lu, M. Bartolo, A. Moore, S. Riedel, and P. Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitiv- ity. In S. Muresan, P. Nakov, and A. Villavicencio, editors,Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098, Dublin, Irel...
2022
-
[36]
Madsen, S
A. Madsen, S. Chandar, and S. Reddy. Are self-explanations from large language models faithful? In L.-W. Ku, A. Martins, and V. Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 295–337, Bangkok, Thailand, Aug. 2024. Association for Computational Linguistics
2024
-
[37]
Madsen, S
A. Madsen, S. Reddy, and S. Chandar. Post-hoc interpretability for neural nlp: A survey.ACM Comput. Surv., 55(8), Dec. 2022
2022
-
[38]
Madsen, S
A. Madsen, S. Reddy, and S. Chandar. Post-hoc interpretability for neural nlp: A survey.ACM Computing Surveys, 55(8):1–42, 2022
2022
-
[39]
K. Meng, D. Bau, A. Andonian, and Y. Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359– 17372, 2022
2022
-
[40]
Moraffah, M
R. Moraffah, M. Karami, R. Guo, A. Raglin, and H. Liu. Causal interpretability for machine learning-problems, methods and evaluation.ACM SIGKDD Explorations Newsletter, 22(1):18–33, 2020
2020
-
[41]
R. K. Mothilal, A. Sharma, and C. Tan. Explaining machine learning classifiers through diverse counterfactual explanations. In M. Hildebrandt, C. Castillo, L. E. Celis, S. Ruggieri, L. Taylor, and G. Zanfir-Fortuna, editors,FAT* ’20: Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, January 27-30, 2020, pages 607–617. ACM, 2020
2020
-
[42]
Mudgal, H
S. Mudgal, H. Li, T. Rekatsinas, A. Doan, Y. Park, G. Krishnan, R. Deep, E. Ar- caute, and V. Raghavendra. Deep learning for entity matching: A design space exploration. InProceedings of the 2018 International Conference on Management of Data, pages 19–34, 2018
2018
-
[43]
Nananukul, K
N. Nananukul, K. Sisaengsuwanchai, and M. Kejriwal. Cost-efficient prompt engineering for unsupervised entity resolution in the product matching domain. Discover Artificial Intelligence, 4(1):56, 2024
2024
-
[44]
Paganelli, D
M. Paganelli, D. Tiano, and F. Guerra. A multi-facet analysis of bert-based entity matching models.The VLDB Journal, 33(4):1039–1064, 2024
2024
-
[45]
Peeters and C
R. Peeters and C. Bizer. Dual-objective fine-tuning of bert for entity matching. Proc. VLDB Endow., 14(10):1913–1921, jun 2021
1913
-
[46]
Peeters and C
R. Peeters and C. Bizer. Using chatgpt for entity matching. In A. Abelló, P. Vas- siliadis, O. Romero, R. Wrembel, F. Bugiotti, J. Gamper, G. Vargas-Solar, and E. Zumpano, editors,New Trends in Database and Information Systems - ADBIS 2023 Short Papers, Doctoral Consortium and Workshops: AIDMA, DOING, K-Gals, MADEISD, PeRS, Barcelona, Spain, September 4-7...
2023
-
[47]
Primpeli, R
A. Primpeli, R. Peeters, and C. Bizer. The wdc training dataset and gold standard for large-scale product matching. InCompanion Proceedings of the 2019 World Wide Web Conference (WWW ’19 Companion), pages 381–386, 2019
2019
-
[48]
why should i trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin. " why should i trust you?" explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144, 2016
2016
-
[49]
Y. Rong, T. Leemann, T.-T. Nguyen, L. Fiedler, P. Qian, V. Unhelkar, T. Seidel, G. Kasneci, and E. Kasneci. Towards human-centered explainable ai: A survey of user studies for model explanations.IEEE transactions on pattern analysis and machine intelligence, 2023
2023
-
[50]
Samek, A
W. Samek, A. Binder, G. Montavon, S. Lapuschkin, and K.-R. Müller. Evaluating the visualization of what a deep neural network has learned.IEEE transactions on neural networks and learning systems, 28(11):2660–2673, 2016
2016
-
[51]
H. Shiyuan, M. Siddarth, J. Shreedhar, Z. Yilun, and H. G. Leilani. Can large language models explain themselves? a study of llm-generated self-explanations. CoRR, abs/2310.11207, 2023
-
[52]
K. Sisaengsuwanchai, N. Nananukul, and M. Kejriwal. How does prompt engi- neering affect chatgpt performance on unsupervised entity resolution?arXiv preprint arXiv:2310.06174, 2023
-
[53]
Slack, A
