CultureForest: Understanding and Evaluating Cultural Norm Grounded Reasoning in LLMs
Pith reviewed 2026-06-28 14:33 UTC · model grok-4.3
The pith
LLMs possess substantial cultural knowledge but are limited by ineffective application of that knowledge in reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CultureForest grounds each of its 5,378 examples in a small set of atomic norms so that reasoning performance can be measured separately from knowledge possession. When top models are tested across multiple-choice to open-ended formats, performance falls sharply, regional differences become pronounced, test-time reasoning yields only marginal gains that sometimes increase inequity, shared preference structures appear across regions, and answers turn markedly more conservative under stricter constraints. Disentangling the two stages shows that models hold the relevant cultural knowledge yet remain bottlenecked by its effective use.
What carries the argument
CultureForest benchmark, which attaches each question to a small verifiable set of atomic cultural norms to support attributable evaluation of reasoning.
If this is right
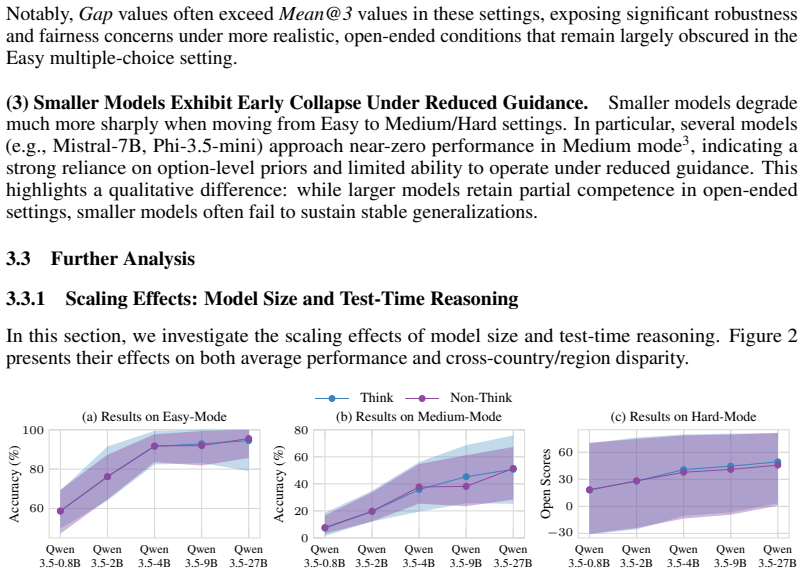
- Model performance degrades substantially when evaluation shifts from multiple-choice to open-ended generation.
- Test-time reasoning produces limited gains and can increase cross-region inequity.
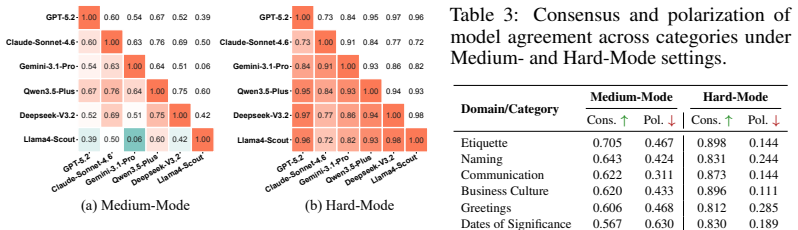
- Models exhibit highly shared regional preference structures regardless of specific inputs.
- Responses become markedly more conservative when cultural constraints are tightened.
- Disentangling shows knowledge acquisition is not the binding limit; effective use is.
Where Pith is reading between the lines
- Future training could target explicit reasoning pathways over cultural norms rather than additional knowledge injection.
- Similar grounding methods could be applied to evaluate reasoning in other rule-based domains such as law or ethics.
- Deployment in multicultural settings may require separate mechanisms to counteract conservative default tendencies.
- A direct test could measure whether supplying atomic norms at inference time closes the observed performance gap.
Load-bearing premise
The chosen atomic norms accurately represent the cultural norms of the 53 countries or regions and permit verifiable attribution without selection bias or oversimplification.
What would settle it
An experiment that first confirms models can state the relevant atomic norms when asked directly and then measures whether performance on the same CultureForest items rises when those norms are supplied explicitly in the prompt.
