TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
Pith reviewed 2026-06-28 14:53 UTC · model grok-4.3
The pith
TRON generates fresh visual reasoning tasks on demand via rule-verifiable programs, enabling scalable RL post-training that improves results on ten external benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
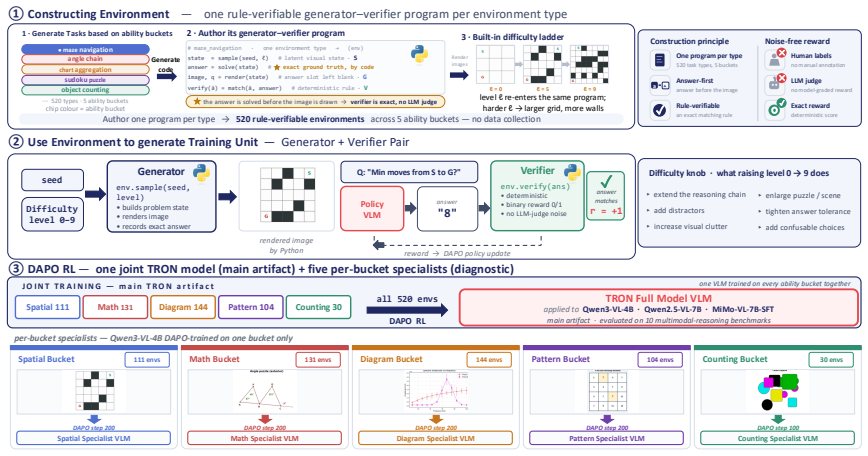
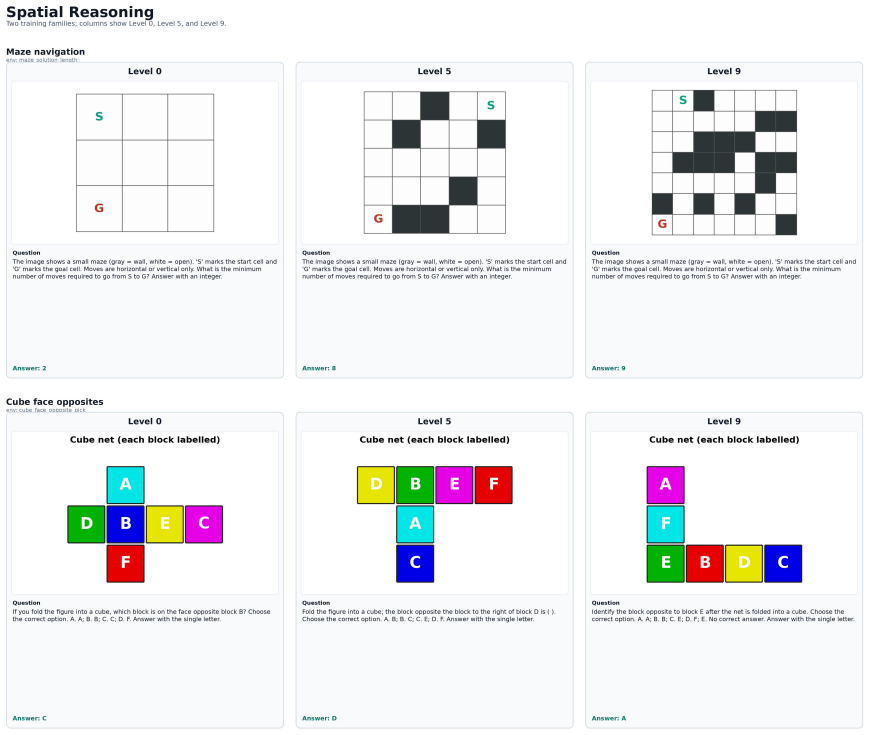
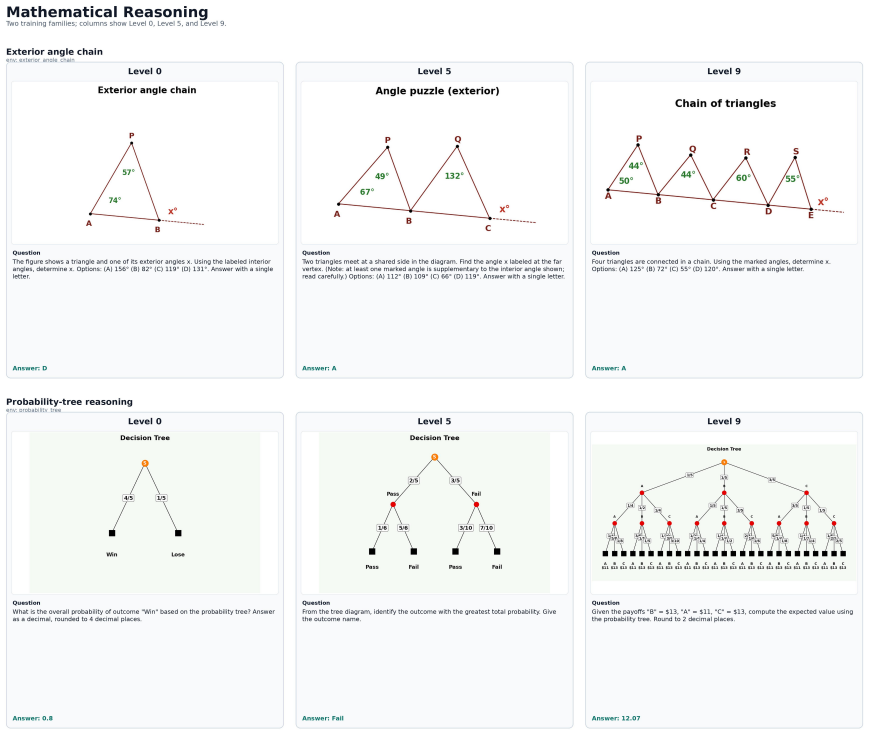
TRON supplies a substrate of controllable generator-verifier programs across 520 environments in five buckets that produce an unbounded stream of fresh visual reasoning instances with exact verification. This allows RL post-training to draw curriculum-matched samples without data collection limits and yields consistent gains on ten external multimodal benchmarks for three vision-language models.
