Scaling LLM Inference Beyond Amdahl`s Limits via Eliminating Non-Scalable Overheads
Pith reviewed 2026-06-28 12:46 UTC · model grok-4.3
The pith
Albireo overlaps scheduling and I/O with compute to raise the optimal tensor parallelism degree for LLM inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Albireo is a parallel inference system that raises the attainable t_e by shrinking the non-scalable portion via overlap of scheduling and I/O with compute and sequence-parallel sampling, without changing model architectures. Across models and benchmarks it delivers up to 1.9x higher throughput, 48% lower latency, 28% higher GPU utilization, and 54% lower energy than vLLM, with up to 2x throughput in production.
What carries the argument
Overlap of scheduling and I/O with compute through sequence-parallel sampling, which reduces the non-scalable fraction of tensor-parallel execution.
If this is right
- Higher tensor parallelism degrees become usable without the usual scaling penalty.
- Cluster-wide throughput increases up to 1.9x on the same number of GPUs.
- Latency drops by up to 48% while GPU utilization rises by 28%.
- Energy consumption falls by up to 54% compared with baseline systems.
- Production deployments see up to 2x throughput improvement.
Where Pith is reading between the lines
- The overlap approach could extend to other parallelism types such as pipeline or data parallelism in inference.
- Data-center operators might reduce hardware needs or power draw for the same service level.
- Standard inference engines could adopt similar overlap patterns as defaults rather than custom systems.
Load-bearing premise
The non-scalable overheads in tensor-parallel execution can be overlapped with compute without creating correctness problems or new bottlenecks.
What would settle it
Running the system on real production traffic at scale and measuring whether the reported throughput and latency gains persist or if new bottlenecks appear.
Figures

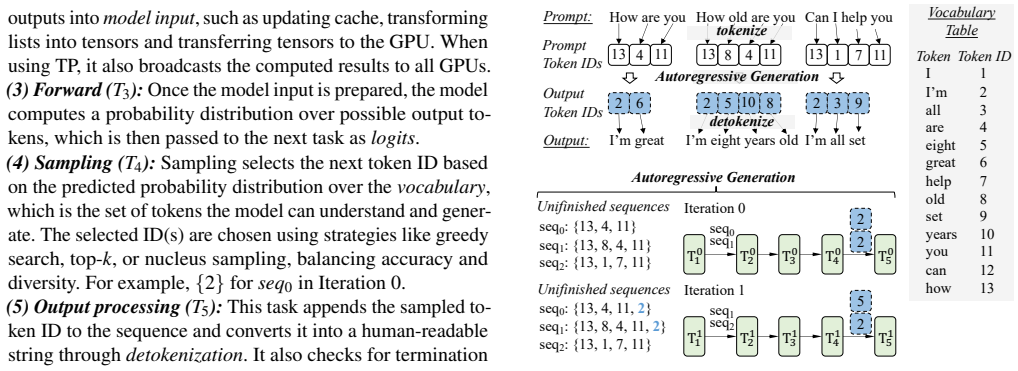


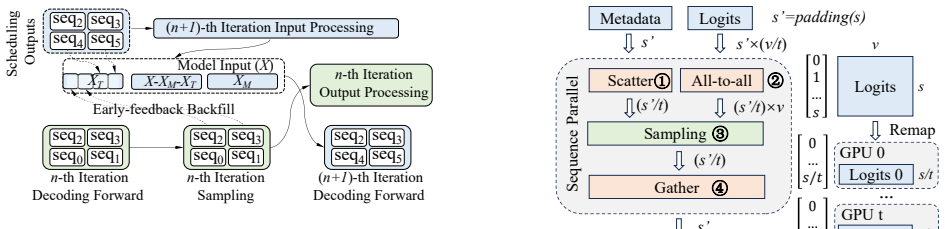









read the original abstract
Deployers of online LLM services usually seek to maximize cluster-wide performance given a fixed number of GPUs. Tensor parallelism (TP) is necessary to fit modern models but scales sub-linearly as the TP degree t grows, due to cross-GPU communication and non-scalable runtime work, as predicted by Amdahl's Law. Conversely, increasing t improves memory efficiency and alleviates KV-cache contention and swapping. We identify and validate an empirical optimal TP degree t_e that balances these effects. We present Albireo, a parallel inference system that raises the attainable t_e by shrinking the non-scalable portion via overlap of scheduling and I/O with compute and sequence-parallel sampling, without changing model architectures. Across models and benchmarks, Albireo achieves up to 1.9x higher throughput, 48% lower latency, 28% higher GPU utilization, and 54% lower energy than vLLM; in production it yields up to 2x higher throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that tensor parallelism (TP) in LLM inference scales sub-linearly due to communication and non-scalable runtime overheads per Amdahl's law, but an empirical optimal TP degree t_e exists that balances this against memory-efficiency gains; Albireo raises attainable t_e by overlapping scheduling, I/O, and sequence-parallel sampling with tensor-parallel compute (without architecture changes), yielding up to 1.9× throughput, 48% lower latency, 28% higher GPU utilization, and 54% lower energy versus vLLM across models/benchmarks, plus up to 2× throughput in production.
