When Hard Negatives Hurt: Bridging the Generative-Discriminative Gap in Hard Negative Synthesis for Retrieval
Pith reviewed 2026-06-28 17:08 UTC · model grok-4.3
The pith
Naively adding LLM-generated negatives to contrastive retrieval training often degrades performance because generation favors fluent text over strategic boundary violations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
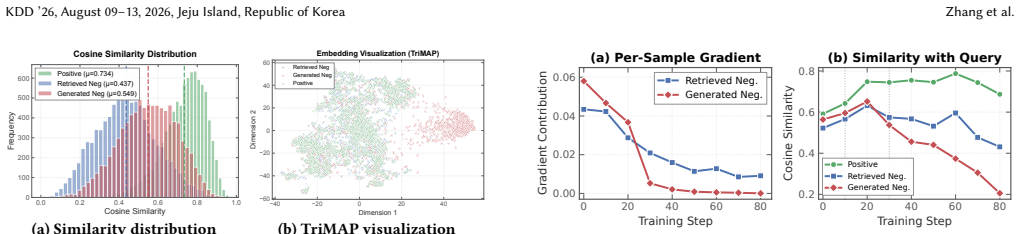
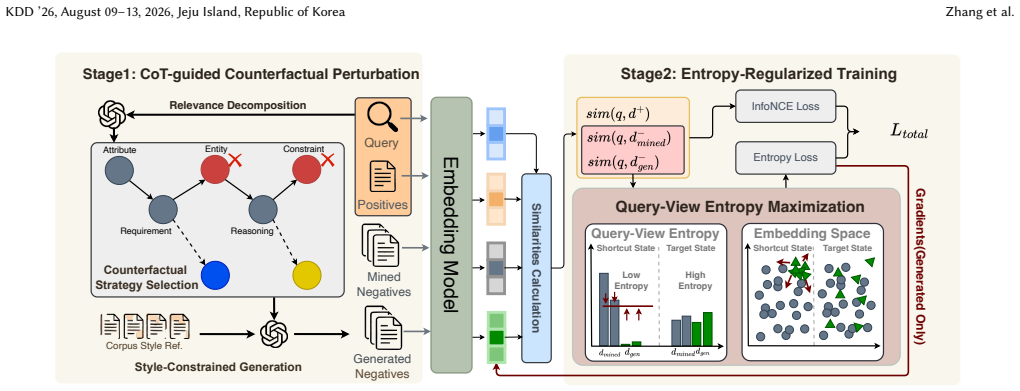
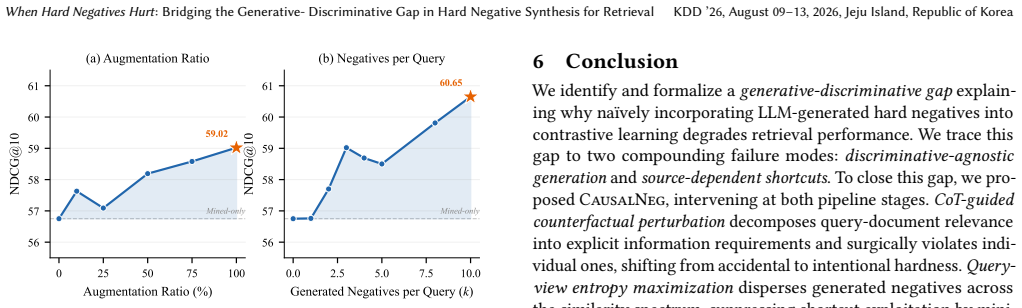
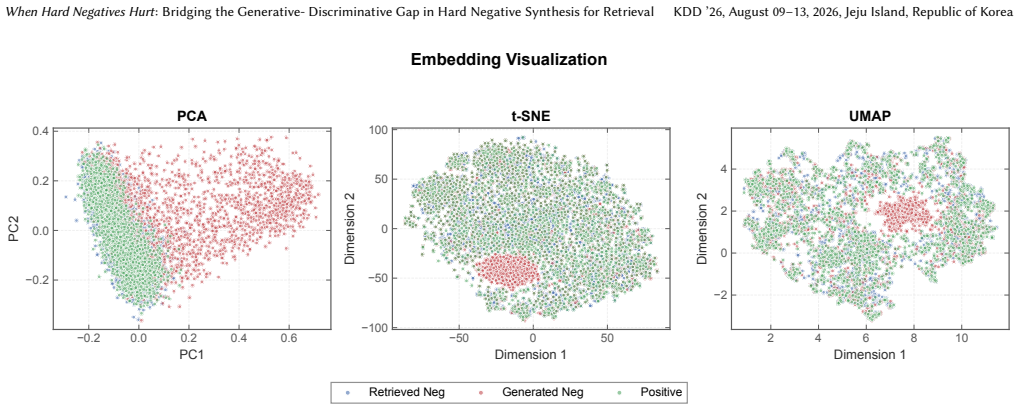
The root cause of performance degradation when using LLM-generated negatives is the generative-discriminative gap: generation optimizes for fluent, plausible text while contrastive learning requires negatives that strategically violate relevance at the decision boundary. This manifests as discriminative-agnostic generation, where the LLM lacks an explicit model of query information needs, and source-dependent shortcuts, where the model exploits origin artifacts rather than relevance. CausalNeg addresses both by (1) CoT-guided counterfactual perturbation that decomposes a document's relevance into explicit information requirements and surgically violates individual ones, and (2) query-view en
What carries the argument
CausalNeg, whose two modules are CoT-guided counterfactual perturbation (decomposes relevance into explicit requirements then violates them individually) and query-view entropy maximization (disperses negatives to suppress source shortcuts).
If this is right
- Negatives with explicitly controlled hardness supply genuine contrastive signal instead of generic or drifted text.
- Suppressing source-identity shortcuts prevents gradient drift that corrupts the similarity space.
- Synthetic negatives become a viable alternative to corpus mining once the generative-discriminative mismatch is removed.
- The same perturbation approach can be applied at inference time to generate diagnostic test cases for retriever evaluation.
Where Pith is reading between the lines
- The same decomposition-plus-violation pattern could be tested on other generative data-augmentation tasks such as synthetic query generation or paraphrase creation.
- If the entropy-maximization step is removed, shortcut exploitation should reappear and performance should fall back toward naive generation levels.
- The method assumes access to a capable LLM for CoT reasoning; weaker generators may not produce usable requirement lists and could widen the gap instead of closing it.
Load-bearing premise
Chain-of-thought decomposition can reliably break a document's relevance into explicit information requirements that can then be violated one at a time to produce negatives of controlled, interpretable hardness.
What would settle it
On a standard retrieval benchmark, training with CausalNeg-generated negatives yields no improvement or a clear drop relative to both corpus-mined hard negatives and naive LLM negatives.
