QoEReasoner: An Agentic Reasoning Framework for Automated and Explainable QoE Diagnosis in RANs
Pith reviewed 2026-06-28 11:54 UTC · model grok-4.3
The pith
QoEReasoner grounds LLM reasoning in deterministic tools, a protocol knowledge base, and historical cases to automate QoE diagnosis in RANs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
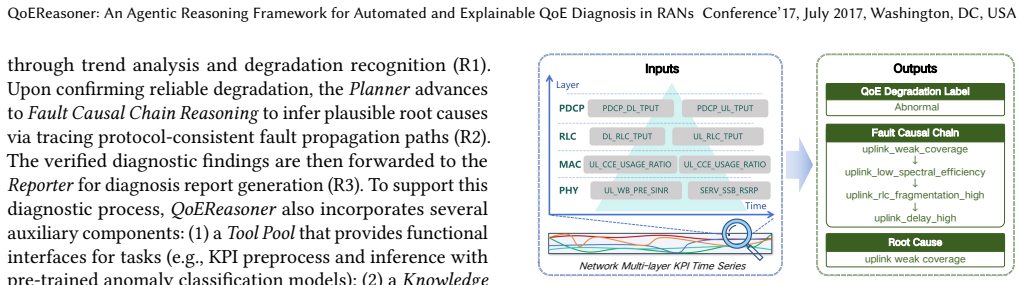
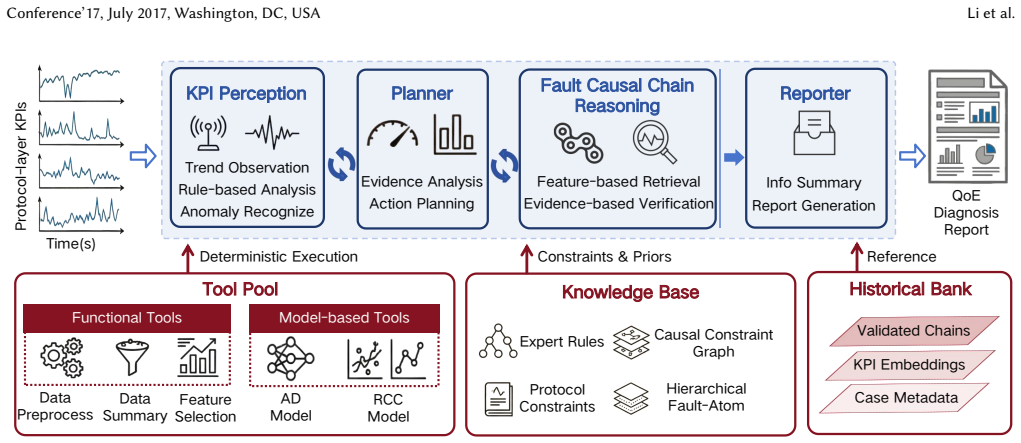
QoEReasoner is an end-to-end LLM-driven agentic system for automated and explainable QoE diagnosis that tames LLM unpredictability by grounding reasoning in the physical realities of the network through deterministic tools for translating raw numeric KPIs into structured evidence, a domain-specific Knowledge Base that enforces protocol-consistent fault propagation, and a Historical Bank of expert-validated cases to guide hypothesis generation, with a stateful central planner orchestrating the closed-loop process across anomaly detection, causal tracing, and root-cause localization.
What carries the argument
QoEReasoner, the end-to-end agentic system whose stateful central planner coordinates deterministic KPI translation tools, a protocol-enforcing Knowledge Base, and a Historical Bank of validated cases.
If this is right
- Diagnostic accuracy on multiple tasks rises 18 to 40 percent above strong baselines on real RAN datasets.
- Time per diagnostic session drops from roughly 30 minutes of expert work to 3 minutes while producing interpretable reports.
- Performance holds across different LLM backbones without retraining the core orchestration.
- The closed-loop process of anomaly detection, causal tracing, and localization becomes repeatable and auditable.