What carries the argument
The generator-verifier program that samples a latent visual state, renders an image, asks a question, and exactly verifies the answer.
If this is right
- A single model can train across all five ability buckets using the same substrate.
- Per-bucket specialist models can be trained without collecting new data.
- Performance gains appear consistently across three different vision-language models on ten held-out benchmarks.
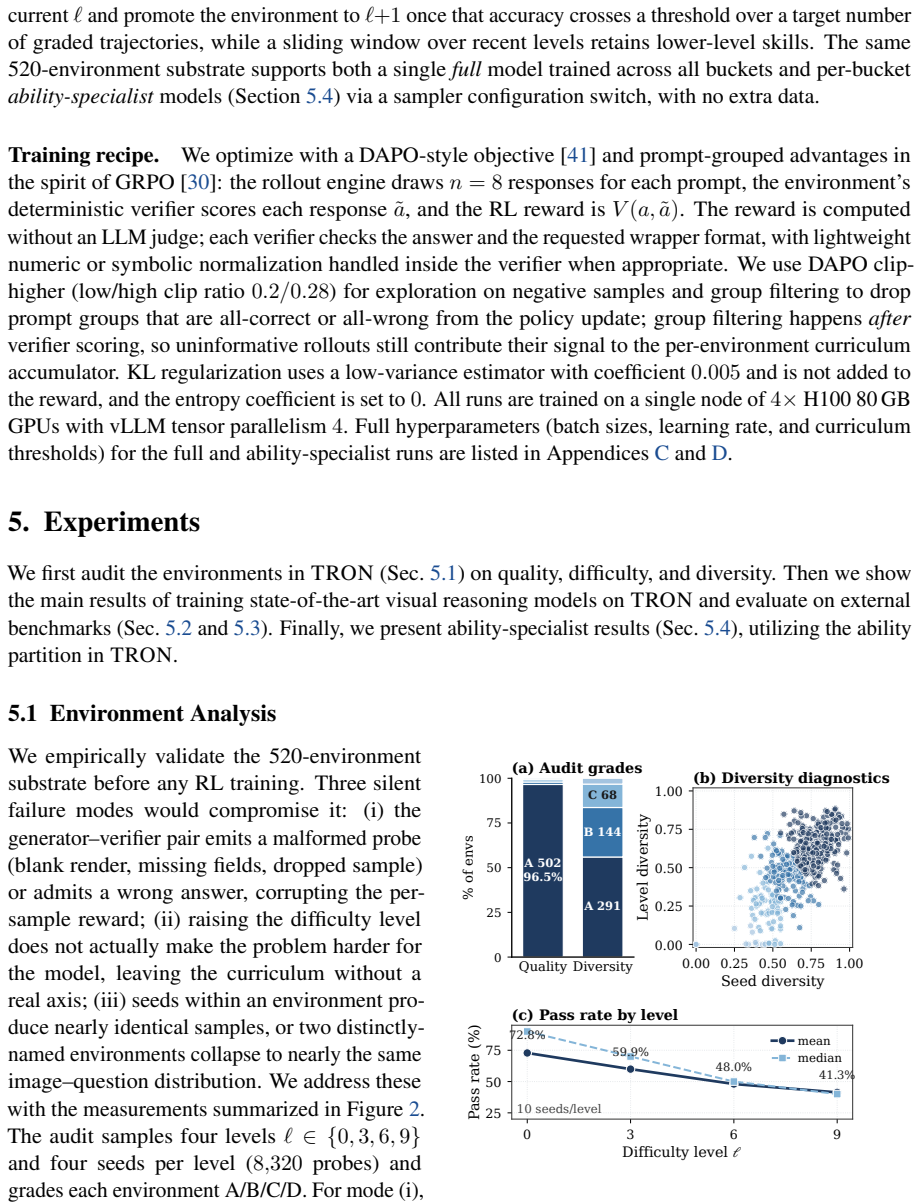
- The substrate permits analysis of generation reliability, instance diversity, and base-model pass rates by difficulty.
Where Pith is reading between the lines
- The online generation approach could extend to other RL domains that need verifiable signals, such as textual or code-based reasoning.
- Curriculum control over difficulty levels might allow training runs to adapt dynamically to a model's current weaknesses.
- Checks for near-duplicates across environments indicate the substrate could scale to larger numbers of environments while preserving diversity.
Load-bearing premise
The generated instances supply training signals whose distribution and verification rules do not introduce systematic biases that block generalization to external benchmarks.
What would settle it
If RL post-training with TRON produces no improvement or a drop in scores on the ten external multimodal benchmarks relative to static-dataset baselines, the central claim would be falsified.
