Token Predictors Are Not Planners: Building Physically Grounded Causal Reasoners
Pith reviewed 2026-06-28 14:17 UTC · model grok-4.3
The pith
Training on a million causal reasoning traces lets vision-language models estimate next physical states more accurately than language pattern matching allows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
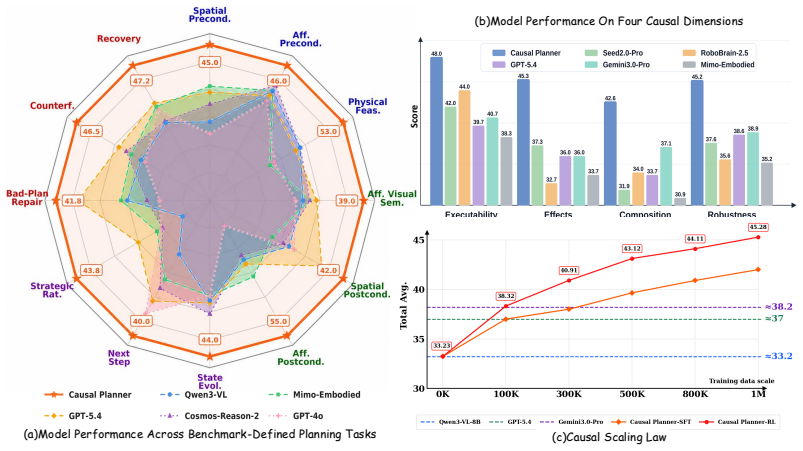
Current leading models reach at most 38.18 on Causal-Plan-Bench because they remain token predictors; the authors' training recipe applied to Qwen3-VL-8B internalizes physical logic through explicit causal traces, yielding stronger next-state estimation both inside and outside the training distribution while exhibiting a clear Causal Scaling Law.
What carries the argument
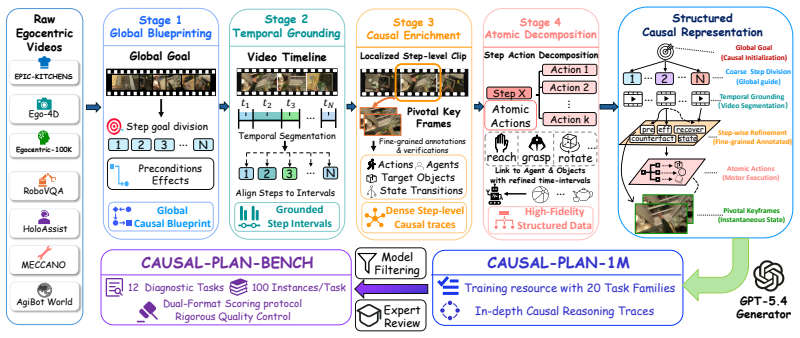
The four-stage annotation pipeline that produces one million explicit causal reasoning traces from egocentric videos, enabling the model to learn physically grounded next-state transitions instead of statistical sequences.
If this is right
- Models achieve higher next-state estimation accuracy when trained on explicit causal traces rather than standard data.
- Performance on the new benchmark and on existing embodied planning tasks both improve after causal training.
- Accuracy continues to rise as the volume of causal training data increases up to one million instances.
- The same training approach produces cross-benchmark generalization beyond the original data distribution.
Where Pith is reading between the lines
- The distinction between token prediction and causal reasoning could be applied to other planning domains where language statistics diverge from real dynamics.
- The four causal dimensions in the benchmark could serve as a template for constructing diagnostic tests in non-visual modalities.
- Real-world robot deployment would provide a direct test of whether the learned causal traces transfer to physical actions outside simulation.
Load-bearing premise
The multi-stage verification and four-stage annotation pipeline create benchmark items and traces that measure physically grounded causal reasoning rather than language patterns or annotation artifacts.
What would settle it
If a model trained on the full Causal-Plan-1M corpus shows no accuracy gain over the base model when tested on new physical scenarios where common language associations contradict actual outcomes, the claim that the model internalized physical logic would be falsified.