Where Pith is reading between the lines
- The same grounding pattern of tools plus knowledge base could be tested on other telemetry-heavy troubleshooting domains such as core network or cloud service faults.
- Adding more historical cases to the bank might further tighten hypothesis ranking if the current set already covers common patterns.
- Real-time streaming of KPIs into the deterministic tools could allow continuous rather than session-based diagnosis.
Load-bearing premise
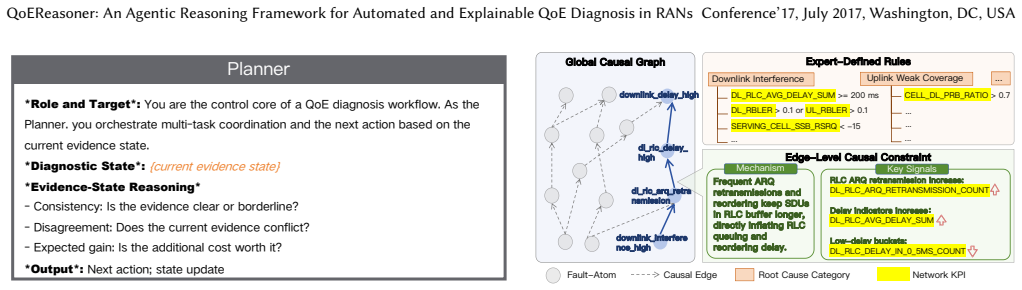
The deterministic tools and domain knowledge base can convert every relevant KPI into accurate evidence and capture all real fault propagation paths without systematic omissions.
What would settle it
An operational RAN trace containing a QoE degradation whose root cause is missed or misattributed by the system because a KPI translation rule or causal link in the knowledge base does not match the actual network behavior.
Figures






read the original abstract
Diagnosing Quality-of-Experience (QoE) degradations in operational Radio Access Networks (RANs) is a critical but notoriously complex task, traditionally requiring labor-intensive expert analysis over high-dimensional, cross-layer telemetry. While Large Language Models (LLMs) offer unprecedented reasoning capabilities, they are fundamentally unsuited for raw RANs troubleshooting: they fail at numeric time-series analysis, hallucinate protocol-violating causal links, and lack the stateful rigor required for multi-step fault localization. To bridge this gap, we present QoEReasoner, an end-to-end, LLM-driven agentic system designed for automated and explainable QoE diagnosis. QoEReasoner tames the inherent unpredictability of LLMs by grounding their reasoning in the physical realities of the network. It employs deterministic tools to reliably translate raw numeric KPIs into structured evidence, enforces protocol-consistent fault propagation through a domain-specific Knowledge Base, and leverages a Historical Bank of expert-validated cases to guide hypothesis generation. A stateful central planner orchestrates this closed-loop process across anomaly detection, causal tracing, and root-cause localization. Evaluations on real-world operational RANs datasets demonstrate that QoEReasoner outperforms strong baselines by 18\%-40\% in accuracy across multiple diagnostic tasks. Furthermore, it reduces diagnostic time from approximately 30 minutes of manual expert analysis to just 3 minutes per session, delivering highly interpretable, expert-grade reports while remaining robust across diverse LLM backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents QoEReasoner, an end-to-end LLM-driven agentic system for automated and explainable QoE diagnosis in operational RANs. It uses deterministic tools to process raw KPIs into evidence, a domain-specific Knowledge Base to enforce protocol-consistent causal links, a Historical Bank of expert cases, and a stateful central planner for anomaly detection, causal tracing, and root-cause localization. The paper claims that on real-world datasets, it outperforms baselines by 18-40% in accuracy and reduces diagnostic time from ~30 minutes to 3 minutes per session, producing interpretable expert-grade reports robust across LLM backbones.
