EVA-Net: Subject-Independent EEG Motor Decoding with Video-Derived Motor Priors
Pith reviewed 2026-06-28 14:57 UTC · model grok-4.3
The pith
EVA-Net improves subject-independent EEG motor decoding by aligning brain signals with action videos during training and distilling the priors into an EEG-only classifier.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
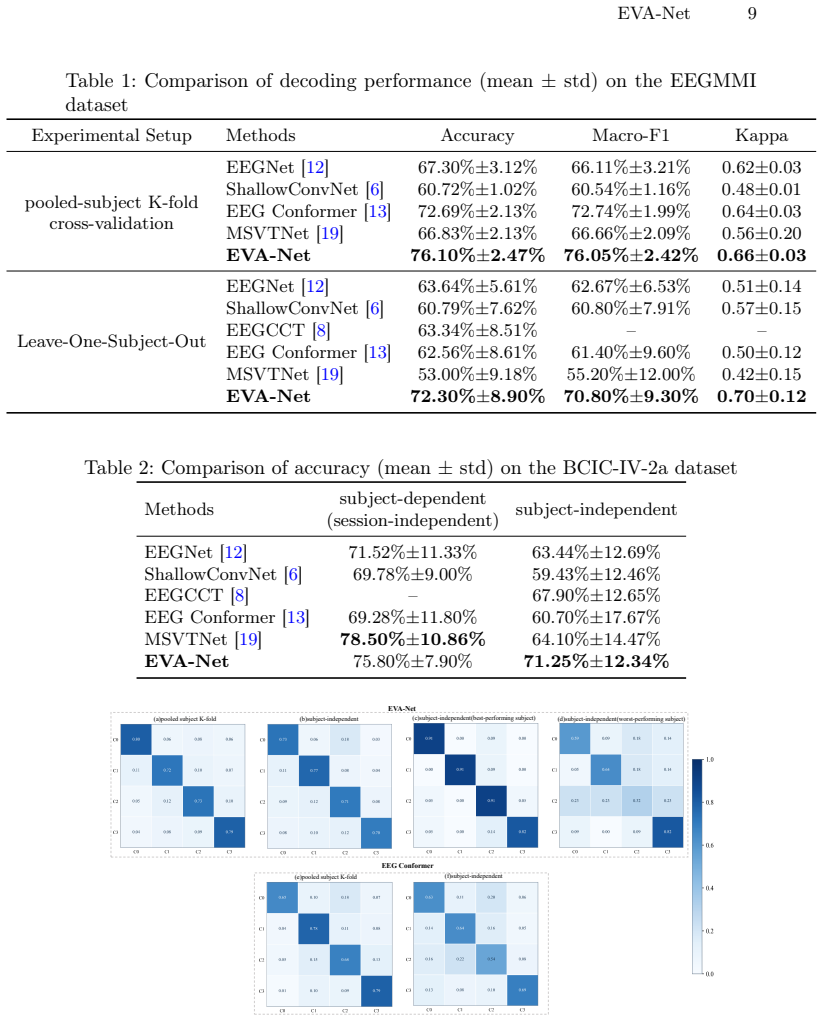
EVA-Net is a two-stage framework that first aligns EEG and video features in a shared space via cross-modal and supervised contrastive objectives to reduce subject-specific variation, then uses video category prototypes and knowledge distillation to transfer the priors to an EEG-only classifier, achieving an 8.66% gain in LOSO accuracy on the EEGMMI dataset while adding no inference overhead.
What carries the argument
The two-stage alignment and distillation pipeline that uses video action features as motor priors transferred via prototypes.
Load-bearing premise
Cross-modal alignment of EEG and video features sufficiently separates motor semantics from subject-specific noise.
What would settle it
A new dataset where the 8.66% gain disappears or reverses when using the same video priors.
Figures



read the original abstract
Practical non-invasive Brain-Computer Interface (BCI) systems require EEG decoders with strong cross-subject generalization and minimal calibration. However, inter-subject variability and signal non-stationarity often entangle motor semantics with subject-specific noise, limiting subject-independent decoding. Recent multimodal approaches use text as a semantic anchor, yet text provides sparse and static supervision for inherently dynamic motor processes. To address this issue, we propose EVA-Net, a two-stage framework that uses action videos as semantic priors for subject-independent EEG motor decoding. In the first stage, EEG and video features are aligned in a shared space using cross-modal and supervised contrastive objectives to reduce subject-specific variation. In the second stage, video category prototypes and knowledge distillation transfer video-derived priors to an EEG-only classifier without adding inference overhead. Experiments on two public datasets show that EVA-Net achieves strong subject-independent decoding performance, including an 8.66% LOSO accuracy gain on EEGMMI. Ablation results further suggest that video provides a more effective semantic anchor than the text baseline considered in this work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EVA-Net, a two-stage framework for subject-independent EEG motor decoding that uses action videos as semantic priors. Stage 1 aligns EEG and video features in a shared embedding space via cross-modal and supervised contrastive objectives to mitigate subject-specific variation. Stage 2 transfers video-derived category prototypes to an EEG-only classifier through knowledge distillation, incurring no inference-time overhead. Experiments on two public datasets report an 8.66% LOSO accuracy gain on EEGMMI, with ablations indicating video outperforms a text baseline as a semantic anchor.
