Trust Region On-Policy Distillation
Pith reviewed 2026-06-28 17:37 UTC · model grok-4.3
The pith
TrOPD restricts on-policy distillation to reliable teacher supervision regions to stabilize training under distribution mismatch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
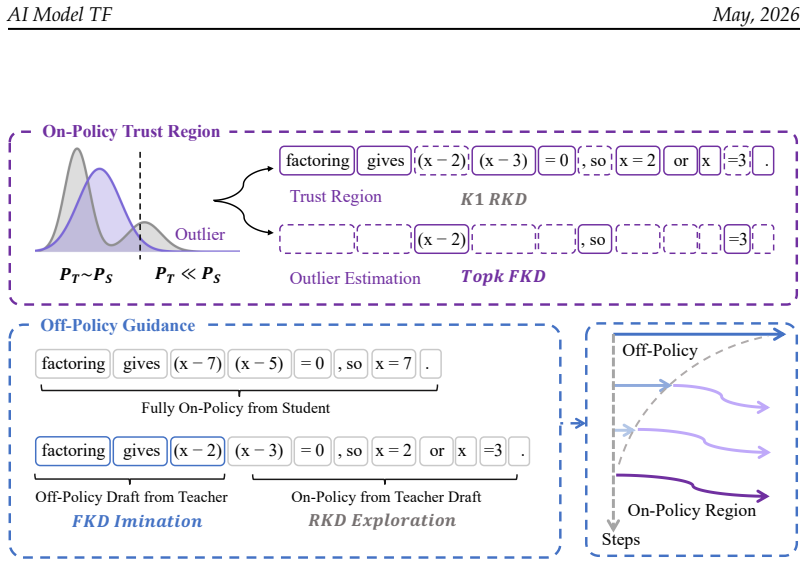
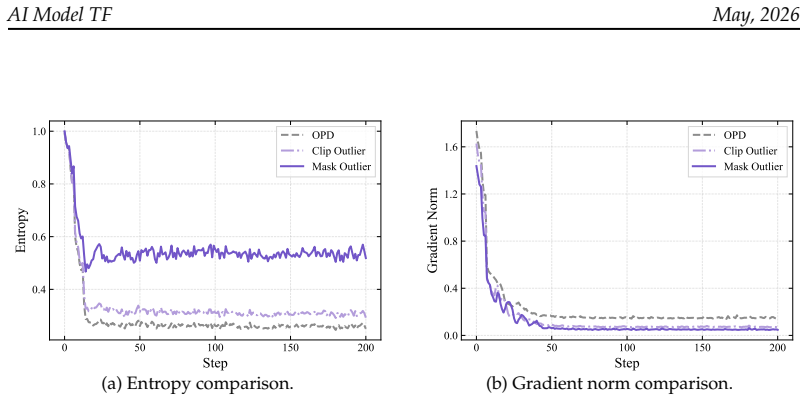
TrOPD performs on-policy distillation only inside trust regions where the teacher supplies reliable supervision, applies outlier estimation via gradient clipping, masking, or forward-KL estimation outside those regions, and augments training with off-policy guidance by continuing student generation from teacher prefixes under forward KL, yielding more stable optimization than prior OPD variants.
What carries the argument
Trust-region restriction on on-policy learning that limits the reverse-KL estimator to reliable supervision areas, paired with outlier handling and off-policy prefix guidance.
If this is right
- On-policy distillation becomes usable for post-training even when teacher and student policies diverge substantially.
- Outlier estimation via forward KL or masking becomes a standard tool for credit assignment in token-level supervision.
- Off-policy guidance from teacher prefixes can be combined with on-policy updates to steer exploration toward stable regions.
- Model compression and multi-task enhancement pipelines gain reliability without switching away from on-policy methods.
Where Pith is reading between the lines
- The same trust-region idea could be tested in other settings where reverse-KL gradients become unstable, such as certain RLHF stages.
- If the method scales without extra tuning, it may lower the barrier to distilling very large teachers into smaller students across domains.
