FedMTFI: Feature Importance Based Optimized Multi Teacher Knowledge Distillation in Heterogeneous Federated Learning Environment
Pith reviewed 2026-06-28 15:49 UTC · model grok-4.3
The pith
FedMTFI clusters clients by hardware to create prototype teachers, then applies multi-teacher distillation weighted by SHAP values to raise accuracy on non-IID data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
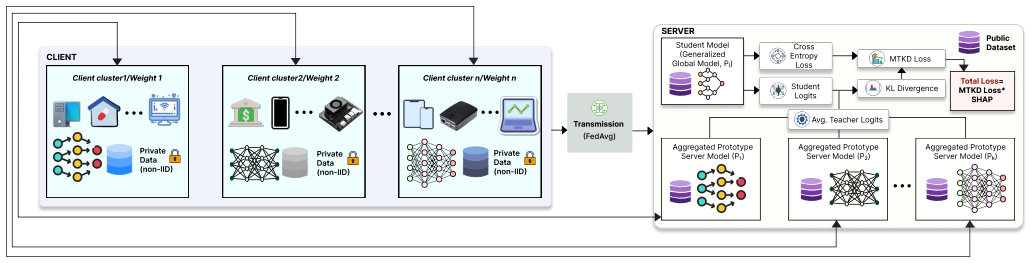
In FedMTFI, clients are clustered based on similar hardware and model types. Each cluster trains a model on its non-IID data, and the server aggregates these into prototype models using FedAvg. These prototypes then serve as teachers in multi-teacher knowledge distillation to train a global student model, with Shapley values used to emphasize important features during the process. Experimental results indicate that this leads to higher accuracy than traditional FL algorithms under non-IID conditions.
What carries the argument
Multi-teacher knowledge distillation that takes cluster-derived prototype models as teachers and applies Shapley values to weight feature importance during distillation of a global student.
Load-bearing premise
Clients can be grouped by hardware and model similarity so that the resulting aggregated prototypes serve as effective teachers for the global student.
What would settle it
An experiment on standard non-IID benchmarks that shows FedMTFI accuracy no higher than plain FedAvg or single-teacher distillation.
Figures
read the original abstract
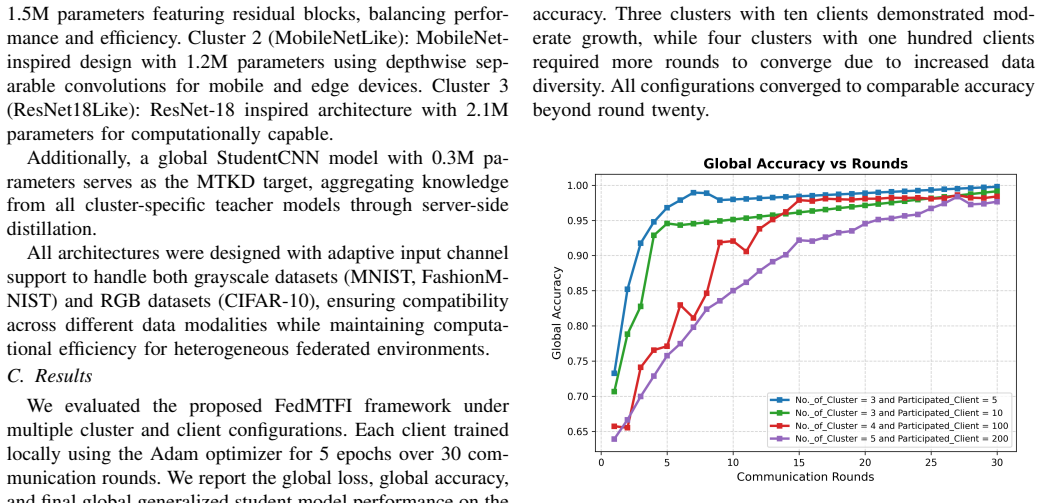
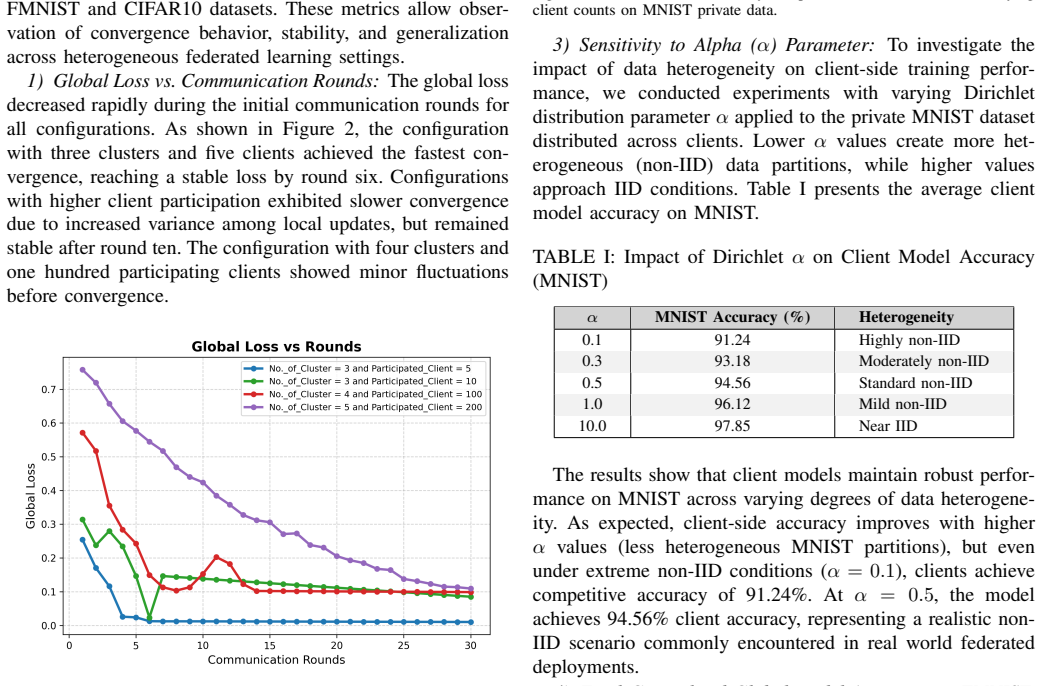
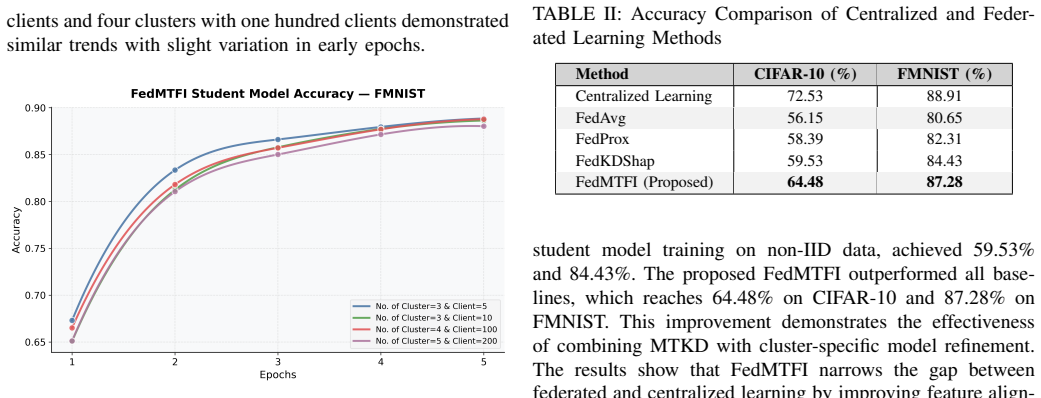
Federated learning (FL) is a decentralized approach that enables collaborative model training without exposing raw data. Instead of transferring sensitive data, it allows devices to share only model weights, keeping personal data locally and secure. However, in real world settings, the data held by devices is often not evenly distributed and devices mostly differ in computing power and memory capacity. These differences make FL harder to maintain consistent performance across the system. To address these