Does Compression Preserve Uncertainty? A Unified Benchmark for Quantized and Sparse LLMs via Conformal Prediction
Pith reviewed 2026-06-28 15:03 UTC · model grok-4.3
The pith
Compression frequently decouples accuracy from uncertainty in large language models
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
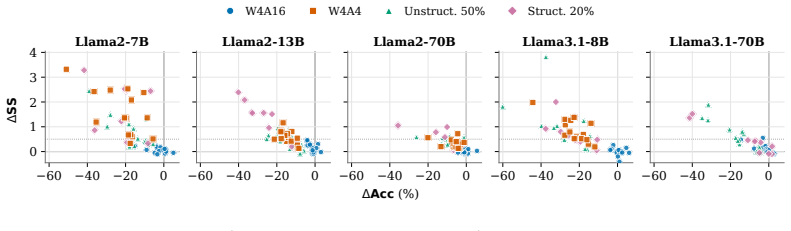
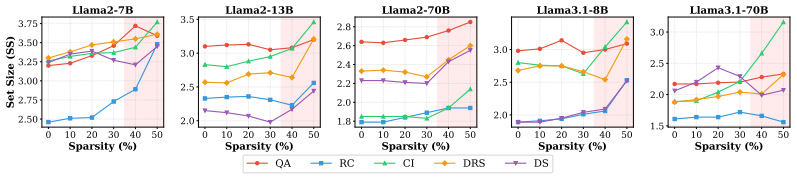
Using conformal prediction on compressed LLMs, the study finds that quantization and pruning frequently decouple accuracy from uncertainty, that larger models absorb compression-induced uncertainty far more effectively than smaller ones, and that uncertainty inflation is often threshold-like rather than gradual.
What carries the argument
Conformal prediction, which supplies a distribution-free measure of uncertainty for the outputs of quantized and pruned LLMs.
If this is right
- Accuracy preservation does not guarantee preservation of uncertainty under compression.
- Larger models are more resilient to compression effects on uncertainty than smaller models.
- Uncertainty inflation tends to occur abruptly rather than gradually as compression increases.
- Accuracy-only evaluation is insufficient for assessing deployment readiness of compressed LLMs.
Where Pith is reading between the lines
- The observed threshold behavior implies that safe compression levels may need to be identified separately for each model size.
- Uncertainty-aware checks could become part of standard compression pipelines beyond the accuracy focus used today.
- The decoupling pattern may appear in other efficiency techniques such as distillation that were not tested here.
Load-bearing premise
Conformal prediction supplies a valid measure of uncertainty that remains applicable to the outputs of quantized and pruned LLMs.
What would settle it
Finding that uncertainty measures remain aligned with accuracy across all tested compression levels and model sizes would challenge the decoupling result.
Figures

read the original abstract
Model compression techniques such as quantization and pruning are widely used to reduce the deployment cost of large language models (LLMs), with existing evaluations focusing almost exclusively on accuracy preservation. However, in safety-critical applications, a model's ability to reliably quantify its own uncertainty is equally important. We ask: does compression preserve this ability? To answer this question, we benchmark 12 LLMs under various compression configurations across five NLP tasks, using conformal prediction to provide a rigorous, distribution-free measure of uncertainty. Our experiments reveal that: (I) compression frequently decouples accuracy from uncertainty; (II) larger models absorb compression-induced uncertainty far more effectively than smaller ones; and (III) uncertainty inflation is often threshold-like rather than gradual. These results suggest that accuracy-only evaluation is insufficient for assessing the deployment readiness of compressed LLMs, and that uncertainty-aware benchmarking should be a standard component of model compression pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks 12 LLMs under quantization and pruning on five NLP tasks, using conformal prediction to measure uncertainty. It reports that compression frequently decouples accuracy from uncertainty, larger models absorb compression-induced uncertainty more effectively, and uncertainty inflation tends to be threshold-like rather than gradual, concluding that accuracy-only evaluations are insufficient for assessing compressed LLMs in safety-critical settings.