- An open question left implicit is whether the trust-region boundaries themselves can be learned rather than set by fixed heuristics.
Load-bearing premise
That the trust-region restriction plus outlier strategies will reliably suppress bad gradients from mismatch without creating new instabilities or demanding heavy hyperparameter search.
What would settle it
A controlled experiment on the same mathematical-reasoning or code-generation benchmarks where TrOPD either fails to converge or underperforms OPD/EOPD/REOPOLD baselines once the teacher-student distribution gap exceeds the levels tested in the paper.
Figures

read the original abstract
On-Policy Distillation (OPD) is a fundamental technique for efficient post-training of large language models (LLMs), with broad applications in agent learning, multi-task enhancement, and model compression. However, OPD training becomes unstable when the teacher and student distributions differ substantially, as teacher supervision on student-generated tokens may yield unreliable policy gradients and even cause optimization failure. This work addresses reliable on-policy token-level supervision through credit assignment strategies, and proposes Trust Region On-Policy Distillation, TrOPD. It features the following characteristics: 1) Trust-Region On-Policy Learning: TrOPD performs OPD only in regions where the teacher provides reliable supervision, mitigating the optimization difficulty of the K1 reverse-KL estimator under distribution mismatch. 2) Outlier Estimation: For outlier regions, we explore gradient clipping, masking, and forward-KL estimation to reduce the adverse effects of unreliable supervision. 3) Off-Policy Guidance: The student continues generation from teacher prefixes and uses forward KL to imitate off-policy guidance, encouraging on-policy exploration toward reliable regions. Experiments show that TrOPD consistently outperforms SoTA OPD baselines, including OPD, EOPD, and REOPOLD, across mathematical reasoning, code generation, and general-domain benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Trust Region On-Policy Distillation (TrOPD) to stabilize On-Policy Distillation (OPD) for large language models when teacher and student distributions differ substantially. The method restricts OPD to regions where the teacher provides reliable supervision, uses outlier estimation techniques including gradient clipping, masking, and forward-KL, and incorporates off-policy guidance from teacher prefixes with forward KL to promote exploration. It claims superior performance over state-of-the-art OPD baselines on mathematical reasoning, code generation, and general-domain benchmarks.
Significance. If the empirical results hold, TrOPD could provide a more robust approach to on-policy distillation, addressing a key challenge in LLM post-training for applications like agent learning and model compression. The proposed strategies target the specific issue of unreliable gradients from distribution mismatch in a structured way.
major comments (1)
- [Abstract] Abstract: The central empirical claim of consistent outperformance over OPD, EOPD, and REOPOLD is presented without quantitative results, error bars, dataset descriptions, ablation studies, or experimental details. This makes it impossible to verify whether the trust-region restriction, outlier estimation, and off-policy guidance actually mitigate unreliable gradients without introducing new instabilities or requiring extensive tuning.
minor comments (1)
- [Abstract] Abstract: The acronym REOPOLD is introduced without expansion or citation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of consistent outperformance over OPD, EOPD, and REOPOLD is presented without quantitative results, error bars, dataset descriptions, ablation studies, or experimental details. This makes it impossible to verify whether the trust-region restriction, outlier estimation, and off-policy guidance actually mitigate unreliable gradients without introducing new instabilities or requiring extensive tuning.
Authors: The abstract is a concise high-level summary (as is standard for the venue). The full manuscript contains the requested details: quantitative results with comparisons and standard deviations appear in Tables 1-3, dataset descriptions and experimental setup are in Section 4.1, and ablation studies on trust-region restriction, outlier estimation, and off-policy guidance are in Section 4.3. These sections enable verification of whether the components mitigate unreliable gradients. We will revise the abstract to include a brief mention of key quantitative gains to improve standalone readability. revision: yes
Circularity Check
No significant circularity; empirical claims only
full rationale
The paper presents an empirical method (TrOPD) with three described components (trust-region restriction, outlier handling, off-policy guidance) and reports benchmark outperformance versus baselines. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Central claims rest on experimental results rather than any self-referential mathematical reduction. This is the expected outcome for a purely empirical distillation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption On-policy distillation is a fundamental technique for efficient post-training of LLMs
Forward citations
Cited by 2 Pith papers
-
Blockwise Policy-Drift Gating for On-Policy Distillation
Blockwise policy-drift gating raises mean pass@8 from 0.4978 to 0.5160 on four math benchmarks by reweighting OPD losses with detached mean-normalized gates from student policy drift over 64-token blocks.