Figures


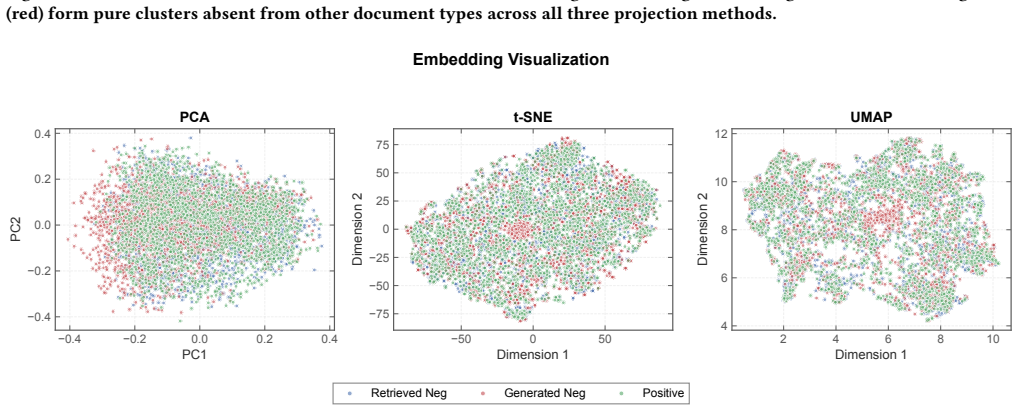
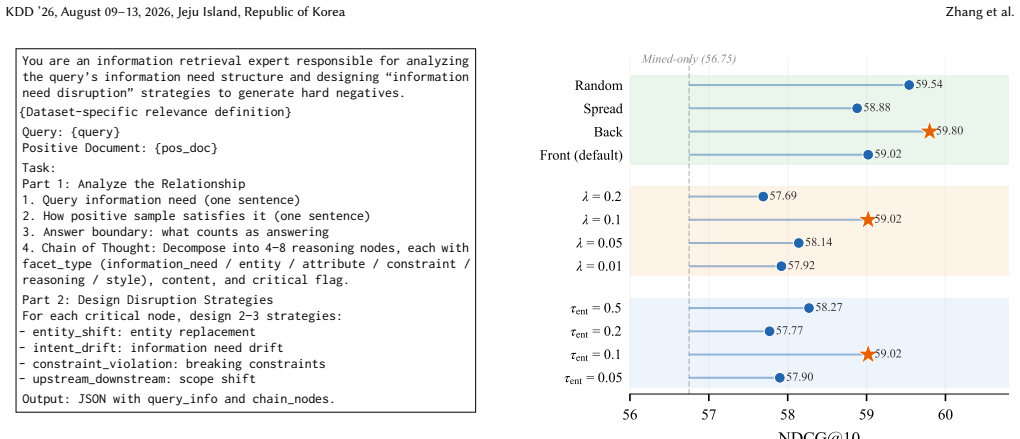
read the original abstract
Hard negative mining has become the dominant strategy for training retrievers, yet it faces intrinsic limitations: negatives are bounded by corpus availability, selected by retriever score rather than diagnostic value, and increasingly contaminated by false positives as the retriever improves. LLM-based synthesis offers a principled alternative, where negatives that are unconstrained, targeted, and free from false positive risk. But we show that naively incorporating generated negatives into contrastive learning often degrades retrieval performance. We identify and formalize the root cause as a generative-discriminative gap: LLM generation optimizes for fluent, plausible text, while contrastive learning demands strategic violations of relevance at the decision boundary. Our analysis reveals two compounding failure modes: discriminative-agnostic generation, where the LLM lacks an explicit model of query information needs and defaults to generic or topic-drifted text that provides no contrastive signal; and source-dependent shortcuts, where distributional artifacts enable the model to distinguish negatives by origin rather than relevance, causing gradient drift that actively corrupts optimization. To close this gap, we propose CausalNeg consisting of two main modules: (1) CoT-guided counterfactual perturbation for data construction: decomposes why a document satisfies a query into explicit information requirements, then surgically violates individual requirements to construct negatives with controlled, interpretable hardness. (2) Query-view entropy maximization during training: disperses generated negatives across the similarity spectrum, minimizing the mutual information between source identity and similarity scores to suppress shortcut exploitation. We make our code publicly available at https://github.com/mzhangzhicheng/CausalNeg.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that naively incorporating LLM-generated hard negatives into contrastive learning for retrieval often degrades performance. It identifies the root cause as a generative-discriminative gap, where LLM generation optimizes for fluent text while contrastive learning requires strategic relevance violations at the decision boundary. Two failure modes are formalized: discriminative-agnostic generation (lacking explicit query information needs) and source-dependent shortcuts (enabling distinction by origin). To close the gap, CausalNeg is proposed with two modules: (1) CoT-guided counterfactual perturbation, which decomposes document relevance into explicit information requirements and surgically violates individual ones for controlled hardness; (2) query-view entropy maximization during training to disperse negatives across the similarity spectrum and minimize mutual information between source identity and scores. Public code is released.