Significance. If the empirical results hold under detailed scrutiny, the work provides a useful demonstration that uncertainty quantification can degrade independently of accuracy under compression. The model-agnostic nature of conformal prediction strengthens the benchmark approach, and the scale (12 models, 5 tasks) offers a broad view that could encourage uncertainty-aware practices in compression pipelines.
major comments (2)
- [Experimental methodology] Experimental methodology section: the manuscript invokes conformal prediction as a 'rigorous, distribution-free measure' but supplies no description of the nonconformity score, calibration-set construction, or how exchangeability is maintained for the specific NLP tasks and compressed model outputs. This detail is load-bearing for validating claims (I)-(III) on decoupling and threshold behavior.
- [Results] Results section (across the 12 models and 5 tasks): the reported patterns of decoupling and threshold-like inflation are presented without statistical tests, error bars, or sensitivity analysis to data splits. This undermines the strength of the qualifiers 'frequently' and 'often' in the abstract and conclusions.
minor comments (2)
- [Abstract] The abstract and introduction refer to 'various compression configurations' without enumerating the specific bit-widths, sparsity ratios, or methods (e.g., GPTQ vs. AWQ) tested; adding this would improve interpretability of the threshold-like behavior.
- [Figures/Tables] Figure and table captions should explicitly state the number of random seeds or runs used to generate the plotted uncertainty metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional methodological detail and statistical support would strengthen the manuscript. We will revise accordingly to address both major comments.
read point-by-point responses
-
Referee: [Experimental methodology] Experimental methodology section: the manuscript invokes conformal prediction as a 'rigorous, distribution-free measure' but supplies no description of the nonconformity score, calibration-set construction, or how exchangeability is maintained for the specific NLP tasks and compressed model outputs. This detail is load-bearing for validating claims (I)-(III) on decoupling and threshold behavior.
Authors: We agree that the Experimental Methodology section requires explicit implementation details to support the claims. In the revised manuscript we will add a dedicated subsection specifying: the nonconformity score (1 minus the softmax probability assigned to the ground-truth label for the classification tasks used), the calibration-set construction (a fixed 20% random hold-out from each task's training split, kept disjoint from test data), and the exchangeability assumption (standard i.i.d. exchangeability within each task's data distribution, with a brief note on how compression does not alter this assumption for the purpose of coverage guarantees). These additions will directly bolster validation of claims (I)-(III). revision: yes
-
Referee: [Results] Results section (across the 12 models and 5 tasks): the reported patterns of decoupling and threshold-like inflation are presented without statistical tests, error bars, or sensitivity analysis to data splits. This undermines the strength of the qualifiers 'frequently' and 'often' in the abstract and conclusions.
Authors: We accept that the Results section would be strengthened by quantitative support for the reported patterns. In revision we will (i) add error bars derived from 5 independent random seeds for calibration/test splits, (ii) perform sensitivity analysis across three different calibration-set sizes, and (iii) include paired statistical tests (Wilcoxon signed-rank) comparing accuracy versus coverage gap under each compression level. These changes will provide empirical grounding for the qualifiers 'frequently' and 'often'. revision: yes
Circularity Check
No significant circularity identified
full rationale