-
A Formula-Driven Survey and Research Agenda for On-Policy Distillation
A survey creates a taxonomy for on-policy distillation in LLMs that separates temporal credit assignment from vocabulary-level probability routing.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2312.10256 , year =
Multi-agent reinforcement learning: A comprehensive survey , author =. arXiv preprint arXiv:2312.10256 , year =
-
[2]
arXiv preprint arXiv:2411.18892 , year =
A comprehensive survey of reinforcement learning: From algorithms to practical challenges , author =. arXiv preprint arXiv:2411.18892 , year =
-
[3]
arXiv preprint arXiv:2505.14677 , year =
Visionary-r1: Mitigating shortcuts in visual reasoning with reinforcement learning , author =. arXiv preprint arXiv:2505.14677 , year =
-
[4]
arXiv preprint arXiv:2505.20777 , year =
TACO: Think-Answer Consistency for Optimized Long-Chain Reasoning and Efficient Data Learning via Reinforcement Learning in LVLMs , author =. arXiv preprint arXiv:2505.20777 , year =
-
[5]
arXiv preprint arXiv:2505.15879 , year =
GRIT: Teaching MLLMs to Think with Images , author =. arXiv preprint arXiv:2505.15879 , year =
-
[6]
arXiv preprint arXiv:2503.06749 , year =
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author =. arXiv preprint arXiv:2503.06749 , year =
-
[7]
arXiv preprint arXiv:2503.01785 , year =
Visual-rft: Visual reinforcement fine-tuning , author =. arXiv preprint arXiv:2503.01785 , year =
-
[8]
arXiv preprint arXiv:2504.07615 , year =
Vlm-r1: A stable and generalizable r1-style large vision-language model , author =. arXiv preprint arXiv:2504.07615 , year =
-
[9]
arXiv preprint arXiv:2505.20272 , year =
Ground-R1: Incentivizing Grounded Visual Reasoning via Reinforcement Learning , author =. arXiv preprint arXiv:2505.20272 , year =
-
[10]
arXiv preprint arXiv:2505.23558 , year =
Qwen Look Again: Guiding Vision-Language Reasoning Models to Re-attention Visual Information , author =. arXiv preprint arXiv:2505.23558 , year =
-
[11]
arXiv preprint arXiv:2505.11409 , year =
Visual Planning: Let's Think Only with Images , author =. arXiv preprint arXiv:2505.11409 , year =
-
[12]
arXiv preprint arXiv:2408.01072 , year =
A survey on self-play methods in reinforcement learning , author =. arXiv preprint arXiv:2408.01072 , year =
-
[13]
arXiv preprint arXiv:2508.08189 , year =
Reinforcement Learning in Vision: A Survey , author =. arXiv preprint arXiv:2508.08189 , year =
-
[14]
arXiv preprint arXiv:2508.17608 , year =
ChartMaster: Advancing Chart-to-Code Generation with Real-World Charts and Chart Similarity Reinforcement Learning , author =. arXiv preprint arXiv:2508.17608 , year =
-
[15]
arXiv preprint arXiv:2303.18223 , volume =
A survey of large language models , author =. arXiv preprint arXiv:2303.18223 , volume =
-
[16]
arXiv preprint arXiv:2505.00551 , year =
100 days after deepseek-r1: A survey on replication studies and more directions for reasoning language models , author =. arXiv preprint arXiv:2505.00551 , year =
-
[17]
arXiv preprint arXiv:2502.17419 , year =
From system 1 to system 2: A survey of reasoning large language models , author =. arXiv preprint arXiv:2502.17419 , year =
-
[18]
arXiv preprint arXiv:2501.09686 , year =
Towards large reasoning models: A survey of reinforced reasoning with large language models , author =. arXiv preprint arXiv:2501.09686 , year =
-
[19]
arXiv preprint arXiv:2507.04136 , year =
