Private and Stable Test-Time Adaptation with Differential Privacy
Pith reviewed 2026-06-28 15:13 UTC · model grok-4.3
The pith
Test-time adaptation methods can be rewritten with per-sample gradient clipping and noise to satisfy differential privacy while retaining most of their accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Casting TTA update rules into DP form via per-sample clipping plus Gaussian noise yields methods that meet formal privacy guarantees, incur only small accuracy loss on ImageNet-C, and in the low-privacy regime can improve accuracy and stability of continual adaptation.
What carries the argument
Per-sample gradient clipping followed by addition of calibrated Gaussian noise, applied directly to the update rules of existing TTA methods.
If this is right
- Test inputs can be used for adaptation without the model parameters leaking information about any single test sample.
- Clipping during low-privacy adaptation can reduce error and variance compared with unclipped TTA in the continual setting.
- The same privacy mechanism works across multiple TTA algorithms with only modest extra compute.
- Private TTA becomes practical for settings where test data must remain confidential.
Where Pith is reading between the lines
- The approach could be extended to other online adaptation settings such as domain generalization or federated learning where test-time updates occur.
- Tighter privacy accounting that exploits the structure of TTA updates rather than treating each step independently might reduce the noise needed.
- The stability benefit of clipping suggests that similar regularization could be studied outside the DP context.
Load-bearing premise
Standard per-sample gradient clipping and Gaussian noise can be inserted into TTA update rules without destroying the intended adaptation dynamics or the formal privacy proof.
What would settle it
A concrete measurement showing that the DP-TTA variants either fail to meet their stated epsilon-delta privacy bound on the test stream or produce accuracy drops larger than the non-private baselines across the ImageNet-C corruptions.
Figures
read the original abstract
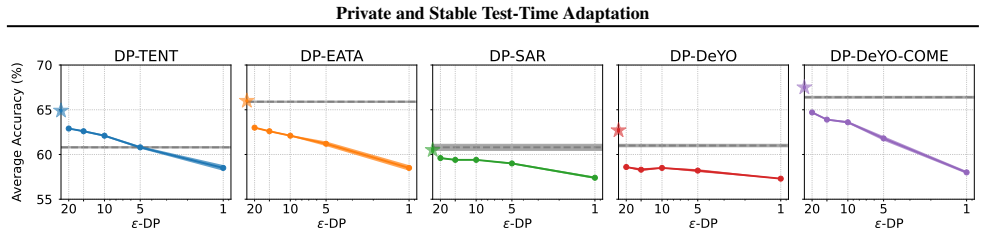
Test-time adaptation (TTA) can reduce error on new and different data by updating the model on these inputs during inference. However, these updates raise the issue of privacy w.r.t. the testing data, because the model parameters now depend on all past inputs. To control this privacy risk, we cast multiple popular TTA methods (Tent, EATA, SAR, DeYO, and COME) into differential privacy (DP) forms that apply per-sample gradient clipping and Gaussian noise for all updates. On ImageNet-C, our DP-TTA methods provide adequate privacy at small cost to accuracy, and in the low-privacy regime the clipping mechanism of DP can even improve the accuracy and stability of adaptation in the continual setting. These improvements to privacy and accuracy come at only modest computational overhead. These first results on private TTA raise awareness of the issue, inform the development of more private test-time updates, and identify per-sample clipping as an effective technique for improving the accuracy and stability of adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes to address privacy risks in test-time adaptation (TTA) by reformulating several existing methods (Tent, EATA, SAR, DeYO, COME) as differentially private variants that apply per-sample gradient clipping followed by Gaussian noise to all parameter updates. On ImageNet-C, the resulting DP-TTA procedures are claimed to deliver adequate privacy at modest accuracy cost; moreover, in the low-privacy regime the clipping operation itself is reported to improve both accuracy and stability of continual adaptation, with only modest extra compute.
