DOT-MoE: Differentiable Optimal Transport for MoEfication
Pith reviewed 2026-06-28 15:28 UTC · model grok-4.3
The pith
DOT-MoE converts dense models to MoEs by framing neuron assignment as a differentiable optimal transport problem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
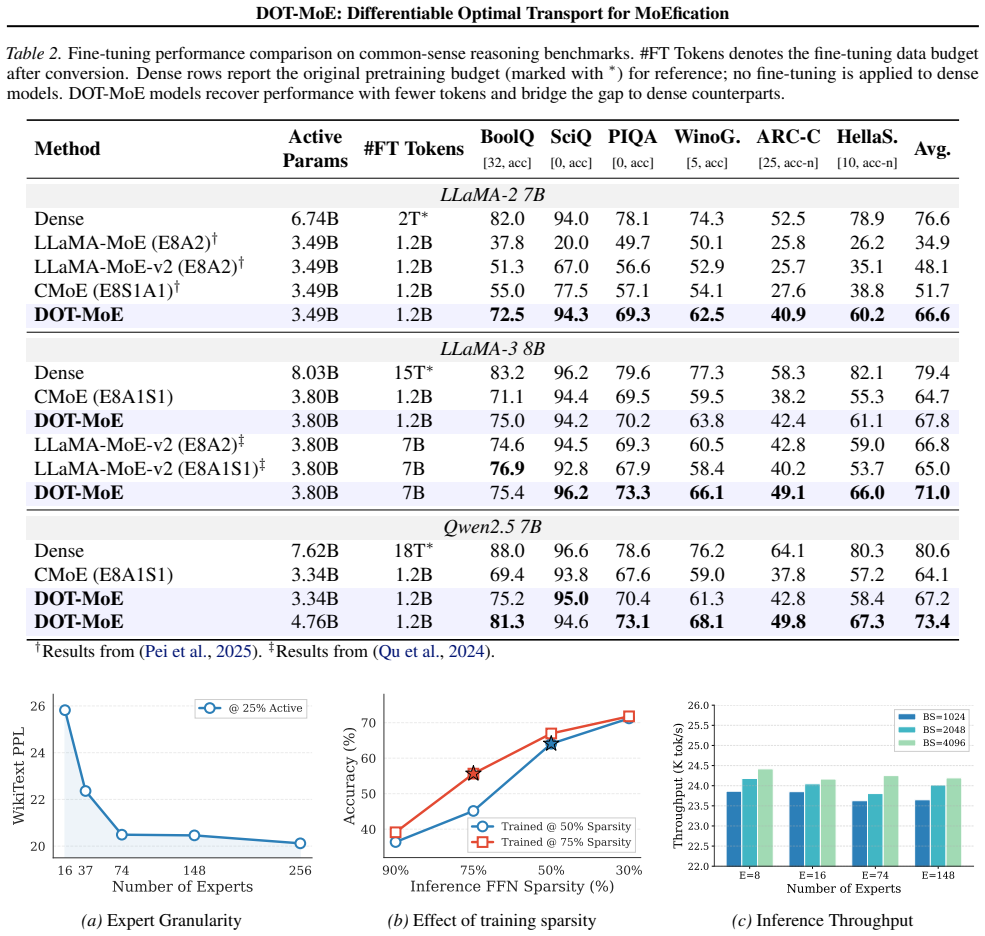
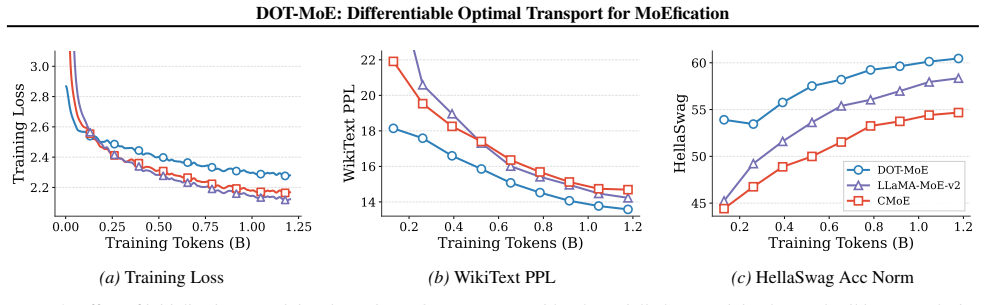
DOT-MoE formulates the decomposition of dense layers as a balanced optimal transport problem and solves it with differentiable Sinkhorn-Knopp iterations to enforce strict expert capacity constraints, then uses straight-through estimators to jointly optimize the discrete neuron-to-expert assignments and the token-to-expert routing policy, yielding models that outperform structured pruning, heuristic clustering, and random-split baselines while retaining 90 percent of original performance at 50 percent active parameters.