Figures
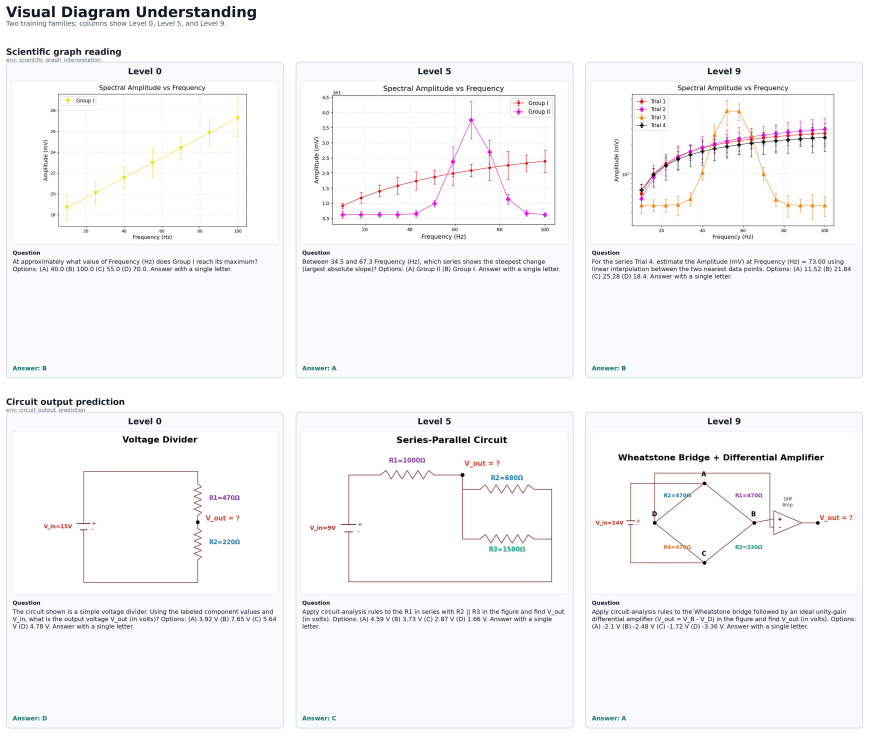
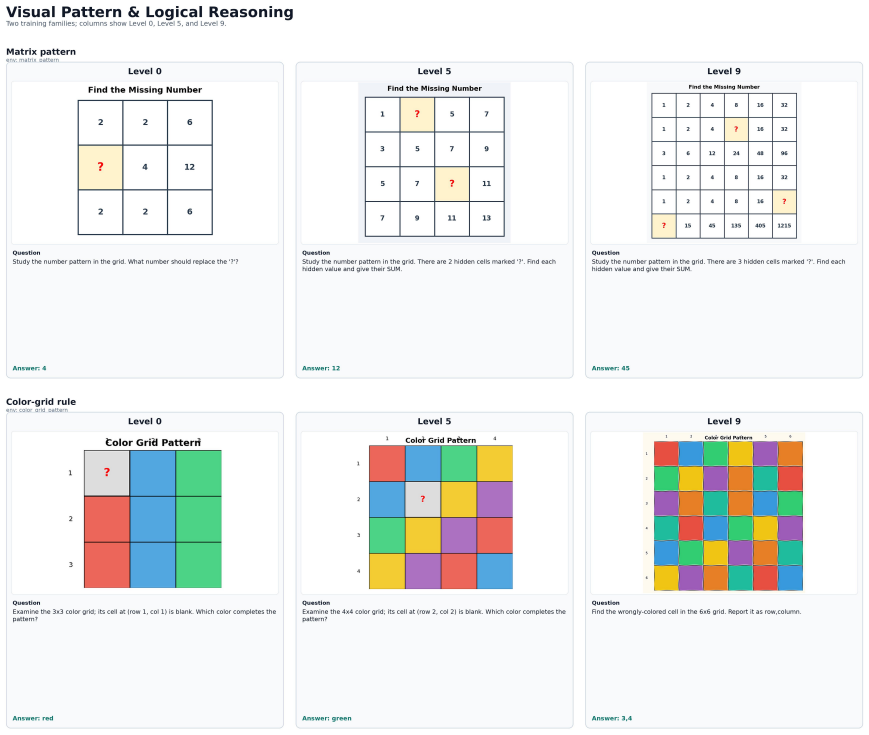


read the original abstract
Reinforcement learning (RL) for visual reasoning needs scalable, verifiable, and controllable training signals. Existing visual RL post-training trains on static curated datasets, with fixed image-question-answer samples bounded by their collection budget. In this work, we introduce TRON (Targeted, Rule-verifiable Online eNvironments), an online environment substrate: a training rollout is generated on demand by a controllable generator-verifier program that samples a fresh latent visual state, renders an image, asks a question, and exactly verifies the answer. A single run can therefore draw an unbounded stream of fresh instances at the difficulty level required by the current curriculum. The current TRON suite contains 520 environments organized into five ability buckets (spatial, mathematical, diagram, pattern/logic, and counting); the same substrate supports both a single full model trained on all buckets and per-bucket ability-specialist models, with no additional data collection. We also introduce a substrate analysis covering generation reliability, instance and level diversity, cross-environment near-duplicates, and base-model pass rate by difficulty level. RL post-training with METHOD consistently improves performance on ten external multimodal reasoning benchmarks across Qwen3-VL-4B, Qwen2.5-VL-7B, and MiMo-VL-7B-SFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRON, a suite of 520 controllable generator-verifier programs organized into five ability buckets (spatial, mathematical, diagram, pattern/logic, counting) that produce on-demand visual reasoning instances for RL post-training. It claims that RL using these environments yields consistent performance gains on ten external multimodal reasoning benchmarks across three VL models (Qwen3-VL-4B, Qwen2.5-VL-7B, MiMo-VL-7B-SFT). The manuscript also presents a substrate analysis of generation reliability, instance diversity, near-duplicates, and base-model pass rates by difficulty.
