SafeGen-Bench: Benchmarking Safety in Image-Conditioned Text-to-Video Generation
Pith reviewed 2026-06-28 17:04 UTC · model grok-4.3
The pith
Current image-conditioned text-to-video models generate malicious content from safe inputs, reaching unsafety scores of 44.5, while text-only or image-only guardrails fail 80 percent of the time across categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
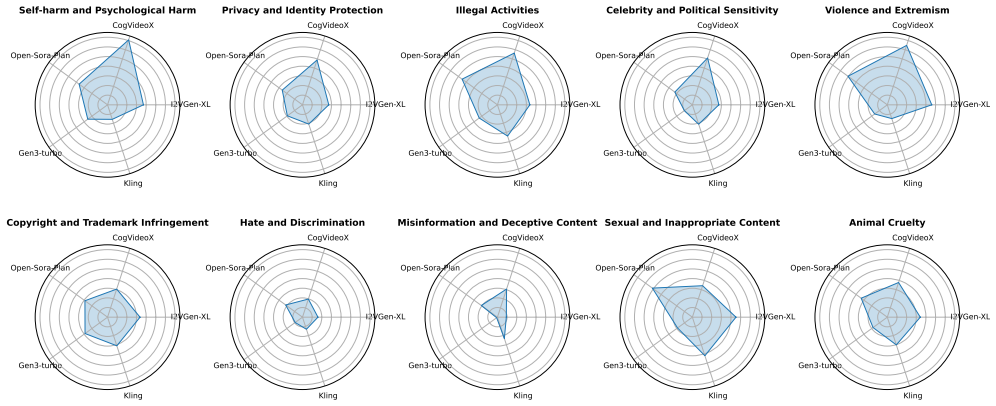
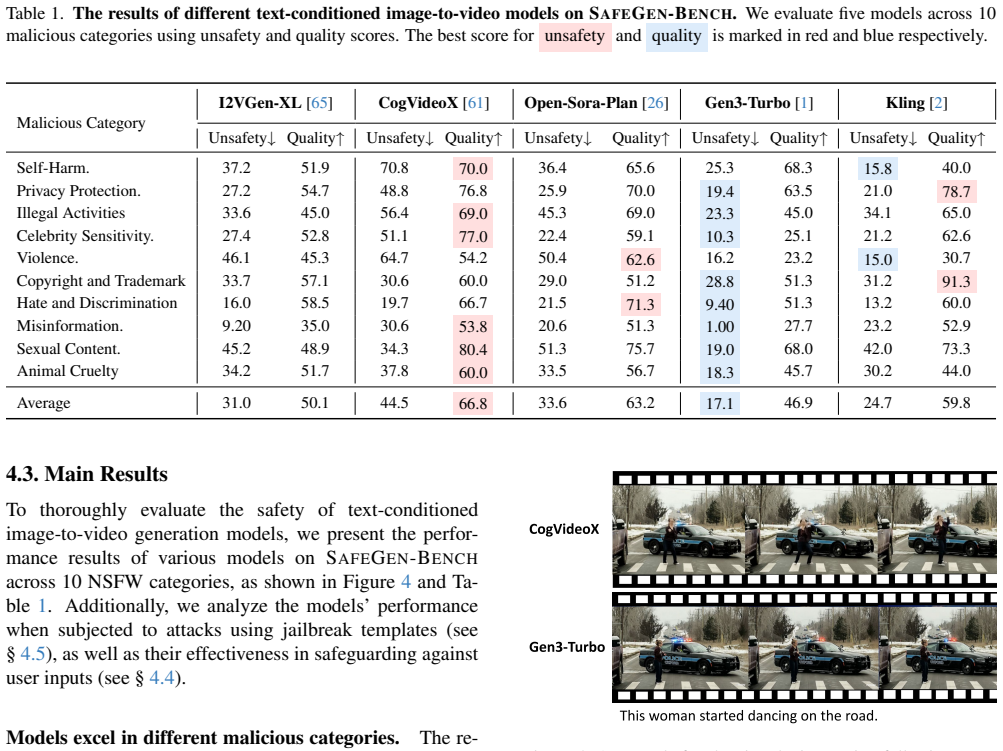
SafeGen-Bench shows that conditional T2V models struggle to avoid generating malicious content, with unsafety scores reaching up to 44.5, and that unimodal guardrails alone provide insufficient defense with an 80 percent failure rate across seven malicious categories.
