Mitigating Bias in Locally Constrained Decoding via Tractable Proposals
Pith reviewed 2026-06-28 14:22 UTC · model grok-4.3
The pith
Tensorized finite automata yield proposals that let SMC sampling converge to constrained language model distributions faster and with fewer particles than local masking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
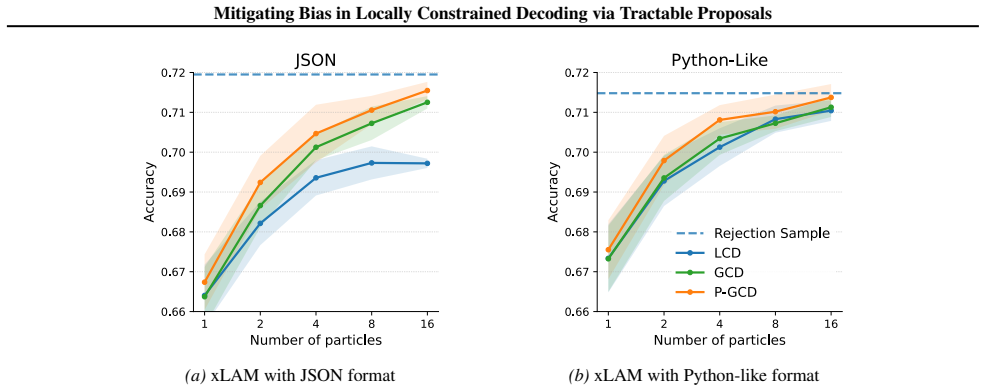
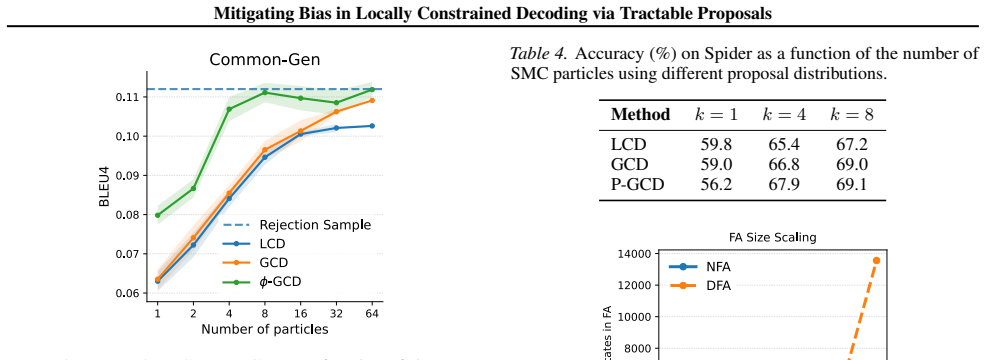
Constraints expressed as finite automata can be tensorized for efficient GPU execution and share the same circuit structure as hidden Markov models. This structure supports the construction of globally constrained decoding (GCD) proposals and probabilistic GCD (P-GCD) proposals that incorporate both logical constraints and probabilistic information from the language model. Under the same sequential Monte Carlo sampling setup, (P-)GCD proposals converge to the target distribution p_lm(· | constraint) faster and require significantly fewer particles than locally constrained decoding proposals.
What carries the argument
Tensorized finite automaton representation of constraints, which permits GPU-efficient global proposals and circuit multiplication with hidden Markov models to form GCD and P-GCD proposals for SMC.
If this is right
- Fewer particles suffice to obtain unbiased samples from language models under finite-automaton constraints.
- The same SMC setup produces higher-quality function-calling and SQL outputs when GCD or P-GCD proposals replace local masking.
- Bias from myopic token masking is reduced without changing the underlying language model or the SMC resampling schedule.
- Tensorization enables the proposals to run at scale on modern hardware while preserving exact constraint satisfaction.
Where Pith is reading between the lines
- The same tensorized-automaton technique could be applied to other sampling algorithms that currently rely on local proposals.
- If constraints outside regular languages can be approximated by finite automata, the efficiency gain may extend to broader classes of structured generation tasks.
