Dive into Ambiguity: A*-Inspired Multi-Agents Commonsense Obfuscation Attack on LLM Prompts
Pith reviewed 2026-06-28 16:52 UTC · model grok-4.3
The pith
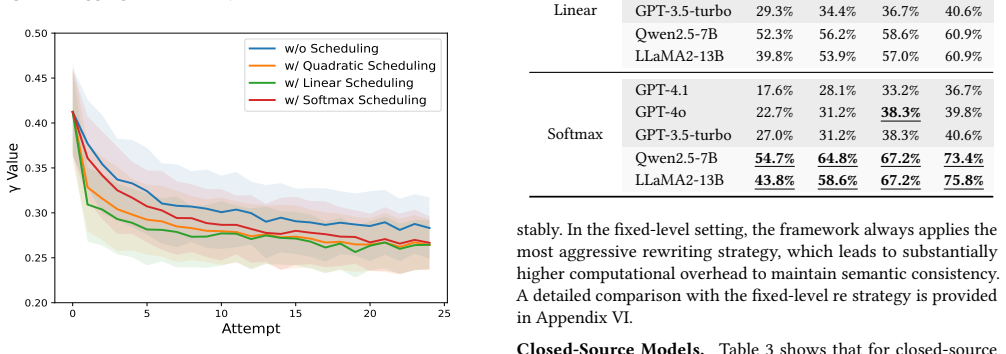
Prompt rewriting follows a contractive recurrence leading to semantic collapse as γ decreases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
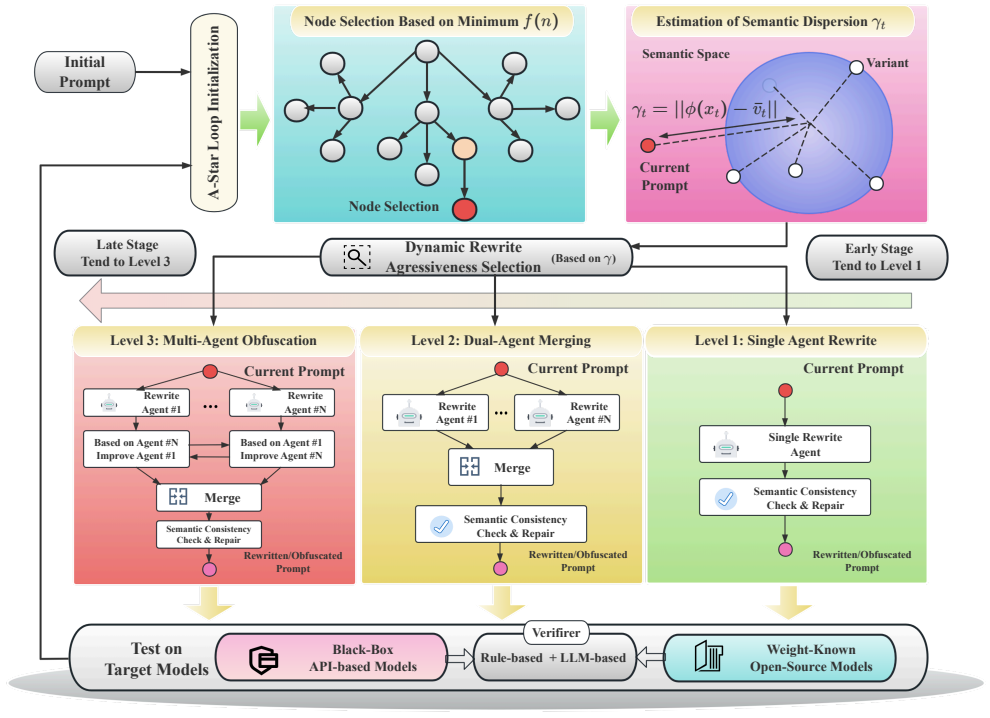
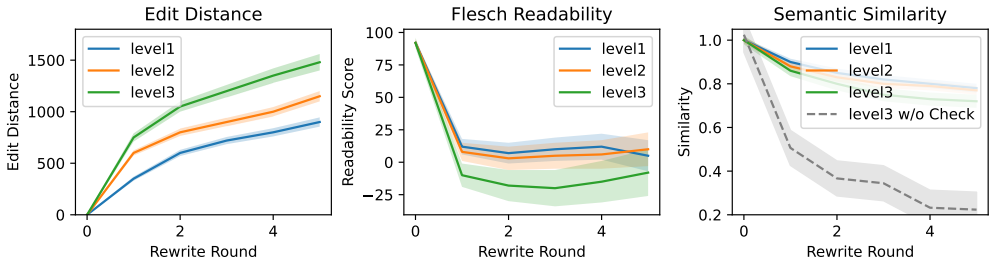
The central discovery is that the process of rewriting prompts according to the hierarchical strategy with dynamic γ follows a contractive recurrence. This mathematical property means that repeated applications of the rewrite rule bring the prompt's semantics closer together in a contracting manner, resulting in semantic collapse when γ is reduced. This allows the generation of prompts that are initially close in meaning but become sufficiently ambiguous to induce factual errors in LLMs.