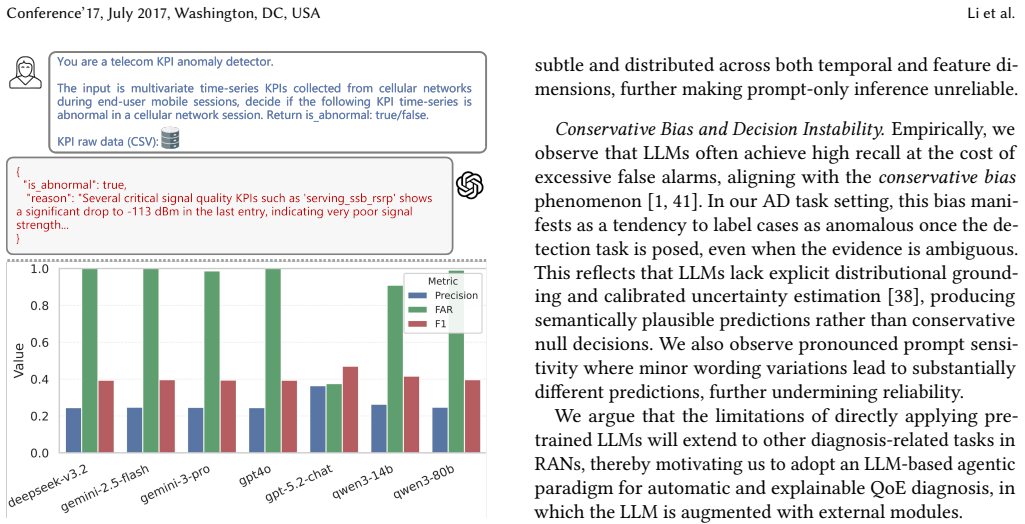
Significance. If the performance claims hold under rigorous evaluation, this work could be significant for the field of multi-agent systems applied to network management, demonstrating how to effectively ground LLMs with domain tools and knowledge to overcome their limitations in numeric analysis and causal reasoning. The closed-loop agentic approach addresses a practical pain point in RAN troubleshooting.
major comments (2)
- [Abstract] Abstract: The central performance claims of 18%-40% accuracy improvement across diagnostic tasks and reduction from approximately 30 minutes to 3 minutes lack any description of the datasets used, the strong baselines compared against, the specific diagnostic tasks, statistical tests, or error analysis. This absence makes it impossible to evaluate the soundness of the main results.
- [Abstract / System Description] Abstract / System Description: The claim that the domain-specific Knowledge Base enforces complete, protocol-consistent causal links (and thereby supports the reported accuracy gains) is load-bearing, yet no construction method, coverage metrics, or ablation on KB completeness is provided. If the KB omits real-world fault propagations such as cross-layer interactions, the causal tracing component would produce systematically biased hypotheses.
minor comments (1)
- [Abstract] Abstract: The time reduction is stated as 'approximately 30 minutes' to 'just 3 minutes'; providing more precise measurement methodology (e.g., how sessions were timed and what constitutes a 'session') would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires additional context for the performance claims and that the Knowledge Base construction merits explicit description and evaluation. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims of 18%-40% accuracy improvement across diagnostic tasks and reduction from approximately 30 minutes to 3 minutes lack any description of the datasets used, the strong baselines compared against, the specific diagnostic tasks, statistical tests, or error analysis. This absence makes it impossible to evaluate the soundness of the main results.
Authors: We agree the abstract should be self-contained. In revision we will expand it to name the real-world operational RAN datasets (including scale and collection period), identify the baselines (LLM-only agents, rule-based systems, and prior diagnostic frameworks), specify the three diagnostic tasks (anomaly detection, causal tracing, root-cause localization), and note that paired statistical tests (McNemar and Wilcoxon) were used with error analysis reported in Section 5. Full dataset statistics, baseline implementations, and per-task breakdowns already appear in Sections 4 and 5; the abstract will now reference these elements concisely. revision: yes
-
Referee: [Abstract / System Description] Abstract / System Description: The claim that the domain-specific Knowledge Base enforces complete, protocol-consistent causal links (and thereby supports the reported accuracy gains) is load-bearing, yet no construction method, coverage metrics, or ablation on KB completeness is provided. If the KB omits real-world fault propagations such as cross-layer interactions, the causal tracing component would produce systematically biased hypotheses.