Significance. If the reported gains and ablations are robust, the work offers a practical advance for calibration-light BCI by exploiting readily available video data to anchor dynamic motor semantics, addressing a noted limitation of static text priors. The two-stage design and use of public datasets are strengths that support reproducibility and potential extension.
major comments (2)
- [§3 and abstract] The central claim of an 8.66% LOSO accuracy gain on EEGMMI rests on the assumption that cross-modal contrastive alignment sufficiently decouples subject-specific noise from motor semantics (abstract and §3). Without explicit quantification of preserved motor semantics (e.g., via downstream action recognition accuracy on the aligned features or visualization of class separability), it is unclear whether the alignment step is load-bearing or merely incidental to the prototype transfer.
- [Experiments section (assumed §4)] The ablation results are cited as evidence that video is superior to text, yet the manuscript provides no statistical tests (paired t-test or Wilcoxon) or confidence intervals on the accuracy differences across subjects. This weakens the claim that video-derived priors are demonstrably more effective for the subject-independent setting.
minor comments (2)
- [§3.1] Notation for the contrastive loss terms and prototype computation should be defined explicitly with equation numbers rather than inline descriptions.
- [Table 1 or §4.1] The second public dataset is mentioned only in the abstract; its name, size, and per-subject accuracy numbers should be reported in the main results table for completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3 and abstract] The central claim of an 8.66% LOSO accuracy gain on EEGMMI rests on the assumption that cross-modal contrastive alignment sufficiently decouples subject-specific noise from motor semantics (abstract and §3). Without explicit quantification of preserved motor semantics (e.g., via downstream action recognition accuracy on the aligned features or visualization of class separability), it is unclear whether the alignment step is load-bearing or merely incidental to the prototype transfer.
Authors: We agree that direct quantification of preserved motor semantics would provide stronger evidence for the role of the alignment stage. The current results rely on end-to-end performance and ablations, which indirectly support the claim but do not isolate the semantic preservation. In the revision we will add (i) downstream action recognition accuracy on the aligned EEG features and (ii) t-SNE or similar visualizations of class separability before versus after alignment to make this explicit. revision: yes
-
Referee: [Experiments section (assumed §4)] The ablation results are cited as evidence that video is superior to text, yet the manuscript provides no statistical tests (paired t-test or Wilcoxon) or confidence intervals on the accuracy differences across subjects. This weakens the claim that video-derived priors are demonstrably more effective for the subject-independent setting.
Authors: We concur that statistical testing is needed to support the ablation claims. The manuscript currently reports mean accuracies without significance tests or confidence intervals on the per-subject differences. In the revision we will include paired t-tests (or Wilcoxon signed-rank tests) together with 95% confidence intervals for the accuracy differences between video and text priors across subjects. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and context describe a two-stage pipeline that aligns EEG and video features via standard cross-modal and supervised contrastive objectives on public external datasets, then transfers prototypes via knowledge distillation. No equations or steps are shown that reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations. The claimed LOSO gains are presented as empirical outcomes from the described architecture rather than internal tautologies, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
McFarland, D.J., Wolpaw, J.R.: EEG-based brain-computer interfaces. Curr. Opin. Biomed. Eng.4, 194–200 (2017)
2017
-
[2]
Mane, R., Chouhan, T., Guan, C.: BCI for stroke rehabilitation: motor and beyond. J. Neural Eng.17(4), 041001 (2020)
2020
-
[3]
Bioengineering12(4), 331 (2025)
Acuña Luna, K.P., Dall’Alba, H.A.C., Kaufmann, A.T., Maldonado, A., Nef, T.: Deep learning-enhanced motor training: a hybrid VR and exoskeleton system for cognitive–motor rehabilitation. Bioengineering12(4), 331 (2025)
2025
-
[4]
Sensors18(10), 3342 (2018)
Al-Quraishi, M.S., Elamvazuthi, I., Daud, S.A., Parasuraman, S.: EEG-based con- trol for upper and lower limb exoskeletons and prostheses: a systematic review. Sensors18(10), 3342 (2018)
