Resonant Context Anchoring: Decoupling Attention Routing and Signal Gain at Inference Time
Pith reviewed 2026-06-28 14:24 UTC · model grok-4.3
The pith
Resonant Context Anchoring decouples attention routing from signal gain to boost context evidence in LLMs at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
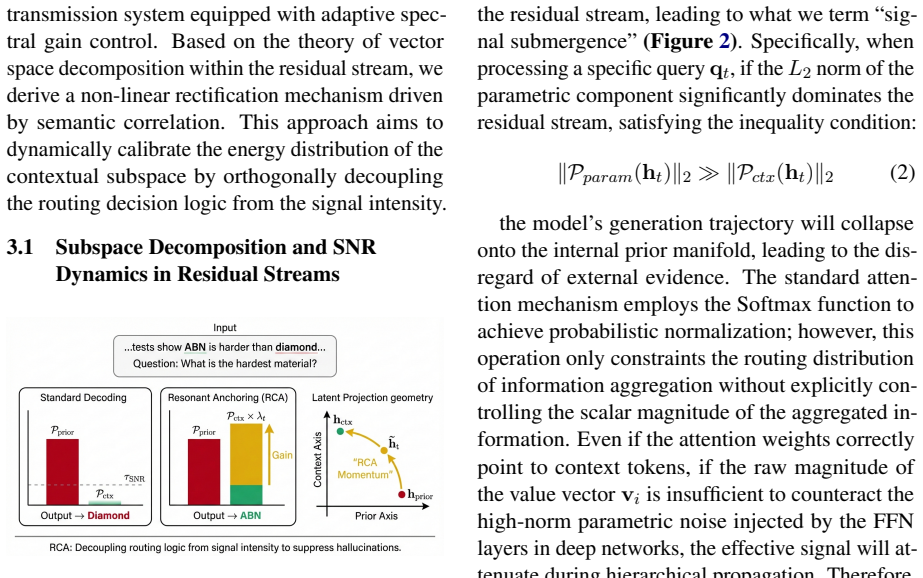
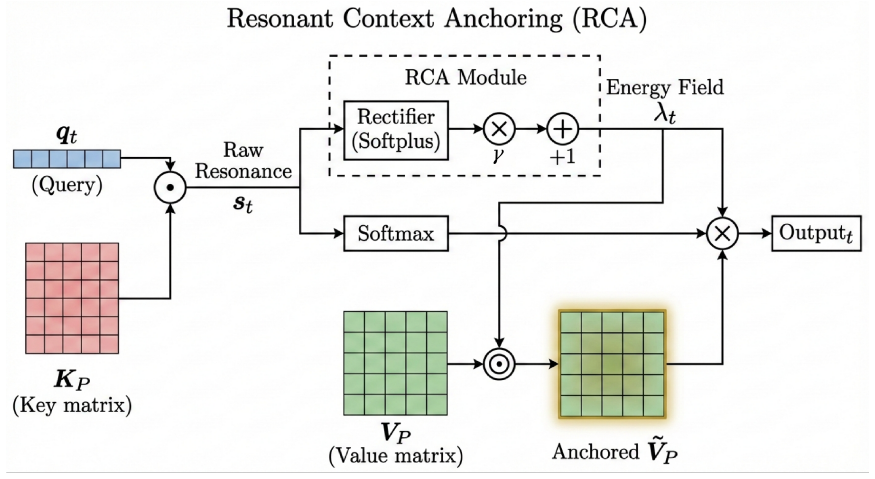
By orthogonally decoupling the routing logic and information magnitude within the self-attention module, RCA constructs a dynamic gain field from raw pre-softmax attention scores via non-linear rectification. This selectively amplifies the norms of value vectors for context tokens, elevating the signal-to-noise ratio of input evidence and anchoring the generation trajectory to the truthful context during inference.
What carries the argument
The dynamic gain field derived from pre-softmax attention scores, which amplifies context value vector norms without altering the attention probability distribution.
Load-bearing premise
That pre-softmax attention scores provide a reliable enough measure of semantic alignment to create a gain field that amplifies context signals without introducing new distortions or errors in the output.
What would settle it
Running RCA on a knowledge-conflict benchmark and finding that faithfulness scores do not increase or that fluency decreases compared to the unmodified model.