What carries the argument
The balanced optimal transport formulation solved by differentiable Sinkhorn iterations that produces neuron-to-expert assignments under capacity constraints.
If this is right
- Pre-trained dense models can be converted to MoEs without the instability of training sparse models from scratch.
- Active parameter count can be halved while retaining 90 percent of the dense model's performance across tested architectures.
- End-to-end learning of both the discrete assignments and the routing policy becomes feasible through straight-through estimators.
Where Pith is reading between the lines
- The same transport framing might apply to partitioning weights in other layer types such as attention heads.
- Automated conversion pipelines could become practical for deploying large models under tight memory or latency budgets.
- The strict balance enforced by transport may produce different behavior when the number of experts grows very large.
Load-bearing premise
That the optimal transport solution for assigning neurons to experts preserves model capability better than simpler heuristic or random partitions.
What would settle it
A controlled test on a held-out architecture and benchmark set where DOT-MoE falls below the performance of heuristic clustering baselines.
Figures


read the original abstract
The scaling of Large Language Models (LLMs) has driven significant performance gains but created substantial challenges in inference efficiency. While Mixture of Experts (MoEs) architectures address this by decoupling model size from inference cost, training MoEs from scratch is often unstable and compute intensive. Conversion of pre-trained dense models into sparse MoEs has emerged as an alternative solution; however, existing methods typically rely on heuristic neuron clustering or random splitting to partition the Feed-Forward Network (FFN) into experts. In this work, we propose DOT-MoE, a novel framework that formulates the decomposition of dense layers as a Differentiable Optimal Transport (DOT) problem. Instead of static heuristics, we model neuron assignment as a balanced transport problem, utilizing differentiable Sinkhorn-Knopp iterations to enforce strict expert capacity constraints. Furthermore, we utilize Straight-Through Estimators (STE) to jointly learn the discrete neuron-to-expert assignment and the token-to-expert routing policy end-to-end. Extensive experiments across multiple architectures and benchmarks demonstrate that DOT-MoE significantly outperforms structured pruning, heuristic clustering, and random-split baselines, retaining 90% of the original dense model's performance while reducing active parameters by 50%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DOT-MoE, a framework that converts pre-trained dense LLMs into sparse MoE models by casting FFN layer decomposition as a balanced differentiable optimal transport problem. Neuron-to-expert assignments are obtained via Sinkhorn-Knopp iterations with strict capacity constraints, and straight-through estimators enable joint end-to-end learning of the discrete assignments together with the token-to-expert routing policy. The central empirical claim is that this approach significantly outperforms structured pruning, heuristic clustering, and random-split baselines, retaining 90% of the original dense model's performance while halving the number of active parameters.
Significance. If the reported performance retention and outperformance hold under rigorous controls, the method would supply a more principled, capacity-constrained alternative to heuristic partitioning for post-hoc MoE conversion. This could reduce reliance on unstable from-scratch MoE training and improve inference efficiency for large models. The use of differentiable OT plus STE is a technically coherent way to enforce balance without post-hoc fixes, but the absence of concrete metrics, significance tests, or robustness data in the supplied material prevents a firm judgment of practical impact.
major comments (2)
- Abstract: the claim that DOT-MoE 'significantly outperforms' baselines and 'retains 90% of the original dense model's performance' is presented without any reported metrics (e.g., perplexity, accuracy deltas), statistical significance, hyperparameter sensitivity analysis, or checks for robustness across random seeds and model scales. This omission makes the central empirical claim impossible to evaluate from the given text.