This is a purely empirical benchmark paper with no derivations, equations, fitted parameters, or load-bearing self-citations. It applies standard conformal prediction (a model-agnostic, distribution-free procedure) to measure uncertainty on compressed LLMs and reports experimental observations across 12 models and five tasks. The central claims (decoupling of accuracy from uncertainty, etc.) are direct outputs of the benchmark results rather than quantities defined by or reduced to the evaluation method itself. No step reduces a prediction or result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conformal prediction provides distribution-free uncertainty quantification valid for the tested LLM outputs
Reference graph
Works this paper leans on
-
[1]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[3]
Hierarchically robust zero-shot vision- language models,
J. Dong, Y . Zhang, H. Zhu, Y .-S. Ong, and P. Koniusz, “Hierarchically robust zero-shot vision- language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 37 642–37 652
2026
-
[4]
Tug-of-war no more: Harmonizing accuracy and robustness in vision-language models via stability-aware task vector merging,
J. Dong, X. Qu, C. Zhang, S. Q. Rong, N. D. Thai, W. Pan, X. Li, T. Liu, P. Koniusz, and Y .-S. Ong, “Tug-of-war no more: Harmonizing accuracy and robustness in vision-language models via stability-aware task vector merging,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
Craft-lora: Content-style personalization via rank-constrained adaptation and training-free fusion,
Y . Li, Y . Cai, and C. Zhang, “Craft-lora: Content-style personalization via rank-constrained adaptation and training-free fusion,”arXiv preprint arXiv:2602.18936, 2026
arXiv 2026
-
[6]
Y . Li, S. Tang, and T. Lan, “Reason in chains, learn in trees: Self-rectification and grafting for multi-turn agent policy optimization,”arXiv preprint arXiv:2604.07165, 2026
Pith/arXiv arXiv 2026
-
[7]
Sage: Accelerating vision-language models via entropy-guided adaptive speculative decoding,
Y . Tong, T. Zhang, Y . Wan, K. Lin, J. Yuan, and C. Hu, “Sage: Accelerating vision-language models via entropy-guided adaptive speculative decoding,”arXiv preprint arXiv:2602.00523, 2026
arXiv 2026
-
[8]
A survey on model compression for large language models,
X. Zhu, J. Li, Y . Liu, C. Ma, and W. Wang, “A survey on model compression for large language models,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 1556–1577, 2024
2024
-
[9]
Optimal brain restoration for joint quantization and sparsification of llms,
H. Guo, Y . Li, and L. Benini, “Optimal brain restoration for joint quantization and sparsification of llms,”arXiv preprint arXiv:2509.11177, 2025
arXiv 2025
-
[10]
Quarot: Outlier-free 4-bit inference in rotated llms,
S. Ashkboos, A. Mohtashami, M. L. Croci, B. Li, P. Cameron, M. Jaggi, D. Alistarh, T. Hoefler, and J. Hensman, “Quarot: Outlier-free 4-bit inference in rotated llms,”Advances in Neural Information Processing Systems, vol. 37, pp. 100 213–100 240, 2024
2024
-
[11]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “Awq: Activation-aware weight quantization for on-device llm compression and acceleration,”Proceedings of machine learning and systems, vol. 6, pp. 87–100, 2024
2024
-
[12]
Smoothquant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 38 087–38 099
2023
-
[13]
Gpt3. int8 (): 8-bit matrix multiplica- tion for transformers at scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “Gpt3. int8 (): 8-bit matrix multiplica- tion for transformers at scale,”Advances in neural information processing systems, vol. 35, pp. 30 318–30 332, 2022
2022
-
[14]
Omniquant: Omnidirectionally calibrated quantization for large language models,
W. Shao, M. Chen, Z. Zhang, P. Xu, L. Zhao, Z. Li, K. Zhang, G. Peng, Y . Qiao, and P. Luo, “Omniquant: Omnidirectionally calibrated quantization for large language models,” inInterna- tional Conference on Learning Representations, vol. 2024, 2024, pp. 45 472–45 496
2024
-
[15]
Slicegpt: Com- press large language models by deleting rows and columns,
S. Ashkboos, M. L. Croci, M. G. d. Nascimento, T. Hoefler, and J. Hensman, “Slicegpt: Com- press large language models by deleting rows and columns,”arXiv preprint arXiv:2401.15024, 2024
arXiv 2024
-
[16]
Sparsegpt: Massive language models can be accurately pruned in one-shot,