Significance. If the central empirical and formal claims hold, the work is a useful first exploration of privacy in TTA. It correctly identifies that model parameters become dependent on test inputs and shows that standard DP primitives can be grafted onto existing TTA update rules. The additional observation that per-sample clipping can stabilize adaptation is a potentially actionable finding that could influence future TTA design. The manuscript supplies no machine-checked proofs or parameter-free derivations, but the empirical demonstration on a standard benchmark is a concrete starting point.
major comments (3)
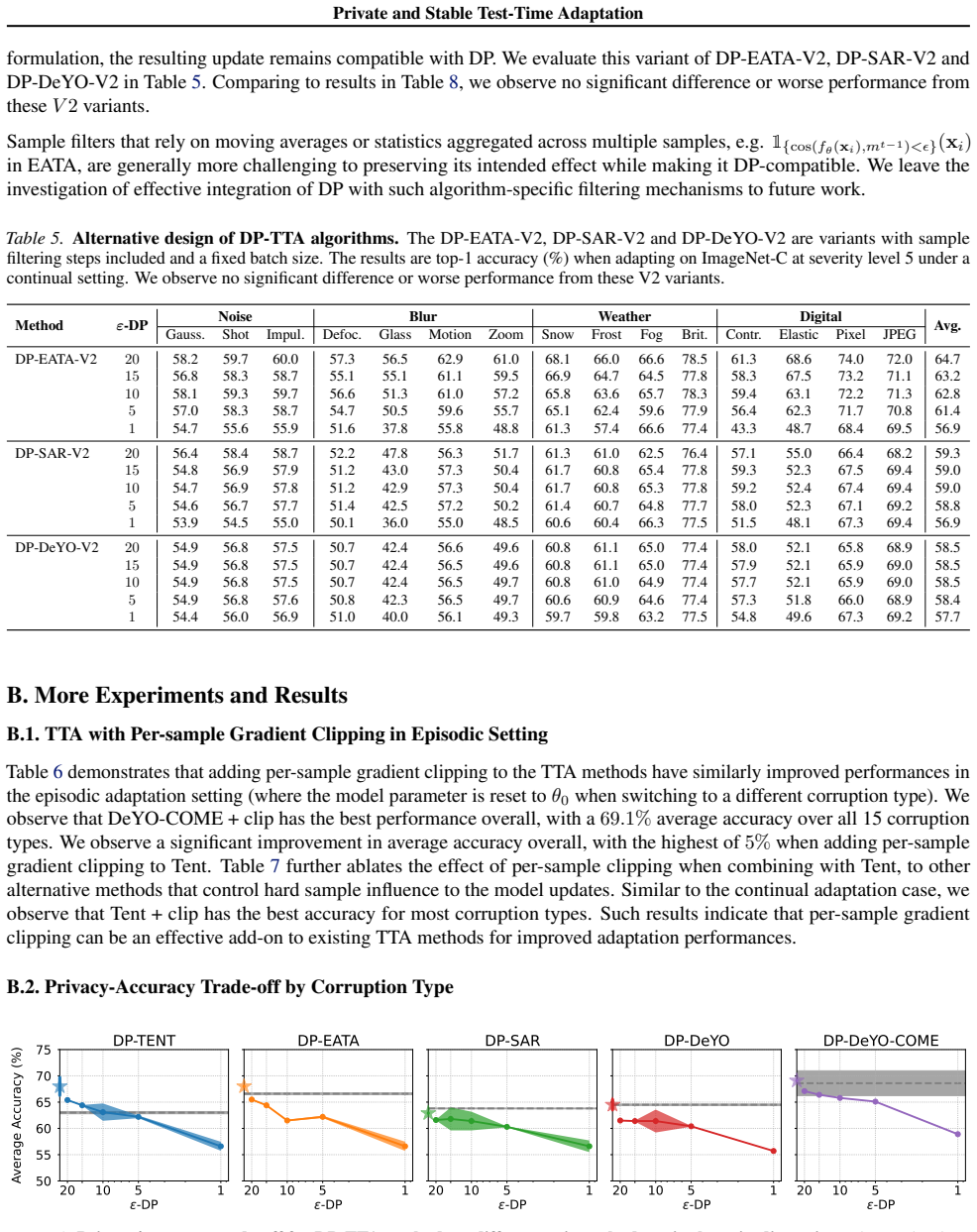
- [DP-TTA formulation] DP-TTA formulation section: the manuscript states that casting TTA update rules into DP form via standard per-sample clipping plus Gaussian noise yields formal (ε,δ)-DP while preserving the intended adaptation behavior. No sensitivity analysis or Lipschitz-style bound is supplied for the non-convex TTA losses (entropy minimization, etc.) that operate on single or small unlabeled batches; standard DP-SGD sensitivity arguments therefore do not automatically transfer. This is load-bearing for both the privacy guarantee and the claim that adaptation dynamics remain intact.