Figures












read the original abstract
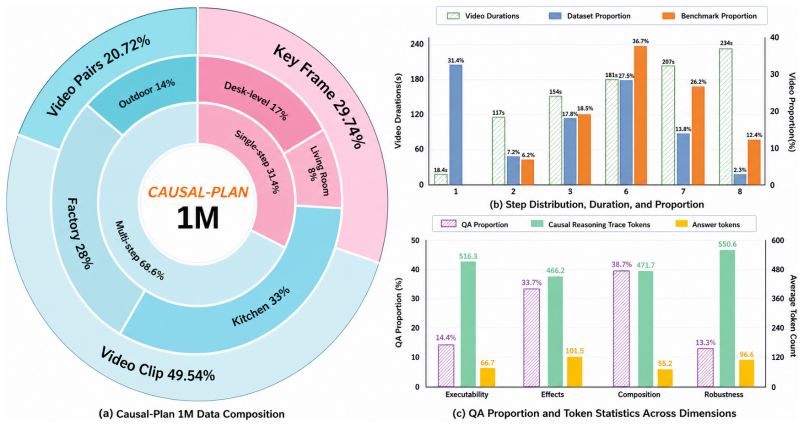
Current benchmarks for embodied vision-language planning often favor linguistic next-token prediction over physically grounded next-state reasoning. This rewards models that mimic statistical language priors rather than track causal dependencies, reducing physical planning to shallow sequence modeling. We argue that reliable physical autonomy requires a shift from linguistically grounded token prediction toward physically grounded causal reasoning. To this end, we introduce Causal-Plan-Bench, a high-fidelity diagnostic suite curated through multi-stage verification to evaluate embodied planning across four causal dimensions. We also construct Causal-Plan-1M, a million-scale corpus of explicit reasoning traces produced by a four-stage annotation pipeline over egocentric videos. Extensive evaluation shows that leading models still struggle to demonstrate genuine physical agency, with Gemini 3 Pro reaching only 38.18 on our benchmark. In contrast, our training recipe enables Causal Planner, built on Qwen3-VL-8B, to internalize physical logic for more accurate next-state estimation. The model achieves strong in-domain performance and cross-benchmark generalization, and reveals a Causal Scaling Law: scaling causal training data to one million instances yields a 36.3% relative gain, from 33.22 to 45.28. Overall, our work provides a concrete step toward turning agents from superficial token predictors into physically grounded causal reasoners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that current embodied VLMs favor linguistic next-token prediction over physically grounded causal reasoning for planning. It introduces Causal-Plan-Bench, a diagnostic suite with multi-stage verification across four causal dimensions, and Causal-Plan-1M, a million-scale corpus of explicit reasoning traces generated via a four-stage annotation pipeline over egocentric videos. Leading models (e.g., Gemini 3 Pro at 38.18) struggle on the benchmark, while the authors' Causal Planner (Qwen3-VL-8B trained on their data) shows strong in-domain performance, cross-benchmark generalization, and a Causal Scaling Law with a 36.3% relative gain (33.22 to 45.28) when scaling causal training data to 1M instances.
Significance. If the benchmark and traces genuinely isolate physical causal dependencies, the work provides a useful diagnostic and training resource for shifting VLMs toward physical agency in embodied settings, with the scaling observation offering a potential empirical guideline. The construction of a large annotated corpus and demonstration of cross-benchmark gains are concrete strengths. However, the self-generated nature of both benchmark and training data, absent external validation or controls for annotation artifacts, limits the result's immediate generalizability and impact on the field.
major comments (2)
- [Abstract / benchmark construction] Abstract and benchmark construction section: the multi-stage verification and four-stage annotation pipeline are presented as isolating physically grounded causal reasoning across four dimensions, yet no controls (e.g., inter-annotator reliability metrics for causality judgments, ablations replacing causal labels with statistically matched non-causal ones, or explicit language-prior baselines) are described to rule out statistical regularities or annotation artifacts. This directly underpins the claim that performance gains reflect internalized physical logic.