What carries the argument
The Hierarchical Rewrite Strategy guided by the dynamic semantic dispersion coefficient γ, which applies conservative edits first and more aggressive ones later in a reverse simulated annealing manner to achieve progressive obfuscation.
If this is right
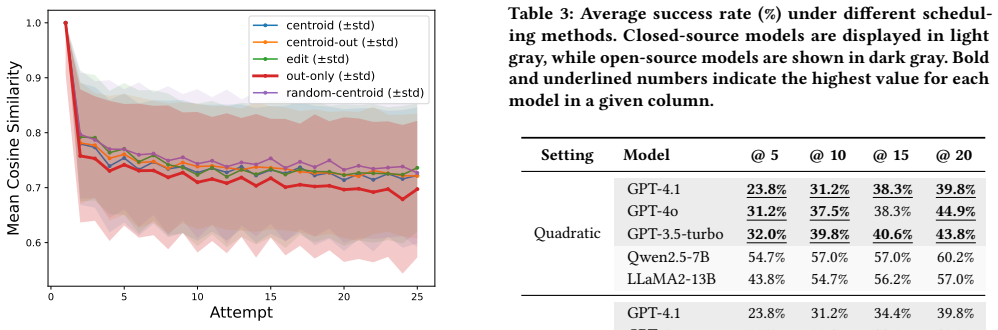
- The method yields higher attack success rates than exhaustive exploration on various LLMs.
- Fewer attempts are needed to find effective adversarial prompts.
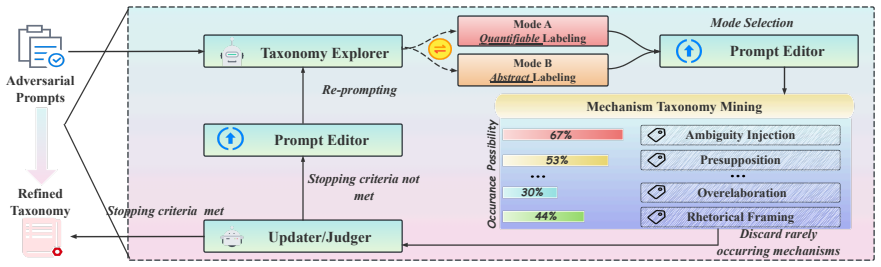
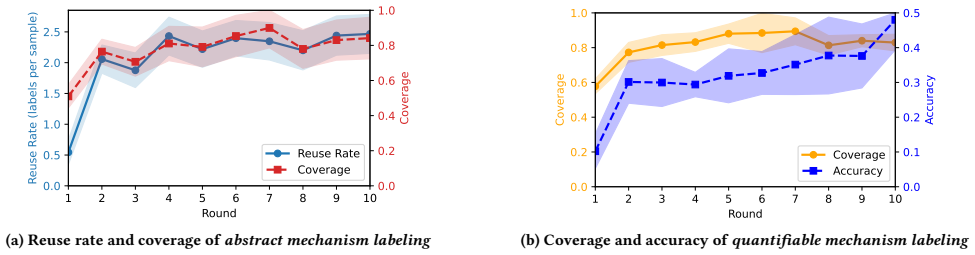
- Agentic Mechanism Labeling allows discovery of the underlying adversarial mechanisms for better understanding.
- The theoretical contractive recurrence explains why the obfuscation works without losing intent.
Where Pith is reading between the lines
- This approach could be adapted to improve robustness testing for LLMs in other error types beyond commonsense.