issues, we propose FedMTFI, a novel architecture that combines multi-teacher knowledge distillation (MTKD) with feature importance to improve the FL process in heterogeneous environments. In FedMTFI, clients are clustered based on similar hardware and model types. Each cluster trains a specific model on not independently and identically distributed (non-IID) data. Within a cluster, every client updates that model using only its own local private data. The server then aggregates the locally trained models in each cluster using FedAvg to form multiple prototype models. Then these prototypes serve as teacher models to train a global generalized student model using MTKD. What makes FedMTFI more unique is the integration of Shapley values (SHAP) to emphasize important features during distillation, which enhances both accuracy and interpretability. Experimental results show that FedMTFI achieves higher accuracy than traditional FL algorithms and performs more effectively under non-IID data conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce FedMTFI, which clusters clients in heterogeneous FL by hardware and model similarity, aggregates local models per cluster with FedAvg to create multiple prototype teachers, and then uses multi-teacher knowledge distillation weighted by SHAP feature importance to train a global student model, reporting higher accuracy than standard FL methods under non-IID conditions.
Significance. Should the experimental results be substantiated, the method could provide a useful framework for managing device and data heterogeneity in federated learning through prototype-based multi-teacher distillation and feature importance, potentially improving both performance and interpretability in practical deployments.
major comments (2)
- [Abstract] The statement 'Experimental results show that FedMTFI achieves higher accuracy than traditional FL algorithms and performs more effectively under non-IID data conditions' is presented without any accompanying metrics, baseline comparisons, dataset descriptions, number of experimental runs, or statistical significance tests. This omission is load-bearing for the central performance claim.