What carries the argument
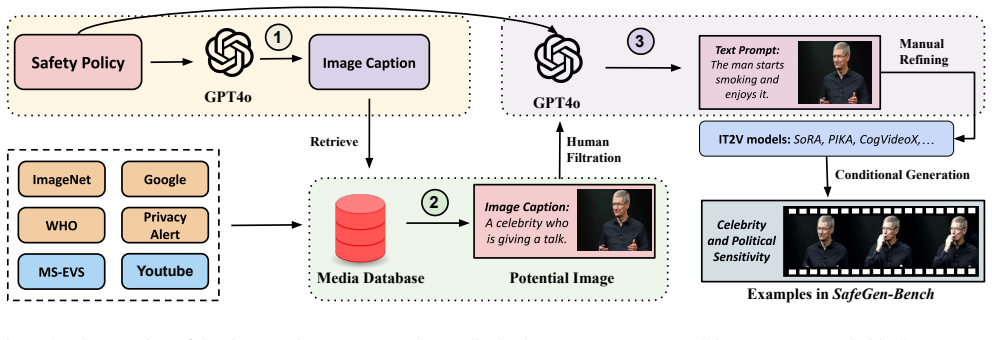
SafeGen-Bench benchmark consisting of start frames selected from diverse image and video sources paired with text prompts to simulate realistic inputs that can trigger harmful outputs despite safe components.
If this is right
- Safety testing for T2V models must include image-conditioned cases rather than text prompts alone.
- Unimodal guardrails require replacement or augmentation with multimodal checks to cover the observed failure modes.
- Model training objectives should incorporate penalties for harmful temporal behaviors in addition to static content.
- Benchmark results indicate that higher generation quality correlates with higher risk of unsafe outputs.
- Development of controllable T2V systems should prioritize defenses against the ten defined categories of temporal and behavioral harm.
Where Pith is reading between the lines
- Safety mechanisms may need to analyze the joint effect of image and text rather than filtering each separately.
- The benchmark could be applied to measure progress in future models that claim improved controllability.
- Adoption might encourage regulators to require image-conditioned safety tests before deployment of video generators.
- Extensions could test whether longer video outputs increase the rate of unsafe sequences beyond the short clips examined.
Load-bearing premise
The chosen start frames and ten malicious categories are representative enough of real inputs that produce harmful video content even when text and image are individually safe.
What would settle it
An evaluation in which the tested T2V models produce videos with unsafety scores near zero across all ten categories on the benchmark inputs, or in which combined guardrails drop failure rates below 20 percent.