- [Results / scaling experiments] Results section on scaling and evaluation: the Causal Scaling Law and 36.3% relative gain (33.22 to 45.28) are derived exclusively from training/testing on the authors' Causal-Plan-1M and Causal-Plan-Bench without reported error bars, baseline ablations against non-causal data, or validation on independent external physical-reasoning benchmarks. This makes the generalization claim load-bearing and vulnerable to circularity.
minor comments (2)
- [Abstract] The abstract states 'four causal dimensions' without enumerating them; a brief explicit list in the introduction or benchmark section would improve clarity.
- [Evaluation] No mention of statistical significance testing or variance across runs for the reported performance numbers; adding this would strengthen the empirical claims without altering the core argument.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on benchmark validity and experimental controls. We address each major point below with the strongest honest response supported by the manuscript, indicating revisions where the concerns are valid and addressable.
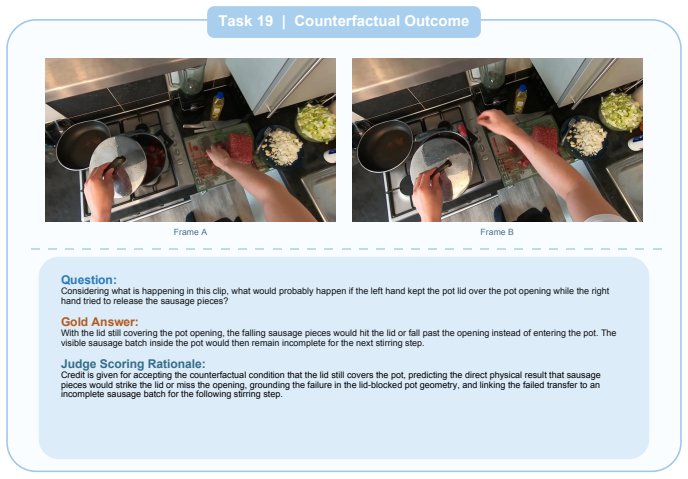
read point-by-point responses
-
Referee: [Abstract / benchmark construction] Abstract and benchmark construction section: the multi-stage verification and four-stage annotation pipeline are presented as isolating physically grounded causal reasoning across four causal dimensions, yet no controls (e.g., inter-annotator reliability metrics for causality judgments, ablations replacing causal labels with statistically matched non-causal ones, or explicit language-prior baselines) are described to rule out statistical regularities or annotation artifacts. This directly underpins the claim that performance gains reflect internalized physical logic.
Authors: The four-stage annotation pipeline and multi-stage verification were designed to enforce focus on physical causal dependencies through sequential human checks rather than surface linguistic patterns. We acknowledge that the manuscript does not report inter-annotator reliability metrics or the specific ablations suggested. We will revise the benchmark construction section to add inter-annotator agreement scores for causality judgments and include an ablation replacing causal traces with statistically matched non-causal sequences. We will also add a language-prior baseline using next-token prediction without explicit causal structure to isolate the contribution of causal reasoning. revision: yes
-
Referee: [Results / scaling experiments] Results section on scaling and evaluation: the Causal Scaling Law and 36.3% relative gain (33.22 to 45.28) are derived exclusively from training/testing on the authors' Causal-Plan-1M and Causal-Plan-Bench without reported error bars, baseline ablations against non-causal data, or validation on independent external physical-reasoning benchmarks. This makes the generalization claim load-bearing and vulnerable to circularity.