Authors: We accept that the abstract and system description must substantiate the KB claim. The full manuscript (Section 3.2) describes KB construction from 3GPP TS 38.300/TS 38.331 plus expert-validated fault trees, but we will add an explicit subsection detailing the extraction pipeline, validation protocol, and coverage statistics (number of causal edges, cross-layer paths covered). We will also insert an ablation study removing KB subsets and measuring accuracy drop on the same test cases, directly addressing potential omissions such as cross-layer interactions. revision: yes
Circularity Check
No significant circularity; engineered system with no mathematical derivation chain
full rationale
The paper describes an LLM-driven agentic framework (QoEReasoner) that combines deterministic tools, a domain Knowledge Base, a Historical Bank, and a stateful planner for QoE diagnosis in RANs. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text. Performance claims rest on external evaluations against baselines rather than any closed-loop reduction to the system's own definitions or prior self-referential results. The derivation chain is absent; the work is an engineering artifact whose correctness is assessed via empirical testing, not internal self-consistency of a mathematical construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Toyin Aguda, Erik Wilson, Allan Anzagira, Simerjot Kaur, and Charese Smiley. 2025. Conservative bias in large language models: measuring relation predictions. InFindings of the association for computational linguistics: acl 2025. 18989–18998
2025
-
[2]
Khurshid Alam, Mohammad Asif Habibi, Matthias Tammen, Dennis Krummacker, Walid Saad, Marco Di Renzo, Tommaso Melodia, Xavier Costa-Pérez, Mérouane Debbah, Ashutosh Dutta, et al. 2025. A com- prehensive tutorial and survey of O-RAN: Exploring slicing-aware architecture, deployment options, use cases, and challenges.IEEE Communications Surveys & Tutorials(2025)
2025
-
[3]
Gordon Owusu Boateng, Hani Sami, Ahmed Alagha, Hanae Elmekki, Ahmad Hammoud, Rabeb Mizouni, Azzam Mourad, Hadi Otrok, Jamal Bentahar, Sami Muhaidat, et al . 2025. A survey on large language models for communication, network, and service management: Appli- cation insights, challenges, and future directions.IEEE Communications Surveys & Tutorials(2025)
2025
-
[4]
Ashima Chawla, Paul Jacob, Saman Feghhi, Devashish Rughwani, Sven van der Meer, and Sheila Fallon. 2020. Interpretable unsupervised anomaly detection for RAN cell trace analysis. In2020 16th Interna- tional Conference on Network and Service Management (CNSM). IEEE, 1–5
2020
-
[5]
Haolong Chen, Hanzhi Chen, Zijian Zhao, Kaifeng Han, Guangxu Zhu, Yichen Zhao, Ying Du, Wei Xu, and Qingjiang Shi. 2026. An overview of domain-specific foundation model: key technologies, applications and challenges.Science China Information Sciences69, 1 (2026), 111301
2026
-
[6]
Kuo-Ming Chen, Tsung-Hui Chang, Kai-Cheng Wang, and Ta-Sung Lee. 2019. Machine learning based automatic diagnosis in mobile communication networks.IEEE Transactions on Vehicular Technology 68, 10 (2019), 10081–10093
2019
- [7]
-
[8]
Gabriela Ciocarlie, Ulf Lindqvist, Kenneth Nitz, Szabolcs Nováczki, and Henning Sanneck. 2014. On the feasibility of deploying cell anom- aly detection in operational cellular networks. In2014 IEEE Network Operations and Management Symposium (NOMS). IEEE, 1–6
2014
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Giorgos Dimopoulos, Ilias Leontiadis, Pere Barlet-Ros, Konstantina Papagiannaki, and Peter Steenkiste. 2015. Identifying the root cause of video streaming issues on mobile devices. InProceedings of the 11th ACM Conference on Emerging Networking Experiments and Technologies. 1–13
2015
-
[11]
Emadeldeen Eldele, Mohamed Ragab, Zhenghua Chen, Min Wu, Chee- Keong Kwoh, Xiaoli Li, and Cuntai Guan. 2023. Self-supervised con- trastive representation learning for semi-supervised time-series classi- fication.IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 12 (2023), 15604–15618
2023
-
[12]
Emadeldeen Eldele, Mohamed Ragab, Zhenghua Chen, Min Wu, Chee- Kong Lee, Hien Nguyen, Chi Li, and Kwoh Chee Keong. 2021. Time- Series Representation Learning via Temporal and Contextual Contrast- ing. InProceedings of the Thirtieth International Joint Conference on Ar- tificial Intelligence (IJCAI-21). International Joint Conferences on Arti- ficial Intel...