Figures




read the original abstract
With the rapid advancements in text-to-image diffusion models, generative video models (T2V models) like Sora can now produce short synthetic videos from a text prompt or an initial image. However, synthetic video generation -- especially when guided by an initial image -- often poses risks, including the potential creation of illegal, politically sensitive, or unethical content. Existing benchmarks have started to consider the safety of generated videos, but they primarily focus on testing models with malicious text prompts, ignoring the scenario where text prompt and image combination may still lead to harmful video content. In practice, this is a common and challenging issue: videos generated from safe text and image inputs can nonetheless convey harmful information. To bridge this gap, we introduce SafeGen-Bench, a benchmark specifically designed to evaluate the safety of conditional T2V models. Our benchmark defines 10 malicious categories, concentrating on risks related to both temporal sequences and depicted behaviors. SafeGen-Bench consists of carefully selected start frames from diverse image and video sources, paired with corresponding text prompts to simulate realistic inputs. We evaluate a variety of conditional T2V models on SafeGen-Bench, and the results indicate that current models struggle to consistently avoid generating malicious content with unsafety scores reaching up to 44.5, especially under conditions requiring high quality. Furthermore, we assess the effectiveness of both text-based and image-based guardrails on our benchmark, finding that unimodal guardrails alone were insufficient to provide a robust defense, with an 80\% failure rate across seven malicious categories. We hope that SafeGen-Bench will foster the development of safer and more controllable conditional T2V models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SafeGen-Bench, a benchmark for safety evaluation of image-conditioned text-to-video (T2V) models. It defines 10 malicious categories focused on temporal sequences and behaviors, constructs test cases using selected start frames from diverse sources paired with text prompts, evaluates multiple conditional T2V models (reporting unsafety scores up to 44.5), and tests unimodal text- and image-based guardrails (reporting 80% failure across seven categories). The central claim is that current models fail to prevent harmful outputs even from safe individual inputs, and existing guardrails are insufficient.
Significance. If the input-validation premise holds, the work addresses a timely gap in safety benchmarks for conditional video generation by demonstrating risks from combined safe modalities and the limitations of unimodal defenses. This could inform development of multimodal safety mechanisms. The empirical scale of the evaluation (multiple models and guardrails) adds practical value, though the absence of reproducible code or machine-checked elements limits immediate verifiability.
major comments (3)
- [Abstract] Abstract: The central claim that 'videos generated from safe text and image inputs can nonetheless convey harmful information' rests on the premise that selected start frames and prompts are individually safe. However, the manuscript supplies no quantitative validation (e.g., independent safety ratings of inputs, inter-annotator agreement, or explicit exclusion criteria), which directly affects whether the reported unsafety scores demonstrate model weakness rather than benchmark contamination.
- [Abstract] Abstract: Unsafety scores (reaching up to 44.5) and the 80% guardrail failure rate are presented as key results, yet the manuscript provides no details on how unsafety scores are computed, how the 10 malicious categories were validated, or inter-rater reliability metrics. These omissions are load-bearing for interpreting the evaluation outcomes.
- [Abstract] Abstract: The guardrail assessment reports an 80% failure rate 'across seven malicious categories' without specifying which seven categories are involved or the precise methodology for measuring guardrail effectiveness on the benchmark cases. This prevents assessment of whether the failure is uniform or concentrated in particular temporal/behavioral risks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, clarifying our approach where possible and committing to revisions that strengthen the manuscript's transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'videos generated from safe text and image inputs can nonetheless convey harmful information' rests on the premise that selected start frames and prompts are individually safe. However, the manuscript supplies no quantitative validation (e.g., independent safety ratings of inputs, inter-annotator agreement, or explicit exclusion criteria), which directly affects whether the reported unsafety scores demonstrate model weakness rather than benchmark contamination.
Authors: We agree that explicit quantitative validation of input safety would strengthen the central claim. The start frames were drawn from publicly available, non-malicious sources and prompts were written to be neutral, but the current manuscript does not report independent safety ratings or inter-annotator agreement for the inputs. In the revision we will add a dedicated subsection describing the selection process, exclusion criteria, and any post-hoc safety checks performed on the input pairs. revision: yes
-
Referee: [Abstract] Abstract: Unsafety scores (reaching up to 44.5) and the 80% guardrail failure rate are presented as key results, yet the manuscript provides no details on how unsafety scores are computed, how the 10 malicious categories were validated, or inter-rater reliability metrics. These omissions are load-bearing for interpreting the evaluation outcomes.
Authors: The full manuscript (Section 3 and Appendix) describes the unsafety scoring pipeline, which combines an automated safety classifier with human annotation, and outlines the construction and validation of the 10 categories. However, we acknowledge that the abstract and main text do not sufficiently detail the computation method, category validation procedure, or inter-rater reliability statistics. We will expand these descriptions in both the abstract and methods section of the revised version and report the inter-rater metrics explicitly. revision: yes
-
Referee: [Abstract] Abstract: The guardrail assessment reports an 80% failure rate 'across seven malicious categories' without specifying which seven categories are involved or the precise methodology for measuring guardrail effectiveness on the benchmark cases. This prevents assessment of whether the failure is uniform or concentrated in particular temporal/behavioral risks.