Authors: The scaling law is shown via controlled increases in causal training data, and the manuscript reports cross-benchmark generalization on other embodied planning tasks. We agree that error bars and non-causal ablations are missing and would strengthen the results. In revision we will add error bars to the scaling experiments and include an ablation training on non-causal traces of matched scale. The cross-benchmark results provide evidence of generalization beyond the training distribution, but we will revise the discussion to more explicitly address the scope and any remaining risks of circularity. revision: partial
Circularity Check
No significant circularity; empirical results on constructed dataset
full rationale
The paper constructs Causal-Plan-1M and Causal-Plan-Bench via a four-stage annotation pipeline over videos, trains Causal Planner on the data, and reports measured accuracies (e.g., scaling from 33.22 to 45.28) plus cross-benchmark generalization. No equations, self-citations, or derivations reduce the reported gains or 'Causal Scaling Law' to inputs by construction. This matches standard empirical ML evaluation on author-curated resources and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- Causal Scaling Law coefficients
axioms (1)
- domain assumption Multi-stage verification ensures the benchmark measures genuine physical causal reasoning
Reference graph
Works this paper leans on
-
[1]
Egocentric-100K, 2025
Build AI. Egocentric-100K, 2025. URLhttps://huggingface.co/datasets/builddotai/ Egocentric-100K. Hugging Face Datasets
2025
-
[2]
Egocentric-10K, 2025
Build AI. Egocentric-10K, 2025. URLhttps://huggingface.co/datasets/builddotai/ Egocentric-10K. Hugging Face Datasets
2025
-
[3]
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Alisson Azzolini, Junjie Bai, Hannah Brandon, Jiaxin Cao, Prithvijit Chattopadhyay, Huayu Chen, Jinju Chu, Yin Cui, Jenna Diamond, Yifan Ding, et al. Cosmos-Reason1: From physical common sense to embodied reasoning.arXiv preprint arXiv:2503.15558, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL Technical Report, 2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. AgiBot World Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Seed2.0 Model Card.https://lf3-static.bytednsdoc.com/obj/ eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model%20Card.pdf, 2026
ByteDance Seed Team. Seed2.0 Model Card.https://lf3-static.bytednsdoc.com/obj/ eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model%20Card.pdf, 2026
2026
-
[8]
IJCV130(1), 33–55 (2022).https://doi.org/10.1007/s11263-021-01531-2
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Evangelos Kazakos, Jian Ma, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Rescaling egocentric vision: Collection, pipeline and challenges for EPIC-KITCHENS-100.International Journal of Computer Vi- sion, 130(1):33–55, 2022. doi: 10.1007/s11263-021-01531-2. URLhtt...
-
[9]
Rynnbrain: Open embodied foundation models
Ronghao Dang, Jiayan Guo, Bohan Hou, Sicong Leng, Kehan Li, Xin Li, Jiangpin Liu, Yunxuan Mao, Zhikai Wang, Yuqian Yuan, et al. RynnBrain: Open embodied foundation models.arXiv preprint arXiv:2602.14979, 2026
-
[10]
Gemini 2.5 Pro Model Card.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-2-5-Pro-Model-Card.pdf, 2025
Google DeepMind. Gemini 2.5 Pro Model Card.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-2-5-Pro-Model-Card.pdf, 2025
2025
-
[11]
Gemini 3 Pro Model Card.https://deepmind.google/models/model-cards/ gemini-3-pro/, 2025
Google DeepMind. Gemini 3 Pro Model Card.https://deepmind.google/models/model-cards/ gemini-3-pro/, 2025
2025
-
[12]
Gemini Robotics-ER 1.6 Model Card.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-Robotics-ER-1-6-Model-Card.pdf, 2026
Google DeepMind. Gemini Robotics-ER 1.6 Model Card.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-Robotics-ER-1-6-Model-Card.pdf, 2026
2026
-
[13]
Ego4D: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4D: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 18995–19012, 2022
2022
-
[14]
Ego-Exo4D: Under- standing skilled human activity from first- and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-Exo4D: Under- standing skilled human activity from first- and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages ...