A Technical Survey of Reinforcement Learning Techniques for Large Language Models , author =. arXiv preprint arXiv:2507.04136 , year =
-
[20]
arXiv preprint arXiv:2505.02686 , year =
Sailing by the Stars: A Survey on Reward Models and Learning Strategies for Learning from Rewards , author =. arXiv preprint arXiv:2505.02686 , year =
-
[21]
ACM Computing Surveys , volume =
A survey of reasoning with foundation models: Concepts, methodologies, and outlook , author =. ACM Computing Surveys , volume =. 2025 , publisher =
2025
-
[22]
arXiv preprint arXiv:2507.06167 , year=
Skywork-r1v3 technical report , author=. arXiv preprint arXiv:2507.06167 , year=
-
[23]
arXiv preprint arXiv:2505.07608 , year=
MiMo: Unlocking the Reasoning Potential of Language Model--From Pretraining to Posttraining , author=. arXiv preprint arXiv:2505.07608 , year=
-
[24]
arXiv preprint arXiv:2505.07291 , year=
INTELLECT-2: A Reasoning Model Trained Through Globally Decentralized Reinforcement Learning , author=. arXiv preprint arXiv:2505.07291 , year=
-
[25]
arXiv preprint arXiv:2505.15431 , year=
Hunyuan-turbos: Advancing large language models through mamba-transformer synergy and adaptive chain-of-thought , author=. arXiv preprint arXiv:2505.15431 , year=
-
[26]
arXiv preprint arXiv:2506.03570 , year =
FreePRM: Training Process Reward Models Without Ground Truth Process Labels , author =. arXiv preprint arXiv:2506.03570 , year =
-
[27]
arXiv preprint arXiv:2410.08146 , year =
Rewarding progress: Scaling automated process verifiers for llm reasoning , author =. arXiv preprint arXiv:2410.08146 , year =
-
[28]
arXiv preprint arXiv:2508.12551 , year =
OS-R1: Agentic Operating System Kernel Tuning with Reinforcement Learning , author =. arXiv preprint arXiv:2508.12551 , year =
-
[29]
arXiv preprint arXiv:2508.15144 , year =
Mobile-Agent-v3: Foundamental Agents for GUI Automation , author =. arXiv preprint arXiv:2508.15144 , year =
-
[30]
arXiv preprint arXiv:2508.20018 , year =
SWIRL: A Staged Workflow for Interleaved Reinforcement Learning in Mobile GUI Control , author =. arXiv preprint arXiv:2508.20018 , year =
-
[31]
arXiv preprint arXiv:2505.21493 , year =
Reinforcing General Reasoning without Verifiers , author =. arXiv preprint arXiv:2505.21493 , year =
-
[32]
arXiv preprint arXiv:2506.18254 , year =
RLPR: Extrapolating RLVR to General Domains without Verifiers , author =. arXiv preprint arXiv:2506.18254 , year =
-
[33]
arXiv preprint arXiv:2507.09884 , year =
VerifyBench: A Systematic Benchmark for Evaluating Reasoning Verifiers Across Domains , author =. arXiv preprint arXiv:2507.09884 , year =
-
[34]
arXiv preprint arXiv:2507.08794 , year =
One Token to Fool LLM-as-a-Judge , author =. arXiv preprint arXiv:2507.08794 , year =
-
[35]
arXiv preprint arXiv:2505.22203 , year =
Pitfalls of Rule-and Model-based Verifiers--A Case Study on Mathematical Reasoning , author =. arXiv preprint arXiv:2505.22203 , year =
-
[36]
2025 , eprint =
Kimi K2: Open Agentic Intelligence , author =. 2025 , eprint =
2025
-
[37]
arXiv preprint arXiv:2508.11356 , year =
ETTRL: Balancing Exploration and Exploitation in LLM Test-Time Reinforcement Learning Via Entropy Mechanism , author =. arXiv preprint arXiv:2508.11356 , year =
-
[38]
arXiv preprint arXiv:2508.03682 , year =
Self-Questioning Language Models , author =. arXiv preprint arXiv:2508.03682 , year =
-
[39]
arXiv preprint arXiv:2507.21931 , year =
Post-Training Large Language Models via Reinforcement Learning from Self-Feedback , author =. arXiv preprint arXiv:2507.21931 , year =