Figures








read the original abstract
Existing research largely reduces cultural intelligence in LLMs to a knowledge-level problem, overlooking whether models can effectively utilize their acquired knowledge in realistic scenarios. To bridge this gap, we introduce CultureForest, a benchmark for \textit{Cultural Norm Grounded Reasoning}. Each question is grounded in a small set of atomic norms, enabling verifiable and attributable evaluation. CultureForest comprises 5,378 examples across 8 domains and 53 countries/regions, and supports a progressive evaluation from multiple-choice to open-ended generation. Extensive experiments reveal that even top-tier models degrade substantially in open-ended settings, accompanied by pronounced cross-region disparities. Through targeted analysis, we uncover several consistent patterns: (1) test-time reasoning yields limited gains and may exacerbate inequity; (2) models exhibit highly shared regional preference structures; (3) model responses are markedly conservative, especially under stricter cultural constraints; and (4) by disentangling cultural knowledge acquisition from cultural reasoning, we show that while LLMs possess substantial cultural knowledge, their performance is further bottlenecked by its effective use. These findings point to a necessary shift from knowledge-centric evaluation toward measuring knowledge-grounded reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CultureForest, a benchmark of 5,378 examples across 8 domains and 53 countries/regions for evaluating cultural norm grounded reasoning in LLMs. Each question is grounded in a small set of atomic norms to support verifiable attribution. Experiments compare multiple-choice to open-ended generation settings and report substantial degradation in the latter, along with patterns such as limited gains from test-time reasoning, shared regional preferences, conservative responses, and the conclusion that LLMs possess substantial cultural knowledge but are bottlenecked by its effective use in reasoning.
Significance. If the benchmark construction and attribution methodology hold, the work usefully shifts cultural evaluation in LLMs from pure knowledge retrieval toward knowledge-grounded reasoning, with the scale and multi-region coverage providing a concrete resource for future work. The progressive evaluation design (MC to open-ended) and the reported patterns on reasoning limits are potentially impactful for model development.
major comments (3)
- [Abstract and §3] Abstract and §3 (Benchmark Construction): the claim that the benchmark 'enables verifiable and attributable evaluation' rests on the atomic norms accurately representing the 53 regions without selection bias or oversimplification, yet no details are provided on norm selection criteria, expert validation process, inter-rater agreement, or coverage checks across the 8 domains. This directly affects the central disentanglement of knowledge acquisition from reasoning use.
- [§5] §5 (Experiments and Analysis): the headline finding that performance is 'further bottlenecked by its effective use' is supported by degradation in open-ended generation, but without reported statistical controls for potential norm mismatch or regional representation bias in the 5,378 examples, alternative explanations (e.g., norm selection artifacts rather than reasoning deficits) cannot be ruled out.
- [Table 2 / §5] Table 2 or equivalent results table (cross-region disparities): the reported patterns of inequity and conservative responses are load-bearing for the shift from knowledge-centric to reasoning-centric evaluation, yet the manuscript provides no ablation or sensitivity analysis on how varying the atomic norm set alters these disparities.
minor comments (2)
- [§2] Related work section: several prior cultural benchmarks (e.g., those focusing on value alignment or region-specific QA) are referenced but not compared on the knowledge-vs-reasoning axis that the paper emphasizes.
- [Figures in §5] Figure captions and axis labels in the results figures could be expanded to explicitly note the number of examples per region/domain for easier interpretation of disparity claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the transparency of our benchmark construction and analysis. We address each major comment below and commit to revisions that enhance the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Benchmark Construction): the claim that the benchmark 'enables verifiable and attributable evaluation' rests on the atomic norms accurately representing the 53 regions without selection bias or oversimplification, yet no details are provided on norm selection criteria, expert validation process, inter-rater agreement, or coverage checks across the 8 domains. This directly affects the central disentanglement of knowledge acquisition from reasoning use.