E. Frantar and D. Alistarh, “Sparsegpt: Massive language models can be accurately pruned in one-shot,” inInternational conference on machine learning. PMLR, 2023, pp. 10 323–10 337
2023
-
[17]
Fluctuation-based adaptive structured pruning for large language models,
Y . An, X. Zhao, T. Yu, M. Tang, and J. Wang, “Fluctuation-based adaptive structured pruning for large language models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 10, 2024, pp. 10 865–10 873
2024
-
[18]
Language models (mostly) know what they know,
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield- Dodds, N. DasSarma, E. Tran-Johnsonet al., “Language models (mostly) know what they know,”arXiv preprint arXiv:2207.05221, 2022. 10
Pith/arXiv arXiv 2022
-
[19]
A tutorial on conformal prediction
G. Shafer and V . V ovk, “A tutorial on conformal prediction.”Journal of machine learning research, vol. 9, no. 3, 2008
2008
-
[20]
Conformal prediction: A gentle introduction,
A. N. Angelopoulos and S. Bates, “Conformal prediction: A gentle introduction,”Foundations and Trends in Machine Learning, vol. 16, no. 4, pp. 494–591, 2023
2023
-
[21]
Benchmarking llms via uncertainty quantification,
F. Ye, M. Yang, J. Pang, L. Wang, D. F. Wong, E. Yilmaz, S. Shi, and Z. Tu, “Benchmarking llms via uncertainty quantification,”Advances in Neural Information Processing Systems, vol. 37, pp. 15 356–15 385, 2024
2024
-
[22]
Conformal language modeling,
V . Quach, A. Fisch, T. Schuster, A. Yala, J. H. Sohn, T. Jaakkola, and R. Barzilay, “Conformal language modeling,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 11 654–11 681
2024
-
[23]
Large language model validity via enhanced conformal prediction methods,
J. J. Cherian, I. Gibbs, and E. J. Candès, “Large language model validity via enhanced conformal prediction methods,”Advances in Neural Information Processing Systems, vol. 37, pp. 114 812– 114 842, 2024
2024
-
[24]
Quantifying deep learning model uncertainty in conformal predic- tion,
H. Karimi and R. Samavi, “Quantifying deep learning model uncertainty in conformal predic- tion,” inProceedings of the AAAI Symposium Series, vol. 1, no. 1, 2023, pp. 142–148
2023
-
[25]
Robust machine unlearning for quantized neural networks via adaptive gradient reweighting with similar labels,
Y . Tong, Y . Wang, J. Yuan, and C. Hu, “Robust machine unlearning for quantized neural networks via adaptive gradient reweighting with similar labels,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 20 603–20 612
2025
-
[26]
Enhancing quantization-aware training on edge devices via relative entropy coreset selection and cascaded layer correction,
Y . Tong, J. Yuan, and C. Hu, “Enhancing quantization-aware training on edge devices via relative entropy coreset selection and cascaded layer correction,”IEEE Transactions on Mobile Computing, 2026
2026
-
[27]
Forget by uncertainty: Orthogonal entropy unlearning for quantized neural networks,
T. Zhang, Y . Tong, J. Dong, K. Xu, Y . Wang, and J. Yuan, “Forget by uncertainty: Orthogonal entropy unlearning for quantized neural networks,”arXiv preprint arXiv:2602.00567, 2026
Pith/arXiv arXiv 2026
-
[28]
Data-free quantization of vision transformers via easy-to-hard synthesis and activation correction,
Y . Tong, J. Yuan, T. Zhang, J. Liu, and C. Hu, “Data-free quantization of vision transformers via easy-to-hard synthesis and activation correction,”ACM Transactions on Multimedia Computing, Communications and Applications, 2025
2025
-
[29]
A simple and effective pruning approach for large language models,
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter, “A simple and effective pruning approach for large language models,”arXiv preprint arXiv:2306.11695, 2023
Pith/arXiv arXiv 2023
-
[30]
Gptq: Accurate post-training quantization for generative pre-trained transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “Gptq: Accurate post-training quantization for generative pre-trained transformers,”arXiv preprint arXiv:2210.17323, 2022
Pith/arXiv arXiv 2022
-
[31]
Spinquant: Llm quantization with learned rotations,
Z. Liu, C. Zhao, I. Fedorov, B. Soran, D. Choudhary, R. Krishnamoorthi, V . Chandra, Y . Tian, and T. Blankevoort, “Spinquant: Llm quantization with learned rotations,”arXiv preprint arXiv:2405.16406, 2024