Significance. If the overlap mechanism is validated to materially shrink the non-scalable fraction without new contention bottlenecks, the result would be significant for practical LLM serving: it offers a systems-level path to higher effective TP degrees on fixed GPU clusters, improving cluster-wide throughput and energy efficiency. The work is credited for providing concrete cross-model empirical measurements against a production baseline (vLLM) rather than purely analytical predictions.
major comments (2)
- [Abstract] Abstract: the central claim that Albireo raises attainable t_e by shrinking the non-scalable portion rests on the reported speedups, yet the abstract supplies no benchmark details, workload characteristics, error bars, or ablation studies; this is load-bearing because it prevents verification that gains derive from the overlap technique rather than workload selection or tuning.
- [Abstract] Abstract: no per-component timelines or overlap-efficiency metrics are provided to confirm that scheduling/I/O/sequence-parallel sampling can be overlapped with tensor-parallel kernels without residual serial time from resource contention (e.g., NVLink/PCIe saturation or CUDA-stream conflicts at high TP); this directly affects whether the measured 1.9× throughput and 2× production gains are consistent with the claimed reduction below the new Amdahl limit.
minor comments (1)
- [Title] Title: 'Amdahl`s' uses a backtick rather than a standard apostrophe; correct for typographic consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and propose targeted revisions to improve clarity while preserving the abstract's conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Albireo raises attainable t_e by shrinking the non-scalable portion rests on the reported speedups, yet the abstract supplies no benchmark details, workload characteristics, error bars, or ablation studies; this is load-bearing because it prevents verification that gains derive from the overlap technique rather than workload selection or tuning.
Authors: We agree the abstract is concise and could better contextualize the empirical results. The full paper reports benchmarks on Llama-7B/70B, OPT-66B, and Mixtral-8x7B using ShareGPT and synthetic workloads (Section 4), with error bars from 5+ runs, ablations isolating the overlap contributions (Section 5.2), and production traces (Section 6). We will revise the abstract to name the primary models and workloads evaluated and to note that detailed ablations and statistical reporting appear in the body. revision: yes
-
Referee: [Abstract] Abstract: no per-component timelines or overlap-efficiency metrics are provided to confirm that scheduling/I/O/sequence-parallel sampling can be overlapped with tensor-parallel kernels without residual serial time from resource contention (e.g., NVLink/PCIe saturation or CUDA-stream conflicts at high TP); this directly affects whether the measured 1.9× throughput and 2× production gains are consistent with the claimed reduction below the new Amdahl limit.