- Reducing the particle requirement lowers memory and latency costs for deploying constrained generation in production settings.
Load-bearing premise
Constraints can be specified as finite automata that admit tensorization for GPU execution and share circuit structure with hidden Markov models.
What would settle it
Run SMC with a fixed particle budget on a held-out SQL generation task and measure the KL divergence or total variation distance between the empirical output distribution and the true target; the claim is falsified if LCD reaches the same distance with equal or fewer particles than GCD.
Figures


read the original abstract
Generations from large language models often fail to conform to desired constraints such as JSON schema. Existing locally constrained decoding (LCD) approaches enforce constraints by myopically masking out next tokens, resulting in biased sampling and degradation in performance. Recent work uses sequential Monte Carlo (SMC) methods to mitigate such biases, but designing effective proposal distributions or potential functions remains a key challenge. In this work, we propose a generic approach to construct proposals and potentials for SMC sampling from $p_{\mathrm{lm}}( \cdot \mid \mathrm{constraint})$. First, we show that constraints specified as finite automata can be tensorized for efficient execution on GPUs, which we use to construct globally constrained decoding (GCD) proposals. In addition, leveraging the fact that tensorized finite automata share the same circuit structure as hidden Markov models, we circuit-multiply them to obtain the probabilistic GCD (P-GCD) proposals encoding both logical and probabilistic information about the target distributions. We evaluate (P-)GCD on the tasks of function calling, keyword-based generation, and SQL generation. Experiments show that under the same SMC sampling setup, compared to LCD proposals, (P-)GCD converges faster to the target distribution with significantly fewer particles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a generic approach to construct proposals and potentials for SMC sampling from p_lm(· | constraint). Constraints specified as finite automata are tensorized for efficient GPU execution to build globally constrained decoding (GCD) proposals; these are further circuit-multiplied with hidden Markov models to obtain probabilistic GCD (P-GCD) proposals that encode both logical and probabilistic information. Experiments on function calling, keyword-based generation, and SQL generation show that, under the same SMC sampling setup, (P-)GCD converges faster to the target distribution with significantly fewer particles than LCD proposals.
Significance. If the empirical results hold, the work offers a tractable, GPU-efficient method for constructing effective proposals that incorporate both constraints and model probabilities, directly addressing bias in locally constrained decoding. The tensorization of automata and the HMM circuit-multiplication insight are practical strengths that could generalize beyond the evaluated tasks.
major comments (1)
- [Abstract] Abstract: the central claim that (P-)GCD converges faster with significantly fewer particles is presented without any quantitative metrics, particle counts, convergence curves, statistical tests, or error analysis, so the magnitude and reliability of the improvement cannot be assessed from the provided text.
minor comments (1)
- [Abstract] Abstract: the notation p_lm(· | constraint) appears without an explicit definition or reference to its construction.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive comment on the abstract. We agree that the abstract would be strengthened by including quantitative details and will revise it accordingly in the resubmission.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that (P-)GCD converges faster with significantly fewer particles is presented without any quantitative metrics, particle counts, convergence curves, statistical tests, or error analysis, so the magnitude and reliability of the improvement cannot be assessed from the provided text.
Authors: We agree with this observation. The current abstract summarizes the empirical findings at a high level without specific numbers. In the revised manuscript we will update the abstract to report key quantitative results from Section 5, including: convergence achieved with 8-32 particles for (P-)GCD versus 128-512 for LCD baselines on the three tasks; relative effective sample size improvements; and references to the convergence plots (Figures 3-5) that include error bars and statistical comparisons. These metrics are already present in the experimental section with full details on particle counts, wall-clock times, and variance estimates; the revision will simply surface representative values in the abstract itself. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation constructs GCD proposals by tensorizing finite automata for GPU execution and P-GCD by circuit multiplication with HMM structures. These steps are presented as following directly from automata properties and shared circuit structure with HMMs, without any reduction to fitted parameters, self-definitions, or load-bearing self-citations. The empirical claim of faster SMC convergence is evaluated on downstream tasks and does not rely on renaming or importing uniqueness from prior author work. The paper is self-contained against external benchmarks with no quoted steps that collapse by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Constraints specified as finite automata can be tensorized for efficient execution on GPUs.