- [Abstract] No quantitative support is provided for the assumption that hardware/model-based clustering yields intra-cluster prototypes that are effective teachers for MTKD; the description lacks any mention of data distribution similarity within clusters or ablation experiments on the clustering approach, which is critical given that hardware similarity does not guarantee statistical similarity of local datasets.
minor comments (1)
- [Abstract] The sentence 'Within a cluster, every client updates that model using only its own local private data' could be clarified to specify the local training procedure more precisely.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract requires more specific quantitative support and justification for the clustering approach to strengthen the central claims, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] The statement 'Experimental results show that FedMTFI achieves higher accuracy than traditional FL algorithms and performs more effectively under non-IID data conditions' is presented without any accompanying metrics, baseline comparisons, dataset descriptions, number of experimental runs, or statistical significance tests. This omission is load-bearing for the central performance claim.
Authors: We acknowledge that the current abstract is too concise and lacks the requested supporting details. In the revised version, we will expand the abstract to include specific accuracy metrics from the experiments (e.g., improvements over FedAvg on MNIST and CIFAR-10), baseline comparisons, dataset information, number of runs, and mention of statistical tests. This change will directly address the load-bearing nature of the performance claim. revision: yes
-
Referee: [Abstract] No quantitative support is provided for the assumption that hardware/model-based clustering yields intra-cluster prototypes that are effective teachers for MTKD; the description lacks any mention of data distribution similarity within clusters or ablation experiments on the clustering approach, which is critical given that hardware similarity does not guarantee statistical similarity of local datasets.