Authors: Section 4.3 and Figure 7 already present per-component timelines, measured overlap efficiency (>85% for scheduling/I/O), and utilization traces confirming no new contention on NVLink/PCIe or CUDA streams at TP=8. These measurements directly support the Amdahl-limit claim. To tie the abstract claim more explicitly to this evidence, we will add a short clause referencing the overlap metrics and will ensure the abstract points readers to the supporting section. revision: partial
Circularity Check
No significant circularity; claims rest on empirical measurements vs. vLLM
full rationale
The paper identifies an empirical optimal TP degree t_e through validation and presents Albireo gains as direct throughput/latency/utilization/energy measurements against vLLM baselines. No equations, fitted parameters, or self-citations are shown reducing a central prediction or uniqueness claim to its own inputs by construction. The derivation chain is self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tensor parallelism is necessary to fit modern models
Reference graph
Works this paper leans on
-
[1]
Taming throughput- latency tradeoff in llm inference with sarathi-serve
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tu- manov, and Ramachandran Ramjee. Taming throughput- latency tradeoff in llm inference with sarathi-serve. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 117–134, Santa Clara, CA, July 2024. USENIX Association
2024
-
[2]
Adithya Bhaskar, Alexander Wettig, Tianyu Gao, Yihe Dong, and Danqi Chen. Cache me if you can: How many kvs do you need for effective long-context lms? arXiv preprint arXiv:2506.17121, 2025
arXiv 2025
-
[3]
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling. arXiv preprint arXiv:2406.02069, 2024
Pith/arXiv arXiv 2024
-
[4]
Llm-inference-bench: Inference bench- marking of large language models on ai accelerators
Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus, Aditya Tanikanti, Ken Raf- fenetti, Valerie Taylor, Murali Emani, and Venkatram Vishwanath. Llm-inference-bench: Inference bench- marking of large language models on ai accelerators. In SC24-W: Workshops of the International Conference for High Performance Computing, Networking,...
2024
-
[5]
Databricks. Databricks-dolly-15k is an open source dataset of instruction-following records generated by thousands of Databricks employees in several of the behavioral categories outlined in the InstructGPT paper,
-
[6]
https://huggingface.co/datasets/databr icks/databricks-dolly-15k
-
[7]
Dell. Llama 2. https://infohub.delltechnologi es.com/ja-jp/l/llama-2-inferencing-on-a-s ingle-gpu/introduction-3976/, 2025
2025
-
[8]
Serverlessllm: Low-latency serverless inference for large language models
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. Serverlessllm: Low-latency serverless inference for large language models. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 135–153. USENIX Association, 2024
2024
-
[9]
A new algorithm for data compression
Philip Gage. A new algorithm for data compression. The C Users Journal, 12(2):23–38, 1994
1994
-
[10]
Cost-efficient large language model serving for multi-turn conversations with cachedatten- tion
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. Cost-efficient large language model serving for multi-turn conversations with cachedatten- tion. In2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 111–126, 2024
2024
-
[11]
Elsevier, 2011
John L Hennessy and David A Patterson.Computer architecture: a quantitative approach. Elsevier, 2011
2011
-
[12]
An integrated GPU power and performance model
Sunpyo Hong and Hyesoon Kim. An integrated GPU power and performance model. InProceedings of the 37th annual international symposium on Computer ar- chitecture, pages 280–289, 2010
2010
-
[13]
Fastkv: Kv cache compression for fast long- context processing with token-selective propagation
Dongwon Jo, Jiwon Song, Yulhwa Kim, and Jae-Joon Kim. Fastkv: Kv cache compression for fast long- context processing with token-selective propagation. arXiv preprint arXiv:2502.01068, 2025
Pith/arXiv arXiv 2025
-
[14]
Kamath, Ramya Prabhu, Jayashree Mohan, Si- mon Peter, Ramachandran Ramjee, and Ashish Panwar
Aditya K. Kamath, Ramya Prabhu, Jayashree Mohan, Si- mon Peter, Ramachandran Ramjee, and Ashish Panwar. Pod-attention: Unlocking full prefill-decode overlap for faster llm inference. InProceedings of ASPLOS ’25, Rotterdam, Netherlands, 2025. ACM
2025
-
[15]
Reducing activation recomputation in large transformer models.Proceed- ings of Machine Learning and Systems, 5, 2023
Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation recomputation in large transformer models.Proceed- ings of Machine Learning and Systems, 5, 2023
2023
-
[16]
SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing
Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Eduardo Blanco and Wei Lu, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71, Brus- sels, Belgium, November 2018. Association for C...