Authors: We agree that additional details on norm construction are necessary to fully support the attribution claim. The manuscript's §3 outlines that atomic norms were sourced from peer-reviewed cultural anthropology and sociology literature with region-specific grounding, but we will expand this section in revision to explicitly describe the selection criteria (prioritizing norms with documented prevalence and minimal internal contradiction), the expert consultation process (involving native cultural informants for validation), inter-rater agreement metrics where collected, and domain coverage verification (ensuring balanced representation across the 8 domains). These additions will directly bolster the disentanglement argument. revision: yes
-
Referee: [§5] §5 (Experiments and Analysis): the headline finding that performance is 'further bottlenecked by its effective use' is supported by degradation in open-ended generation, but without reported statistical controls for potential norm mismatch or regional representation bias in the 5,378 examples, alternative explanations (e.g., norm selection artifacts rather than reasoning deficits) cannot be ruled out.
Authors: The degradation pattern holds across all 53 regions and 8 domains with consistent effect sizes, which we interpret as evidence of reasoning bottlenecks rather than knowledge gaps. We acknowledge the value of explicit controls and will add in the revised §5: (i) correlation analysis between performance and sample size per region, (ii) checks for norm count per question as a potential confound, and (iii) discussion of how any detected biases were mitigated through stratified sampling. These controls will be reported to strengthen the interpretation. revision: partial
-
Referee: [Table 2 / §5] Table 2 or equivalent results table (cross-region disparities): the reported patterns of inequity and conservative responses are load-bearing for the shift from knowledge-centric to reasoning-centric evaluation, yet the manuscript provides no ablation or sensitivity analysis on how varying the atomic norm set alters these disparities.
Authors: We did not conduct full ablations on alternative norm sets, as curating multiple independent grounded sets at this scale would require substantial additional resources beyond the current study. The observed disparities and conservative tendencies appear consistently across domains and models. In revision we will include a sensitivity analysis by randomly subsampling 20-30% of norms per region and re-computing key disparity metrics, reporting stability of the inequity patterns to address this concern. revision: yes
Circularity Check
Empirical benchmark construction with no derivations or self-referential steps
full rationale
The paper introduces CultureForest as a new benchmark grounded in atomic norms, evaluates LLMs across multiple-choice to open-ended tasks, and draws conclusions about knowledge vs. reasoning bottlenecks directly from the experimental outcomes on the collected 5,378 examples. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or description; the central claim rests on fresh data rather than reducing to prior inputs by construction. This is a standard empirical contribution with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cultural norms can be decomposed into small sets of atomic norms that ground reasoning questions verifiably.
Reference graph
Works this paper leans on
-
[1]
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, H. Behl, A. Benhaim, M. Bilenko, J. Bjorck, S. Bubeck, M. Cai, Q. Cai, V . Chaudhary, D. Chen, D. Chen, W. Chen, Y .-C. Chen, Y .-L. Chen, H. Cheng, P. Chopra, X. Dai, M. Dixon, R. Eldan, V . Fragoso, J. Gao, M. Gao, M. Gao, A. Garg, A. D. Giorno, A. Goswa...
Pith/arXiv arXiv 2024
-
[2]
Introducing claude 4, 2025
Anthropic. Introducing claude 4, 2025. URL https://www.anthropic.com/news/ claude-4?c=6709
2025
-
[3]
Introducing claude sonnet 4.6, 2026
Anthropic. Introducing claude sonnet 4.6, 2026. URL https://www.anthropic.com/news/ claude-sonnet-4-6
2026
-
[4]
Bulté and A
B. Bulté and A. Rigouts Terryn. Llms and cultural values: the impact of prompt language and explicit cultural framing.Computational Linguistics, pages 1–85, 2025
2025
-
[5]
Y . Y . Chiu, L. Jiang, B. Y . Lin, C. Y . Park, S. S. Li, S. Ravi, M. Bhatia, M. Antoniak, Y . Tsvetkov, V . Shwartz, and Y . Choi. CulturalBench: A robust, diverse and challenging benchmark for measuring LMs’ cultural knowledge through human-AI red-teaming. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Proceedings of the 63rd Annual Mee...