- Abstract: the assumption that framing neuron assignment as a balanced OT problem solved by differentiable Sinkhorn iterations will yield partitions that preserve capability better than heuristics is stated but not accompanied by any derivation or ablation showing that the transport cost or capacity constraints are load-bearing for the reported gains; the experimental outcomes are the sole support.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. We address each major point below and indicate where revisions to the manuscript will be made.
read point-by-point responses
-
Referee: Abstract: the claim that DOT-MoE 'significantly outperforms' baselines and 'retains 90% of the original dense model's performance' is presented without any reported metrics (e.g., perplexity, accuracy deltas), statistical significance, hyperparameter sensitivity analysis, or checks for robustness across random seeds and model scales. This omission makes the central empirical claim impossible to evaluate from the given text.
Authors: We agree that the abstract, due to length constraints, does not include specific numerical deltas, statistical tests, or robustness details. The full manuscript reports concrete perplexity and accuracy results across models and benchmarks, with baseline comparisons. To make the central claim more evaluable directly from the abstract, we will revise it to include example quantitative results (e.g., specific retention percentages and deltas on key tasks). revision: yes
-
Referee: Abstract: the assumption that framing neuron assignment as a balanced OT problem solved by differentiable Sinkhorn iterations will yield partitions that preserve capability better than heuristics is stated but not accompanied by any derivation or ablation showing that the transport cost or capacity constraints are load-bearing for the reported gains; the experimental outcomes are the sole support.
Authors: The method section motivates the balanced OT formulation by the need for strict, differentiable capacity constraints without post-hoc adjustments. No theoretical derivation of optimality is provided. The primary evidence is empirical comparison to heuristic baselines. We will add a targeted ablation isolating the transport cost and capacity terms in the revised manuscript to demonstrate their contribution to the observed gains. revision: yes
Circularity Check
No significant circularity
full rationale
The paper formulates neuron-to-expert assignment as a balanced optimal transport problem solved with differentiable Sinkhorn iterations and STE, then reports empirical gains over pruning, clustering, and random baselines. No equation or claim in the supplied abstract reduces the reported performance retention or parameter reduction to a quantity defined by the same fitted parameters or by a self-citation chain. The central claim rests on external experimental outcomes rather than on a definitional or fitted-input equivalence, making the derivation self-contained against the given material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[2]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Outrageously large neural networks , volume=
The sparsely-gated mixture-of-experts layer , author=. Outrageously large neural networks , volume=
-
[4]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[5]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
St-moe: Designing stable and transferable sparse expert models , author=. arXiv preprint arXiv:2202.08906 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proceedings of the 2020 conference on empirical methods in natural language processing (emnlp) , pages=
Structured pruning of large language models , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (emnlp) , pages=
2020
-
[7]
M o E fication: Transformer Feed-forward Layers are Mixtures of Experts
Zhang, Zhengyan and Lin, Yankai and Liu, Zhiyuan and Li, Peng and Sun, Maosong and Zhou, Jie. M o E fication: Transformer Feed-forward Layers are Mixtures of Experts. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.71
-
[8]
LL a MA - M o E : Building Mixture-of-Experts from LL a MA with Continual Pre-Training
Zhu, Tong and Qu, Xiaoye and Dong, Daize and Ruan, Jiacheng and Tong, Jingqi and He, Conghui and Cheng, Yu. LL a MA - M o E : Building Mixture-of-Experts from LL a MA with Continual Pre-Training. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.890
-
[9]
ArXiv , year=
LLaMA-MoE v2: Exploring Sparsity of LLaMA from Perspective of Mixture-of-Experts with Post-Training , author=. ArXiv , year=
-
[10]
Morley and Chen, Beidi and Lai, Fan and Prakash, Atul , title =
Zheng, Haizhong and Bai, Xiaoyan and Liu, Xueshen and Mao, Z. Morley and Chen, Beidi and Lai, Fan and Prakash, Atul , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[11]