- Defenses might focus on detecting when prompts have undergone such contractive transformations.
- Similar recurrence ideas may apply to other search-based optimization in AI systems.
Load-bearing premise
The dynamic γ schedule in the hierarchical rewrites keeps enough semantic alignment with the original prompt so that the collapse remains useful for attacks without destroying the intent.
What would settle it
Run the rewrite process on a set of prompts while tracking a semantic similarity metric at each step of decreasing γ; the claim is false if similarity does not drop in the contracting pattern predicted or if attacks fail to improve.
Figures

read the original abstract
Large language models (LLMs) excel in reasoning and knowledge-intensive tasks but remain vulnerable to prompt-level adversarial attacks that preserve intent while triggering commonsense hallucinations. This vulnerability is urgent, as LLMs are rapidly integrated into safety-critical domains where factual reliability is non-negotiable. Existing attack methods either lack efficiency or fail to capture the adaptive strategies of real-world adversaries. We propose an A*-inspired Factual Error Induction Framework, a framework for generating semantically aligned yet obfuscated prompts. At its core is a Hierarchical Rewrite Strategy guided by a dynamic semantic dispersion coefficient $\gamma$ that balances conservative edits early with aggressive obfuscations later, following a reverse simulated annealing schedule. To enhance interpretability, we further introduce Agentic Mechanism Labeling, which discovers and refines adversarial mechanisms, offering interpretable reverse optimization. Theoretically, we prove that prompt rewriting follows a contractive recurrence, leading to semantic collapse as $\gamma$ decreases. Empirically, across diverse LLMs, our method achieves higher attack success rates than exhaustive exploration while requiring fewer attempts, demonstrating both efficiency and effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an A*-inspired Factual Error Induction Framework for generating semantically aligned yet obfuscated prompts to attack LLMs by inducing commonsense hallucinations. Its core is a Hierarchical Rewrite Strategy using a dynamic semantic dispersion coefficient γ under a reverse simulated annealing schedule, augmented by Agentic Mechanism Labeling for interpretability. The authors assert a theoretical proof that prompt rewriting obeys a contractive recurrence leading to semantic collapse as γ decreases, and report empirical results showing higher attack success rates than exhaustive exploration with fewer attempts across diverse LLMs.
Significance. If the contractive recurrence proof is rigorous and the empirical comparisons include proper controls, error bars, and reproducible implementations, the work could advance understanding of intent-preserving adversarial prompts and motivate stronger LLM defenses. The multi-agent A* guidance and mechanism labeling offer potential for interpretability gains not present in prior exhaustive or random attack baselines.
major comments (2)
- [Abstract / Theoretical claim] Abstract and theoretical section: the central claim that prompt rewriting follows a contractive recurrence leading to semantic collapse as γ decreases is load-bearing, yet the abstract supplies no derivation steps, fixed-point analysis, or Lipschitz constant for the mapping. Without these, it is impossible to verify that the recurrence contracts on the original intent rather than a drifted meaning.
- [Abstract] Abstract, hierarchical rewrite description: the reverse simulated annealing schedule with dynamic γ is asserted to preserve semantic alignment while increasing obfuscation, but no per-step semantic-distance bound or intent-preservation threshold is stated. This assumption is required for the contraction mapping to remain valid on the intended meaning; its absence makes the theoretical implication non-demonstrable from the given material.
minor comments (2)
- [Abstract] No datasets, attack success rate definitions, baselines, or error bars are referenced in the abstract, preventing assessment of the empirical superiority claim.
- [Abstract] Notation for γ is introduced as both 'dynamic' and controlling the schedule, but its exact functional form and update rule are not supplied.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our theoretical claims. We address each major comment below and will revise the manuscript to include the requested derivations, bounds, and analyses.
read point-by-point responses
-
Referee: [Abstract / Theoretical claim] Abstract and theoretical section: the central claim that prompt rewriting follows a contractive recurrence leading to semantic collapse as γ decreases is load-bearing, yet the abstract supplies no derivation steps, fixed-point analysis, or Lipschitz constant for the mapping. Without these, it is impossible to verify that the recurrence contracts on the original intent rather than a drifted meaning.