2024
-
[15]
MiMo-Embodied: X-Embodied Foundation Model Technical Report
Xiaoshuai Hao, Lei Zhou, Zhijian Huang, Zhiwen Hou, Yingbo Tang, Lingfeng Zhang, Guang Li, Zheng Lu, Shuhuai Ren, Xianhui Meng, et al. MiMo-Embodied: X-Embodied Foundation Model Technical Report.arXiv preprint arXiv:2511.16518, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. GPT-4o System Card.arXiv preprint arXiv:2410.21276, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
HOI4D: A 4D egocentric dataset for category-level human-object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. HOI4D: A 4D egocentric dataset for category-level human-object interaction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21013– 21022, 2022
2022
-
[18]
Cosmos-Reason2-8B.https://huggingface.co/nvidia/Cosmos-Reason2-8B, 2026
NVIDIA. Cosmos-Reason2-8B.https://huggingface.co/nvidia/Cosmos-Reason2-8B, 2026. Model card
2026
-
[19]
GPT-5.4 Thinking System Card.https://openai.com/index/ gpt-5-4-thinking-system-card/, 2026
OpenAI. GPT-5.4 Thinking System Card.https://openai.com/index/ gpt-5-4-thinking-system-card/, 2026
2026
-
[20]
Lu Qiu, Yi Chen, Yuying Ge, Yixiao Ge, Ying Shan, and Xihui Liu. EgoPlan-Bench2: A benchmark for multimodal large language model planning in real-world scenarios.International Journal of Com- puter Vision, 134(5):222, 2026. doi: 10.1007/s11263-026-02826-y. URLhttps://doi.org/10.1007/ s11263-026-02826-y
-
[21]
Qwen3.5: Towards Native Multimodal Agents, February 2026
Qwen Team. Qwen3.5: Towards Native Multimodal Agents, February 2026. URLhttps://qwen.ai/ blog?id=qwen3.5
2026
-
[22]
Francesco Ragusa, Antonino Furnari, and Giovanni Maria Farinella. MECCANO: A multimodal ego- centric dataset for humans behavior understanding in the industrial-like domain.Computer Vision and Image Understanding, 235:103764, 2023. doi: 10.1016/j.cviu.2023.103764. URLhttps://doi.org/ 10.1016/j.cviu.2023.103764
-
[23]
Assembly101: A large-scale multi-view video dataset for understanding procedural activities
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and An- gela Yao. Assembly101: A large-scale multi-view video dataset for understanding procedural activities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21096– 21106, 2022
2022
-
[24]
RoboVQA: Multimodal long-horizon reasoning for robotics
Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, et al. RoboVQA: Multimodal long-horizon reasoning for robotics. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 645–652. IEEE, 2024
2024
-
[25]
ALFRED: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. ALFRED: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10740–10749, 2020
2020
-
[26]
Robobrain 2.5: Depth in sight, time in mind.arXiv preprint arXiv:2601.14352,
Huajie Tan, Enshen Zhou, Zhiyu Li, Yijie Xu, Yuheng Ji, Xiansheng Chen, Cheng Chi, Pengwei Wang, Huizhu Jia, Yulong Ao, et al. RoboBrain 2.5: Depth in Sight, Time in Mind.arXiv preprint arXiv:2601.14352, 2026
-
[27]
RoboBrain 2.0 technical report.arXiv preprint arXiv:2507.02029, 2025
BAAI RoboBrain Team, Mingyu Cao, Huajie Tan, Yuheng Ji, Xiansheng Chen, Minglan Lin, Zhiyu Li, Zhou Cao, Pengwei Wang, Enshen Zhou, et al. RoboBrain 2.0 Technical Report.arXiv preprint arXiv:2507.02029, 2025
-
[28]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi K2.5: Visual Agentic Intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing open-source multimodal models in versatil- ity, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
HoloAssist: An egocentric human interaction dataset for interactive AI assistants in the real world
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bugra Tekin, Felipe Vieira Frujeri, et al. HoloAssist: An egocentric human interaction dataset for interactive AI assistants in the real world. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20270–20281, 2023
2023
-
[31]
video_id
Lingfeng Zhang, Yuening Wang, Hongjian Gu, Atia Hamidizadeh, Zhanguang Zhang, Yuecheng Liu, Yutong Wang, David Gamaliel Arcos Bravo, Junyi Dong, Shunbo Zhou, et al. ET-Plan-Bench: Em- bodied task-level planning benchmark towards spatial-temporal cognition with foundation models. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (...