- [Experiments] Experimental evaluation on ImageNet-C: the central claims of 'adequate privacy at small cost to accuracy' and 'clipping improves accuracy and stability in the low-privacy regime' are asserted without reported values of ε and δ, without the number of independent runs, without statistical tests, and without an ablation that isolates clipping from noise. These omissions prevent verification of the quantitative outcomes that support the paper's main contribution.
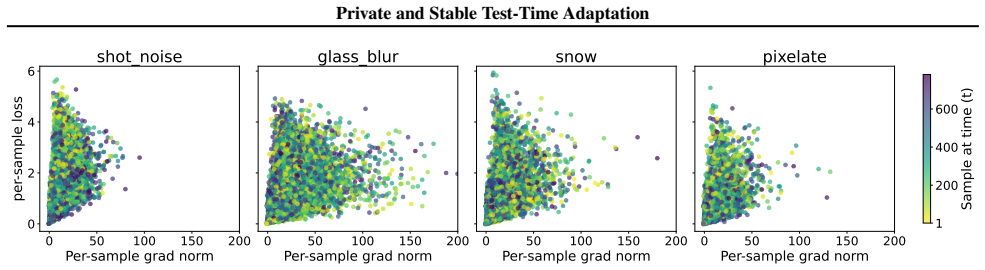
- [Continual adaptation analysis] Continual-adaptation analysis: the assertion that clipping stabilizes continual TTA requires evidence that the noisy iterates remain in a neighborhood of the non-private fixed point. No convergence argument or diagnostic (e.g., distance to non-private trajectory) is provided, leaving the stability claim unsupported.
minor comments (2)
- [Abstract] Abstract: the summary of empirical outcomes would be clearer if it referenced the concrete privacy budgets and controls used in the ImageNet-C experiments.
- [Method] Notation: the distinction between per-sample clipping norm and the noise scale σ should be stated explicitly when the DP mechanism is first introduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [DP-TTA formulation] DP-TTA formulation section: the manuscript states that casting TTA update rules into DP form via standard per-sample clipping plus Gaussian noise yields formal (ε,δ)-DP while preserving the intended adaptation behavior. No sensitivity analysis or Lipschitz-style bound is supplied for the non-convex TTA losses (entropy minimization, etc.) that operate on single or small unlabeled batches; standard DP-SGD sensitivity arguments therefore do not automatically transfer. This is load-bearing for both the privacy guarantee and the claim that adaptation dynamics remain intact.
Authors: We thank the referee for highlighting this point. The DP-TTA procedures follow the standard DP-SGD template of per-sample clipping to a fixed norm followed by Gaussian noise; under this clipping the per-update sensitivity is bounded by construction, yielding (ε,δ)-DP for each step. We agree, however, that an explicit Lipschitz or sensitivity analysis tailored to the non-convex TTA objectives (entropy minimization, etc.) is absent. In the revision we will add a clarifying paragraph that states the assumptions under which the guarantee holds and explicitly notes the lack of such bounds as a limitation of the current analysis. revision: partial
-
Referee: [Experiments] Experimental evaluation on ImageNet-C: the central claims of 'adequate privacy at small cost to accuracy' and 'clipping improves accuracy and stability in the low-privacy regime' are asserted without reported values of ε and δ, without the number of independent runs, without statistical tests, and without an ablation that isolates clipping from noise. These omissions prevent verification of the quantitative outcomes that support the paper's main contribution.