2018
-
[17]
Ilya Kulikov, Alexander H Miller, Kyunghyun Cho, and Jason Weston. Importance of a search strategy in neural dialogue modelling.arXiv preprint arXiv:1811.00907, 2, 2018
arXiv 2018
-
[18]
Efficient memory man- agement for large language model serving with page- dattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, 12 Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with page- dattention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
2023
-
[19]
Infinigen: Efficient generative inference of large language models with dynamic KV cache management
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. Infinigen: Efficient generative inference of large language models with dynamic KV cache management. In18th USENIX Symposium on Operating Systems De- sign and Implementation (OSDI 24), pages 155–172, Santa Clara, CA, July 2024. USENIX Association
2024
-
[20]
Snapkv: LLM knows what you are looking for before generation.arXiv preprint arXiv:2404.14469, 2024
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: LLM knows what you are looking for before generation.arXiv preprint arXiv:2404.14469, 2024
Pith/arXiv arXiv 2024
-
[21]
Deepseek-v2: A strong, econom- ical, and efficient mixture-of-experts language model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, econom- ical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434, 2024
Pith/arXiv arXiv 2024
-
[22]
Deepseek-v3 techni- cal report.arXiv preprint arXiv:2412.19437, 2024
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 techni- cal report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[23]
Cachegen: Kv cache compression and streaming for fast large lan- guage model serving
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, et al. Cachegen: Kv cache compression and streaming for fast large lan- guage model serving. InProceedings of the ACM SIG- COMM 2024 Conference, pages 38–56, 2024
2024
-
[24]
meta-llama/Llama-2-7b
Meta. meta-llama/Llama-2-7b. https://huggingfac e.co/meta-llama/Llama-2-7b, 2025
2025
-
[25]
Deepspeed, 2024
Microsoft. Deepspeed, 2024. https://github.com /microsoft/DeepSpeed
2024
-
[26]
OpenAI API Documentation
OpenAI. OpenAI API Documentation. https://platform.openai.com/docs, 2025
2025
-
[27]
Training language models to follow instructions with human feedback.Advances in Neural Information Pro- cessing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Pro- cessing Systems, 35:27730–27744, 2022
2022
-
[28]
The carbon footprint of machine learning training will plateau, then shrink, 2022
David Patterson, Joseph Gonzalez, Urs Hölzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. The carbon footprint of machine learning training will plateau, then shrink, 2022
2022
-
[29]
Zipf’s word frequency law in natural language: A critical review and future directions
Steven T Piantadosi. Zipf’s word frequency law in natural language: A critical review and future directions. Psychonomic bulletin & review, 21(5):1112–1130, 2014
2014
-
[30]
vattention: Dynamic memory management for serving llms with- out pagedattention
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ra- machandran Ramjee, and Ashish Panwar. vattention: Dynamic memory management for serving llms with- out pagedattention. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol- ume 1, pages 1133–1150, 2025
2025
-
[31]
pickle — python object serialization, 2024
Python. pickle — python object serialization, 2024. https://docs.python.org/3/library/pickle.h tml
2024
-
[32]
Asynchronous I/O
Python. Asynchronous I/O. https://docs.python. org/3/library/asyncio.html, 2025
2025
-
[33]
Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX Confer- ence on File and Storage Technologies (FAST 25), pages 155–170, 2025
2025
-
[34]
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbig- niew Kalbarczyk, Tamer Ba¸ sar, and Ravishankar K. Iyer. Power-aware deep learning model serving with u-Serve. In2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 75–93, Santa Clara, CA, July
-
[35]
Neural machine translation of rare words with subword units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In Katrin Erk and Noah A. Smith, editors,Pro- ceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany, August 2016. As- sociation for Computational Linguistics
2016
-
[36]
Sglang: Zero-overhead batch scheduler
SGLang. Sglang: Zero-overhead batch scheduler. http s://lmsys.org/blog/2024-12-04-sglang-v0-4/ , 2024
2024
-
[37]
Sglang: Benchmark and profiling
SGLang. Sglang: Benchmark and profiling. https: //docs.sglang.ai/developer_guide/benchmark _and_profiling.html, 2025
2025
-
[38]
Sglang documentation, 2025
SGLang. Sglang documentation, 2025. https://docs .sglang.ai/index.html
2025
-
[39]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter lan- guage models using model parallelism.arXiv preprint arXiv:1909.08053, 2019. 13
Pith/arXiv arXiv 1909
-
[40]
Llumnix: Dynamic scheduling for large language model serving
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. Llumnix: Dynamic scheduling for large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 173–191, Santa Clara, CA, July 2024. USENIX Association
2024
-
[41]
Kimi k2: Open agen- tic intelligence.arXiv preprint arXiv:2507.20534, 2025
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Ji- ahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agen- tic intelligence.arXiv preprint arXiv:2507.20534, 2025
Pith/arXiv arXiv 2025
-
[42]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024
2024
-
[43]
QwQ: Reflect deeply on the boundaries of the unknown
Qwen Team. QwQ: Reflect deeply on the boundaries of the unknown. https://qwenlm.github.io/blog/qw q-32b-preview/, 2025
2025
-
[44]
Llama 2: Open foundation and fine-tuned chat models, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Al- bert, Amjad Almahairi, Yasmine Babaei, Nikolay Bash- lykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernan- des, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony...
