HarnessForge: Joint Harness and Policy Evolution for Adaptive Agent Systems
Pith reviewed 2026-06-28 14:57 UTC · model grok-4.3
The pith
LLM agent systems improve when their external harness and internal reasoning policy co-evolve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
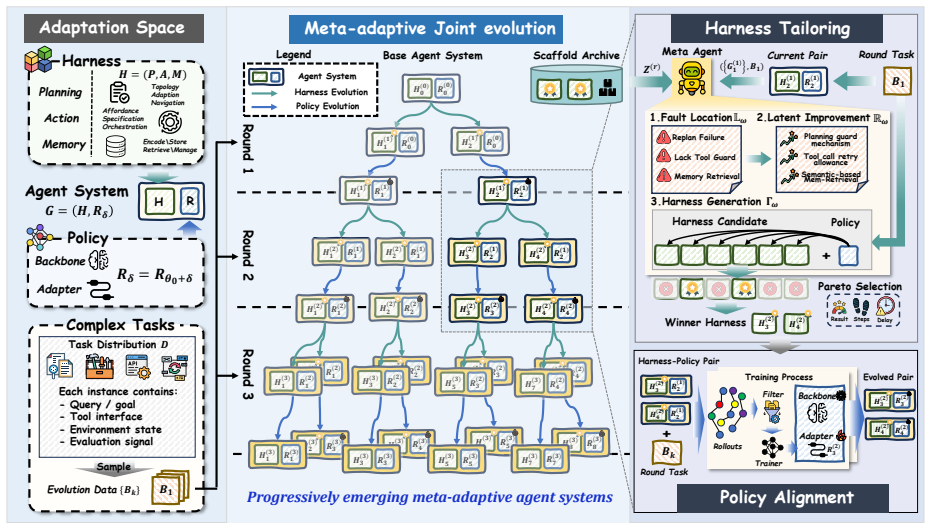
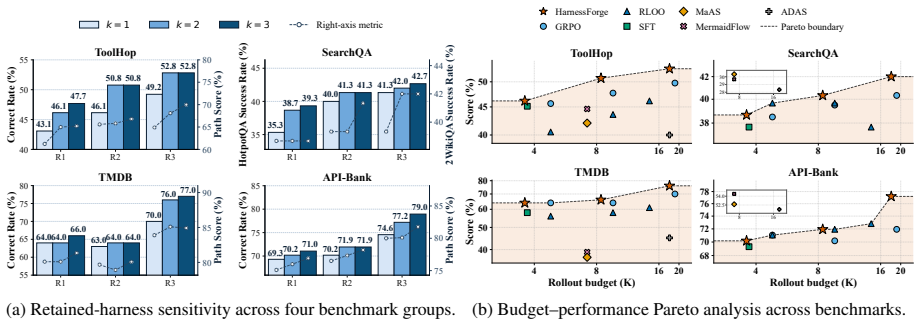
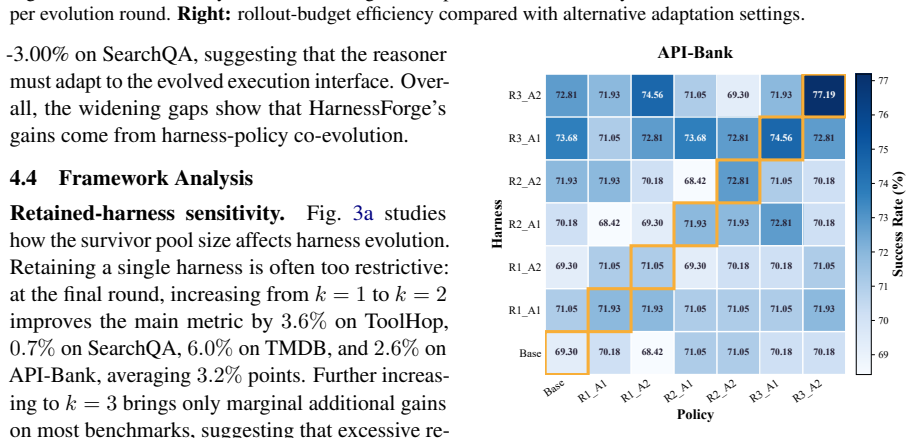
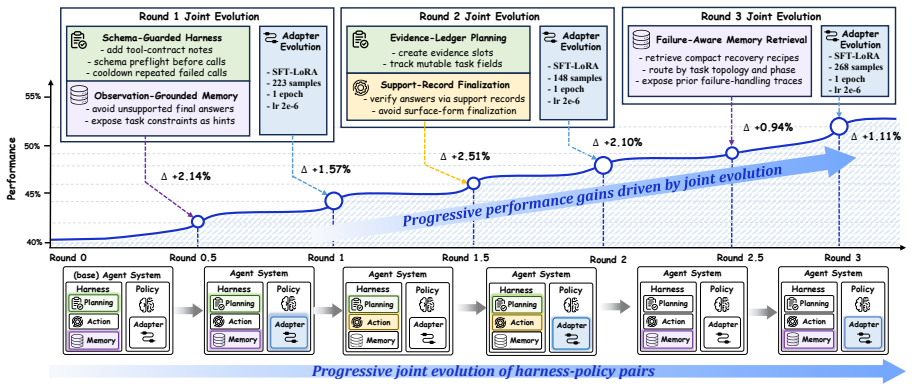
HarnessForge formulates an agent system as a harness–policy pair, performs harness–policy co-evolution through fault-guided harness tailoring and harness-conditioned policy alignment, and demonstrates on five benchmarks that this joint process improves Qwen3-4B and Qwen3-8B backbones over harness-only and policy-only baselines with gains up to 12.0 percent while producing favorable rollout-efficiency tradeoffs.
What carries the argument
The harness–policy pair, which separates harness-level execution structure from policy-level reasoning behavior and supplies the stable space for joint adaptation.
If this is right
- Joint co-evolution outperforms isolated updates to either harness or policy alone.
- Executable compatibility between harness and policy is required for effective system-level adaptation.
- The same co-evolution process delivers gains on both 4B and 8B model backbones.
- The approach yields improved performance without sacrificing rollout efficiency.
Where Pith is reading between the lines
- Making the harness-policy boundary explicit could be applied to other agent frameworks that currently adapt components independently.
- The separation of structure and reasoning might allow modular testing of compatibility on tasks outside the current five benchmarks.
- If compatibility proves load-bearing, future agent designs could include explicit compatibility checks during training or deployment.
Load-bearing premise
The five benchmarks adequately represent heterogeneous task regimes such that performance gains can be attributed to harness-policy compatibility rather than benchmark-specific artifacts or baseline weaknesses.
What would settle it
A new set of benchmarks or models where separate harness-only or policy-only updates match or exceed the joint co-evolution results would falsify the necessity of joint evolution.