Authors: We agree that these reporting omissions hinder verification. The revised manuscript will include the concrete ε and δ values employed, results averaged over multiple independent runs together with standard deviations and appropriate statistical tests, and a dedicated ablation that isolates the contribution of clipping from that of noise. revision: yes
-
Referee: [Continual adaptation analysis] Continual-adaptation analysis: the assertion that clipping stabilizes continual TTA requires evidence that the noisy iterates remain in a neighborhood of the non-private fixed point. No convergence argument or diagnostic (e.g., distance to non-private trajectory) is provided, leaving the stability claim unsupported.
Authors: We acknowledge that the stability observation would benefit from quantitative support. The revision will add diagnostic plots that track the parameter distance between the private (clipped+noisy) and non-private trajectories throughout continual adaptation, thereby providing evidence that the iterates remain in a neighborhood of the non-private path. revision: yes
Circularity Check
No circularity: standard DP primitives applied to existing TTA methods
full rationale
The paper applies per-sample gradient clipping and Gaussian noise (standard DP-SGD mechanisms) to the update rules of prior TTA methods (Tent, EATA, SAR, etc.) without introducing self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. All central claims rest on empirical evaluation of privacy-accuracy tradeoffs on ImageNet-C rather than any derivation that reduces to its own inputs by construction. The approach is self-contained against external DP and TTA benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Theory of cryptography conference , year=
Calibrating noise to sensitivity in private data analysis , author=. Theory of cryptography conference , year=
-
[2]
Annual international conference on the theory and applications of cryptographic techniques , year=
Our data, ourselves: Privacy via distributed noise generation , author=. Annual international conference on the theory and applications of cryptographic techniques , year=
-
[3]
Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
Deep learning with differential privacy , author=. Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
2016
-
[4]
The algorithmic foundations of differential privacy.Found
Foundations and Trends® in Theoretical Computer Science , title =. 2014 , volume =. doi:10.1561/0400000042 , issn =
-
[5]
International Conference on Learning Representations , year=
Tent: Fully test-time adaptation by entropy minimization , author=. International Conference on Learning Representations , year=
-
[6]
International conference on machine learning , pages=
Efficient test-time model adaptation without forgetting , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[7]
International Conference on Learning Representations , year=
Towards stable test-time adaptation in dynamic wild world , author=. International Conference on Learning Representations , year=
-
[8]
arXiv preprint arXiv:2403.07366 , year=
Entropy is not enough for test-time adaptation: From the perspective of disentangled factors , author=. arXiv preprint arXiv:2403.07366 , year=
-
[9]
2024 , eprint=
COME: Test-time adaption by Conservatively Minimizing Entropy , author=. 2024 , eprint=
2024
-
[10]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Gaussian differential privacy , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2022 , publisher=
2022
-
[11]
2022 IEEE symposium on security and privacy (SP) , year=
Membership inference attacks from first principles , author=. 2022 IEEE symposium on security and privacy (SP) , year=
2022
-
[12]
28th USENIX security symposium (USENIX security 19) , pages=
The secret sharer: Evaluating and testing unintended memorization in neural networks , author=. 28th USENIX security symposium (USENIX security 19) , pages=
-
[13]
30th USENIX security symposium (USENIX Security 21) , year=
Extracting training data from large language models , author=. 30th USENIX security symposium (USENIX Security 21) , year=
-
[14]
2022 IEEE Symposium on Security and Privacy (SP) , year=
Reconstructing training data with informed adversaries , author=. 2022 IEEE Symposium on Security and Privacy (SP) , year=
2022
-
[15]
Scalable Extraction of Training Data from (Production) Language Models
Scalable extraction of training data from (production) language models , author=. arXiv preprint arXiv:2311.17035 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
See through gradients: Image batch recovery via gradinversion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
-
[17]
Proceedings of the 2017 ACM SIGSAC conference on computer and communications security , pages=
Deep models under the GAN: Information leakage from collaborative deep learning , author=. Proceedings of the 2017 ACM SIGSAC conference on computer and communications security , pages=