-
[13]
Mah-Rukh Fida, Azza H Ahmed, Thomas Dreibholz, Andrés F Ocampo, Ahmed Elmokashfi, and Foivos I Michelinakis. 2023. Bottleneck identi- fication in cloudified mobile networks based on distributed telemetry. IEEE Transactions on Mobile Computing23, 5 (2023), 5660–5676
2023
-
[14]
Madhuri Ghuge, Nidhi Ranjan, Rupali Atul Mahajan, Pawan Arunku- mar Upadhye, Shrinivas T Shirkande, and Darshana Bhamare. 2023. Deep learning driven QoS anomaly detection for network performance optimization.Journal of Electrical Systems19, 2 (2023). 13 Conference’17, July 2017, Washington, DC, USA Li et al
2023
-
[15]
Juan Luis Herrera, Sofia Montebugnoli, Domenico Scotece, Luca Fos- chini, and Paolo Bellavista. 2025. A tutorial on o-ran deployment solutions for 5g: From simulation to emulated and real testbeds.IEEE Communications Surveys & Tutorials(2025)
2025
-
[16]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Ebenezer R.H.P. Isaac and Akshat Sharma. 2024. Adaptive Threshold- ing Heuristic for KPI Anomaly Detection. In2024 16th International Conference on COMmunication Systems & NETworkS (COMSNETS). 737–741. doi:10.1109/COMSNETS59351.2024.10427016
-
[18]
Feibo Jiang, Cunhua Pan, Kezhi Wang, Pietro Michiardi, Octavia A Dobre, and Merouane Debbah. 2026. From large ai models to agentic ai: A tutorial on future intelligent communications.IEEE Journal on Selected Areas in Communications(2026)
2026
-
[19]
Feibo Jiang, Yubo Peng, Li Dong, Kezhi Wang, Kun Yang, Cunhua Pan, Dusit Niyato, and Octavia A Dobre. 2024. Large language model enhanced multi-agent systems for 6G communications.IEEE Wireless Communications(2024)
2024
-
[20]
Cameron Kane. 2015. System and method for identifying problems on a network. US Patent 9,172,593
2015
-
[21]
Fahime Khoramnejad and Ekram Hossain. 2025. Generative AI for the optimization of next-generation wireless networks: Basics, state-of- the-art, and open challenges.IEEE Communications Surveys & Tutorials 27, 6 (2025), 3483–3525
2025
-
[22]
Yaxuan Kong, Yiyuan Yang, Yoontae Hwang, Wenjie Du, Stefan Zohren, Zhangyang Wang, Ming Jin, and Qingsong Wen. 2025. Time- MQA: Time Series Multi-Task Question Answering with Context En- hancement. InProceedings of the 63rd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers). Associ- ation for Computational Linguistic...