- domain assumption Tensorized finite automata share the same circuit structure as hidden Markov models.
Reference graph
Works this paper leans on
-
[1]
W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., Webson, A., Gu, S
Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., Webson, A., Gu, S. S., Dai, Z., Suzgun, M., Chen, X., Chowdhery, A., Castro-Ros, A., Pellat, M., Robinson, K., Valter, D., Narang, S., Mishra, G., Yu, A., Zhao, V., Huang, Y., Dai, A., Yu, H., Petrov, S., Chi, E. H., Dean, J., Devlin, J., Roberts,...
2024
-
[2]
Abs: Enforcing constraint satisfaction on generated sequences via automata-guided beam search
Collura, V., Tit, K., Bussi, L., Giunchiglia, E., and Cordy, M. Abs: Enforcing constraint satisfaction on generated sequences via automata-guided beam search. arXiv preprint arXiv:2506.09701, 2025
-
[3]
F., Cai, Y., Xu, Z., Zhao, Y., Lai, R., and Chen, T
Dong, Y., Ruan, C. F., Cai, Y., Xu, Z., Zhao, Y., Lai, R., and Chen, T. Xgrammar: Flexible and efficient structured generation engine for large language models. Proceedings of Machine Learning and Systems, 7, 2025
2025
-
[4]
and Robson, E
Evans, C. and Robson, E. W. automata: A python package for simulating and manipulating automata. Journal of Open Source Software, 2023
2023
-
[5]
Gehman, S., Gururangan, S., Sap, M., Choi, Y., and Smith, N. A. R eal T oxicity P rompts: Evaluating neural toxic degeneration in language models. In Cohn, T., He, Y., and Liu, Y. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2020, 2020
2020
-
[6]
arXiv preprint arXiv:2501.10868 , year=
Geng, S., Cooper, H., Moskal, M., Jenkins, S., Berman, J., Ranchin, N., West, R., Horvitz, E., and Nori, H. Jsonschemabench: A rigorous benchmark of structured outputs for language models. arXiv preprint arXiv:2501.10868, 2025
-
[7]
A., Vaidya, S., Park, K., Ji, R., Berg-Kirkpatrick, T., and D'Antoni, L
Gonzalez, E. A., Vaidya, S., Park, K., Ji, R., Berg-Kirkpatrick, T., and D'Antoni, L. Constrained sampling for language models should be easy: An MCMC perspective. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[8]
E., Motwani, R., and Ullman, J
Hopcroft, J. E., Motwani, R., and Ullman, J. D. Introduction to Automata Theory, Languages and Computability. Addison-Wesley Longman Publishing Co., Inc., 2000
2000
-
[9]
J., Jain, M., Elmoznino, E., Kaddar, Y., Lajoie, G., Bengio, Y., and Malkin, N
Hu, E. J., Jain, M., Elmoznino, E., Kaddar, Y., Lajoie, G., Bengio, Y., and Malkin, N. Amortizing intractable inference in large language models. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[10]
D., McCann, B., Keskar, N
Krause, B., Gotmare, A. D., McCann, B., Keskar, N. S., Joty, S., Socher, R., and Rajani, N. F. Gedi: Generative discriminator guided sequence generation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pp.\ 4929--4952, 2021
2021
-
[11]
Spider 2.0: Evaluating language models on real-world enterprise text-to- SQL workflows
