Reducing Token Usage of State-in-Context Agents using Minification
Pith reviewed 2026-06-28 16:39 UTC · model grok-4.3
The pith
Minifying source code in state-in-context agents cuts average input token use by 42 percent while dropping resolution rate by 12 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
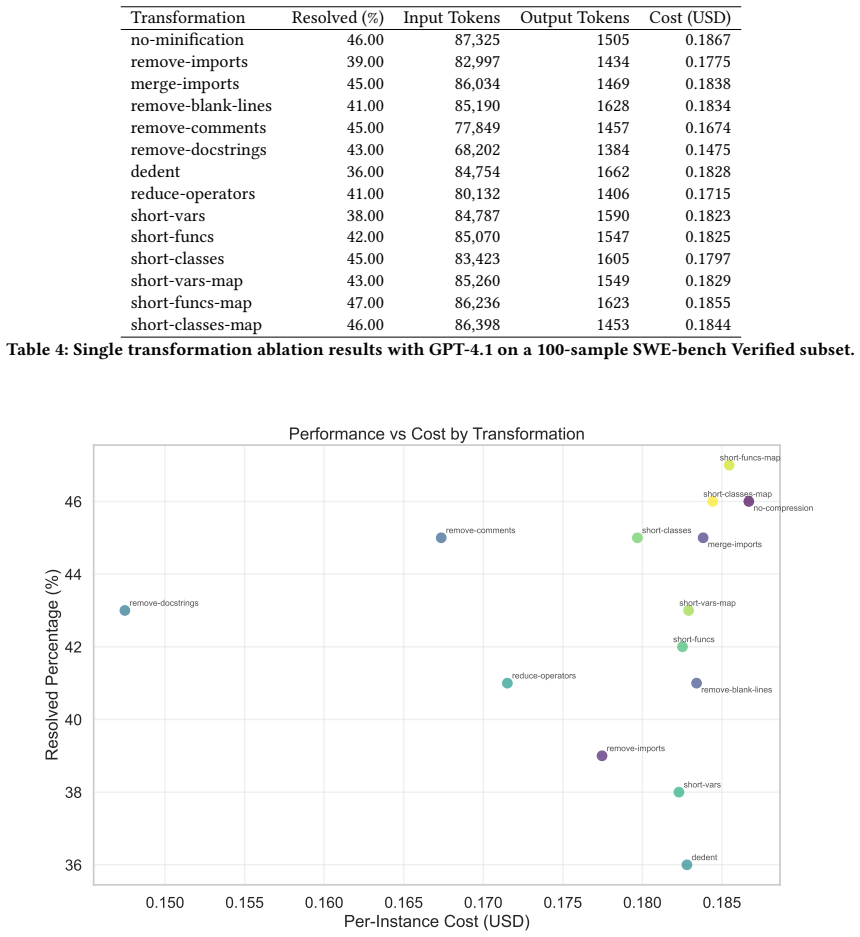
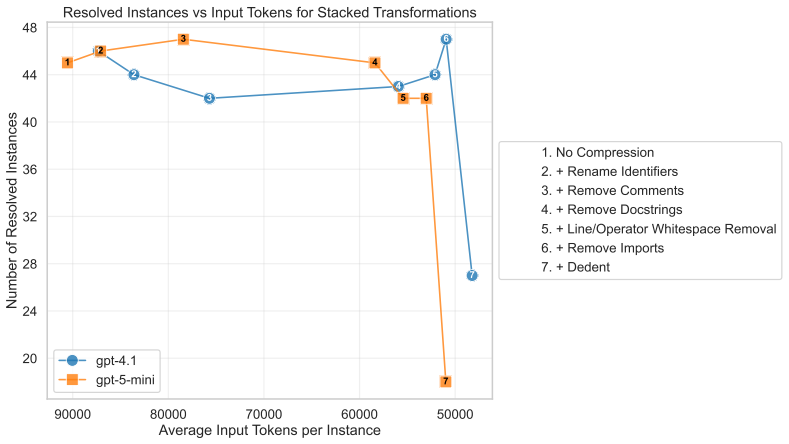
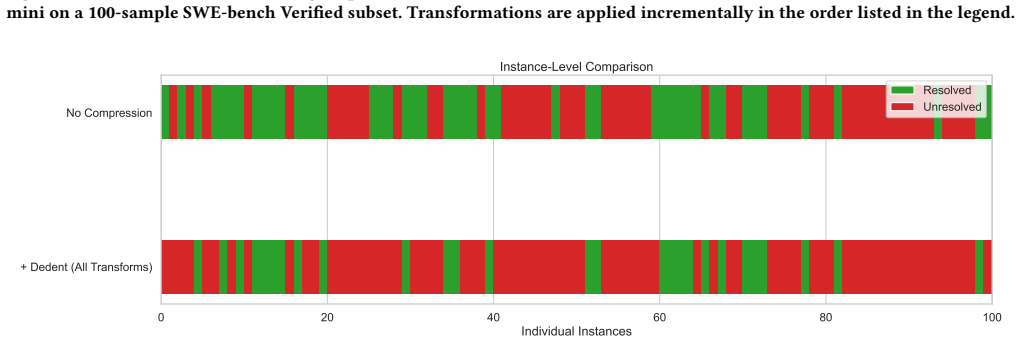
By integrating code minification transformations into the state-in-context agent, average input token usage falls by 42 percent and resolution rate on SWE-bench Verified declines by 12 percentage points from the unminified baseline, while still retaining a substantial fraction of the original performance.