-
[23]
LangChain. 2024. https://github.com/langchain-ai/langgraph
2024
-
[24]
Jungjae Lee, Dongjae Lee, Chihun Choi, Youngmin Im, Jaeyoung Wi, Kihong Heo, Sangeun Oh, Sunjae Lee, and Insik Shin. 2025. Verisafe agent: Safeguarding mobile gui agent via logic-based action verifi- cation. InProceedings of the 31st Annual International Conference on Mobile Computing and Networking. 817–831
2025
-
[25]
Borui Li, Tianen Liu, Weilong Wang, Chengqing Zhao, and Shuai Wang
-
[26]
Agent-as-a-Service: An AI-Native Edge Computing Framework for 6G Networks.IEEE Network(2024)
2024
-
[27]
Qizhe Li, Haolong Chen, Jiansheng Li, Shuqi Chai, Xuan Li, Yuzhou Hou, Xinhua Shao, Fangfang Li, Kaifeng Han, and Guangxu Zhu. 2025. DK-Root: A Joint Data-and-Knowledge-Driven Framework for Root Cause Analysis of QoE Degradations in Mobile Networks.arXiv preprint arXiv:2511.11737(2025)
-
[28]
Zheng Lin, Guanqiao Qu, Qiyuan Chen, Xianhao Chen, Zhe Chen, and Kaibin Huang. 2025. Pushing large language models to the 6g edge: Vision, challenges, and opportunities.IEEE Communications Magazine 63, 9 (2025), 52–59
2025
-
[29]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. 2025. Large language models can deliver accurate and interpretable time series anomaly detection. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4623–4634
2025
-
[31]
Haoxiang Luo, Yinqiu Liu, Ruichen Zhang, Jiacheng Wang, Gang Sun, Dusit Niyato, Hongfang Yu, Zehui Xiong, Xianbin Wang, and Xuemin Shen. 2025. Toward edge general intelligence with multiple-large language model (Multi-LLM): architecture, trust, and orchestration. IEEE Transactions on Cognitive Communications and Networking(2025)
2025
- [32]
-
[33]
Abdelkader Mekrache, Adlen Ksentini, and Christos Verikoukis. 2024. Intent-based management of next-generation networks: An LLM- centric approach.IEEE Network38, 5 (2024), 29–36
2024
-
[34]
Mohamed Moulay, Rafael Garcia Leiva, Pablo J Rojo Maroni, Javier Lazaro, Vincenzo Mancuso, and Antonio Fernandez Anta. 2020. A novel methodology for the automated detection and classification of networking anomalies. InIEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS). IEEE, 780–786
2020
-
[35]
Mourad Nouioua, Philippe Fournier-Viger, Ganghuan He, Farid Nouioua, and Zhou Min. 2021. A survey of machine learning for network fault management. InMachine Learning and Data Mining for Emerging Trend in Cyber Dynamics: Theories and Applications. Springer, 1–27
2021
-
[36]
Kinge Mbeke Theophane Osee, Valery Nkemeni, and Michael Ekonde Sone. 2025. Quality of experience management in mobile networks: Techniques, constraints, and emerging trends for value-added services. Computer Networks and Communications(2025), 21–58
2025
-
[37]
Junwoo Park, Hyuck Lee, Dohyun Lee, Daehoon Gwak, and Jaegul Choo. 2025. Revisiting LLMs as Zero-Shot Time Series Forecasters: Small Noise Can Break Large Models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 906–922
2025
-
[38]
Guanqiao Qu, Qiyuan Chen, Wei Wei, Zheng Lin, Xianhao Chen, and Kaibin Huang. 2025. Mobile edge intelligence for large language models: A contemporary survey.IEEE Communications Surveys & Tutorials(2025)
2025
-
[39]
Yuval Reif and Roy Schwartz. 2024. Beyond performance: Quantifying and mitigating label bias in LLMs. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 6784–6798
2024
-
[40]
Abdelaziz Salama, Zeinab Nezami, Mohammed MH Qazzaz, Maryam Hafeez, and Syed Ali Raza Zaidi. 2025. Edge agentic AI framework for autonomous network optimisation in O-RAN. In2025 IEEE 36th International Symposium on Personal, Indoor and Mobile Radio Commu- nications (PIMRC). IEEE, 1–7