Significance. If the modules prove effective, the work addresses a practical limitation in hard negative synthesis for retrieval, offering a construction that supplies genuine contrastive signal rather than fluent but non-diagnostic text. The public code release is a clear strength supporting reproducibility.
major comments (1)
- [CoT-guided counterfactual perturbation module] The description of the CoT-guided counterfactual perturbation module: the central claim that this decomposition yields negatives with controlled, interpretable hardness aligned to the retriever decision boundary is load-bearing, yet the manuscript provides no independent verification (e.g., human evaluation of decomposition accuracy or ablation on boundary alignment) of whether the CoT step avoids inheriting the same LLM limitations on modeling query information needs that the paper itself diagnoses as the root problem.
minor comments (1)
- [Abstract] Abstract: a brief quantitative summary of the observed degradation from naive generation and the gains from CausalNeg would strengthen the presentation of the core claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [CoT-guided counterfactual perturbation module] The description of the CoT-guided counterfactual perturbation module: the central claim that this decomposition yields negatives with controlled, interpretable hardness aligned to the retriever decision boundary is load-bearing, yet the manuscript provides no independent verification (e.g., human evaluation of decomposition accuracy or ablation on boundary alignment) of whether the CoT step avoids inheriting the same LLM limitations on modeling query information needs that the paper itself diagnoses as the root problem.
Authors: We agree that the manuscript relies primarily on downstream retrieval metrics and module ablations rather than direct human evaluation of decomposition accuracy or explicit measurements of decision-boundary alignment. The empirical gains from CausalNeg over naive LLM generation provide indirect support that the CoT step produces more diagnostic negatives, but this does not constitute independent verification of the decomposition quality itself. In the revised manuscript we will add qualitative examples of the CoT decompositions together with an extended discussion of the approach's dependence on LLM reasoning fidelity and its relation to the diagnosed generative-discriminative gap. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces CausalNeg as a new construction with two modules (CoT-guided counterfactual perturbation for data construction and query-view entropy maximization during training) to address an identified generative-discriminative gap. No equations, derivations, or fitted parameters are presented that reduce by construction to inputs, self-definitions, or self-citation chains. The central claims rest on the proposed method and public code rather than any load-bearing self-referential step or renamed known result. This is the expected outcome for a methods paper without mathematical self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive learning for retrieval improves when supplied with hard negatives that lie near the relevance decision boundary.
Reference graph
Works this paper leans on
-
[1]
Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. 2022. InPars: Unsupervised Dataset Generation for Information Retrieval. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 2387–2392. doi:10....
-
[2]
Luiz Henrique Bonifacio, Israel Campiotti, Roberto Lotufo, and Rodrigo Nogueira
-
[3]
mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset. arXiv:2108.13897(2021)
-
[4]
Ricardo JGB Campello, Davoud Moulavi, and Jörg Sander. 2013. Density-based clustering based on hierarchical density estimates. InPacific-Asia conference on knowledge discovery and data mining. Springer, 160–172
2013
-
[5]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[6]
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. InFindings of the As- sociation for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 2318–2335. doi:10.18653/v1/2024.findings-acl.137
-
[7]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. InProceed- ings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 149, 11 pages
2020
-
[8]
Kuicai Dong, Yujing Chang, Derrick Goh Xin Deik, Dexun Li, Ruiming Tang, and Yong Liu. 2025. MMDocIR: Benchmarking Multimodal Retrieval for Long Documents. InProceedings of the 2025 Conference on Empirical Methods in Nat- ural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Comput...
- [9]
-
[10]
Kuicai Dong, Derrick Goh Xin Deik, Yi Quan Lee, Hao Zhang, Xiangyang Li, Cong Zhang, and Yong Liu. 2024. MC-indexing: Effective Long Document Re- trieval via Multi-view Content-aware Indexing. InFindings of the Association KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Zhang et al. for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, ...