What carries the argument
Code minification transformations that shorten or remove non-essential lexical elements from source code while preserving program semantics.
If this is right
- Agents can handle larger code contexts inside fixed token budgets.
- The same transformations can be added to other agent pipelines to lower inference cost.
- The observed retention of most baseline performance shows that the minification steps are largely semantics-preserving for the tasks tested.
- Full-benchmark numbers supply a concrete reference point for measuring future token-reduction methods.
Where Pith is reading between the lines
- Selective application of only the least disruptive minification steps could narrow the performance gap.
- The same token-saving pattern may appear in other LLM-based coding systems that ingest full source files.
- The results point to a broader design choice between context richness and cost that future agent work will need to navigate.
Load-bearing premise
The chosen minification steps keep enough of the original program meaning that the agent's reasoning and repair steps stay effective enough to produce the reported performance level.
What would settle it
Re-running the identical agent and benchmark with and without each minification step while logging whether the performance drop correlates with specific semantic changes introduced by the transformations.
Figures

read the original abstract
This paper presents a replication and extension of the recently introduced state-in-context agent framework. We independently re-implement the DirectSolve variant and evaluate it on the SWE-bench Verified benchmark. We report end-to-end full-benchmark results using GPT-5-mini and run selected ablations with GPT-4.1. In addition, we investigate a complementary research question: What is the impact of token-reducing input transformation strategies on the performance of software engineering agents? Based on a preliminary prompt analysis, we identify source code as the dominant contributor to token consumption. We therefore apply a series of code minification techniques that remove or shorten non-essential lexical elements while preserving program semantics. The proposed transformations are integrated into the agent and systematically evaluated. Experiments show that minification reduces average input token usage by 42% with a 12 percentage-point drop in resolution rate. These findings demonstrate that lightweight source code transformations can yield substantial efficiency gains while retaining a substantial fraction of the baseline performance, indicating a promising path toward more cost-effective agents. The full implementation is publicly available on GitHub: https://github.com/ipa-lab/minified-state-in-context-agent
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper re-implements the DirectSolve variant of the state-in-context agent framework and evaluates it end-to-end on SWE-bench Verified using GPT-5-mini (with selected ablations on GPT-4.1). It additionally proposes a set of code minification transformations applied to source code in the agent inputs, claiming these reduce average input token usage by 42% while incurring only a 12 percentage-point drop in resolution rate.
Significance. If the central empirical result holds, the work shows that lightweight, semantics-preserving input transformations can deliver substantial efficiency gains for state-in-context software engineering agents. The public release of the full implementation is a clear strength that supports reproducibility and follow-on work.
major comments (1)
- [Minification techniques (following the preliminary prompt analysis)] The description of the minification techniques asserts that they 'remove or shorten non-essential lexical elements while preserving program semantics,' yet supplies no supporting evidence (no test-suite equivalence checks, no behavioral comparison of agent outputs on original vs. minified code, and no formal argument). This is load-bearing for the headline claim, because the observed 12pp resolution drop could be explained by corrupted task inputs rather than by the intended efficiency mechanism.
minor comments (2)
- The reported end-to-end numbers lack any information on variance, statistical significance, or confidence intervals.
- No details are given on the fidelity of the re-implementation relative to the original DirectSolve work.
Simulated Author's Rebuttal
Thank you for the constructive review and recommendation. We address the major comment below.
read point-by-point responses
-
Referee: [Minification techniques (following the preliminary prompt analysis)] The description of the minification techniques asserts that they 'remove or shorten non-essential lexical elements while preserving program semantics,' yet supplies no supporting evidence (no test-suite equivalence checks, no behavioral comparison of agent outputs on original vs. minified code, and no formal argument). This is load-bearing for the headline claim, because the observed 12pp resolution drop could be explained by corrupted task inputs rather than by the intended efficiency mechanism.