-
[6]
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[7]
W. H. Durham. The adaptive significance of cultural behavior.Human Ecology, 4(2):89–121, 1976
1976
-
[8]
E. Durmus, K. Nguyen, T. I. Liao, N. Schiefer, A. Askell, A. Bakhtin, C. Chen, Z. Hatfield- Dodds, D. Hernandez, N. Joseph, et al. Towards measuring the representation of subjective global opinions in language models.arXiv preprint arXiv:2306.16388, 2023
Pith/arXiv arXiv 2023
-
[9]
A. R. Fabbri, D. Mares, J. Flores, M. Mankikar, E. Hernandez, D. Lee, B. Liu, and C. Xing. Multinrc: A challenging and native multilingual reasoning evaluation benchmark for llms.arXiv preprint arXiv:2507.17476, 2025
arXiv 2025
-
[10]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[11]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[12]
M. A. Hasan, M. Hasanain, F. Ahmad, S. R. Laskar, S. Upadhyay, V . N. Sukhadia, M. Kutlu, S. A. Chowdhury, and F. Alam. NativQA: Multilingual culturally-aligned natural query for LLMs. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Findings of the Association 10 for Computational Linguistics: ACL 2025, pages 14886–14909, Vienna, Austria, J...
-
[13]
S. Havaldar, M. Pressimone, E. Wong, and L. Ungar. Comparing styles across languages. In H. Bouamor, J. Pino, and K. Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6775–6791, Singapore, Dec. 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.419. URL https:// aclan...
-
[14]
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
Pith/arXiv arXiv 2009
-
[15]
Huang and D
J. Huang and D. Yang. Culturally aware natural language inference. In H. Bouamor, J. Pino, and K. Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7591–7609, Singapore, Dec. 2023. Association for Computational Linguistics. doi: 10.18653/ v1/2023.findings-emnlp.509. URL https://aclanthology.org/2023.findings-emnlp. 509/
2023
-
[16]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
Pith/arXiv arXiv 2024
-
[17]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed. Mistral 7b, 2023. URL https://arxiv.org/abs/ 2310.06825
Pith/arXiv arXiv 2023
-
[18]
M. Kabir, T. Ahmed, M. M. Rahman, S. Ji, H. Alhuzali, and S. Ananiadou. Xcr-bench: A multi- task benchmark for evaluating cultural reasoning in llms.arXiv preprint arXiv:2601.14063, 2026
Pith/arXiv arXiv 2026
-
[19]
C. Li, M. Chen, J. Wang, S. Sitaram, and X. Xie. Culturellm: Incorporating cultural differences into large language models.Advances in Neural Information Processing Systems, 37:84799– 84838, 2024
2024
-
[20]
C. Li, D. Teney, L. Yang, Q. Wen, X. Xie, and J. Wang. Culturepark: Boosting cross-cultural understanding in large language models.Advances in Neural Information Processing Systems, 37:65183–65216, 2024
2024
-
[21]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[22]
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
Pith/arXiv arXiv 2025
-
[23]
R. I. Masoud, Z. Liu, M. Ferianc, P. Treleaven, and M. Rodrigues. Cultural alignment in large language models: An explanatory analysis based on hofstede’s cultural dimensions. In O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, pages...
2025
-
[24]
Llama 3.3, 2024
Meta. Llama 3.3, 2024. URL https://github.com/meta-llama/llama-models/blob/ main/models/llama3_3/MODEL_CARD.md
2024
-
[25]
The llama 4 herd, 2025
Meta. The llama 4 herd, 2025. URL https://ai.meta.com/blog/ llama-4-multimodal-intelligence/
2025
-
[26]
The cultural atlas, 2024
Mosaica. The cultural atlas, 2024. URLhttps://culturalatlas.sbs.com.au/
2024
-
[27]
Myung, N
J. Myung, N. Lee, Y . Zhou, J. Jin, R. Putri, D. Antypas, H. Borkakoty, E. Kim, C. Perez- Almendros, A. A. Ayele, et al. Blend: A benchmark for llms on everyday knowledge in diverse cultures and languages.Advances in Neural Information Processing Systems, 37:78104–78146, 2024. 11
2024
-
[28]
and Ritter, Alan and Xu, Wei , title =
T. Naous, M. J. Ryan, A. Ritter, and W. Xu. Having beer after prayer? measuring cultural bias in large language models. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16366–16393, Bangkok, Thailand, Aug. 2024. Association for Computat...