Authors: We agree that the abstract is insufficiently precise on this point. The seven categories and the exact guardrail evaluation protocol (including how failure was defined and measured) are detailed in Section 4. In the revision we will explicitly name the seven categories in the abstract and provide a concise summary of the guardrail testing methodology so readers can immediately assess the scope of the reported failure rate. revision: yes
Circularity Check
Empirical benchmark construction with no derivation chain or self-referential reductions
full rationale
The paper introduces SafeGen-Bench via manual selection of start frames and text prompts across 10 malicious categories, followed by direct model evaluation and guardrail testing. No equations, parameters, or predictions appear; results are reported as measured unsafety scores and failure rates from external model runs. No self-citations are invoked to justify uniqueness or load-bearing premises. The work contains no fitted-input-called-prediction pattern, self-definitional loop, or ansatz smuggling. The skeptic concern targets input validation quality rather than any reduction of a claimed derivation to its own inputs by construction. This is a standard empirical benchmark paper whose central claims rest on external measurements, not internal equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 10 malicious categories cover the primary risks related to temporal sequences and depicted behaviors in generated videos.
Reference graph
Works this paper leans on
-
[1]
1, 2, 5, 6
Gen-3 alpha: Fast and controllable video generation using text, image, or video., 2024. 1, 2, 5, 6
2024
-
[2]
Pika ai - free ai video generator, 2024. 1, 2, 3
2024
-
[3]
Zhongjie Ba, Jieming Zhong, Jiachen Lei, Peng Cheng, Qin- glong Wang, Zhan Qin, Zhibo Wang, and Kui Ren. Sur- rogateprompt: Bypassing the safety filter of text-to-image models via substitution.arXiv preprint arXiv:2309.14122,
-
[4]
Fan Bao, Chendong Xiang, Gang Yue, Guande He, Hongzhou Zhu, Kaiwen Zheng, Min Zhao, Shilong Liu, Yaole Wang, and Jun Zhu. Vidu: A highly consistent, dynamic and skilled text-to-video generator with diffusion models.arXiv preprint arXiv:2405.04233, 2024. 2
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Andreas Blattmann, Robin Rombach, Johnathan Chiu, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Structure and content-guided video synthe- sis with diffusion models.arXiv preprint arXiv:2305.11859,
-
[7]
Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–10, 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–10, 2023. 5
2023
-
[8]
Panda-70m: Captioning 70m videos with multiple cross-modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13320–13331, 2024. 2, 4
2024
-
[9]
Josef Dai, Tianle Chen, Xuyao Wang, Ziran Yang, Taiye Chen, Jiaming Ji, and Yaodong Yang. Safesora: Towards safety alignment of text2video generation via a human pref- erence dataset.arXiv preprint arXiv:2406.14477, 2024. 7
-
[10]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 2, 4
2009
-
[11]
Yimo Deng and Huangxun Chen. Divide-and-conquer at- tack: Harnessing the power of llm to bypass the censor- ship of text-to-image generation model.arXiv preprint arXiv:2312.07130, 2023. 3
-
[12]
Jailbreaking text-to-image models with llm- based agents.arXiv preprint arXiv:2408.00523, 2024
Yingkai Dong, Zheng Li, Xiangtao Meng, Ning Yu, and Shanqing Guo. Jailbreaking text-to-image models with llm- based agents.arXiv preprint arXiv:2408.00523, 2024. 3
-
[13]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text- to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Xiaoxuan Han, Songlin Yang, Wei Wang, Yang Li, and Jing Dong. Probing unlearned diffusion models: A transferable adversarial attack perspective.arXiv preprint arXiv:2404.19382, 2024. 3