-
[11]
Kuicai Dong, Shurui Huang, Fangda Ye, Wei Han, Zhi Zhang, Dexun Li, Wen- jun Li, Qu Yang, Gang Wang, Yichao Wang, Chen Zhang, and Yong Liu. 2025. Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research. arXiv:2510.21603 [cs.IR] https://arxiv.org/abs/2510.21603
-
[12]
Zeyu Gan and Yong Liu. 2025. Towards a Theoretical Understanding of Synthetic Data in LLM Post-Training: A Reverse-Bottleneck Perspective. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/ forum?id=UxkznlcnHf
2025
-
[13]
Pengyue Jia, Derong Xu, Xiaopeng Li, Zhaocheng Du, Xiangyang Li, Yichao Wang, Yuhao Wang, Qidong Liu, Maolin Wang, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. 2025. Bridging Relevance and Reasoning: Rationale Distillation in Retrieval-Augmented Generation. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende,...
-
[14]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Regina Barzilay and Min-Yen Kan (Eds.). Association for Computational Linguistics, V...
2017
-
[15]
Jaehun Jung, Seungju Han, Ximing Lu, Skyler Hallinan, David Acuna, Shrimai Prabhumoye, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, and Yejin Choi. 2025. Prismatic Synthesis: Gradient-based Data Diversification Boosts Gen- eralization in LLM Reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview...
2025
-
[16]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Com...
-
[17]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research.Tr...
-
[18]
Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gustavo Hernández Ábrego, Zhe Li, Kaifeng Chen, Henrique Schechter Vera, Xiaoqi Ren, Shanfeng Zhang, Daniel Salz, Michael Boratko, Jay Han, Blair Chen, Shuo Huang, Vikram Rao, Paul Suganthan, Feng Han, Andreas Doumanoglou, Nithi Gupta, Fedor Moiseev, Cathy Yip, Aashi Jain...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Xiangyang Li, Kuicai Dong, Yi Quan Lee, Wei Xia, Hao Zhang, Xinyi Dai, Yasheng Wang, and Ruiming Tang. 2025. CoIR: A Comprehensive Benchmark for Code Information Retrieval Models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad T...
2025
- [20]
-
[21]
Zhiteng Li, Lele Chen, Jerone Andrews, Yunhao Ba, Yulun Zhang, and Alice Xiang. 2025. GenDataAgent: On-the-fly Dataset Augmentation with Synthetic Data. InInternational Conference on Learning Represen- tations, Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (Eds.), Vol. 2025. 48578–48598. https://proceedings.iclr.cc/paper_files/paper/2025/file/ 79081c9548270...
2025
-
[22]
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. 2024. On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 11...
2024
-
[23]
Moreira, Radek Osmulski, Mengyao Xu, Ronay Ak, Benedikt Schifferer, and Even Oldridge
Gabriel de Souza P. Moreira, Radek Osmulski, Mengyao Xu, Ronay Ak, Benedikt Schifferer, and Even Oldridge. 2025. Improving Text Embedding Models with Positive-aware Hard-negative Mining. InProceedings of the 34th ACM Interna- tional Conference on Information and Knowledge Management(Seoul, Republic of Korea)(CIKM ’25). Association for Computing Machinery,...
-
[24]
Le, Long Tran-Thanh, and Khoat Than
Lan-Cuong Nguyen, Quan Nguyen-Tri, Bang Tran Khanh, Dung D. Le, Long Tran-Thanh, and Khoat Than. 2025. Provably Improving Generalization of Few- shot models with Synthetic Data. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=L6U7nYc4ah
2025
-
[25]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. InProceedings of the Workshop on Cogni- tive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Syste...
2016
-
[26]
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. 2021. RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question An- swering. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T...