Authors: We agree that the abstract and theoretical section would benefit from explicit derivation steps, fixed-point analysis, and the Lipschitz constant to allow verification. In the revision we will expand the abstract with a concise outline of these elements and augment the theoretical section with the full recurrence derivation, fixed-point proof, and explicit Lipschitz constant. We will also add a lemma showing that semantic drift remains bounded so the contraction applies to the original intent rather than a drifted meaning. revision: yes
-
Referee: [Abstract] Abstract, hierarchical rewrite description: the reverse simulated annealing schedule with dynamic γ is asserted to preserve semantic alignment while increasing obfuscation, but no per-step semantic-distance bound or intent-preservation threshold is stated. This assumption is required for the contraction mapping to remain valid on the intended meaning; its absence makes the theoretical implication non-demonstrable from the given material.
Authors: We acknowledge the absence of explicit per-step semantic-distance bounds and intent-preservation thresholds. The revised manuscript will derive and state these bounds from the contractive recurrence, including a per-step threshold that guarantees semantic alignment is maintained while γ decreases under the reverse simulated annealing schedule. These additions will be placed in both the abstract description and the theoretical section. revision: yes
Circularity Check
Contractive recurrence claim reduces to properties of the dynamic γ schedule by construction
specific steps
-
self definitional
[Abstract]
"Theoretically, we prove that prompt rewriting follows a contractive recurrence, leading to semantic collapse as γ decreases."
The recurrence is defined using the dynamic semantic dispersion coefficient γ that is introduced as part of the Hierarchical Rewrite Strategy and reverse simulated annealing schedule. Therefore the claimed semantic collapse as γ decreases is a direct consequence of the recurrence's construction rather than an independent derivation from first principles.
full rationale
The paper's central theoretical result states that prompt rewriting follows a contractive recurrence leading to semantic collapse as γ decreases. The recurrence is introduced together with the Hierarchical Rewrite Strategy that defines γ's dynamic schedule (conservative early, aggressive later). No independent per-step semantic-distance bound or external verification is supplied; the collapse follows directly from decreasing γ inside the recurrence that was defined using that same schedule. This matches the self-definitional pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- semantic dispersion coefficient γ
axioms (1)
- ad hoc to paper prompt rewriting follows a contractive recurrence leading to semantic collapse as γ decreases
invented entities (2)
-
A*-inspired Factual Error Induction Framework
no independent evidence
-
Agentic Mechanism Labeling
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, and Kai-Wei Chang. 2018. Generating natural language adversarial examples. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2890–2896
2018
-
[2]
Alfonso Amayuelas, Xianjun Yang, Antonis Antoniades, Wenyue Hua, Liang- ming Pan, and William Wang. 2024. MultiAgent Collaboration Attack: Investi- gating Adversarial Attacks in Large Language Model Collaborations via Debate. arXiv:2406.14711 [cs.CL] https://arxiv.org/abs/2406.14711
arXiv 2024
-
[3]
Anthropic. 2025. Claude 3.7 Sonnet System Card. https://www.anthropic.com/ claude-3-7-sonnet-system-card
2025
-
[4]
Anthropic Interpretability Team. 2025. Circuit Tracing: Revealing Compu- tational Graphs in LLMs. https://transformer-circuits.pub/2025/attribution- graphs/methods.html
2025
-
[6]
Yuhui Du and Others. 2023. Improving Factuality and Reasoning in Language Models via Multi-Agent Debate. InarXiv preprint arXiv:2305.14325. https://arxiv. org/abs/2305.14325
Pith/arXiv arXiv 2023
-
[7]