D. Slack, A. Hilgard, S. Singh, and H. Lakkaraju. Reliable post hoc explanations: Modeling uncertainty in explainability.Advances in neural information processing systems, 34:9391–9404, 2021
2021
-
[54]
Srivastava, A
A. Srivastava, A. Rastogi, A. Rao, A. A. M. Shoeb, A. Abid, A. Fisch, A. R. Brown, A. Santoro, A. Gupta, A. Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on machine learning research, 2023
2023
-
[55]
Teofili, D
T. Teofili, D. Firmani, N. Koudas, V. Martello, P. Merialdo, and D. Srivastava. Effective explanations for entity resolution models. In2022 IEEE 38th International Conference on Data Engineering (ICDE), pages 2709–2721. IEEE, 2022
2022
-
[56]
Teofili, D
T. Teofili, D. Firmani, N. Koudas, P. Merialdo, and D. Srivastava. Certem: explain- ing and debugging black-box entity resolution systems with certa.Proceedings of the VLDB Endowment, 15(12):3642–3645, 2022
2022
-
[57]
Thirumuruganathan, M
S. Thirumuruganathan, M. Ouzzani, and N. Tang. Explaining entity resolution predictions: Where are we and what needs to be done? InProceedings of the Workshop on Human-In-the-Loop Data Analytics, pages 1–6, 2019
2019
-
[58]
Thirumuruganathan, M
S. Thirumuruganathan, M. Ouzzani, and N. Tang. Explaining entity resolution predictions: Where are we and what needs to be done? InProceedings of the Workshop on Human-In-the-Loop Data Analytics, HILDA ’19, New York, NY, USA,
-
[59]
Association for Computing Machinery
-
[60]
Turpin, J
M. Turpin, J. Michael, E. Perez, and S. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems, 36:74952–74965, 2023
2023
-
[61]
Wachter, B
S. Wachter, B. Mittelstadt, and C. Russell. Counterfactual explanations without opening the black box: Automated decisions and the gdpr.Harv. JL & Tech., 31:841, 2017
2017
-
[62]
Wang and Y
J. Wang and Y. Li. Minun: evaluating counterfactual explanations for entity matching. In M. Boehm, P. Varma, and D. Xin, editors,DEEM ’22: Proceedings of the Sixth Workshop on Data Management for End-To-End Machine Learning Philadelphia, PA, USA, 12 June 2022, pages 7:1–7:11. ACM, 2022
2022
-
[63]
T. Wang, X. Chen, H. Lin, X. Chen, X. Han, L. Sun, H. Wang, and Z. Zeng. Match, compare, or select? an investigation of large language models for entity matching. InProceedings of the 31st International Conference on Computational Linguistics, pages 96–109, 2025
2025
-
[64]
Wang and M
X. Wang and M. Yin. Are explanations helpful? a comparative study of the effects of explanations in ai-assisted decision-making. InProceedings of the 26th International Conference on Intelligent User Interfaces, pages 318–328, 2021
2021
-
[65]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Can we trust LLM Self-Explanations for Entity Resolution? Advances in neural information processing systems, 35:24824–24837, 2022
2022
- [66]
- [67]
-
[68]
Zeakis, G
A. Zeakis, G. Papadakis, D. Skoutas, and M. Koubarakis. Pre-trained embed- dings for entity resolution: an experimental analysis.Proceedings of the VLDB Endowment, 16(9):2225–2238, 2023
2023
-
[69]
Zeakis, G
A. Zeakis, G. Papadakis, D. Skoutas, and M. Koubarakis. An in-depth analysis of pre-trained embeddings for entity resolution.The VLDB Journal, 34(1):1–27, 2025
2025
-
[70]
Zecchini, G
L. Zecchini, G. Simonini, S. Bergamaschi, and F. Naumann. Brewer: Entity resolution on-demand.Proceedings of the VLDB Endowment, 16(12):4026–4029, 2023
2023
-
[71]
H. Zhao, H. Chen, F. Yang, N. Liu, H. Deng, H. Cai, S. Wang, D. Yin, and M. Du. Ex- plainability for large language models: A survey.ACM Transactions on Intelligent Systems and Technology, 2023
2023
-
[72]
Z. Zhao, E. Wallace, S. Feng, D. Klein, and S. Singh. Calibrate before use: Im- proving few-shot performance of language models. InInternational conference on machine learning, pages 12697–12706. Pmlr, 2021
2021
- [73]
-
[74]
J. Zhuo, S. Zhang, X. Fang, H. Duan, D. Lin, and K. Chen. Prosa: Assessing and understanding the prompt sensitivity of llms. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1950–1976, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.