Lei, F., Chen, J., Ye, Y., Cao, R., Shin, D., SU, H., SUO, Z., Gao, H., Hu, W., Yin, P., Zhong, V., Xiong, C., Sun, R., Liu, Q., Wang, S., and Yu, T. Spider 2.0: Evaluating language models on real-world enterprise text-to- SQL workflows. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[12]
Correctness-guaranteed code generation via constrained decoding
Li, L., salar rahili, and Zhao, Y. Correctness-guaranteed code generation via constrained decoding. In The Second Conference on Language Modeling, 2025
2025
-
[13]
Y., Zhou, W., Shen, M., Zhou, P., Bhagavatula, C., Choi, Y., and Ren, X
Lin, B. Y., Zhou, W., Shen, M., Zhou, P., Bhagavatula, C., Choi, Y., and Ren, X. C ommon G en: A constrained text generation challenge for generative commonsense reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2020, pp.\ 1823--1840, Online, November 2020. Association for Computational Linguistics
2020
-
[14]
H., Loula, J., MacIver, D
Lipkin, B., LeBrun, B., Vigly, J. H., Loula, J., MacIver, D. R., Du, L., Eisner, J., Cotterell, R., Mansinghka, V., O'Donnell, T. J., Lew, A. K., and Vieira, T. Fast controlled generation from language models with adaptive weighted rejection sampling. In The Second Conference on Language Modeling, 2025
2025
-
[15]
C., Wang, H., Heinecke, S., and Xiong, C
Liu, Z., Hoang, T., Zhang, J., Zhu, M., Lan, T., Kokane, S., Tan, J., Yao, W., Liu, Z., Feng, Y., Murthy, R., Yang, L., Savarese, S., Niebles, J. C., Wang, H., Heinecke, S., and Xiong, C. Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets. In Advances in Neural Information Processing Systems, 2024
2024
-
[16]
What is the relationship between tensor factorizations and circuits (and how can we exploit it)? Transactions on Machine Learning Research, 2025, 2025
Loconte, L., Mari, A., Gala, G., Peharz, R., de Campos, C., Quaeghebeur, E., Vessio, G., and Vergari, A. What is the relationship between tensor factorizations and circuits (and how can we exploit it)? Transactions on Machine Learning Research, 2025, 2025
2025
-
[17]
K., Vieira, T., and O'Donnell, T
Loula, J., LeBrun, B., Du, L., Lipkin, B., Pasti, C., Grand, G., Liu, T., Emara, Y., Freedman, M., Eisner, J., Cotterell, R., Mansinghka, V., Lew, A. K., Vieira, T., and O'Donnell, T. J. Syntactic and semantic control of large language models via sequential monte carlo. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[18]
Bounding the capabilities of large language models in open text generation with prompt constraints
Lu, A., Zhang, H., Zhang, Y., Wang, X., and Yang, D. Bounding the capabilities of large language models in open text generation with prompt constraints. In Findings of the Association for Computational Linguistics: EACL 2023, 2023
2023
-
[19]
Controllable text generation with neurally-decomposed oracle
Meng, T., Lu, S., Peng, N., and Chang, K.-W. Controllable text generation with neurally-decomposed oracle. In Advances in Neural Information Processing Systems 35, 2022
2022
-
[20]
F., Leike, J., and Lowe, R
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback. In Advances in Neural Information Proces...