Pith/arXiv arXiv 2024
-
[32]
On the convergence of muon and beyond,
D. Chang, Y . Liu, and G. Yuan, “On the convergence of muon and beyond,”arXiv preprint arXiv:2509.15816, 2025
Pith/arXiv arXiv 2025
-
[33]
Muoneq: Balancing before orthogonalization with lightweight equilibration,
D. Chang, Q. Shi, L. Zhang, Y . Li, R. Zhang, Y . Lu, Y . Liu, and G. Yuan, “Muoneq: Balancing before orthogonalization with lightweight equilibration,”arXiv preprint arXiv:2603.28254, 2026
Pith/arXiv arXiv 2026
-
[34]
Mgup: A momentum-gradient alignment update policy for stochastic optimization,
D. Chang and G. Yuan, “Mgup: A momentum-gradient alignment update policy for stochastic optimization,”Advances in Neural Information Processing Systems, vol. 38, pp. 20 488–20 537, 2026
2026
-
[35]
Flatquant: Flatness matters for llm quantization,
Y . Sun, R. Liu, H. Bai, H. Bao, K. Zhao, Y . Li, J. Hu, X. Yu, L. Hou, C. Yuanet al., “Flatquant: Flatness matters for llm quantization,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 57 587–57 613
2025
-
[36]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in neural information processing systems, vol. 36, pp. 10 088–10 115, 2023
2023
-
[37]
Atom: Low-bit quantization for efficient and accurate llm serving,
Y . Zhao, C.-Y . Lin, K. Zhu, Z. Ye, L. Chen, S. Zheng, L. Ceze, A. Krishnamurthy, T. Chen, and B. Kasikci, “Atom: Low-bit quantization for efficient and accurate llm serving,”Proceedings of Machine Learning and Systems, vol. 6, pp. 196–209, 2024
2024
-
[38]
Llm-pruner: On the structural pruning of large language models,
X. Ma, G. Fang, and X. Wang, “Llm-pruner: On the structural pruning of large language models,” Advances in neural information processing systems, vol. 36, pp. 21 702–21 720, 2023. 11
2023
-
[39]
On verbalized confidence scores for llms,
D. Yang, Y .-H. H. Tsai, and M. Yamada, “On verbalized confidence scores for llms,”arXiv preprint arXiv:2412.14737, 2024
Pith/arXiv arXiv 2024
-
[40]
Ensemble based systems in decision making,
R. Polikar, “Ensemble based systems in decision making,”IEEE Circuits and systems magazine, vol. 6, no. 3, pp. 21–45, 2006
2006
-
[41]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[42]
Probabilistic forecasting using monte carlo dropout neural networks,
C. Serpell, I. Araya, C. Valle, and H. Allende, “Probabilistic forecasting using monte carlo dropout neural networks,” inIberoamerican congress on pattern recognition. Springer, 2019, pp. 387–397
2019
-
[43]
Dropout as a bayesian approximation: Representing model uncer- tainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncer- tainty in deep learning,” ininternational conference on machine learning. PMLR, 2016, pp. 1050–1059
2016
-
[44]
Ares: Multimodal adaptive reasoning via difficulty-aware token-level entropy shaping,
S. Chen, Y . Guo, Y . Ye, S. Huang, W. Hu, H. Li, M. Zhang, J. Chen, S. Guo, and N. Peng, “Ares: Multimodal adaptive reasoning via difficulty-aware token-level entropy shaping,”arXiv preprint arXiv:2510.08457, 2025
arXiv 2025
-
[45]
Evidential deep learning to quantify classification uncertainty,
M. Sensoy, L. Kaplan, and M. Kandemir, “Evidential deep learning to quantify classification uncertainty,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[46]
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,”arXiv preprint arXiv:2302.09664, 2023
Pith/arXiv arXiv 2023
-
[47]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inInternational conference on machine learning. PMLR, 2017, pp. 1321–1330
2017
-
[48]
Revisiting the calibration of modern neural networks,
M. Minderer, J. Djolonga, R. Romijnders, F. Hubis, X. Zhai, N. Houlsby, D. Tran, and M. Lu- cic, “Revisiting the calibration of modern neural networks,”Advances in neural information processing systems, vol. 34, pp. 15 682–15 694, 2021
2021
-
[49]
Copu: Conformal prediction for uncertainty quantification in natural language generation,
S. Wang, Y . Jiang, Y . Tang, L. Cheng, and H. Chen, “Copu: Conformal prediction for uncertainty quantification in natural language generation,”arXiv preprint arXiv:2502.12601, 2025