Figures


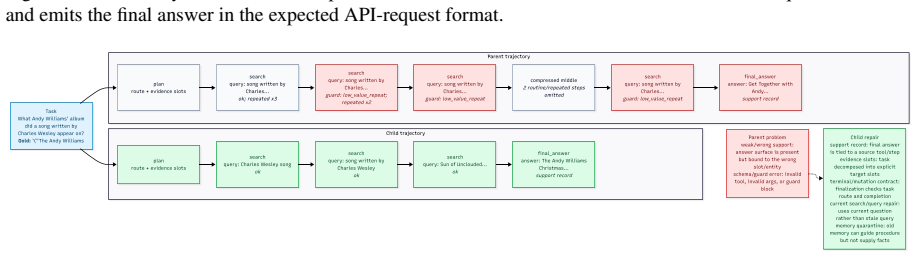
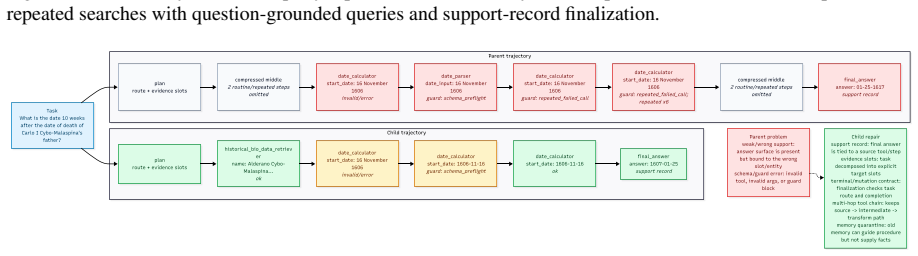
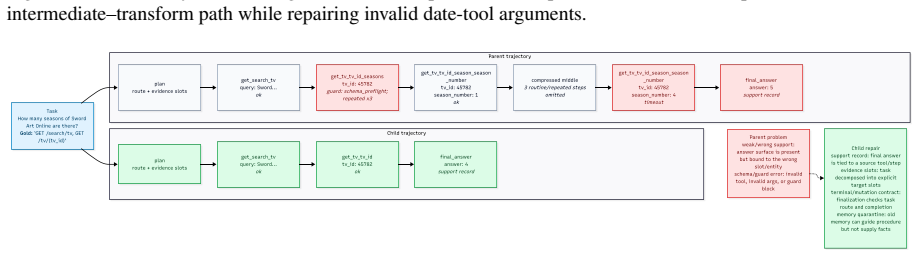
read the original abstract
LLM agents are increasingly expected to operate across heterogeneous task regimes that require distinct execution paradigms. This challenges fixed agent systems and motivates system-level meta-adaptation beyond isolated component updates. While existing works have adapted external harness or trained underlying reasoning policies, full-system adaptation remains insufficiently characterized. The adaptation space between structure and execution is rarely made explicit, and the compatibility between the external harness and the internal reasoner is not optimized jointly. We propose HarnessForge, a meta-adaptive framework for evolving LLM agent systems. HarnessForge formulates an agent system as a harness--policy pair, defining a stable adaptation space that separates harness-level execution structure from policy-level reasoning behavior. It then performs harness--policy co-evolution through fault-guided harness tailoring and harness-conditioned policy alignment. Experiments across five benchmarks from diverse domains show that HarnessForge consistently improves both Qwen3-4B and Qwen3-8B backbones, outperforming harness-only and policy-only baselines with gains of up to 12.0\% over the strongest baseline and achieving favorable rollout-efficiency tradeoffs, demonstrating that harness--policy co-evolution is effective, and that executable compatibility between the harness and reasoning policy is essential for agent-system adaptation. The code is available at https://github.com/mingju-c/HarnessForge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HarnessForge, a meta-adaptive framework that models an LLM agent system as a harness–policy pair and performs co-evolution via fault-guided harness tailoring and harness-conditioned policy alignment. It reports consistent performance gains (up to 12 %) over harness-only and policy-only baselines on five benchmarks using Qwen3-4B and Qwen3-8B backbones, together with favorable efficiency trade-offs, and concludes that executable compatibility between harness and policy is essential for effective system adaptation. The code is released at https://github.com/mingju-c/HarnessForge.