-
[27]
Jiyuan Ren, Zhaocheng Du, Zhihao Wen, Qinglin Jia, Sunhao Dai, Chuhan Wu, and Zhenhua Dong. 2025. Few-shot LLM Synthetic Data with Distribution Matching. InCompanion Proceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machinery, New York, NY, USA, 432–441. doi:10.1145/3701716.3715245
-
[28]
Stephen E Robertson and Steve Walker. 1994. Some simple effective approxi- mations to the 2-poisson model for probabilistic weighted retrieval. InSIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, organised by Dublin City University. Springer, 232–241
1994
-
[29]
Joshua David Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. 2021. Contrastive Learning with Hard Negative Samples. InInternational Conference on Learning Representations. https://openreview.net/forum?id=CR1XOQ0UTh-
2021
-
[30]
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. 2024. AI models collapse when trained on recursively generated data.Nature631, 8022 (2024), 755–759
2024
-
[31]
Morris, Jyoti Aneja, Alexander Rush, and Jianfeng Gao
Chandan Singh, John X. Morris, Jyoti Aneja, Alexander Rush, and Jianfeng Gao
-
[32]
Explaining Data Patterns in Natural Language with Language Models. In Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, Yonatan Belinkov, Sophie Hao, Jaap Jumelet, Najoung Kim, Arya McCarthy, and Hosein Mohebbi (Eds.). Association for Computational Linguistics, Singapore, 31–55. doi:10.18653/v1/2023.blackboxnlp-1.3
-
[33]
Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith, and Yejin Choi. 2020. Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). ...
-
[34]
Jiwei Tang, Zhijing Huang, Xinyu Zhang, Chen Jason Zhang, Jianxing Yu, Libin Zheng, Rui Meng, and Jian Yin. 2026. Beyond Position Bias: Shifting Context Compression from Position-Driven to Semantic-Driven. arXiv:2605.09463 [cs.CL] https://arxiv.org/abs/2605.09463
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Jiwei Tang, Shilei Liu, Zhicheng Zhang, Qingsong Lv, Runsong Zhao, Tingwei Lu, Langming Liu, Haibin Chen, Yujin Yuan, Hai-Tao Zheng, Wenbo Su, and Bo Zheng
-
[36]
arXiv:2602.01840 [cs.CL] https://arxiv.org/abs/2602.01840
Read As Human: Compressing Context via Parallelizable Close Reading and Skimming. arXiv:2602.01840 [cs.CL] https://arxiv.org/abs/2602.01840
-
[37]
Jiwei Tang, Shilei Liu, Zhicheng Zhang, Yujin Yuan, Libin Zheng, Wenbo Su, and Bo Zheng. 2026. COMI: Coarse-to-fine Context Compression via Marginal Information Gain. InThe Fourteenth International Conference on Learning Repre- sentations. https://openreview.net/forum?id=OGDIXDfaN4
2026
-
[38]
Jiwei Tang, Jin Xu, Tingwei Lu, Zhicheng Zhang, Yiming Zhao, Lin Hai, and Hai-Tao Zheng. 2025. Perception Compressor: A Training-Free Prompt Com- pression Framework in Long Context Scenarios. InFindings of the Association for Computational Linguistics: NAACL 2025, Luis Chiruzzo, Alan Ritter, and Lu Wang (Eds.). Association for Computational Linguistics, A...
-
[39]
Jiwei Tang, Zhicheng Zhang, Shunlong Wu, Jingheng Ye, Lichen Bai, Zitai Wang, Tingwei Lu, Lin Hai, Yiming Zhao, Hai-Tao Zheng, and Hong-Gee Kim. 2026. GMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment. arXiv:2505.12215 [cs.CL] https://arxiv.org/abs/2505.12215
-
[40]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InThirty-fifth Conference on Neural Information When Hard Negatives Hurt: Bridging the Generative- Discriminative Gap in Hard Negative Synthesis for Retrieval KDD ’26, August ...
2021
-
[41]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2019. Representation Learning with Contrastive Predictive Coding. arXiv:1807.03748 [cs.LG] https://arxiv.org/ abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[42]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Improving text embeddings with large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 11897–11916
2024
-
[43]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’22). Curran Associates Inc., Red Hook, NY...
2022
-
[44]
Bennett, Junaid Ahmed, and Arnold Overwijk
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate Nearest Neighbor Neg- ative Contrastive Learning for Dense Text Retrieval. InInternational Conference on Learning Representations. https://openreview.net/forum?id=zeFrfgyZln
2021
-
[45]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (...