Significance. If the reported benchmark gains prove robust and transferable, TRON would provide a scalable alternative to static curated datasets by enabling unbounded, difficulty-controllable, rule-verifiable training signals. The substrate analysis of internal properties (reliability, diversity, pass rates) is a positive step toward reproducibility and curriculum design.
major comments (2)
- [Abstract] Abstract and experimental results: the headline claim of consistent improvements on ten external benchmarks is presented without any reported baselines, ablation studies, statistical tests, variance across runs, or effect sizes, preventing assessment of whether the gains are attributable to TRON or to other training choices.
- [Substrate analysis] Substrate analysis section: while internal properties (generation reliability, instance diversity, near-duplicates, base-model pass rates) are examined, no direct distributional comparison (feature-space distances, reasoning-type histograms, image statistics, or question-phrasing overlap) is reported between TRON rollouts and the ten held-out benchmark distributions; this leaves the generalization assumption untested and load-bearing for the transfer claim.
minor comments (1)
- [Abstract] Abstract contains the placeholder 'METHOD' in place of TRON when describing the RL post-training procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, clarifying our experimental reporting and analysis approach while committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: the headline claim of consistent improvements on ten external benchmarks is presented without any reported baselines, ablation studies, statistical tests, variance across runs, or effect sizes, preventing assessment of whether the gains are attributable to TRON or to other training choices.
Authors: We agree that the abstract and experimental results would benefit from more explicit reporting to allow readers to assess the source of the gains. In the revised manuscript we will add (i) comparisons against standard baselines including SFT-only and alternative RL post-training methods, (ii) ablation studies that isolate the contribution of individual ability buckets, and (iii) statistical details consisting of means, standard deviations across three random seeds, and Cohen’s d effect sizes for the reported benchmark improvements. These additions will be placed in both the abstract and the main results section. revision: yes
-
Referee: [Substrate analysis] Substrate analysis section: while internal properties (generation reliability, instance diversity, near-duplicates, base-model pass rates) are examined, no direct distributional comparison (feature-space distances, reasoning-type histograms, image statistics, or question-phrasing overlap) is reported between TRON rollouts and the ten held-out benchmark distributions; this leaves the generalization assumption untested and load-bearing for the transfer claim.
Authors: The substrate analysis is deliberately scoped to internal properties that support reproducibility and curriculum construction. We acknowledge that explicit distributional comparisons would provide additional evidence for the transfer assumption. In revision we will add reasoning-type histograms and basic image statistics (resolution, color distribution, object density) comparing TRON rollouts to the ten external benchmarks. Full feature-space distances and question-phrasing overlap metrics are computationally intensive and will be included only if space permits; otherwise they will be noted as future work. The primary evidence for transfer remains the consistent gains on the held-out benchmarks themselves. revision: partial
Circularity Check
No significant circularity; empirical gains on external benchmarks are not reduced to training inputs by construction.