Significance. If the empirical claims are substantiated, the work supplies a concrete formulation of the adaptation space between external structure and internal reasoning and demonstrates that joint optimization can outperform isolated component adaptation. The public code release is a clear strength that enables direct reproduction and extension.
major comments (3)
- [Abstract / Experiments] Abstract and experimental evaluation: the central claim of consistent gains attributable to harness–policy co-evolution rests on comparisons against baselines, yet the text supplies no description of baseline implementations, no statistical significance tests, no error bars, and no data-exclusion criteria. Without these, the 12 % margin cannot be verified as robust evidence for the compatibility thesis.
- [Abstract / Experiments] Abstract and experimental evaluation: the five benchmarks are described only as “from diverse domains,” with no quantitative characterization of task heterogeneity (statefulness, tool-use density, horizon length, or failure-mode distribution). Consequently it is impossible to confirm that performance deltas arise from harness–policy compatibility rather than benchmark-specific artifacts.
- [Abstract] Abstract: the assertion that “executable compatibility … is essential” is not supported by any explicit metric (e.g., execution-trace overlap, failure-mode alignment, or an ablation that isolates compatibility from the fault-guided tailoring step itself).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where our experimental reporting can be strengthened. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental evaluation: the central claim of consistent gains attributable to harness–policy co-evolution rests on comparisons against baselines, yet the text supplies no description of baseline implementations, no statistical significance tests, no error bars, and no data-exclusion criteria. Without these, the 12 % margin cannot be verified as robust evidence for the compatibility thesis.