-
[29]
Introducing gpt -4.1 in the api, 2025
OpenAI. Introducing gpt -4.1 in the api, 2025. URL https://openai.com/index/ gpt-4-1/
2025
-
[30]
Openai o3 and o4-mini system card, 2025
OpenAI. Openai o3 and o4-mini system card, 2025. URL https://cdn.openai.com/pdf/ 2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
2025
-
[31]
S. Palta and R. Rudinger. FORK: A bite-sized test set for probing culinary cultural biases in commonsense reasoning models. In A. Rogers, J. Boyd-Graber, and N. Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 9952–9962, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023...
-
[32]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, ...
Pith/arXiv arXiv 2025
-
[33]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[34]
A. Srinivasan and E. Choi. TyDiP: A dataset for politeness classification in nine typologically diverse languages. In Y . Goldberg, Z. Kozareva, and Y . Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 5723–5738, Abu Dhabi, United Arab Emirates, Dec. 2022. Association for Computational Linguistics. doi: 10.18653/...
-
[35]
Q. Team. Qwen3.5: Towards native multimodal agents, 2026. URL https://qwen.ai/blog? id=qwen3.5
2026
-
[36]
T. G. Team. Gemini 3.1 pro: A smarter model for your most complex tasks,
-
[37]
URL https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/
-
[38]
Y . Wang, Y . Zhu, C. Kong, S. Wei, X. Yi, X. Xie, and J. Sang. CDEval: A benchmark for measuring the cultural dimensions of large language models. In V . Prabhakaran, S. Dev, L. Benotti, D. Hershcovich, L. Cabello, Y . Cao, I. Adebara, and L. Zhou, editors,Proceedings of the 2nd Workshop on Cross-Cultural Considerations in NLP, pages 1–16, Bangkok, Thail...
-
[39]
Y . Ye, X. Feng, X. Feng, W. Ma, L. Qin, D. Xu, Q. Yang, H. Liu, and B. Qin. GlobeSumm: A challenging benchmark towards unifying multi-lingual, cross-lingual and multi-document news summarization. In Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10803–10821...
2024
-
[40]
Y . Ye, X. Feng, X. Feng, Y . Huang, Z. Yuan, L. Huang, W. Ma, Q. Hong, Y . Lu, D. Tu, et al. x1: Learning to think adaptively across languages and cultures.arXiv preprint arXiv:2604.16917, 2026
Pith/arXiv arXiv 2026
-
[41]
Y . Ye, X. Feng, X. Feng, L. Qin, Y . Huang, L. Huang, W. Ma, Q. Hong, Z. Zhang, Y . Lu, et al. Exploring cross-lingual latent transplantation: Mutual opportunities and open challenges.IEEE Transactions on Audio, Speech and Language Processing, 2026. 12
2026
-
[42]
Z. Yuan, Y . Ye, X. Feng, B. Li, Q. Hong, Y . Lu, D. Tu, and B. Qin. Culture-aware ma- chine translation in large language models: Benchmarking and investigation.arXiv preprint arXiv:2604.24361, 2026
Pith/arXiv arXiv 2026
-
[43]
Easy-Mode(Multiple-ChoiceQuestion):{context}+
W. Zhao, D. Mondal, N. Tandon, D. Dillion, K. Gray, and Y . Gu. WorldValuesBench: A large- scale benchmark dataset for multi-cultural value awareness of language models. In N. Calzolari, M.-Y . Kan, V . Hoste, A. Lenci, S. Sakti, and N. Xue, editors,Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and...
2024
-
[44]
Hard Compliance Rate =97.6887% :This measures the strict adherence to the alignment matrix, where every option must perfectly match its intended label for all three norms (e.g., Option A must violate Norm 1 but comply with Norms 2 and 3)
-
[45]
Answer":
Soft Compliance Rate =99.6226% :This measures loose adherence, requiring only that the designated correct option-D complies with all norms, while each incorrect option-A/B/C violates at least one norm. The inter-annotator agreement was exceptionally high, with aUnanimous Agreement of 98.1132% and aFleiss’ Kappa of 96.6643%. These results, combined with th...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.