2025
-
[41]
Leming Shen, Qiang Yang, Yuanqing Zheng, and Mo Li. 2025. Autoiot: Llm-driven automated natural language programming for aiot appli- cations. InProceedings of the 31st Annual International Conference on Mobile Computing and Networking. 468–482
2025
-
[42]
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. 2024. Llm- check: Investigating detection of hallucinations in large language models.Advances in Neural Information Processing Systems37 (2024), 34188–34216
2024
-
[43]
Chuanhao Sun, Ujjwal Pawar, Molham Khoja, Xenofon Foukas, Ma- hesh K Marina, and Bozidar Radunovic. 2024. SpotLight: Accurate, explainable and efficient anomaly detection for Open RAN. InProceed- ings of the 30th Annual International Conference on Mobile Computing and Networking. 923–937
2024
-
[44]
Yan Sun, Yinqiu Liu, Shaoyong Guo, Xuesong Qiu, Jiewei Chen, Jiakai Hao, and Dusit Niyato. 2025. Edge large AI model agent-empowered cognitive multimodal semantic communication.IEEE Transactions on Mobile Computing(2025). 14 QoEReasoner: An Agentic Reasoning Framework for Automated and Explainable QoE Diagnosis in RANs Conference’17, July 2017, Washington...
2025
-
[45]
Tobias Sundqvist, Monowar H Bhuyan, Johan Forsman, and Erik Elm- roth. 2020. Boosted ensemble learning for anomaly detection in 5G RAN. InIFIP international conference on artificial intelligence applica- tions and innovations. Springer, 15–30
2020
- [46]
- [47]
-
[48]
Kailin Tong and Selim Solmaz. 2024. Connectgpt: Connect large lan- guage models with connected and automated vehicles. In2024 IEEE Intelligent Vehicles Symposium (IV). IEEE, 581–588
2024
-
[49]
Bingrui Wang, Yuan Zhou, Leijiao Ge, and Sun-Yuan Kung. 2025. Large- model-based smart agent for time series anomaly detection in power systems.Expert Systems with Applications(2025), 128917
2025
-
[50]
Duo Wu, Xianda Wang, Yaqi Qiao, Zhi Wang, Junchen Jiang, Shuguang Cui, and Fangxin Wang. 2024. Netllm: Adapting large language models for networking. InProceedings of the ACM SIGCOMM 2024 Conference. 661–678
2024
-
[51]
Junjielong Xu, Qinan Zhang, Zhiqing Zhong, Shilin He, Chaoyun Zhang, Qingwei Lin, Dan Pei, Pinjia He, Dongmei Zhang, and Qi Zhang
-
[52]
InThe Thirteenth International Conference on Learn- ing Representations
OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures?. InThe Thirteenth International Conference on Learn- ing Representations. https://openreview.net/forum?id=M4qNIzQYpd
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[55]
Yannan Yuan, Jiaolong Yang, Ran Duan, I Chih-Lin, and Jinri Huang
-
[56]
In2020 IEEE Globecom Workshops (GC Wkshps
Anomaly detection and root cause analysis enabled by artificial intelligence. In2020 IEEE Globecom Workshops (GC Wkshps. IEEE, 1–6
-
[57]
Ruichen Zhang, Guangyuan Liu, Yinqiu Liu, Changyuan Zhao, Ji- acheng Wang, Yunting Xu, Dusit Niyato, Jiawen Kang, Yonghui Li, Shiwen Mao, et al. 2026. Toward edge general intelligence with agentic AI and agentification: Concepts, technologies, and future directions. IEEE Communications Surveys & Tutorials28 (2026), 4285–4318
2026
-
[58]
Zihao Zhou and Rose Yu. 2025. Can LLMs Understand Time Series Anomalies?. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=LGafQ1g2D2 A Preliminary LLM Study Setup This appendix summarizes the experimental setup for the preliminary study in §2.2. We consider prompt-based anom- aly detection on cellular...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.