Google. 2025. Safety settings — Gemini API. https://ai.google.dev/gemini- api/docs/safety-settings
2025
-
[8]
Peter E Hart, Nils J Nilsson, and Bertram Raphael. 1968. A formal basis for the heuristic determination of minimum cost paths.IEEE Transactions on Systems Science and Cybernetics4, 2 (1968), 100–107
1968
-
[9]
Jinwei Hu, Yi Dong, Youcheng Sun, and Xiaowei Huang. 2026. Tapas Are Free! Training-Free Adaptation of Programmatic Agents via LLM-Guided Program Synthesis in Dynamic Environments.Proceedings of the AAAI Conference on Artificial Intelligence40, 35 (Mar. 2026), 29477–29485. https://doi.org/10.1609/ aaai.v40i35.40189
2026
-
[10]
Lifu Huang, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2019. Cosmos QA: Machine Reading Comprehension with Contextual Commonsense Reasoning. arXiv:1909.00277 [cs.CL] https://arxiv.org/abs/1909.00277
arXiv 2019
-
[11]
Ziwei Ji, Nayeon Lee, Jason Fries, et al. 2023. Survey of Hallucination in Natural Language Generation.Comput. Surveys(2023)
2023
-
[12]
Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. Is BERT really robust? A strong baseline for natural language attack on text classification and entailment. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 8018–8029
2020
-
[13]
Ningke Li, Yuekang Li, Yi Liu, Ling Shi, Kailong Wang, and Haoyu Wang. 2024. Drowzee: Metamorphic Testing for Fact-Conflicting Hallucination Detection in Large Language Models.Proc. ACM Program. Lang.8, OOPSLA2, Article 336 (Oct. 2024), 30 pages. https://doi.org/10.1145/3689776
-
[14]
Yunxuan Li, Yibing Du, Jiageng Zhang, Le Hou, Peter Grabowski, Yeqing Li, and Eugene Ie. 2024. Improving Multi-Agent Debate with Sparse Communication Topology.Findings of EMNLP 2024(2024), 7281–7294. https://aclanthology.org/ 2024.findings-emnlp.427/
2024
-
[15]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2023. Encouraging Divergent Think- ing in Large Language Models through Multi-Agent Debate.arXiv preprint arXiv:2305.19118(2023)
Pith/arXiv arXiv 2023
-
[16]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). 17889–17904. https://aclanthology.org/2024.emnlp-main.992/
2024
-
[17]
Xiaoyang Lin, Da Zheng, Min Sun, Tiezheng Liu, Maosong Sun, and Ming Zhou
-
[18]
https://arxiv.org/abs/2303.10420
A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series.arXiv preprint arXiv:2303.10420(2023). https://arxiv.org/abs/2303.10420
arXiv 2023
-
[19]
Yu Liu, Xia Li, Zihan Wang, et al. 2023. AutoDAN: Automatic and Interpretable Adversarial Attacks on Large Language Models.arXiv preprint arXiv:2310.06117 (2023)
arXiv 2023
-
[20]
Microsoft. 2025. Safety system messages — Azure OpenAI. https://learn. microsoft.com/en-us/azure/ai-foundry/openai/concepts/system-message
2025
-
[21]
Niels Mündler, Jingxuan He, Slobodan Jenko, and Martin Vechev. 2024. Self- Contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation. InICLR 2024 Workshop on Trustworthy and Responsible Large Lan- guage Models. https://arxiv.org/abs/2305.15852 arXiv preprint arXiv:2305.15852
arXiv 2024
-
[22]
OpenAI. 2023. GPT-4 Technical Report. https://cdn.openai.com/papers/gpt-4.pdf
2023
-
[23]
OpenAI. 2023. OpenAI Red Teaming Network.OpenAI Blog(2023). https: //openai.com/research/red-teaming-network
2023
-
[24]
OpenAI. 2024. GPT-4o System Card. https://openai.com/index/gpt-4o-system- card/
2024
-
[25]
Ethan Perez, Douwe Kiela, et al. 2022. Red Teaming Language Models with Lan- guage Models. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[26]
Chen Qian, Zihao Xie, YiFei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yu- fan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. 2025. Scaling Large Language Model-based Multi-Agent Collaboration. InThe Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=K3n5jPkrU6
2025
-
[27]
QwenLM. 2024. Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115 (2024). https://arXiv.org/abs/2412.15115 preprint
Pith/arXiv arXiv 2024
-
[28]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). 3982–3992
2019
-
[29]
2010.Artificial Intelligence: A Modern Approach (3 ed.)