2025
-
[32]
Open the tall wooden door at the side of the kitchen and reach toward a stored shelf container while the eggplant remains in the frying pan on the burner
"Open the tall wooden door at the side of the kitchen and reach toward a stored shelf container while the eggplant remains in the frying pan on the burner."
-
[34]
Pour cooking oil into the frying pan holding eggplant pieces, retrieve the spatula from the utensil drawer, and stir the eggplant pieces across the frying pan surface
"Pour cooking oil into the frying pan holding eggplant pieces, retrieve the spatula from the utensil drawer, and stir the eggplant pieces across the frying pan surface." Find the problematic step and fix the plan. Gold Answer: The flaw is in step 1, which contains a step that skips a required precondition. Step 1 assumes conditions that earlier steps have...
-
[35]
"Place the frying pan from the lower cabinet onto the stovetop and transfer the chopped eggplant from the cutting board into the frying pan with the knife before returning the emptied cutting board to the counter."
-
[36]
Discard the remaining eggplant scraps into the bin, reseal the bowl holding onion pieces, place the bowl into the refrigerator, and turn back toward the stove area
"Discard the remaining eggplant scraps into the bin, reseal the bowl holding onion pieces, place the bowl into the refrigerator, and turn back toward the stove area."
-
[37]
Pour cooking oil into the frying pan holding eggplant pieces, retrieve the spatula from the utensil drawer, and stir the eggplant pieces across the frying pan surface
"Pour cooking oil into the frying pan holding eggplant pieces, retrieve the spatula from the utensil drawer, and stir the eggplant pieces across the frying pan surface."
-
[38]
Open the tall wooden door at the side of the kitchen and reach toward a stored shelf container while the eggplant remains in the frying pan on the burner
"Open the tall wooden door at the side of the kitchen and reach toward a stored shelf container while the eggplant remains in the frying pan on the burner." Judge Scoring Rationale: Credit is given for locating the flaw in step 1, identifying it as a missing-precondition error, explaining that pan placement and eggplant transfer have not yet been establis...
-
[39]
Spatial Relations (Geometric/Topological): Define the visible positional relationships BETWEEN objects. − Preconditions/Effects: Define contact (touching, resting−on), relative position (inside, on top of, beside, above, below) , containment, support relations, orientation of one object relative to another. − Focus: WHERE are objects physically placed rel...
-
[40]
Affordances (Functional/Intrinsic States): Define the object’s OWN intrinsic state, properties, and physical mechanisms. − Preconditions/Effects: Define the object’s mechanical state (open/closed, sealed/unsealed, locked/unlocked, assembled/disassembled), material properties (elastic, spreadable, dry/wet surface), functional readiness based on intrinsic p...
-
[41]
− INCLUDE: objects directly manipulated, tools used, surfaces providing direct support/contact for the action, containers /receptacles involved, body parts executing the action
Action−Relevance Filter (applies to ALL annotation fields): − Every statement in preconditions, effects, rationale, and descriptions MUST be strictly relevant to the physical operation being performed. − INCLUDE: objects directly manipulated, tools used, surfaces providing direct support/contact for the action, containers /receptacles involved, body parts...
-
[42]
SPATIAL: Where are the key objects relative to each other at the start and/or end of the action?
-
[43]
MOTION: What physical motion, force, or manipulation is applied (direction, trajectory, mechanism)?
-
[44]
SELF−CHECK: before finalizing any caption/description, verify all three components are present
STATE CHANGE: What observable property transitions from stateA to state B (contact gained/lost, open/closed, grasped/released, supported/unsupported, inside/outside, assembled/separated)? For TRANSITION actions (reach, carry, walk) where no object state changes, describe the SPATIAL PROGRESSION and what CONTACT or PROXIMITY state changes (e.g., ”hand tran...