Figures

read the original abstract
Large Language Models (LLMs) frequently exhibit "contextual disregard" when faced with input evidence that conflicts with their internal parametric memory, leading to persistent factual hallucinations. Existing mitigation strategies primarily rely on suppressing specific neuron activations or employing computationally expensive contrastive decoding mechanisms, which often result in increased perplexity or significantly elevated inference latency. To address these limitations, we propose Resonant Context Anchoring (RCA), a lightweight inference-time intervention method grounded in the perspective of residual stream signal dynamics. RCA aims to resolve the signal attenuation of external evidence during its propagation through deep networks. The core mechanism involves the orthogonal decoupling of routing logic and information magnitude within the self-attention module. By utilizing raw pre-softmax attention scores as an instantaneous metric of semantic alignment, we construct a dynamic gain field via non-linear rectification to selectively amplify the norms of value vectors corresponding to context tokens, without altering the attention probability distribution. This mechanism effectively elevates the signal-to-noise ratio (SNR) of input evidence within the residual stream mixture, thereby robustly anchoring the generation trajectory to the truthful context during inference. Extensive experiments on the Llama-3 model series demonstrate that RCA significantly improves contextual faithfulness across multiple factual consistency and strong knowledge-conflict tasks, effectively suppressing parametric hallucinations. Furthermore, results confirm that as a training-free and computationally negligible plug-and-play module, RCA achieves a Pareto improvement in faithfulness and fluency while maintaining the model's general language understanding capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Resonant Context Anchoring (RCA), a training-free inference-time intervention for LLMs that decouples attention routing from signal gain. It constructs a non-linear gain field from raw pre-softmax attention scores to selectively amplify the norms of value vectors for context tokens (without changing the attention distribution), thereby elevating the SNR of input evidence in the residual stream and anchoring generation to truthful context. Experiments on Llama-3 models report improved contextual faithfulness on factual consistency and knowledge-conflict tasks, with a Pareto improvement in faithfulness and fluency.
Significance. If the central mechanism is sound, RCA would represent a lightweight, plug-and-play method for mitigating parametric hallucinations that avoids the latency or perplexity costs of contrastive decoding or neuron suppression. The training-free nature and negligible compute overhead are notable strengths if the reported gains hold under rigorous controls.
major comments (1)
- [Abstract / §3] Abstract (mechanism description, cross-referenced to §3): The core assumption that raw pre-softmax attention logits provide a faithful, instantaneous proxy for semantic alignment between context evidence and query is not justified. In strong knowledge-conflict regimes the residual stream already mixes parametric and contextual signals prior to the attention layer; if the logits therefore encode internal priors rather than input evidence, the resulting non-linear gain field will amplify the wrong tokens or leave the SNR of truthful context unchanged. Because the intervention leaves the attention probability distribution unaltered, any misalignment propagates directly into the residual stream.
Simulated Author's Rebuttal
We thank the referee for the comment on the mechanism assumption. We address it directly below.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract (mechanism description, cross-referenced to §3): The core assumption that raw pre-softmax attention logits provide a faithful, instantaneous proxy for semantic alignment between context evidence and query is not justified. In strong knowledge-conflict regimes the residual stream already mixes parametric and contextual signals prior to the attention layer; if the logits therefore encode internal priors rather than input evidence, the resulting non-linear gain field will amplify the wrong tokens or leave the SNR of truthful context unchanged. Because the intervention leaves the attention probability distribution unaltered, any misalignment propagates directly into the residual stream.
Authors: The logits at each layer are computed from the query state (already shaped by prior residual mixing) against the keys, so they reflect instantaneous compatibility given the mixed stream rather than pure priors. RCA applies non-linear rectification to these relative scores to modulate value norms orthogonally; this does not require the logits to be purely contextual. Experiments on strong knowledge-conflict tasks (§4.2) show consistent gains in contextual faithfulness with no fluency degradation, indicating the gain field elevates context SNR in practice. Because routing is unchanged, any residual misalignment is not worsened and the magnitude adjustment provides the observed anchoring benefit. No revision is required. revision: no
Circularity Check
No circularity: RCA is a defined mechanistic intervention, not a reduction to fitted inputs or self-citation
full rationale
The paper introduces RCA as an explicit inference-time procedure that takes raw pre-softmax attention logits as input and applies a non-linear rectification to value-vector norms. No equation or claim equates the reported faithfulness gains to a parameter fitted on the same data, nor does any load-bearing step rest on a self-citation whose content is itself unverified. The derivation chain consists of a stated design choice followed by empirical measurement on held-out tasks; the improvement is therefore not forced by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