Authors: The clustering in FedMTFI groups clients by hardware and model similarity to enable per-cluster FedAvg prototypes as teachers, with MTKD then addressing non-IID data heterogeneity across clusters. We agree the abstract provides no quantitative support or ablations for intra-cluster data similarity. We will revise the abstract to briefly justify the hardware/model clustering rationale and note its role in prototype quality, while acknowledging that data similarity is not directly enforced by hardware. If the full paper lacks dedicated clustering ablations, we will add a clarifying sentence or limitation note. revision: partial
Circularity Check
No derivation chain or equations present; claims rest on experimental assertions
full rationale
The manuscript describes a procedural architecture (client clustering by hardware/model type, per-cluster FedAvg to produce prototypes, MTKD with SHAP weighting) but supplies no equations, first-principles derivations, or mathematical steps that could be inspected for reduction to inputs by construction. Central performance claims are stated as outcomes of unspecified experiments rather than derived predictions. No self-citation load-bearing steps, fitted-input-as-prediction patterns, or ansatz smuggling appear in the provided text. The derivation is therefore self-contained by absence of any derivational content to analyze.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Local data remains private and only model weights are shared.
- ad hoc to paper Hardware and model similarity clustering produces useful prototype teachers.
Reference graph
Works this paper leans on
-
[1]
Review on the application of artificial intelligence in smart homes,
X. Guo, Z. Shen, Y . Zhang, and T. Wu, “Review on the application of artificial intelligence in smart homes,”Smart Cities, vol. 2, no. 3, pp. 402–420, 2019
2019
-
[2]
Artificial intelligence in healthcare: past, present and future,
F. Jiang, Y . Jiang, H. Zhi, Y . Dong, H. Li, S. Ma, Y . Wang, Q. Dong, H. Shen, and Y . Wang, “Artificial intelligence in healthcare: past, present and future,”Stroke and vascular neurology, vol. 2, no. 4, 2017
2017
-
[3]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[4]
arXiv preprint arXiv:1905.05950 , year=
I. Tenney, D. Das, and E. Pavlick, “Bert rediscovers the classical nlp pipeline,”arXiv preprint arXiv:1905.05950, 2019
-
[5]
A survey of autonomous driving: Common practices and emerging technologies,
E. Yurtsever, J. Lambert, A. Carballo, and K. Takeda, “A survey of autonomous driving: Common practices and emerging technologies,” IEEE access, vol. 8, pp. 58 443–58 469, 2020
2020
-
[6]
Fedboost: A communication- efficient algorithm for federated learning,
J. Hamer, M. Mohri, and A. T. Suresh, “Fedboost: A communication- efficient algorithm for federated learning,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 3973–3983
2020
-
[7]
Adaptive privacy preserving deep learning algorithms for medical data,
X. Zhang, J. Ding, M. Wu, S. T. C. Wong, H. Van Nguyen, and M. Pan, “Adaptive privacy preserving deep learning algorithms for medical data,” in2021 IEEE Winter Conference on Applications of Computer Vision (WACV), 2021, pp. 1168–1177
2021
-
[8]
Federated machine learning: Concept and applications,
Q. Yang, Y . Liu, T. Chen, and Y . Tong, “Federated machine learning: Concept and applications,”ACM Transactions on Intelligent Systems and Technology (TIST), vol. 10, no. 2, pp. 1–19, 2019
2019
-
[9]
Leaf: A benchmark for federated settings,
S. Caldas, S. M. K. Duddu, P. Wu, T. Li, J. Kone ˇcn`y, H. B. McMahan, V . Smith, and A. Talwalkar, “Leaf: A benchmark for federated settings,” arXiv preprint arXiv:1812.01097, 2018
-
[10]
Energy efficient federated learning over cooperative relay-assisted wireless networks,
X. Zhang, R. Chen, J. Wang, H. Zhang, and M. Pan, “Energy efficient federated learning over cooperative relay-assisted wireless networks,” inGLOBECOM 2022-2022 IEEE Global Communications Conference. IEEE, 2022, pp. 179–184
2022
-
[11]
Flower: A Friendly Federated Learning Research Framework
D. J. Beutel, T. Topal, A. Mathur, X. Qiu, J. Fernandez-Marques, Y . Gao, L. Sani, K. H. Li, T. Parcollet, P. P. B. de Gusm ˜aoet al., “Flower: A friendly federated learning research framework,”arXiv preprint arXiv:2007.14390, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[12]