2018
-
[5]
Roy, Y., Banville, H.J., Albuquerque, I., Gramfort, A., Falk, T.H., Faubert, J.: Deep learning-based electroencephalography analysis: a comprehensive review. J. Neural Eng.16(5), 051001 (2019)
2019
-
[6]
Wang, T., Dong, E., Du, S., Jia, C.: A shallow convolutional neural network for classifyingMI-EEG.In:Proc.ChineseAutomationCongress(CAC),pp.5837–5841 (2019)
2019
-
[7]
In: Advances in Neural Information Processing Systems (NeurIPS), vol
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 30, pp. 5998–6008 (2017)
2017
-
[8]
Keutayeva, E., Fakhrutdinov, R., Abibullaev, B.: Compact convolutional trans- former for subject-independent motor imagery EEG-based BCIs. Sci. Rep.14(1), 25775 (2024)
2024
-
[9]
In: Proc
Radford, A., et al.: Learning transferable visual models from natural language supervision. In: Proc. 38th Int. Conf. Mach. Learn. (ICML). Proc. Mach. Learn. Res. (PMLR), vol. 139, pp. 8748–8763 (2021)
2021
-
[10]
Camaret Ndir, T., Schirrmeister, R.T., Ball, T.: EEG-CLIP: learning EEG rep- resentations from natural language descriptions. Front. Robot. AI12, 1625731 (2025).https://doi.org/10.3389/frobt.2025.1625731 12 Z. Li, Y. Sun, Y. Zhang
-
[11]
Tong, Z., Song, Y., Wang, J., Wang, L.: VideoMAE: masked autoencoders are data-efficient learners for self-supervised video pre-training. In: Advances in Neu- ral Information Processing Systems (NeurIPS) (2022).https://arxiv.org/abs/ 2203.12602
-
[12]
Lawhern, V.J., Solon, A.J., Waytowich, N.R., Gordon, S.M., Hung, C.P., Lance, B.J.: EEGNet: a compact convolutional neural network for EEG-based brain– computer interfaces. J. Neural Eng.15(5), 056013 (2018).https://doi.org/10. 1088/1741-2552/aace8c
2018
-
[13]
EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization,
Song, Y., Zheng, Q., Liu, B., Gao, X.: EEG Conformer: convolutional transformer for EEG decoding and visualization. IEEE Trans. Neural Syst. Rehabil. Eng.31, 710–719 (2023).https://doi.org/10.1109/TNSRE.2022.3230250
-
[14]
arXiv:2507.02320 (2025).https://arxiv.org/abs/2507.02320
Zhang, H., Li, H.: Transformer-based EEG decoding: a survey. arXiv:2507.02320 (2025).https://arxiv.org/abs/2507.02320
-
[15]
Brunner, C., Leeb, R., Müller-Putz, G.R., Schlögl, A., Pfurtscheller, G.: BCI Com- petition 2008 – Graz data set A. Tech. Rep., Graz University of Technology (2008). https://www.bbci.de/competition/iv/desc_2a.pdf, last accessed 2026/03/03
2008
-
[16]
Leeb, R., Brunner, C., Müller-Putz, G.R., Schlögl, A., Pfurtscheller, G.: BCI Com- petition 2008 – Graz data set B. Tech. Rep., Graz University of Technology (2008). https://www.bbci.de/competition/iv/desc_2b.pdf, last accessed 2026/03/03
2008
-
[17]
IEEE Trans
Zheng, W.-L., Lu, B.-L.: Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Auton. Mental Develop.7(3), 162–175 (2015)
2015
-
[18]
Wu, D., Xu, Y., Lu, B.-L.: Transfer learning for EEG-based brain–computer inter- faces: a review of progress made since 2016. IEEE Trans. Cogn. Dev. Syst.14(1), 4–19 (2022).https://doi.org/10.1109/TCDS.2020.3007453
-
[19]
Liu, K., et al.: MSVTNet: multi-scale vision transformer neural network for EEG- based motor imagery decoding. IEEE J. Biomed. Health Inform.28(12), 7126–7137 (2024).https://doi.org/10.1109/JBHI.2024.3450753
-
[20]
In: Proc
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: Proc. 37th Int. Conf. Mach. Learn. (ICML). Proc. Mach. Learn. Res. (PMLR), vol. 119, pp. 1597–1607 (2020)
2020
-
[21]
In: Advances in Neural Infor- mation Processing Systems (NeurIPS), vol
Khosla, P., et al.: Supervised contrastive learning. In: Advances in Neural Infor- mation Processing Systems (NeurIPS), vol. 33, pp. 18661–18673 (2020)
2020
-
[22]
In: Advances in Neural Information Processing Systems (NeurIPS), vol
Snell, J., Swersky, K., Zemel, R.: Prototypical networks for few-shot learning. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 30 (2017)
2017
-
[23]
In: Proc
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the incep- tion architecture for computer vision. In: Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 2818–2826 (2016)
2016
-
[24]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv:1503.02531 (2015).https://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Goswami, M., Szafer, K., Choudhry, A., Cai, Y ., Li, S., and Dubrawski, A
Goldberger, A.L., et al.: PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. Circulation101(23), E215–E220 (2000).https://doi.org/10.1161/01.CIR.101.23.E215
-
[26]
The Kinetics Human Action Video Dataset
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., Suleyman, M., Zisserman, A.: The Kinetics human action video dataset. arXiv:1705.06950 (2017).https://arxiv. org/abs/1705.06950
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.