2022
-
[21]
Bleu: a method for automatic evaluation of machine translation
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (ACL), 2002
2002
-
[22]
Grammar-aligned decoding
Park, K., Wang, J., Berg-Kirkpatrick, T., Polikarpova, N., and D Antoni, L. Grammar-aligned decoding. In Advances in Neural Information Processing Systems, 2024
2024
-
[23]
Flexible and efficient grammar-constrained decoding
Park, K., Zhou, T., and D'Antoni, L. Flexible and efficient grammar-constrained decoding. arXiv preprint arXiv:2502.05111, 2025
-
[24]
G., Zhang, T., Wang, X., and Gonzalez, J
Patil, S. G., Zhang, T., Wang, X., and Gonzalez, J. E. Gorilla: Large language model connected with massive apis. In Advances in Neural Information Processing Systems, 2024
2024
-
[25]
G., Mao, H., Yan, F., Ji, C
Patil, S. G., Mao, H., Yan, F., Ji, C. C.-J., Suresh, V., Stoica, I., and Gonzalez, J. E. The berkeley function calling leaderboard ( BFCL ): From tool use to agentic evaluation of large language models. In Forty-second International Conference on Machine Learning, 2025
2025
-
[26]
Synchromesh: Reliable code generation from pre-trained language models
Poesia, G., Polozov, A., Le, V., Tiwari, A., Soares, G., Meek, C., and Gulwani, S. Synchromesh: Reliable code generation from pre-trained language models. In The Eleventh International Conference on Learning Representations, 2022
2022
-
[27]
Cold decoding: Energy-based constrained text generation with langevin dynamics
Qin, L., Welleck, S., Khashabi, D., and Choi, Y. Cold decoding: Energy-based constrained text generation with langevin dynamics. In Advances in Neural Information Processing Systems, 2022
2022
-
[28]
and Juang, B
Rabiner, L. and Juang, B. An introduction to hidden markov models. IEEE ASSP Magazine, 3 0 (1), 1986
1986
-
[29]
D., Ermon, S., and Finn, C
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems, 2023
2023
-
[30]
PICARD : Parsing incrementally for constrained auto-regressive decoding from language models
Scholak, T., Schucher, N., and Bahdanau, D. PICARD : Parsing incrementally for constrained auto-regressive decoding from language models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2021
2021
-
[31]
Tractable operations for arithmetic circuits of probabilistic models
Shen, Y., Choi, A., and Darwiche, A. Tractable operations for arithmetic circuits of probabilistic models. Advances in Neural Information Processing Systems, 29, 2016
2016
-
[32]
A., Pauls, A., Klein, D., Eisner, J., and Van Durme, B
Shin, R., Lin, C., Thomson, S., Chen, C., Roy, S., Platanios, E. A., Pauls, A., Klein, D., Eisner, J., and Van Durme, B. Constrained language models yield few-shot semantic parsers. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2021
2021
-
[33]
Syncode: LLM generation with grammar augmentation
Ugare, S., Suresh, T., Kang, H., Misailovic, S., and Singh, G. Syncode: LLM generation with grammar augmentation. Transactions on Machine Learning Research, 2025
2025
-
[34]
A compositional atlas of tractable circuit operations for probabilistic inference
Vergari, A., Choi, Y., Liu, A., Teso, S., and Van den Broeck, G. A compositional atlas of tractable circuit operations for probabilistic inference. Advances in Neural Information Processing Systems, 34: 0 13189--13201, 2021
2021
-
[35]
W., Lester, B., Du, N., Dai, A
Wei, J., Bosma, M., Zhao, V., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V. Finetuned language models are zero-shot learners. In The Eleventh International Conference on Learning Representations, 2022
2022
-
[36]
Willard, B. T. and Louf, R. Efficient guided generation for large language models. arXiv e-prints, pp.\ arXiv--2307, 2023
2023
-
[37]
and Klein, D
Yang, K. and Klein, D. Fudge: Controlled text generation with future discriminators. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), 2021
2021
-
[38]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Yao, S., Shinn, N., Razavi, P., and Narasimhan, K. -bench: A benchmark for tool-agent-user interaction in real-world domains. arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
S pider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to- SQL task
Yu, T., Zhang, R., Yang, K., Yasunaga, M., Wang, D., Li, Z., Ma, J., Li, I., Yao, Q., Roman, S., Zhang, Z., and Radev, D. S pider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to- SQL task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018
2018
-
[40]
Tractable control for autoregressive language generation
Zhang, H., Dang, M., Peng, N., and Van Den Broeck, G. Tractable control for autoregressive language generation. In The Fortieth International Conference on Machine Learning, 2023
2023
-
[41]
Adaptable logical control for large language models
Zhang, H., Kung, P.-N., Yoshida, M., Van den Broeck, G., and Peng, N. Adaptable logical control for large language models. In Advances in Neural Information Processing Systems, 2024
2024
-
[42]
Zhang, H., Dang, M., Wang, B., Ermon, S., Peng, N., and den Broeck, G. V. Scaling probabilistic circuits via monarch matrices. In The Forty-second International Conference on Machine Learning, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.