-
[3]
2022 , eprint=
Rich Knowledge Sources Bring Complex Knowledge Conflicts: Recalibrating Models to Reflect Conflicting Evidence , author=. 2022 , eprint=
2022
-
[7]
2023 , eprint=
Contrastive Decoding Improves Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[8]
2024 , eprint=
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author=. 2024 , eprint=
2024
-
[9]
2024 , eprint=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. 2024 , eprint=
2024
-
[11]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[13]
2025 , eprint=
A mathematical perspective on Transformers , author=. 2025 , eprint=
2025
-
[14]
2021 , eprint=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. 2021 , eprint=
2021
-
[15]
2023 , eprint=
Editing Implicit Assumptions in Text-to-Image Diffusion Models , author=. 2023 , eprint=
2023
-
[16]
2022 , eprint=
In-context Learning and Induction Heads , author=. 2022 , eprint=
2022
-
[18]
2023 , eprint=
LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond , author=. 2023 , eprint=
2023
-
[20]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[21]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[23]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[26]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[27]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[29]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[32]
2024 , eprint=
Inverse Scaling: When Bigger Isn't Better , author=. 2024 , eprint=
2024
-
[33]
2024 , eprint=
TeleChat Technical Report , author=. 2024 , eprint=
2024
-
[34]
2025 , eprint=
Making Every Head Count: Sparse Attention Without the Speed-Performance Trade-off , author=. 2025 , eprint=
2025
-
[35]
T ele C hat: An Open-source Billingual Large Language Model
Wang, Zihan and Liu, XinZhang and Liu, Shixuan and Yao, Yitong and Huang, Yunyao and Li, Mengxiang and He, Zhongjiang and Li, Yongxian and Pu, Luwen and Xu, Huinan and Wang, Chao and Song, Shuangyong. T ele C hat: An Open-source Billingual Large Language Model. Proceedings of the 10th SIGHAN Workshop on Chinese Language Processing (SIGHAN-10). 2024
2024
-
[36]
2025 , eprint=
Technical Report of TeleChat2, TeleChat2.5 and T1 , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Training Report of TeleChat3-MoE , author=. 2025 , eprint=
2025
-
[38]
2024 , eprint=
Tele-FLM Technical Report , author=. 2024 , eprint=
2024
-
[39]
2024 , eprint=
52B to 1T: Lessons Learned via Tele-FLM Series , author=. 2024 , eprint=
2024
-
[40]
2025 , eprint=
MR-UIE: Multi-Perspective Reasoning with Reinforcement Learning for Universal Information Extraction , author=. 2025 , eprint=
2025
-
[41]
2025 , eprint=
TableReasoner: Advancing Table Reasoning Framework with Large Language Models , author=. 2025 , eprint=
2025
-
[42]
Knowledge-Based Systems , volume=
Enhancing math reasoning ability of large language models via computation logic graphs , author=. Knowledge-Based Systems , volume=. 2025 , publisher=
2025
-
[44]
2025 , eprint=
Mosaic Pruning: A Hierarchical Framework for Generalizable Pruning of Mixture-of-Experts Models , author=. 2025 , eprint=
2025
-
[45]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://proceedings.neurips.cc/paper_fil...
2020
-
[46]
Hung-Ting Chen, Michael J. Q. Zhang, and Eunsol Choi. 2022. https://arxiv.org/abs/2210.13701 Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence . Preprint, arXiv:2210.13701
arXiv 2022
-
[47]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. 2024. https://arxiv.org/abs/2309.03883 Dola: Decoding by contrasting layers improves factuality in large language models . Preprint, arXiv:2309.03883
Pith/arXiv arXiv 2024
-
[48]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, and 6 others. 2021. https://transformer-circuits.pub/2021/framework/index.html A mat...
2021
-
[49]
Shangbin Feng, Vidhisha Balachandran, Yuyang Bai, and Yulia Tsvetkov. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.59 F act KB : Generalizable factuality evaluation using language models enhanced with factual knowledge . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 933--952, Singapore. Association f...
-
[50]
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. 2025. https://arxiv.org/abs/2312.10794 A mathematical perspective on transformers . Preprint, arXiv:2312.10794
arXiv 2025
-
[51]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. https://arxiv.org/abs/2012.14913 Transformer feed-forward layers are key-value memories . Preprint, arXiv:2012.14913
Pith/arXiv arXiv 2021
-
[52]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
Pith/arXiv arXiv 2024
-
[53]
Zhongjiang He, Zihan Wang, Xinzhang Liu, Shixuan Liu, Yitong Yao, Yuyao Huang, Xuelong Li, Yongxiang Li, Zhonghao Che, Zhaoxi Zhang, Yan Wang, Xin Wang, Luwen Pu, Huinan Xu, Ruiyu Fang, Yu Zhao, Jie Zhang, Xiaomeng Huang, Zhilong Lu, and 17 others. 2024. https://arxiv.org/abs/2401.03804 Telechat technical report . Preprint, arXiv:2401.03804
arXiv 2024
-
[54]
Wentao Hu, Mingkuan Zhao, Shuangyong Song, Xiaoyan Zhu, Xin Lai, and Jiayin Wang. 2025. https://arxiv.org/abs/2511.19822 Mosaic pruning: A hierarchical framework for generalizable pruning of mixture-of-experts models . Preprint, arXiv:2511.19822
arXiv 2025
-
[55]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. https://doi.org/10.1145/3571730 Survey of hallucination in natural language generation . ACM Comput. Surv., 55(12)
-
[56]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. https://doi.org/10.18653/v1/P17-1147 T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601--1611, Vancouver, Canada. Assoc...