Authors: We agree that the manuscript would be strengthened by explicit evidence for semantic preservation. The original submission described the transformations (comment removal, whitespace normalization, and safe identifier shortening) as standard lexical minifications but did not include verification. In the revised version we will add: (1) test-suite equivalence results on a sample of 20 SWE-bench Verified repositories showing that minified code passes the same tests as the original, and (2) a behavioral comparison of agent outputs on a small subset of tasks using both original and minified inputs. These empirical checks will support that the 12pp drop stems from the efficiency mechanism rather than input corruption. A full formal argument for arbitrary programs is outside the paper's scope. revision: yes
Circularity Check
Empirical replication study with no derivation chain or fitted predictions
full rationale
The paper is a replication and measurement study: it re-implements an agent, applies a fixed set of code minification transformations, and reports direct experimental outcomes (token counts and resolution rates) on SWE-bench Verified. No equations, parameters, or predictions are defined; the results are raw benchmark measurements. No self-citation load-bearing steps, ansatzes, or renamings appear. The semantic-preservation assumption is an unvalidated modeling choice but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. 2024. Introducing SWE-bench Verified. https://openai.com/index/introducing-swe- bench-verified/ Accessed: 2025-10-04
2024
-
[2]
Gheorghe Comanici et al. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabil- ities.CoRRabs/2507.06261 (2025). arXiv:2507.06261 doi:10.48550/ARXIV.2507. 06261
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507 2025
-
[3]
2025.Context Rot: How Increasing Input Tokens Impacts LLM Performance
Kelly Hong, Anton Troynikov, and Jeff Huber. 2025.Context Rot: How Increasing Input Tokens Impacts LLM Performance. Technical Report. Chroma. https: //research.trychroma.com/context-rot
2025
-
[4]
Lastras, Pavan Kapanipathi, and Tatsunori Hashimoto
Mingjian Jiang, Yangjun Ruan, Luis A. Lastras, Pavan Kapanipathi, and Tatsunori Hashimoto. 2025. Putting It All into Context: Simplifying Agents with LCLMs. CoRRabs/2505.08120 (2025). arXiv:2505.08120 doi:10.48550/ARXIV.2505.08120
-
[5]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=VTF8yNQM66
2024
-
[6]
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. 2025. LLMs Get Lost In Multi-Turn Conversation.CoRRabs/2505.06120 (2025). arXiv:2505.06120 doi:10.48550/ARXIV.2505.06120
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.06120 2025
-
[7]
Tobias Lindenbauer, Igor Slinko, Ludwig Felder, Egor Bogomolov, and Yaroslav Zharov. 2025. The Complexity Trap: Simple Observation Masking Is as Efficient as LLM Summarization for Agent Context Management.CoRRabs/2508.21433 (2025). arXiv:2508.21433 doi:10.48550/ARXIV.2508.21433
-
[8]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Trans. Assoc. Comput. Linguistics12 (2024), 157–173. doi:10. 1162/TACL_A_00638
2024
-
[9]
MDN. [n. d.]. Minification — MDN Web Docs. https://developer.mozilla.org/en- US/docs/Glossary/Minification Accessed: 2025-10-16
2025
-
[10]
OpenAI. [n. d.]. OpenAI API Pricing. https://platform.openai.com/docs/pricing. [accessed 2025-12-04]
2025
-
[11]
OpenAI. 2025. Introducing GPT-5. https://openai.com. Accessed: 2025-09-11
2025
-
[12]
OpenAI. 2025. tiktoken: fast BPE tokenizer for use with OpenAI’s models. https: //github.com/openai/tiktoken. [accessed 2025-12-04]
2025
-
[13]
OpenAI and Josh Achiam et al. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv.org/abs/2303.08774
Pith/arXiv arXiv 2024
-
[14]
Dangfeng Pan, Zhensu Sun, Cenyuan Zhang, David Lo, and Xiaoning Du. 2025. The Hidden Cost of Readability: How Code Formatting Silently Consumes Your LLM Budget.CoRRabs/2508.13666 (2025). arXiv:2508.13666 doi:10.48550/ARXIV. 2508.13666
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[15]
Chi, Nathanael Schärli, and Denny Zhou
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. 2023. Large Language Models Can Be Easily Distracted by Irrelevant Context. InInternational Conference on Machine Learn- ing, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research, Vol. 202), Andreas Kraus...
2023
-
[16]
Krithik Vishwanath, Anton Alyakin, Daniel Alexander Alber, Jin Vivian Lee, Douglas Kondziolka, and Eric Karl Oermann. 2025. Medical large language models are easily distracted. arXiv:2504.01201 [cs.CL] https://arxiv.org/abs/2504.01201
arXiv 2025
-
[17]
You Wang, Michael Pradel, and Zhongxin Liu. 2025. Are "Solved Issues" in SWE- bench Really Solved Correctly? An Empirical Study.CoRRabs/2503.15223 (2025). arXiv:2503.15223 doi:10.48550/ARXIV.2503.15223
-
[18]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying LLM-based Software Engineering Agents.CoRR abs/2407.01489 (2024). arXiv:2407.01489 doi:10.48550/ARXIV.2407.01489
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.01489 2024
-
[19]
Yuan-An Xiao, Pengfei Gao, Chao Peng, and Yingfei Xiong. 2025. Improving the Efficiency of LLM Agent Systems through Trajectory Reduction.CoRR abs/2509.23586 (2025). arXiv:2509.23586 doi:10.48550/ARXIV.2509.23586
-
[20]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Inter- faces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, Dece...
2024
-
[21]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, Ellen Riloff, D...
-
[22]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, Sanmi Koyejo, S. M...
2022
-
[23]
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. 2025. MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents.CoRR abs/2506.15841 (2025). arXiv:2506.15841 doi:10.48550/ARXIV.2506.15841
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.15841 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.