full rationale
The paper's central claim is an empirical observation: RL post-training on the 520 TRON environments yields measured improvements on ten separately held-out external multimodal benchmarks. No equations, fitted parameters, or self-citations are invoked that would make the reported benchmark deltas equivalent to quantities defined inside the TRON generators or training loop. The substrate analysis addresses internal properties of the generated instances but does not redefine the external evaluation. This is a standard non-circular experimental setup; the generalization question is one of evidence strength rather than definitional reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning with verifiable rewards improves visual reasoning capabilities in multimodal models
invented entities (1)
-
TRON environments
no independent evidence
Forward citations
Cited by 1 Pith paper
-
VeriEvol: Scaling Multimodal Mathematical Reasoning via Verifiable Evol-Instruct
VeriEvol decouples prompt difficulty evolution from answer reliability verification to scale verified data for visual math reasoning, lifting benchmark accuracy from 35.42 to 54.73 and adding +3.88 in GRPO RL.
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[2]
Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, Junyang Lin, et al. Qwen2.5-VL technical report...
Pith/arXiv arXiv 2025
-
[3]
David G. T. Barrett, Felix Hill, Adam Santoro, Ari S. Morcos, and Timothy Lillicrap. Measuring abstract reasoning in neural networks. InProceedings of the 35th International Conference on Machine Learning (ICML), volume 80 ofProceedings of Machine Learning Research, pages 511–520, 2018
2018
-
[4]
Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles.Advances in Neural Information Processing Systems, 38:3613–3661, 2026
Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Jiaze Chen, Xuefeng Li, Qiying Yu, et al. Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles.Advances in Neural Information Processing Systems, 38:3613–3661, 2026
2026
-
[5]
R1-V: Reinforcing super generalization ability in vision-language models with less than $3
Liang Chen, Lei Li, Haozhe Zhao, Yifan Song, and Vinci. R1-V: Reinforcing super generalization ability in vision-language models with less than $3. https://github.com/Deep-Agent/R1-V, 2025
2025
-
[6]
Yew Ken Chia, Vernon Toh Yan Han, Deepanway Ghosal, Lidong Bing, and Soujanya Poria. PuzzleVQA: Diagnosing multimodal reasoning challenges of language models with abstract visual patterns.arXiv preprint arXiv:2403.13315, 2024
arXiv 2024
-
[7]
On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
Pith/arXiv arXiv 1911
-
[8]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Christopher Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. InProceedings of the 37th International Conference on Machine Learning (ICML), volume 119, pages 2048–2056. PMLR, 2020
2048
-
[9]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM international conference on multimedia, pages 11198–11201, 2024
2024
-
[10]
Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, and Lingpeng Kong. G-LLaV A: Solving geometric problem with multi-modal large language model.arXiv preprint arXiv:2312.11370, 2023
arXiv 2023
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[12]
Yucheng Han, Chi Zhang, Xin Chen, Xu Yang, Zhibin Wang, Gang Yu, Bin Fu, and Hanwang Zhang. ChartLlama: A multimodal LLM for chart understanding and generation.arXiv preprint arXiv:2311.16483, 2023
arXiv 2023
-
[13]
Measuring coding challenge competence with APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with APPS. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021. 11
2021
-
[14]
Vision-R1: Incentivizing reasoning capability in multimodal large language models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-R1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749, 2025
Pith/arXiv arXiv 2025
-
[15]
Lawrence Zitnick, and Ross Girshick
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2901–2910, 2017
2017
-
[16]
Tülu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brah- man, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tülu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
Pith/arXiv arXiv 2024
-
[17]
Sicong Leng, Jing Wang, Jiaxi Li, Hao Zhang, Zhiqiang Hu, Boqiang Zhang, Yuming Jiang, Hang Zhang, Xin Li, Lidong Bing, et al. Mmr1: Enhancing multimodal reasoning with variance-aware sampling and open resources.arXiv preprint arXiv:2509.21268, 2025
arXiv 2025
-
[18]
Jiang, Ziju Shen, et al
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q. Jiang, Ziju Shen, et al. NuminaMath: The largest public dataset in AI4Maths with 860k pairs of competition math problems and solutions. Technical report, Hugging Face / Project Numina, 2024
2024
-
[19]
Competition-level code generation with AlphaCode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with AlphaCode.Science, 378(6624):1092–1097, 2022
2022
-
[20]
SynLogic: Synthesizing verifiable reasoning data at scale for learning logical reasoning and beyond
Junteng Liu, Yuanxiang Fan, Zhuo Jiang, Han Ding, Yongyi Hu, Chi Zhang, Yiqi Shi, Shitong Weng, Aili Chen, Shiqi Chen, Yunan Huang, Mozhi Zhang, Pengyu Zhao, Junjie Yan, and Junxian He. SynLogic: Synthesizing verifiable reasoning data at scale for learning logical reasoning and beyond. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. a...