Authors: We agree that these details are necessary for verifying the robustness of the reported gains. The revised manuscript will include explicit descriptions of the harness-only and policy-only baseline implementations, results from statistical significance tests (such as paired t-tests), error bars in all relevant figures, and any applicable data-exclusion criteria. revision: yes
-
Referee: [Abstract / Experiments] Abstract and experimental evaluation: the five benchmarks are described only as “from diverse domains,” with no quantitative characterization of task heterogeneity (statefulness, tool-use density, horizon length, or failure-mode distribution). Consequently it is impossible to confirm that performance deltas arise from harness–policy compatibility rather than benchmark-specific artifacts.
Authors: We concur that quantitative characterization of benchmark heterogeneity is required. We will add a dedicated table and accompanying analysis quantifying statefulness, tool-use density, horizon length, and failure-mode distributions for each of the five benchmarks to demonstrate that the observed gains are attributable to harness–policy co-evolution. revision: yes
-
Referee: [Abstract] Abstract: the assertion that “executable compatibility … is essential” is not supported by any explicit metric (e.g., execution-trace overlap, failure-mode alignment, or an ablation that isolates compatibility from the fault-guided tailoring step itself).
Authors: While the performance advantage of joint co-evolution over isolated adaptations provides supporting evidence, we acknowledge the value of more direct quantification. The revision will introduce an explicit compatibility metric (e.g., execution-trace overlap) together with an ablation isolating compatibility effects from the tailoring step. revision: yes
Circularity Check
No circularity: purely empirical comparisons with no equations or self-referential reductions
full rationale
The manuscript describes a meta-adaptive framework evaluated via experiments on five benchmarks, reporting performance gains over harness-only and policy-only baselines. No equations, fitted parameters, derivation steps, or self-citations appear in the abstract or described content. Claims rest on direct empirical deltas rather than any reduction of outputs to inputs by construction. The absence of mathematical structure or load-bearing citations means the derivation chain (such as it is) is self-contained and externally falsifiable via the reported rollouts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agent systems can be decomposed into a stable harness-policy pair that separates execution structure from reasoning behavior.
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs , author=. 2024 , eprint=
2024
-
[2]
2026 , eprint=
AutoHarness: improving LLM agents by automatically synthesizing a code harness , author=. 2026 , eprint=
2026
-
[3]
2026 , eprint=
Meta-Harness: End-to-End Optimization of Model Harnesses , author=. 2026 , eprint=
2026
-
[4]
2026 , eprint=
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses , author=. 2026 , eprint=
2026
-
[5]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[6]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[7]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , url =
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , url =
-
[8]
2024 , eprint=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. 2024 , eprint=
2024
-
[9]
The Fourteenth International Conference on Learning Representations , year=
Agentic Reinforced Policy Optimization , author=. The Fourteenth International Conference on Learning Representations , year=
-
[10]
Group-in-Group Policy Optimization for LLM Agent Training , url =
Feng, Lang and Xue, Zhenghai and Liu, Tingcong and An, Bo , booktitle =. Group-in-Group Policy Optimization for LLM Agent Training , url =
-
[11]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[12]
Ho, Xanh and Duong Nguyen, Anh-Khoa and Sugawara, Saku and Aizawa, Akiko. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.580
-
[13]
Sirui Hong and Mingchen Zhuge and Jonathan Chen and Xiawu Zheng and Yuheng Cheng and Jinlin Wang and Ceyao Zhang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and Liyang Zhou and Chenyu Ran and Lingfeng Xiao and Chenglin Wu and J. Meta. The Twelfth International Conference on Learning Representations , year=
-
[14]
T ree RL : LLM Reinforcement Learning with On-Policy Tree Search
Hou, Zhenyu and Hu, Ziniu and Li, Yujiang and Lu, Rui and Tang, Jie and Dong, Yuxiao. T ree RL : LLM Reinforcement Learning with On-Policy Tree Search. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.604
-
[15]
Automated Design of Agentic Systems , url =
Hu, Shengran and Lu, Cong and Clune, Jeff , booktitle =. Automated Design of Agentic Systems , url =
-
[16]
2025 , eprint=
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[17]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav , title...