2017
-
[18]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Sharpness-aware minimization for efficiently improving generalization , author=. arXiv preprint arXiv:2010.01412 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[19]
International Conference on Machine Learning , pages=
Differentially private sharpness-aware training , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[20]
Ashkan Yousefpour and Igor Shilov and Alexandre Sablayrolles and Davide Testuggine and Karthik Prasad and Mani Malek and John Nguyen and Sayan Ghosh and Akash Bharadwaj and Jessica Zhao and Graham Cormode and Ilya Mironov , journal=. Opacus:
-
[21]
Numerical Composition of Differential Privacy , url =
Gopi, Sivakanth and Lee, Yin Tat and Wutschitz, Lukas , booktitle =. Numerical Composition of Differential Privacy , url =
-
[22]
2019 , eprint=
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author=. 2019 , eprint=
2019
-
[23]
2017 , eprint=
Membership Inference Attacks against Machine Learning Models , author=. 2017 , eprint=
2017
-
[24]
ICML , pages =
Uncovering Adversarial Risks of Test-Time Adaptation , author =. ICML , pages =. 2023 , editor =
2023
-
[25]
Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security , pages =
Fredrikson, Matt and Jha, Somesh and Ristenpart, Thomas , title =. Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security , pages =. 2015 , isbn =. doi:10.1145/2810103.2813677 , abstract =
-
[26]
Benchmarking neural network robustness to common corruptions and perturbations , year =
Hendrycks, Dan and Dietterich, Thomas , booktitle =. Benchmarking neural network robustness to common corruptions and perturbations , year =
-
[27]
Generalisation in humans and deep neural networks , year =
Geirhos, Robert and Temme, Carlos RM and Rauber, Jonas and Sch. Generalisation in humans and deep neural networks , year =. Advances in Neural Information Processing Systems , pages =
-
[28]
ReservoirTTA: Prolonged Test-time Adaptation for Evolving and Recurring Domains , year =
Vray, Guillaume and Tomar, Devavrat and Gao, Xufeng and Thiran, Jean-Philippe and Shelhamer, Evan and Bozorgtabar, Behzad , booktitle =. ReservoirTTA: Prolonged Test-time Adaptation for Evolving and Recurring Domains , year =
-
[29]
GitHub repository , doi =
Ross Wightman , title =. GitHub repository , doi =. 2019 , publisher =
2019
-
[30]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[31]
International conference on machine learning , pages=
On the difficulty of training recurrent neural networks , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[32]
International Conference on Learning Representations , year=
Can gradient clipping mitigate label noise? , author=. International Conference on Learning Representations , year=
-
[33]
International conference on machine learning , pages=
High-performance large-scale image recognition without normalization , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[34]
arXiv preprint arXiv:2110.06500 , year=
Differentially private fine-tuning of language models , author=. arXiv preprint arXiv:2110.06500 , year=
-
[35]
arXiv preprint arXiv:2204.13650 , year=
Unlocking high-accuracy differentially private image classification through scale , author=. arXiv preprint arXiv:2204.13650 , year=
-
[36]
International conference on machine learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[37]
Proceedings of the European conference on computer vision (ECCV) , pages=
Group normalization , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[38]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence , year=
(Nearly) optimal differentially private stochastic multi-arm bandits , author=. Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence , year=
-
[40]
International Conference on Machine Learning , year=
Private reinforcement learning with pac and regret guarantees , author=. International Conference on Machine Learning , year=
-
[41]
Russakovsky, Olga and Deng, Jia and Su, Hao and Krause, Jonathan and Satheesh, Sanjeev and Ma, Sean and Huang, Zhiheng and Karpathy, Andrej and Khosla, Aditya and Bernstein, Michael and others , journal =
-
[42]
Adam: A method for stochastic optimization , year =
Kingma, Diederik and Ba, Jimmy , booktitle =. Adam: A method for stochastic optimization , year =
-
[43]
2022 , eprint=
Hyperparameter Tuning with Renyi Differential Privacy , author=. 2022 , eprint=
2022
-
[44]
2018 , eprint=
Private Selection from Private Candidates , author=. 2018 , eprint=
2018
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[46]
ICCV , year=
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization , author=. ICCV , year=
-
[47]
2022 , eprint=
Differentially Private Learning with Adaptive Clipping , author=. 2022 , eprint=
2022
-
[48]
Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Wild-Time: A Benchmark of in-the-Wild Distribution Shift over Time , author=. Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.