arXiv 2025
-
[21]
Visual-RFT: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-RFT: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025
Pith/arXiv arXiv 2025
-
[22]
MathVista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[23]
Ahmed Masry, Megh Thakkar, Aayush Bajaj, Aaryaman Kartha, Enamul Hoque, and Shafiq Joty. ChartGemma: Visual instruction-tuning for chart reasoning in the wild.arXiv preprint arXiv:2407.04172, 2024
arXiv 2024
-
[24]
ChartQAPro: A more diverse and challenging benchmark for chart question answering
Ahmed Masry, Mohammed Saidul Islam, Mahir Ahmed, Aayush Bajaj, Firoz Kabir, Aaryaman Kartha, Md Tahmid Rahman Laskar, Mizanur Rahman, Shadikur Rahman, Mehrad Shahmoham- madi, et al. ChartQAPro: A more diverse and challenging benchmark for chart question answering. arXiv preprint arXiv:2504.05506, 2025
arXiv 2025
-
[25]
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, Ping Luo, Yu Qiao, Qiaosheng Zhang, and Wenqi Shao. MM-Eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2503.07365, 2025
Pith/arXiv arXiv 2025
-
[26]
Fanqing Meng, Lingxiao Du, Jiawei Gu, Jiaqi Liao, Linjie Li, Zijian Wu, Xiangyan Liu, Ziqi Zhao, Mengkang Hu, Zichen Liu, et al. Gym-v: A unified vision environment system for agentic vision research.arXiv preprint arXiv:2603.15432, 2026. 12
Pith/arXiv arXiv 2026
-
[27]
Patel, Yuke Zhu, and Anima Anandkumar
Weili Nie, Zhiding Yu, Lei Mao, Ankit B. Patel, Yuke Zhu, and Anima Anandkumar. Bongard- LOGO: A new benchmark for human-level concept learning and reasoning. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[28]
Yingzhe Peng, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. LMM-R1: Empowering 3b LMMs with strong reasoning abilities through two-stage rule-based rl.arXiv preprint arXiv:2503.07536, 2025
Pith/arXiv arXiv 2025
-
[29]
Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, Runfeng Qiao, Yifan Zhang, Xiao Zong, Yida Xu, Muxi Diao, Zhimin Bao, Chen Li, and Honggang Zhang. We-Math: Does your large multimodal model achieve human-like mathematical reasoning?arXiv preprint arXiv:2407.01284, 2024
Pith/arXiv arXiv 2024
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[31]
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. VLM-R1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
Pith/arXiv arXiv 2025
-
[32]
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Lidong Bing, and Roy Ka-Wei Lee. Math-LLaV A: Bootstrapping mathematical reasoning for multimodal large language models.arXiv preprint arXiv:2406.17294, 2024
arXiv 2024
-
[33]
Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kad- dour, and Andreas Köpf. Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2505.24760
arXiv 2025
-
[34]
Reason-RFT: Reinforcement fine-tuning for visual reasoning.arXiv preprint arXiv:2503.20752, 2025
Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Minglan Lin, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Reason-RFT: Reinforcement fine-tuning for visual reasoning.arXiv preprint arXiv:2503.20752, 2025
arXiv 2025
-
[35]
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. VL-Rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025
Pith/arXiv arXiv 2025
-
[36]
Is a picture worth a thousand words? delving into spatial reasoning for vision language models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[37]
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, Alexis Chevalier, Sanjeev Arora, and Danqi Chen. CharXiv: Charting gaps in realistic chart understanding in multimodal LLMs.arXiv preprint arXiv:2406.18521, 2024