-
[57]
Fabbri, Caiming Xiong, Shafiq Joty, and Chien-Sheng Wu
Philippe Laban, Wojciech Kryściński, Divyansh Agarwal, Alexander R. Fabbri, Caiming Xiong, Shafiq Joty, and Chien-Sheng Wu. 2023. https://arxiv.org/abs/2305.14540 Llms as factual reasoners: Insights from existing benchmarks and beyond . Preprint, arXiv:2305.14540
arXiv 2023
-
[58]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. https://arxiv.org/abs/2005.11401 Retrieval-augmented generation for knowledge-intensive nlp tasks . Preprint, arXiv:2005.11401
Pith/arXiv arXiv 2021
-
[59]
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2024 a . https://arxiv.org/abs/2306.03341 Inference-time intervention: Eliciting truthful answers from a language model . Preprint, arXiv:2306.03341
Pith/arXiv arXiv 2024
-
[60]
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, and Tiejun Huang. 2024 b . https://arxiv.org/abs/2407.02783 52b to 1t: Lessons learned via tele-flm series . Preprint, arXi...
arXiv 2024
-
[61]
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, and Tiejun Huang. 2024 c . https://arxiv.org/abs/2404.16645 Tele-flm technical report . Preprint, arXiv:2404.16645
arXiv 2024
-
[62]
Zhongqiu Li, Shiquan Wang, Ruiyu Fang, Mengjiao Bao, Zhenhe Wu, Shuangyong Song, Yongxiang Li, and Zhongjiang He. 2025. https://arxiv.org/abs/2509.09082 Mr-uie: Multi-perspective reasoning with reinforcement learning for universal information extraction . Preprint, arXiv:2509.09082
arXiv 2025
-
[63]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013/ ROUGE : A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
2004
-
[64]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://doi.org/10.18653/v1/2022.acl-long.229 T ruthful QA : Measuring how models mimic human falsehoods . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland. Association for Computational Linguistics
-
[65]
Xinzhang Liu, Chao Wang, Zhihao Yang, Zhuo Jiang, Xuncheng Zhao, Haoran Wang, Lei Li, Dongdong He, Luobin Liu, Kaizhe Yuan, Han Gao, Zihan Wang, Yitong Yao, Sishi Xiong, Wenmin Deng, Haowei He, Kaidong Yu, Yu Zhao, Ruiyu Fang, and 35 others. 2025. https://arxiv.org/abs/2512.24157 Training report of telechat3-moe . Preprint, arXiv:2512.24157
arXiv 2025
-
[66]
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.565 Entity-based knowledge conflicts in question answering . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7052--7063, Online and Punta Cana, Dominican Republic....
-
[67]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. https://doi.org/10.18653/v1/2023.acl-long.546 When not to trust language models: Investigating effectiveness of parametric and non-parametric memories . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
-
[68]
Ian R. McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, Andrew Gritsevskiy, Daniel Wurgaft, Derik Kauffman, Gabriel Recchia, Jiacheng Liu, Joe Cavanagh, Max Weiss, Sicong Huang, The Floating Droid, and 8 others. 2024. https://arxiv.org/abs/2306.09479 Inverse scali...
arXiv 2024
-
[69]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.741 FA ct S core: Fine-grained atomic evaluation of factual precision in long form text generation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Langua...
-
[70]
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. https://doi.org/10.18653/v1/D18-1206 Don ' t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797--1807, Brussels, Belgium. Association for Co...
-
[71]
Sean O'Brien and Mike Lewis. 2023. https://arxiv.org/abs/2309.09117 Contrastive decoding improves reasoning in large language models . Preprint, arXiv:2309.09117
arXiv 2023
-
[72]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, and 7 others. 2022. https://arxiv.org/abs/2209.11895 In-context learning and induct...
Pith/arXiv arXiv 2022
-
[73]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, and 262 others. 2024. https://arxiv.org/abs/2303.08774 Gpt-4 technical r...