-
[45]
PRIMARY: State change of the patient (the acted−upon object) — e.g., ”package seal is broken (contents now extractable)”, ”onion outer layer is separated from flesh”
-
[46]
SECONDARY: State change of the tool/agent contact object — e.g., ”knife blade retains cutting capability”
-
[47]
Every ‘causaleffect on affordance‘ list MUST begin with at least one primary effect
TERTIARY (only if space permits): Environment/workspace side effects — e.g., ”cutting board has less free space” Do NOT write only tertiary effects. Every ‘causaleffect on affordance‘ list MUST begin with at least one primary effect. Examples (contrast; follow the GOOD style): SPATIAL examples: − Bad: ”Ingredients are accessible on the counter.” Good: [ ”...
-
[48]
A draft step list extracted from a plan (read−only; do NOT edit it). High−level goal (context):{high level goal} Draft steps (read−only): {draft plan outline} 62 Note on indices: − Some frames may look identical due to uniform sampling/padding; avoid choosing a segment whose boundaries fall on visually identical frames with no time progress. Task: For EAC...
-
[49]
The boundary is AFTER the release is complete but BEFORE any reaching toward the next object begins
RELEASE−REACH transition: The hand releases the current object (fingers open, no contact), and then begins reaching toward a new object. The boundary is AFTER the release is complete but BEFORE any reaching toward the next object begins
-
[50]
The boundary is AFTER the object is stationary
PLACEMENT−WITHDRAWAL transition: An object is placed in its final position (no longer moving), and the hand begins withdrawing. The boundary is AFTER the object is stationary
-
[51]
The boundary is AFTER the first tool is released
TOOL CHANGE: A tool is put down and a different tool is picked up. The boundary is AFTER the first tool is released
-
[52]
The boundary is at the moment of shift
WORKSPACE SHIFT: The agent’s focus/body orientation shifts from one area to another. The boundary is at the moment of shift
-
[53]
The boundary is at the neutral pose
POSE RESET: The agent returns to a neutral stance between actions. The boundary is at the neutral pose. STEP DEPENDENCY (quick judgment alongside boundaries): For each step except Step 1, set ‘independence‘ to ‘”yes”‘ if the previous step physically enables this one (e.g., an object moved/opened/created that this step needs), or ‘”no”‘ otherwise. Do NOT i...
-
[54]
A draft step plan (read−only)
-
[55]
A PROPOSED set of step boundaries that you must VERIFY and CORRECT if needed. High−level goal:{high level goal} Draft steps: {draft plan outline} Proposed boundaries (to verify/correct): {current boundaries json} Task: For EACH boundary between consecutive steps, examine the frames AT and AROUND the boundary and determine whether the boundary is correctly...
-
[56]
Scan all frames quickly to understand the step progression and physical state changes
-
[57]
Pick exactly 2 DISTINCT frames that are the two most causally important and visually anchorable key moments within this step (NOT limited to initiation/completion)
-
[58]
Treat each keyframe as a conjunction of constraints: the selected ‘frameindex‘ MUST be consistent with its own ‘actionstate change description‘, ‘causalchain‘ (frame−level), and ‘interaction‘ simultaneously (avoid partial matches)
-
[59]
If a mismatch remains, FIX IT NOW by revising the text and/or selecting a different ‘frameindex‘ (do NOT defer mismatches to a later pass)
Do an explicit self−check BEFORE you finalize: for each selected ‘frameindex‘, every factual claim in the corresponding ‘criticalframes[*]‘ object MUST be visually grounded in that exact image (preconditions, contacts, spatial relations, object identities). If a mismatch remains, FIX IT NOW by revising the text and/or selecting a different ‘frameindex‘ (d...