Hermes: an efficient federated learning framework for heterogeneous mobile clients,
A. Li, J. Sun, P. Li, Y . Pu, H. Li, and Y . Chen, “Hermes: an efficient federated learning framework for heterogeneous mobile clients,” in Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, 2021, pp. 420–437
2021
-
[13]
Interpret Federated Learning with Shapley Values
G. Wang, “Interpret federated learning with shapley values,”arXiv preprint arXiv:1905.04519, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[14]
Eefl: High-speed wireless communications inspired energy efficient federated learning over mobile devices,
R. Chen, Q. Wan, X. Zhang, X. Qin, Y . Hou, D. Wang, X. Fu, and M. Pan, “Eefl: High-speed wireless communications inspired energy efficient federated learning over mobile devices,” inProceedings of the 21st Annual International Conference on Mobile Systems, Applications and Services, 2023, pp. 544–556
2023
-
[15]
Face mask detection using deep learning and transfer learning models,
N. S. Shadin, S. Sanjana, and D. Ibrahim, “Face mask detection using deep learning and transfer learning models,” in2022 International Conference on Innovations in Science, Engineering and Technology (ICISET), 2022, pp. 196–201
2022
-
[16]
Ensemble distillation for robust model fusion in federated learning,
T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,”Advances in neural information processing systems, vol. 33, pp. 2351–2363, 2020
2020
-
[17]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,”Proceedings of Machine learning and systems, vol. 2, pp. 429–450, 2020
2020
-
[18]
Fedmd: Heterogenous federated learning via model distillation,
D. Li and J. Wang, “Fedmd: Heterogenous federated learning via model distillation,”arXiv preprint arXiv:1910.03581, 2019
-
[19]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Ro- bust semantic segmentation with multi-teacher knowledge distillation,
A. Amirkhani, A. Khosravian, M. Masih-Tehrani, and H. Kashiani, “Ro- bust semantic segmentation with multi-teacher knowledge distillation,” IEEE Access, vol. 9, pp. 119 049–119 066, 2021
2021
-
[21]
Heterogeneity-aware private personalized federated learning for medical imaging via con- trastive distillation,
N. S. Shadin, X. Zhang, J. Wang, and M. Pan, “Heterogeneity-aware private personalized federated learning for medical imaging via con- trastive distillation,” in2025 IEEE International Conference on Big Data (BigData), 2025, pp. 2033–2042
2025
-
[22]
Fedkdshap: Enhancing federated learning via shapley values driven knowledge distillation on non-iid data,
N. S. Shadin and X. Zhang, “Fedkdshap: Enhancing federated learning via shapley values driven knowledge distillation on non-iid data,” in Companion Proceedings of the ACM on Web Conference 2025, 2025, pp. 1744–1751
2025
-
[23]
Characterizing impacts of heterogeneity in federated learning upon large-scale smartphone data,
C. Yang, Q. Wang, M. Xu, Z. Chen, K. Bian, Y . Liu, and X. Liu, “Characterizing impacts of heterogeneity in federated learning upon large-scale smartphone data,” inProceedings of the Web Conference 2021, 2021, pp. 935–946
2021
-
[24]
Adaptive group robust en- semble knowledge distillation,
P. Kenfack, U. A ¨ıvodji, and S. E. Kahou, “Adaptive group robust en- semble knowledge distillation,”arXiv preprint arXiv:2411.14984, 2024
-
[25]
Measure contribution of partici- pants in federated learning,
G. Wang, C. X. Dang, and Z. Zhou, “Measure contribution of partici- pants in federated learning,” in2019 IEEE International Conference on Big Data (Big Data). IEEE, 2019, pp. 2597–2604
2019
-
[26]
X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of fedavg on non-iid data,”arXiv preprint arXiv:1907.02189, 2019
-
[27]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[28]
Scaffold: Stochastic controlled averaging for federated learn- ing,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “Scaffold: Stochastic controlled averaging for federated learn- ing,” inInternational conference on machine learning. PMLR, 2020, pp. 5132–5143
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.