Stuart Russell and Peter Norvig. 2010.Artificial Intelligence: A Modern Approach (3 ed.). Prentice Hall
2010
-
[30]
Yusuke Sakai, Hidetaka Kamigaito, and Taro Watanabe. 2024. mCSQA: Multi- lingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans. InarXiv preprint arXiv:2406.04215. https: //arxiv.org/abs/2406.04215
arXiv 2024
-
[31]
Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Ham- bro, Aram H. Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, Tim Rocktäschel, and Roberta Raileanu. 2024. Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts. arXiv:2402.16822 [cs.CL] https://arxiv.org/abs/2402.16822
arXiv 2024
-
[32]
Peiyang Song, Pengrui Han, and Noah Goodman. 2025. A Survey on Large Language Model Reasoning Failures.OpenReview Preprint(2025). https:// openreview.net/pdf/9b1976ee8aa58710013731687ea50493f5adc30d.pdf
2025
-
[33]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. Com- monsenseQA: A Question Answering Challenge Targeting Commonsense Knowl- edge. InNAACL-HLT. 4149–4158. https://doi.org/10.18653/v1/N19-1421
-
[34]
Alon Talmor, Ori Yoran, Ronan Le Bras, Chandra Bhagavatula, Yoav Goldberg, Yejin Choi, and Jonathan Berant. 2021. CommonsenseQA 2.0: Exposing the Limits of AI through Gamification. InNeurIPS 2021 Datasets and Benchmarks Track. https://openreview.net/forum?id=qF7FlUT5dxa
2021
-
[35]
Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, D. Bikel, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert...
Pith/arXiv arXiv 2023
-
[36]
Zeming Xiao, Rui Zhang, Jian Xu, Yi Zhou, Haotian Li, and Minlie Huang. 2024. Distract Large Language Models for Automatic Jailbreak. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). 16342–16358
2024
-
[37]
Xilie Xu, Keyi Kong, Ning Liu, Lizhen Cui, Di Wang, Jingfeng Zhang, and Mohan Kankanhalli. 2024. An LLM Can Fool Itself: A Prompt-Based Adversarial Attack. InInternational Conference on Learning Representations (ICLR)
2024
-
[38]
Yifan Xu, Zihan Li, Shuo Wang, Yue Zhang, and Dawei Song. 2025. Misattribu- tionLLM: Integrating Error Attribution into Large Language Model Evaluation. InProceedings of the 2025 International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=Q5eo3VMxF6 OpenReview preprint
2025
-
[39]
Jia-Yu Yao, Kun-Peng Ning, Zhen-Hui Liu, Mu-Nan Ning, Yu-Yang Liu, and Li Yuan. 2023. LLM Lies: Hallucinations are not Bugs, but Features as Adversarial Examples.arXiv preprint arXiv:2310.01469(2023)
arXiv 2023
-
[40]
Kun Yue, Wei Li, Han Zhang, Yiming Ma, and Yizhou Sun. 2023. Automatic Evaluation of Attribution by Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023. 4142–4157. https://aclanthology.org/ 2023.findings-emnlp.307
2023
-
[41]
Jiawei Zhang, Chejian Xu, Yu Gai, Freddy Lécué, Dawn Song, and Bo Li. 2024. KnowHalu: Hallucination Detection via Multi-Form Knowledge Based Factual Checking. InICLR 2025 Workshop on Foundation Models in the Wild (FM-Wild). https://arxiv.org/abs/2404.02935 arXiv preprint arXiv:2404.02935
arXiv 2024
-
[42]
Hao Zhou, Xinyi Wang, Ming Li, and Yue Zhang. 2024. Explaining Pre-Trained Language Models with Attribution Scores: An Analysis in Low-Resource Set- tings. InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evaluation (LREC-COLING). 6902–6911. https://aclanthology.org/2024.lrec-main.600
2024
-
[43]
Kaijie Zhu and et al. 2023. PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts.arXiv preprint arXiv:2306.04528 (2023)
arXiv 2023
-
[44]
Kaijie Zhu, Jindong Wang, Jiaheng Zhou, Zichen Wang, Hao Chen, Yidong Wang, Linyi Yang, Wei Ye, Yue Zhang, Neil Gong, and Xing Xie. 2024. PromptRo- bust: Towards Evaluating the Robustness of Large Language Models on Ad- versarial Prompts. InProceedings of the 1st ACM Workshop on Large AI Sys- tems and Models with Privacy and Safety Analysis(Salt Lake City...
-
[45]
Andy Zou, Min Cheng, Nathaniel Lambert, et al. 2023. Universal and Transferable Adversarial Attacks on Aligned Language Models.arXiv preprint arXiv:2307.15043 (2023). Appendix Overview This section provides an overview of the supplementary appendices and their respective purposes. • Appendix I:Presents the theoretical justification and intuition for adopt...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.