-
[18]
API -Bank: A Comprehensive Benchmark for Tool-Augmented LLM s
Li, Minghao and Zhao, Yingxiu and Yu, Bowen and Song, Feifan and Li, Hangyu and Yu, Haiyang and Li, Zhoujun and Huang, Fei and Li, Yongbin. API -Bank: A Comprehensive Benchmark for Tool-Augmented LLM s. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.187
-
[19]
2025 , eprint=
ToRL: Scaling Tool-Integrated RL , author=. 2025 , eprint=
2025
-
[20]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[21]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[22]
Cheng Qian and Emre Can Acikgoz and Qi He and Hongru WANG and Xiusi Chen and Dilek Hakkani-T. Tool. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[23]
2025 , eprint=
Group Sequence Policy Optimization , author=. 2025 , eprint=
2025
-
[24]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[25]
AgentSquare: Automatic
Yu Shang and Yu Li and Keyu Zhao and Likai Ma and Jiahe Liu and Fengli Xu and Yong Li , booktitle=. AgentSquare: Automatic. 2025 , url=
2025
-
[26]
2025 , eprint=
Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search , author=. 2025 , eprint=
2025
-
[27]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Reflexion: language agents with verbal reinforcement learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[28]
Agentic Reasoning and Tool Integration for
Joykirat Singh and Yash Pandya and Pranav Vajreshwari and Raghav Magazine and Akshay Nambi , booktitle=. Agentic Reasoning and Tool Integration for. 2025 , url=
2025
-
[29]
2026 , eprint=
EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis , author=. 2026 , eprint=
2026
-
[30]
2023 , eprint=
RestGPT: Connecting Large Language Models with Real-World RESTful APIs , author=. 2023 , eprint=
2023
-
[31]
Plan-and-solve prompting: Improving zero-shot Chain-of-Thought reasoning by Large Lan- guage Models
Wang, Lei and Xu, Wanyu and Lan, Yihuai and Hu, Zhiqiang and Lan, Yunshi and Lee, Roy Ka-Wei and Lim, Ee-Peng. Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.147
-
[32]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[33]
AutoGen: Enabling Next-Gen
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Beibin Li and Erkang Zhu and Li Jiang and Xiaoyun Zhang and Shaokun Zhang and Jiale Liu and Ahmed Hassan Awadallah and Ryen W White and Doug Burger and Chi Wang , booktitle=. AutoGen: Enabling Next-Gen. 2024 , url=
2024
-
[34]
2026 , eprint=
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[35]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[36]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[37]
T ool H op: A Query-Driven Benchmark for Evaluating Large Language Models in Multi-Hop Tool Use
Ye, Junjie and Du, Zhengyin and Yao, Xuesong and Lin, Weijian and Xu, Yufei and Chen, Zehui and Wang, Zaiyuan and Zhu, Sining and Xi, Zhiheng and Yuan, Siyu and Gui, Tao and Zhang, Qi and Huang, Xuanjing and Chen, Jiecao. T ool H op: A Query-Driven Benchmark for Evaluating Large Language Models in Multi-Hop Tool Use. Proceedings of the 63rd Annual Meeting...
-
[38]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , url =
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and liu, juncai and Liu, LingJun and Liu, Xin and Lin, Haibin and Lin, Zhiqi and Ma, Bole and Sheng, Guangming and Tong, Yuxuan and Zhang, Chi and Zhang, Mofan and Zhang, Ru and Zhang, Wang and Zhu, Hang and Zhu, Ji...
-
[39]
Forty-second International Conference on Machine Learning , year=
Multi-agent Architecture Search via Agentic Supernet , author=. Forty-second International Conference on Machine Learning , year=
-
[40]
2025 , eprint=
MemEvolve: Meta-Evolution of Agent Memory Systems , author=. 2025 , eprint=
2025
-
[41]
2025 , url=
Jiayi Zhang and Jinyu Xiang and Zhaoyang Yu and Fengwei Teng and Xiong-Hui Chen and Jiaqi Chen and Mingchen Zhuge and Xin Cheng and Sirui Hong and Jinlin Wang and Bingnan Zheng and Bang Liu and Yuyu Luo and Chenglin Wu , booktitle=. 2025 , url=
2025
-
[42]
2025 , eprint=
Absolute Zero: Reinforced Self-play Reasoning with Zero Data , author=. 2025 , eprint=
2025
-
[43]
2025 , eprint=
MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming , author=. 2025 , eprint=
2025
-
[44]
2023 , eprint=
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author=. 2023 , eprint=
2023
-
[45]
2025 , eprint=
Planner-R1: Reward Shaping Enables Efficient Agentic RL with Smaller LLMs , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.