-
[40]
arXiv preprint arXiv:2502.10482 , year =
A Self-Supervised Reinforcement Learning Approach for Fine-Tuning Large Language Models Using Cross-Attention Signals , author =. arXiv preprint arXiv:2502.10482 , year =
-
[41]
arXiv preprint arXiv:2508.00410 , year =
Co-Reward: Self-supervised Reinforcement Learning for Large Language Model Reasoning via Contrastive Agreement , author =. arXiv preprint arXiv:2508.00410 , year =
-
[42]
arXiv preprint arXiv:2312.09390 , year =
Weak-to-strong generalization: Eliciting strong capabilities with weak supervision , author =. arXiv preprint arXiv:2312.09390 , year =
-
[43]
2025 , eprint =
ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents , author =. 2025 , eprint =
2025
-
[44]
Hugging Face repository , volume =
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions , author =. Hugging Face repository , volume =
-
[45]
arXiv preprint arXiv:2411.04872 , year =
Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai , author =. arXiv preprint arXiv:2411.04872 , year =
-
[46]
There may not be aha moment in r1-zero-like training—a pilot study , author =
-
[47]
arXiv preprint arXiv:2412.02674 , year =
Mind the gap: Examining the self-improvement capabilities of large language models , author =. arXiv preprint arXiv:2412.02674 , year =
-
[48]
arXiv preprint arXiv:2505.12493 , year =
UIShift: Enhancing VLM-based GUI Agents through Self-supervised Reinforcement Learning , author =. arXiv preprint arXiv:2505.12493 , year =
-
[49]
arXiv preprint arXiv:2508.05615 , year =
Test-Time Reinforcement Learning for GUI Grounding via Region Consistency , author =. arXiv preprint arXiv:2508.05615 , year =
-
[50]
arXiv preprint arXiv:2507.05720 , year =
MobileGUI-RL: Advancing Mobile GUI Agent through Reinforcement Learning in Online Environment , author =. arXiv preprint arXiv:2507.05720 , year =
-
[51]
arXiv preprint arXiv:2506.08012 , year =
GUI-Reflection: Empowering Multimodal GUI Models with Self-Reflection Behavior , author =. arXiv preprint arXiv:2506.08012 , year =
-
[52]
arXiv preprint arXiv:2506.04614 , year =
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation , author =. arXiv preprint arXiv:2506.04614 , year =
-
[53]
Advances in Neural Information Processing Systems , volume =
Learning formal mathematics from intrinsic motivation , author =. Advances in Neural Information Processing Systems , volume =
-
[54]
arXiv preprint arXiv:2502.03373 , year =
Demystifying long chain-of-thought reasoning in llms , author =. arXiv preprint arXiv:2502.03373 , year =
-
[55]
Open R1: A fully open reproduction of DeepSeek-R1 , url =
-
[56]
arXiv preprint arXiv:2508.05004 , year =
R-Zero: Self-Evolving Reasoning LLM from Zero Data , author =. arXiv preprint arXiv:2508.05004 , year =
-
[57]
arXiv preprint arXiv:2305.14483 , year =
Language model self-improvement by reinforcement learning contemplation , author =. arXiv preprint arXiv:2305.14483 , year =
-
[58]
arXiv preprint arXiv:2505.16637 , year =
SSR-Zero: Simple Self-Rewarding Reinforcement Learning for Machine Translation , author =. arXiv preprint arXiv:2505.16637 , year =
-
[59]
arXiv preprint arXiv:2401.01335 , year =
Self-play fine-tuning converts weak language models to strong language models , author =. arXiv preprint arXiv:2401.01335 , year =
-
[60]
Advances in Neural Information Processing Systems , volume =
Calibrated self-rewarding vision language models , author =. Advances in Neural Information Processing Systems , volume =