arXiv 2025
-
[50]
Conformal prediction with large language models for multi-choice question answering,
B. Kumar, C. Lu, G. Gupta, A. Palepu, D. Bellamy, R. Raskar, and A. Beam, “Conformal prediction with large language models for multi-choice question answering,”arXiv preprint arXiv:2305.18404, 2023
arXiv 2023
-
[51]
Non-exchangeable conformal language generation with nearest neighbors,
D. Ulmer, C. Zerva, and A. F. Martins, “Non-exchangeable conformal language generation with nearest neighbors,” inFindings of the Association for Computational Linguistics: EACL 2024, 2024, pp. 1909–1929
2024
-
[52]
Uncertainty quantification and confidence calibration in large language models: A survey,
X. Liu, T. Chen, L. Da, C. Chen, Z. Lin, and H. Wei, “Uncertainty quantification and confidence calibration in large language models: A survey,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 6107–6117
2025
-
[53]
Quantized can still be calibrated: A unified framework to calibration in quantized large language models,
M. Zhong, G. Wang, Y .-N. Chuang, and N. Zou, “Quantized can still be calibrated: A unified framework to calibration in quantized large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 30 503–30 517
2025
-
[54]
Least ambiguous set-valued classifiers with bounded error levels,
M. Sadinle, J. Lei, and L. Wasserman, “Least ambiguous set-valued classifiers with bounded error levels,”Journal of the American Statistical Association, vol. 114, no. 525, pp. 223–234, 2019
2019
-
[55]
Classification with valid and adaptive coverage,
Y . Romano, M. Sesia, and E. Candes, “Classification with valid and adaptive coverage,”Ad- vances in neural information processing systems, vol. 33, pp. 3581–3591, 2020
2020
-
[56]
Measuring massive multitask language understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,”arXiv preprint arXiv:2009.03300, 2020
Pith/arXiv arXiv 2009
-
[57]
Cosmos qa: Machine reading compre- hension with contextual commonsense reasoning,
L. Huang, R. Le Bras, C. Bhagavatula, and Y . Choi, “Cosmos qa: Machine reading compre- hension with contextual commonsense reasoning,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 2391–2401. 12
2019
-
[58]
Hellaswag: Can a machine really finish your sentence?
R. Zellers, A. Holtzman, Y . Bisk, A. Farhadi, and Y . Choi, “Hellaswag: Can a machine really finish your sentence?” inProceedings of the 57th annual meeting of the association for computational linguistics, 2019, pp. 4791–4800
2019
-
[59]
Halueval: A large-scale hallucination evaluation benchmark for large language models,
J. Li, X. Cheng, X. Zhao, J.-Y . Nie, and J.-R. Wen, “Halueval: A large-scale hallucination evaluation benchmark for large language models,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 6449–6464
2023
-
[60]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[61]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[62]
Deepseek llm: Scaling open-source language models with longtermism,
X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu et al., “Deepseek llm: Scaling open-source language models with longtermism,”arXiv preprint arXiv:2401.02954, 2024
Pith/arXiv arXiv 2024
-
[63]
The falcon series of open language models,
E. Almazrouei, H. Alobeidli, A. Alshamsi, A. Cappelli, R. Cojocaru, M. Debbah, É. Goffinet, D. Hesslow, J. Launay, Q. Malarticet al., “The falcon series of open language models,”arXiv preprint arXiv:2311.16867, 2023
Pith/arXiv arXiv 2023
-
[64]
Holistic evaluation of language models,
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y . Zhang, D. Narayanan, Y . Wu, A. Kumaret al., “Holistic evaluation of language models,”arXiv preprint arXiv:2211.09110, 2022
Pith/arXiv arXiv 2022
-
[65]
A survey on evaluation of large language models,
Y . Chang, X. Wang, J. Wang, Y . Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y . Wanget al., “A survey on evaluation of large language models,”ACM transactions on intelligent systems and technology, vol. 15, no. 3, pp. 1–45, 2024. 13 A Appendix A.1 Prompting Strategies Following [21], we evaluate all models with prompt-based inference rather than task-s...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.