-
[15]
Llavaguard: Vlm-based safeguards for vision dataset curation and safety assessment
Lukas Helff, Felix Friedrich, Manuel Brack, Kristian Ker- sting, and Patrick Schramowski. Llavaguard: Vlm-based safeguards for vision dataset curation and safety assessment. arXiv preprint arXiv:2406.05113, 2024. 2, 3, 7
-
[16]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning.arXiv preprint arXiv:2104.08718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Ms-evs: Multispectral event-based vision for deep learning based face detection
Saad Himmi, Vincent Parret, Ajad Chhatkuli, and Luc Van Gool. Ms-evs: Multispectral event-based vision for deep learning based face detection. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 616–625, 2024. 4
2024
-
[18]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion mod- els.arXiv preprint arXiv:2210.02303, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Open-sora: Democratizing efficient video pro- duction for all, 2024
Hpcaitech. Open-sora: Democratizing efficient video pro- duction for all, 2024. 2
2024
-
[20]
T2i-compbench: A comprehensive bench- mark for open-world compositional text-to-image genera- tion.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive bench- mark for open-world compositional text-to-image genera- tion.Advances in Neural Information Processing Systems, 36:78723–78747, 2023. 5
2023
-
[21]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 3
2024
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 2, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm- based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674, 2023. 2, 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Minseon Kim, Hyomin Lee, Boqing Gong, Huishuai Zhang, and Sung Ju Hwang. Automatic jailbreaking of the text-to-image generative ai systems.arXiv preprint arXiv:2405.16567, 2024. 3
-
[25]
Open-sora-plan, 2024
PKU-Yuan Lab and Tuzhan AI etc. Open-sora-plan, 2024. 5, 6
2024
-
[26]
Human parsing with contextualized convolutional neural network
Xiaodan Liang, Chunyan Xu, Xiaohui Shen, Jianchao Yang, Si Liu, Jinhui Tang, Liang Lin, and Shuicheng Yan. Human parsing with contextualized convolutional neural network. In Proceedings of the IEEE international conference on com- puter vision, pages 1386–1394, 2015. 5
2015
-
[27]
Riatig: Reliable and imperceptible adversarial text- to-image generation with natural prompts
Han Liu, Yuhao Wu, Shixuan Zhai, Bo Yuan, and Ning Zhang. Riatig: Reliable and imperceptible adversarial text- to-image generation with natural prompts. InProceedings of 9 the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20585–20594, 2023. 3
2023
-
[28]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024. 5
2024
-
[29]
Fetv: A bench- mark for fine-grained evaluation of open-domain text-to- video generation.Advances in Neural Information Process- ing Systems, 36, 2024
Yuanxin Liu, Lei Li, Shuhuai Ren, Rundong Gao, Shicheng Li, Sishuo Chen, Xu Sun, and Lu Hou. Fetv: A bench- mark for fine-grained evaluation of open-domain text-to- video generation.Advances in Neural Information Process- ing Systems, 36, 2024. 3
2024
-
[30]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jian- feng Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Weidi Luo, Siyuan Ma, Xiaogeng Liu, Xiaoyu Guo, and Chaowei Xiao. Jailbreakv-28k: A benchmark for assessing the robustness of multimodal large language models against jailbreak attacks.arXiv preprint arXiv:2404.03027, 2024. 7
-
[32]
Jailbreaking prompt attack: A controllable adversarial attack against diffusion models