2025 , eprint=
CMoE: Converting Mixture-of-Experts from Dense to Accelerate LLM Inference , author=. 2025 , eprint=
2025
-
[12]
Transactions on Machine Learning Research , issn=
ToMoE: Converting Dense Large Language Models to Mixture-of-Experts through Dynamic Structural Pruning , author=. Transactions on Machine Learning Research , issn=. 2026 , url=
2026
-
[13]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Shortgpt: Layers in large language models are more redundant than you expect , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[14]
Slicegpt: Compress large language models by deleting rows and columns.arXiv preprint, 2024
Slicegpt: Compress large language models by deleting rows and columns , author=. arXiv preprint arXiv:2401.15024 , year=
-
[15]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[16]
arXiv preprint arXiv:2402.09025 , year=
Sleb: Streamlining llms through redundancy verification and elimination of transformer blocks , author=. arXiv preprint arXiv:2402.09025 , year=
-
[17]
arXiv preprint arXiv:2312.17244 , year=
The llm surgeon , author=. arXiv preprint arXiv:2312.17244 , year=
-
[18]
arXiv preprint arXiv:2408.09632 , year=
Modegpt: Modular decomposition for large language model compression , author=. arXiv preprint arXiv:2408.09632 , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Disp-llm: Dimension-independent structural pruning for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
HellaSwag: Can a Machine Really Finish Your Sentence?
Hellaswag: Can a machine really finish your sentence? , author=. arXiv preprint arXiv:1905.07830 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[22]
Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin , title =. Commun. ACM , month = aug, pages =. 2021 , issue_date =. doi:10.1145/3474381 , abstract =
-
[23]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. arXiv preprint arXiv:1905.10044 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[24]
Crowdsourcing Multiple Choice Science Questions
Crowdsourcing multiple choice science questions , author=. arXiv preprint arXiv:1707.06209 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[26]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Estimating or propagating gradients through stochastic neurons for conditional computation , author=. arXiv preprint arXiv:1308.3432 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[28]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[29]
SIAM Journal on Matrix Analysis and Applications , volume=
The Sinkhorn--Knopp algorithm: convergence and applications , author=. SIAM Journal on Matrix Analysis and Applications , volume=. 2008 , publisher=
2008
-
[30]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[31]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Rethinking the Value of Training-Free Structured Pruning of
Nahush Lele and Arnav Chavan and Aryamaan Thakur and Deepak Gupta , journal=. Rethinking the Value of Training-Free Structured Pruning of. 2025 , url=
2025
-
[34]
Pacific Journal of Mathematics , volume=
Concerning nonnegative matrices and doubly stochastic matrices , author=. Pacific Journal of Mathematics , volume=. 1967 , publisher=
1967
-
[35]
Journal of machine learning research , volume=
Visualizing data using t-SNE , author=. Journal of machine learning research , volume=
-
[36]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[37]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[38]
Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
2020
-
[39]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[40]
2025 , eprint=
2 OLMo 2 Furious , author=. 2025 , eprint=
2025
-
[41]
2025 , eprint=
OLMoE: Open Mixture-of-Experts Language Models , author=. 2025 , eprint=
2025
-
[42]
2013 , eprint=
Sinkhorn Distances: Lightspeed Computation of Optimal Transportation Distances , author=. 2013 , eprint=
2013
-
[43]
The LLM Surgeon , author=
-
[44]
SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks , author=
-
[45]
MoDeGPT: Modular Decomposition for Large Language Model Compression , author=
-
[46]
International conference on machine learning , pages=
Sparsegpt: Massive language models can be accurately pruned in one-shot , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[47]
A Simple and Effective Pruning Approach for Large Language Models , author=
-
[48]
International Conference on Machine Learning , pages=
Pruner-Zero: Evolving Symbolic Pruning Metric From Scratch for Large Language Models , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[49]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, Joshua and Lee-Thorp, James and de Jong, Michiel and Zemlyanskiy, Yury and Lebr. arXiv preprint arXiv:2305.13245 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.