-
[46]
Zhen Yang, Zhou Shao, Yuxiao Dong, and Jie Tang. 2024. TriSampler: a better negative sampling principle for dense retrieval. InProceedings of the Thirty- Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intellig...
-
[47]
Andrew Yates, Rodrigo Nogueira, and Jimmy Lin. 2021. Pretrained Transformers for Text Ranking: BERT and Beyond. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Tutorials, Greg Kondrak, Kalina Bontcheva, and Dan Gillick (Eds.). Association for Computational Li...
2021
-
[48]
Jingtao Zhan, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang, and Shaop- ing Ma. 2021. Optimizing Dense Retrieval Model Training with Hard Neg- atives. InProceedings of the 44th International ACM SIGIR Conference on Re- search and Development in Information Retrieval(Virtual Event, Canada)(SIGIR ’21). Association for Computing Machinery, New York, NY, USA,...
-
[49]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[50]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Zhicheng Zhang, Zhaocheng Du, Jieming Zhu, Jiwei Tang, Fengyuan Lu, Wang Jiaheng, Song-Li Wu, Qianhui Zhu, Jingyu Li, Hai-Tao Zheng, and Zhenhua Dong
-
[52]
arXiv:2601.19142 [cs.AI] https://arxiv.org/abs/2601
Length-Adaptive Interest Network for Balancing Long and Short Sequence Modeling in CTR Prediction. arXiv:2601.19142 [cs.AI] https://arxiv.org/abs/2601. 19142
-
[53]
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen
-
[54]
SWIFT: a scalable lightweight infrastructure for fine-tuning. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Sympo- sium on Educational Advances in Artificial Intelligence (AAAI’25/IAAI’25/EAAI’25). AAAI Press, Article 3485, 3 pa...
-
[55]
Ruiqi Zhong, Charlie Snell, Dan Klein, and Jacob Steinhardt. 2022. Describing Differences between Text Distributions with Natural Language. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato ...
2022
-
[56]
Kun Zhou, Yeyun Gong, Xiao Liu, Wayne Xin Zhao, Yelong Shen, Anlei Dong, Jingwen Lu, Rangan Majumder, Ji-rong Wen, and Nan Duan. 2022. SimANS: Simple Ambiguous Negatives Sampling for Dense Text Retrieval. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, Yunyao Li and Angeliki Lazaridou (Eds.). Assoc...
-
[57]
good” and “bad
Xuekai Zhu, Daixuan Cheng, Hengli Li, Kaiyan Zhang, Ermo Hua, Xingtai Lv, Ning Ding, Zhouhan Lin, Zilong Zheng, and Bowen Zhou. 2025. How to Synthe- size Text Data without Model Collapse?. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=ihUi76a4u7 A Detailed LLM Diagnostic Results This section provides comprehe...
2025
-
[58]
Query information need (one sentence)
-
[59]
How positive sample satisfies it (one sentence)
-
[60]
Answer boundary: what counts as answering
-
[61]
Chain of Thought: Decompose into 4–8 reasoning nodes, each with facet_type (information_need / entity / attribute / constraint / reasoning / style), content, and critical flag. Part 2: Design Disruption Strategies For each critical node, design 2–3 strategies: - entity_shift: entity replacement - intent_drift: information need drift - constraint_violation...
-
[62]
Cannot answer the query in any form (correct, incorrect, or partial)
-
[63]
Prioritize rewriting candidate negatives; preserve their style and noise
-
[64]
{Dataset-specific writing style constraints} Output: JSON with node_id, strategy_id, generated text, and break_explanation
Only generate from scratch if no candidates fit; simulate real corpus style. {Dataset-specific writing style constraints} Output: JSON with node_id, strategy_id, generated text, and break_explanation. Figure 10: Condensed Step 3 prompt template for constrained hard negative generation. query are used by default for fair comparison with vanilla gener- atio...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.