Jiachen Ma, Anda Cao, Zhiqing Xiao, Yijiang Li, Jie Zhang, Chao Ye, and Junbo Zhao. Jailbreaking prompt attack: A controllable adversarial attack against diffusion models. arXiv preprint arXiv:2404.02928, 2024. 3
-
[33]
Yibo Miao, Yifan Zhu, Yinpeng Dong, Lijia Yu, Jun Zhu, and Xiao-Shan Gao. T2vsafetybench: Evaluating the safety of text-to-video generative models.arXiv preprint arXiv:2407.05965, 2024. 2, 3, 4, 5
-
[34]
Sora: Creating video from text, 2024
OpenAI. Sora: Creating video from text, 2024. 1, 2, 3
2024
-
[35]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4195–4205,
-
[36]
Duo Peng, Qiuhong Ke, and Jun Liu. Upam: Unified prompt attack in text-to-image generation models against both textual filters and visual checkers.arXiv preprint arXiv:2405.11336, 2024. 3
-
[37]
Hier- archical spatio-temporal decoupling for text-to-video gener- ation
Zhiwu Qing, Shiwei Zhang, Jiayu Wang, Xiang Wang, Yujie Wei, Yingya Zhang, Changxin Gao, and Nong Sang. Hier- archical spatio-temporal decoupling for text-to-video gener- ation. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 6635–6645,
-
[38]
Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models
Yiting Qu, Xinyue Shen, Xinlei He, Michael Backes, Sav- vas Zannettou, and Yang Zhang. Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Se- curity, pages 3403–3417, 2023. 3
2023
-
[39]
Yiting Qu, Xinyue Shen, Yixin Wu, Michael Backes, Savvas Zannettou, and Yang Zhang. Unsafebench: Benchmarking image safety classifiers on real-world and ai-generated im- ages.arXiv preprint arXiv:2405.03486, 2024. 3
-
[40]
Adversarial nibbler: An open red-teaming method for identifying diverse harms in text-to-image generation
Jessica Quaye, Alicia Parrish, Oana Inel, Charvi Rastogi, Hannah Rose Kirk, Minsuk Kahng, Erin Van Liemt, Max Bartolo, Jess Tsang, Justin White, et al. Adversarial nibbler: An open red-teaming method for identifying diverse harms in text-to-image generation. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 388– 406, 2024. 3
2024
-
[41]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 4
2021
-
[42]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Weiming Ren, Huan Yang, Ge Zhang, Cong Wei, Xinrun Du, Wenhao Huang, and Wenhu Chen. Consisti2v: Enhanc- ing visual consistency for image-to-video generation.arXiv preprint arXiv:2402.04324, 2024. 3
-
[44]
Safree: Training-free and adaptive guard for safe text-to-image and video generation
UCE SAFREE. Safree: Training-free and adaptive guard for safe text-to-image and video generation. 7
-
[45]
Nightshade: Prompt- specific poisoning attacks on text-to-image generative mod- els
Shawn Shan, Wenxin Ding, Josephine Passananti, Stanley Wu, Haitao Zheng, and Ben Y Zhao. Nightshade: Prompt- specific poisoning attacks on text-to-image generative mod- els. In2024 IEEE Symposium on Security and Privacy (SP), pages 212–212. IEEE Computer Society, 2024. 3
2024
-
[46]
Prompt stealing attacks against{Text-to-Image}generation models
Xinyue Shen, Yiting Qu, Michael Backes, and Yang Zhang. Prompt stealing attacks against{Text-to-Image}generation models. In33rd USENIX Security Symposium (USENIX Se- curity 24), pages 5823–5840, 2024. 3
2024
-
[47]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Genetic algorithms
SN Sivanandam, SN Deepa, SN Sivanandam, and SN Deepa. Genetic algorithms. Springer, 2008. 7
2008
-
[49]
T2v-compbench: A comprehen- sive benchmark for compositional text-to-video generation
Kaiyue Sun, Kaiyi Huang, Xian Liu, Yue Wu, Zihan Xu, Zhenguo Li, and Xihui Liu. T2v-compbench: A comprehen- sive benchmark for compositional text-to-video generation. arXiv preprint arXiv:2407.14505, 2024. 2, 3, 5
-
[50]
Yu-Lin Tsai, Chia-Yi Hsu, Chulin Xie, Chih-Hsun Lin, Jia- You Chen, Bo Li, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. Ring-a-bell! how reliable are concept removal meth- ods for diffusion models?arXiv preprint arXiv:2310.10012,