-
[60]
Ensure the 2 selected frames are in chronological order (‘frameindex‘ strictly increases). If multiple frames match similarly well, break ties by **key−moment fidelity** (NOT by being early/late in the clip): − Prefer the frame where the described micro−action / state−change is most visually evident and discriminative. − Avoid idle/paused frames if there ...
-
[61]
− The gap between the two frame index values MUST be at least 15%% of{num frames}(i.e., frame index 2 − frame index 1>={min keyframe gap})
DISTRIBUTION CONSTRAINT (HARD RULE — ZERO TOLERANCE): − The 2 critical frames MUST NOT both fall in the last 25%% of the step clip (i.e., both frame index>{num frames} * 0.75 is REJECTED). − The gap between the two frame index values MUST be at least 15%% of{num frames}(i.e., frame index 2 − frame index 1>={min keyframe gap}). If both frames are clustered...
-
[62]
A refined ‘highlevel goal‘ for the entire video
-
[63]
A ‘detailindependence‘ explanation for each step (except Step 1). −−− PART A: Refine high level goal −−− Refine the overall ‘highlevel goal‘ into ONE comprehensive English sentence describing the overall goal and intended final outcome of the ENTIRE video. This refinement happens AFTER all step−level annotations are generated; it MUST be consistent with t...
-
[64]
Scan ALL frames first to understand the full motion trajectory and state changes within this step. 74
-
[65]
Identify the critical state−change boundaries: moments where the agent−patient contact changes (contact established / broken), motion direction reverses, a new object is engaged, or a distinct sub−goal is achieved
-
[66]
If the two critical frames suggest a state change between frame index A and B, place an atomic action boundary near that transition
Use the reference step annotation’s ‘criticalframes‘ (if present) as ANCHOR POINTS: boundaries of atomic actions should generally align with or bracket these key moments. If the two critical frames suggest a state change between frame index A and B, place an atomic action boundary near that transition
-
[67]
For each segment between boundaries, assign exactly one atomic action with the correct verb and patient
-
[68]
g., contact just established, object just lifted, hand just released)
Perform an explicit self−check: for every boundary frame, verify that the frame visually shows the claimed transition (e. g., contact just established, object just lifted, hand just released). If a mismatch exists, adjust the boundary by±1 frame. For each atomic action, predict: − ‘atomicaction id‘: sequential 1−based integer − ‘startframe index‘: 1−based...
-
[69]
Separate AAs are only justified by a VISIBLE PAUSE, a CHANGE OF INTENT, or a SWITCH TO A DIFFERENT OBJECT
KINEMATIC MERGE SCAN: If consecutive AAs form a kinematic chain targeting the SAME object with no visible pause between them (e.g., carry→lower→place→release; reach→grasp→lift), merge them into ONE action . Separate AAs are only justified by a VISIBLE PAUSE, a CHANGE OF INTENT, or a SWITCH TO A DIFFERENT OBJECT
-
[70]
GOAL−RELEVANCE GATE: For each AA, ask: ”Does this action directly serve THIS step’s goal?” If NO (e.g., tidying an unrelated object, adjusting clothing, straightening a towel in a pouring step), remove it and absorb its frames into the nearest goal−relevant AA
-
[71]
IDLE SCAN: If any AA describes static resting, waiting, or hands−off idle (no goal−directed motion), remove it and extend the neighboring action’s boundary to cover those frames
-
[72]
REPETITION SCAN: If two or more consecutive AAs share the same patient and describe the same operation (look for ”continue”, ”repeat”, ”more”, ”additional”, ”resume”, ”further”), merge them into ONE
-
[73]
If an early AA requires a precondition not yet met (using an object before obtaining it, tearing material before unwrapping), those early AAs are spillover — remove and absorb
CAUSAL ORDER SCAN: Read the AAs as a story. If an early AA requires a precondition not yet met (using an object before obtaining it, tearing material before unwrapping), those early AAs are spillover — remove and absorb. GROUNDING REQUIREMENTS: − All text fields MUST be grounded in visual evidence from the frames. Do NOT hallucinate objects, contacts, or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.