arXiv 2024
-
[38]
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. LogicVista: Multimodal LLM logical reasoning benchmark in visual contexts.arXiv preprint arXiv:2407.04973, 2024
Pith/arXiv arXiv 2024
-
[39]
Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar
Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. LeanDojo: Theorem proving with retrieval-augmented language models. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023. 13
2023
-
[40]
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, Bo Zhang, and Wei Chen. R1-Onevision: Advancing generalized multimodal reasoning through cross-modal formalization.arXiv preprint arXiv:2503.10615, 2025
Pith/arXiv arXiv 2025
-
[41]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[42]
Jiakang Yuan, Tianshuo Peng, Yilei Jiang, Yiting Lu, Renrui Zhang, Kaituo Feng, Chaoyou Fu, Tao Chen, Lei Bai, Bo Zhang, et al. MME-Reasoning: A comprehensive benchmark for logical reasoning in MLLMs.arXiv preprint arXiv:2505.21327, 2025
arXiv 2025
-
[43]
Mimo-vl technical report.arXiv preprint arXiv:2506.03569, 2025
Zihao Yue, Zhenru Lin, Yifan Song, Weikun Wang, Shuhuai Ren, Shuhao Gu, Shicheng Li, Peidian Li, Liang Zhao, Lei Li, et al. Mimo-vl technical report.arXiv preprint arXiv:2506.03569, 2025
arXiv 2025
-
[44]
Zhiyuan Zeng, Hamish Ivison, Yiping Wang, Lifan Yuan, Shuyue Stella Li, Zhuorui Ye, Siting Li, Jacqueline He, Runlong Zhou, Tong Chen, et al. Rlve: Scaling up reinforcement learning for language models with adaptive verifiable environments.arXiv preprint arXiv:2511.07317, 2025
Pith/arXiv arXiv 2025
-
[45]
RA VEN: A dataset for relational and analogical visual rEasoNing
Chi Zhang, Feng Gao, Baoxiong Jia, Yixin Zhu, and Song-Chun Zhu. RA VEN: A dataset for relational and analogical visual rEasoNing. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5317–5327, 2019
2019
-
[46]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, and Hongsheng Li. MathVerse: Does your multi-modal LLM truly see the diagrams in visual math problems?arXiv preprint arXiv:2403.14624, 2024
Pith/arXiv arXiv 2024
-
[47]
Mavis: Mathematical visual instruction tuning with an automatic data engine
Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Ziyu Guo, Yichi Zhang, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Shanghang Zhang, Gao Peng, et al. Mavis: Mathematical visual instruction tuning with an automatic data engine. InInternational Conference on Learning Representations, volume 2025, pages 87955–87989, 2025
2025
-
[48]
Xiangyu Zhao, Junming Lin, Tianhao Liang, Yifan Zhou, Wenhao Chai, Yuzhe Gu, Weiyun Wang, Kai Chen, Gen Luo, Wenwei Zhang, Junchi Yan, Hua Yang, Haodong Duan, and Xue Yang. MM- HELIX: Boosting multimodal long-chain reflective reasoning with holistic platform and adaptive hybrid policy optimization.arXiv preprint arXiv:2510.08540, 2025
arXiv 2025
-
[49]
miniF2F: A cross-system benchmark for formal olympiad-level mathematics
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. miniF2F: A cross-system benchmark for formal olympiad-level mathematics. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[50]
Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. DynaMath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models.arXiv preprint arXiv:2411.00836, 2024. 14 A. Fine-Grained Environment Coverage Table 6 expands the high-level suite composition in Table 1. The entries are representative r...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.