-
[61]
arXiv preprint arXiv:2504.14669 , year =
Trans-Zero: Self-Play Incentivizes Large Language Models for Multilingual Translation Without Parallel Data , author =. arXiv preprint arXiv:2504.14669 , year =
-
[62]
arXiv preprint arXiv:2505.19439 , year =
Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers , author =. arXiv preprint arXiv:2505.19439 , year =
-
[63]
arXiv preprint arXiv:2503.01307 , year =
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars , author =. arXiv preprint arXiv:2503.01307 , year =
-
[64]
arXiv preprint arXiv:2506.10943 , year =
Self-Adapting Language Models , author =. arXiv preprint arXiv:2506.10943 , year =
-
[65]
arXiv preprint arXiv:2504.16084 , year =
Ttrl: Test-time reinforcement learning , author =. arXiv preprint arXiv:2504.16084 , year =
-
[66]
arXiv preprint arXiv:2504.20571 , year =
Reinforcement learning for reasoning in large language models with one training example , author =. arXiv preprint arXiv:2504.20571 , year =
-
[67]
arXiv preprint arXiv:2504.05812 , year =
Right question is already half the answer: Fully unsupervised llm reasoning incentivization , author =. arXiv preprint arXiv:2504.05812 , year =
-
[68]
arXiv preprint arXiv:2505.19590 , year =
Learning to reason without external rewards , author =. arXiv preprint arXiv:2505.19590 , year =
-
[69]
arXiv preprint arXiv:2505.22617 , year =
The entropy mechanism of reinforcement learning for reasoning language models , author =. arXiv preprint arXiv:2505.22617 , year =
-
[70]
arXiv preprint arXiv:2505.20347 , year =
SeRL: Self-Play Reinforcement Learning for Large Language Models with Limited Data , author =. arXiv preprint arXiv:2505.20347 , year =
-
[71]
arXiv preprint arXiv:2506.08745 , year =
Consistent Paths Lead to Truth: Self-Rewarding Reinforcement Learning for LLM Reasoning , author =. arXiv preprint arXiv:2506.08745 , year =
-
[72]
arXiv preprint arXiv:2505.22660 , year =
Maximizing Confidence Alone Improves Reasoning , author =. arXiv preprint arXiv:2505.22660 , year =
-
[73]
Workshop on challenges in representation learning, ICML , volume =
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks , author =. Workshop on challenges in representation learning, ICML , volume =. 2013 , organization =
2013
-
[74]
arXiv preprint arXiv:2305.17493 , year =
The curse of recursion: Training on generated data makes models forget , author =. arXiv preprint arXiv:2305.17493 , year =
-
[75]
arXiv preprint arXiv:2401.10020 , volume =
Self-rewarding language models , author =. arXiv preprint arXiv:2401.10020 , volume =
-
[76]
arXiv preprint arXiv:2407.19594 , year =
Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge , author =. arXiv preprint arXiv:2407.19594 , year =
-
[77]
arXiv preprint arXiv:2503.03746 , year =
Process-based self-rewarding language models , author =. arXiv preprint arXiv:2503.03746 , year =
-
[78]
arXiv preprint arXiv:2506.10947 , year =
Spurious Rewards: Rethinking Training Signals in RLVR , author =. arXiv preprint arXiv:2506.10947 , year =
-
[79]
arXiv preprint arXiv:2505.22453 , year =
Unsupervised Post-Training for Multi-Modal LLM Reasoning via GRPO , author =. arXiv preprint arXiv:2505.22453 , year =
-
[80]
arXiv preprint arXiv:2506.06395 , year =
Confidence Is All You Need: Few-Shot RL Fine-Tuning of Language Models , author =. arXiv preprint arXiv:2506.06395 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.