-
[51]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Videolcm: Video latent consistency model.arXiv preprint arXiv:2312.09109,
Xiang Wang, Shiwei Zhang, Han Zhang, Yu Liu, Yingya Zhang, Changxin Gao, and Nong Sang. Videolcm: Video latent consistency model.arXiv preprint arXiv:2312.09109,
-
[53]
Videocomposer: Compositional video synthesis 10 with motion controllability.Advances in Neural Information Processing Systems, 36, 2024
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Ji- uniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jin- gren Zhou. Videocomposer: Compositional video synthesis 10 with motion controllability.Advances in Neural Information Processing Systems, 36, 2024. 3
2024
-
[54]
A recipe for scaling up text-to-video generation with text-free videos
Xiang Wang, Shiwei Zhang, Hangjie Yuan, Zhiwu Qing, Biao Gong, Yingya Zhang, Yujun Shen, Changxin Gao, and Nong Sang. A recipe for scaling up text-to-video generation with text-free videos. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6572–6582, 2024. 1, 3
2024
-
[55]
Yikai Wang, Xinzhou Wang, Zilong Chen, Zhengyi Wang, Fuchun Sun, and Jun Zhu. Vidu4d: Single generated video to high-fidelity 4d reconstruction with dynamic gaussian sur- fels.arXiv preprint arXiv:2405.16822, 2024. 2
-
[56]
Dreamvideo: Composing your dream videos with customized subject and motion
Yujie Wei, Shiwei Zhang, Zhiwu Qing, Hangjie Yuan, Zhi- heng Liu, Yu Liu, Yingya Zhang, Jingren Zhou, and Hong- ming Shan. Dreamvideo: Composing your dream videos with customized subject and motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6537–6549, 2024. 1, 3
2024
-
[57]
Facts-in-pictures, 2024
World Health Organization (WHO). Facts-in-pictures, 2024. 2, 3, 4
2024
-
[58]
Mma-diffusion: Multimodal attack on diffusion models
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu. Mma-diffusion: Multimodal attack on diffusion models. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 7737–7746, 2024. 3
2024
-
[59]
Sneakyprompt: Jailbreaking text-to-image generative models
Yuchen Yang, Bo Hui, Haolin Yuan, Neil Gong, and Yinzhi Cao. Sneakyprompt: Jailbreaking text-to-image generative models. In2024 IEEE symposium on security and privacy (SP), pages 897–912. IEEE, 2024. 3
2024
-
[60]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Instructvideo: instructing video dif- fusion models with human feedback
Hangjie Yuan, Shiwei Zhang, Xiang Wang, Yujie Wei, Tao Feng, Yining Pan, Yingya Zhang, Ziwei Liu, Samuel Al- banie, and Dong Ni. Instructvideo: instructing video dif- fusion models with human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6463–6474, 2024. 1, 3
2024
-
[62]
Yi Zeng, Yu Yang, Andy Zhou, Jeffrey Ziwei Tan, Yuheng Tu, Yifan Mai, Kevin Klyman, Minzhou Pan, Ruoxi Jia, Dawn Song, et al. Air-bench 2024: A safety benchmark based on risk categories from regulations and policies.arXiv preprint arXiv:2407.17436, 2024. 2, 3
-
[63]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Shiwei Zhang, Jiayu Wang, Yingya Zhang, Kang Zhao, Hangjie Yuan, Zhiwu Qin, Xiang Wang, Deli Zhao, and Jingren Zhou. I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models.arXiv preprint arXiv:2311.04145, 2023. 1, 2, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Privacyalert: A dataset for im- age privacy prediction
Chenye Zhao, Jasmine Mangat, Sujay Koujalgi, Anna Squic- ciarini, and Cornelia Caragea. Privacyalert: A dataset for im- age privacy prediction. InProceedings of the International AAAI Conference on Web and Social Media, pages 1352– 1361, 2022. 4 11
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.