2023
-
[45]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[46]
vLLM Asynchronous Scheduling
vLLM. vLLM Asynchronous Scheduling. https: //github.com/vllm-project/vllm/pull/24799 , 2025
2025
-
[47]
vllm: Optimization and tuning, 2025
vLLM. vllm: Optimization and tuning, 2025. https: //docs.vllm.ai/en/latest/configuration/opt imization.html
2025
-
[48]
vllm: Parallelism and scaling, 2025
vLLM. vllm: Parallelism and scaling, 2025. https: //docs.vllm.ai/en/latest/serving/paralleli sm_scaling.html
2025
-
[49]
Efficient streaming lan- guage models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming lan- guage models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
Pith/arXiv arXiv 2023
-
[50]
Jiaming Xu, Jiayi Pan, Yongkang Zhou, Siming Chen, Jinhao Li, Yaoxiu Lian, Junyi Wu, and Guohao Dai. Specee: Accelerating large language model infer- ence with speculative early exiting.arXiv preprint arXiv:2504.08850, 2025. Accepted by ISCA 2025
arXiv 2025
-
[51]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. Flashinfer: Efficient and customizable atten- tion engine for llm inference serving.arXiv preprint arXiv:2501.01005, 2025
Pith/arXiv arXiv 2025
-
[52]
Orca: A distributed serving system for transformer-based generative mod- els
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for transformer-based generative mod- els. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, 2022
2022
-
[53]
Ahmet Caner Yüzügüler, Jiawei Zhuang, and Lukas Cavigelli. Preserve: Prefetching model weights and kv-cache in distributed llm serving.arXiv preprint arXiv:2501.08192, 2025
arXiv 2025
-
[54]
Hossein Entezari Zarch, Lei Gao, Chaoyi Jiang, and Mu- rali Annavaram. Del: Context-aware dynamic exit layer for efficient self-speculative decoding.arXiv preprint arXiv:2504.05598, 2025
arXiv 2025
-
[55]
H2o: Heavy- hitter oracle for efficient generative inference of large language models.Advances in Neural Information Pro- cessing Systems, 36:34661–34710, 2023
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy- hitter oracle for efficient generative inference of large language models.Advances in Neural Information Pro- cessing Systems, 36:34661–34710, 2023
2023
-
[56]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model pro- grams.arXiv preprint arXiv:2312.07104, 2024
Pith/arXiv arXiv 2024
-
[57]
Dist- serve: Disaggregating prefill and decoding for goodput- optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Dist- serve: Disaggregating prefill and decoding for goodput- optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, Santa Clara, CA, July 2024. USENIX Association. 14
2024
-
[58]
Benchmarking LLM inference backends: vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and TGI, 2024
Rick Zhou. Benchmarking LLM inference backends: vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and TGI, 2024. https://bentoml.com/blog/benchmark ing-llm-inference-backends
2024
-
[59]
{NanoFlow}: Towards opti- mal large language model serving throughput
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Zihao Ye, Keisuke Kama- hori, Chien-Yu Lin, et al. {NanoFlow}: Towards opti- mal large language model serving throughput. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 749–765, 2025. 15 Seq Seq Output Processor Update Sequence Stop Chec...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.