Pith/arXiv arXiv 2024
-
[74]
Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. 2023. https://arxiv.org/abs/2303.08084 Editing implicit assumptions in text-to-image diffusion models . Preprint, arXiv:2303.08084
arXiv 2023
-
[75]
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. 2024. https://doi.org/10.18653/v1/2024.acl-long.828 Steering llama 2 via contrastive activation addition . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504--15522, Bangkok, Thailand. Assoc...
-
[76]
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Wen-tau Yih. 2024. https://doi.org/10.18653/v1/2024.naacl-short.69 Trusting your evidence: Hallucinate less with context-aware decoding . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo...
-
[77]
Nishant Subramani, Nivedita Suresh, and Matthew Peters. 2022. https://doi.org/10.18653/v1/2022.findings-acl.48 Extracting latent steering vectors from pretrained language models . In Findings of the Association for Computational Linguistics: ACL 2022, pages 566--581, Dublin, Ireland. Association for Computational Linguistics
-
[78]
Vazquez, Ulisse Mini, and Monte MacDiarmid
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. 2024. https://arxiv.org/abs/2308.10248 Steering language models with activation engineering . Preprint, arXiv:2308.10248
Pith/arXiv arXiv 2024
-
[79]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf Attention is all you need . In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc
2017
-
[80]
Xi Wang, Procheta Sen, Ruizhe Li, and Emine Yilmaz. 2025 a . https://doi.org/10.18653/v1/2025.findings-naacl.30 Adaptive retrieval-augmented generation for conversational systems . In Findings of the Association for Computational Linguistics: NAACL 2025, pages 491--503, Albuquerque, New Mexico. Association for Computational Linguistics
-
[81]
Zihan Wang, XinZhang Liu, Shixuan Liu, Yitong Yao, Yunyao Huang, Mengxiang Li, Zhongjiang He, Yongxian Li, Luwen Pu, Huinan Xu, Chao Wang, and Shuangyong Song. 2024. https://aclanthology.org/2024.sighan-1.2/ T ele C hat: An open-source billingual large language model . In Proceedings of the 10th SIGHAN Workshop on Chinese Language Processing (SIGHAN-10), ...
2024
-
[82]
Zihan Wang, Xinzhang Liu, Yitong Yao, Chao Wang, Yu Zhao, Zhihao Yang, Wenmin Deng, Kaipeng Jia, Jiaxin Peng, Yuyao Huang, Sishi Xiong, Zhuo Jiang, Kaidong Yu, Xiaohui Hu, Fubei Yao, Ruiyu Fang, Zhuoru Jiang, Ruiting Song, Qiyi Xie, and 19 others. 2025 b . https://arxiv.org/abs/2507.18013 Technical report of telechat2, telechat2.5 and t1 . Preprint, arXiv...
arXiv 2025
-
[83]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: Sta...
-
[84]
Hongrui Xing, Xinzhang Liu, Zhuo Jiang, Zhihao Yang, Yitong Yao, Zihan Wang, Wenmin Deng, Chao Wang, Shuangyong Song, Wang Yang, Zhongjiang He, and Yongxiang Li. 2025. https://doi.org/10.18653/v1/2025.xllm-1.31 LLMSR @ XLLM 25: A language model-based pipeline for structured reasoning data construction . In Proceedings of the 1st Joint Workshop on Large La...
-
[85]
Sishi Xiong, Dakai Wang, Yu Zhao, Jie Zhang, Changzai Pan, Haowei He, Xiangyu Li, Wenhan Chang, Zhongjiang He, Shuangyong Song, and Yongxiang Li. 2025. https://arxiv.org/abs/2507.08046 Tablereasoner: Advancing table reasoning framework with large language models . Preprint, arXiv:2507.08046
arXiv 2025
-
[86]
Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. 2023. https://doi.org/10.18653/v1/2023.acl-long.634 A lign S core: Evaluating factual consistency with a unified alignment function . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328--11348, Toronto, Canada. Association for Co...
-
[87]
Deji Zhao, Donghong Han, Jia Wu, Zhongjiang He, Bo Ning, Ye Yuan, Yongxiang Li, Chao Wang, and Shuangyong Song. 2025 a . Enhancing math reasoning ability of large language models via computation logic graphs. Knowledge-Based Systems, 325:113905
2025
-
[88]
Mingkuan Zhao, Wentao Hu, Jiayin Wang, Xin Lai, Tianchen Huang, Yuheng Min, Rui Yan, and Xiaoyan Zhu. 2025 b . https://arxiv.org/abs/2511.09596 Making every head count: Sparse attention without the speed-performance trade-off . Preprint, arXiv:2511.09596
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.