Unified Driving Tokens: Representation- and Geometry-Guided Discrete Tokenizer for Driving World Models and Planning
Pith reviewed 2026-06-28 15:28 UTC · model grok-4.3
The pith
A tokenizer for driving scenes learns discrete tokens by aligning them to DINO features while adding depth and pose supervision to support world models and planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
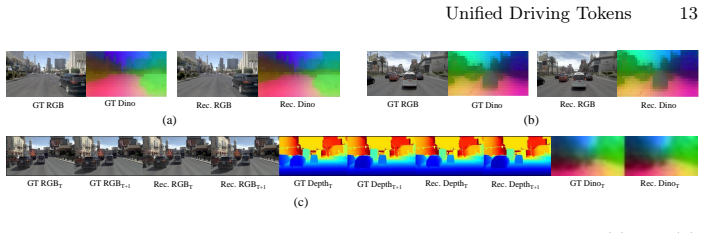
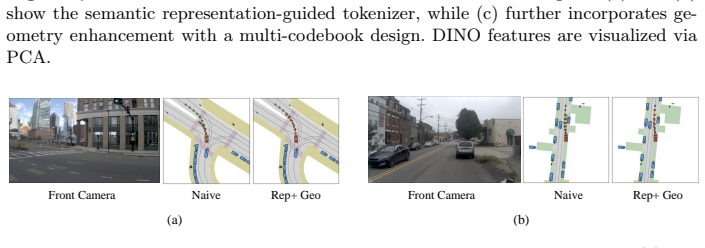
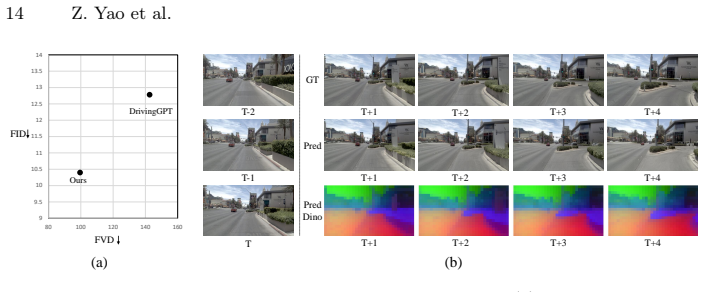
The representation-guided and geometry-enhanced tokenizer learns discrete tokens under joint supervision that yield improved reconstruction fidelity and representation consistency, competitive planning performance under a fixed decoder, and better generative quality under matched settings on NAVSIM.
What carries the argument
The discrete bottleneck aligned to a frozen DINO feature space through feature decoding, combined with adjacent-frame depth and relative-pose supervision and stabilized by multi-codebook quantization.
If this is right
- Tokens achieve improved reconstruction fidelity on NAVSIM.
- Tokens exhibit better representation consistency across frames.
- Planning performance remains competitive when the decoder is held fixed.
- Generative quality improves in next-token world modeling under matched settings.
Where Pith is reading between the lines
- If the tokens better encode geometric state, world models built on them could maintain accuracy over longer prediction horizons without additional fine-tuning.
- The same joint-supervision recipe might transfer to other sensor inputs such as radar or event cameras to enrich the geometric signal.
- Higher cross-frame consistency could reduce drift when these tokens are used for closed-loop planning in extended driving sequences.
- Because the decoder can stay fixed, the approach may lower the compute cost of adapting planners to new vehicle platforms.
Load-bearing premise
Aligning the discrete bottleneck with a frozen DINO feature space through feature decoding, together with adjacent-frame depth and relative-pose supervision, will produce tokens more useful for driving decisions than standard image-generation tokenizers optimized only for pixel reconstruction.
What would settle it
A head-to-head test in which the proposed tokenizer and a standard reconstruction-only tokenizer are each used to train identical world models and planners on NAVSIM, with the new tokenizer showing no gains in planning success rate or generative metrics.
Figures

read the original abstract
Discrete visual tokens should provide a compact representation for both token-based world modeling and planning in autonomous driving. However, most tokenizers are inherited from image generation and are optimized mainly for pixel reconstruction, which may leave a gap between what is easy to generate and what is useful to decode for driving decisions. We present a representation-guided and geometry-enhanced tokenizer that learns discrete tokens under joint supervision. The tokenizer aligns its discrete bottleneck with a frozen DINO feature space through feature decoding, while preserving appearance via RGB reconstruction with perceptual and adversarial losses. To inject geometric state-related cues, we add adjacent-frame depth and relative-pose supervision during training and stabilize joint objectives with multi-codebook quantization. We evaluate the same learned tokens with a lightweight planning readout and a GPT-style next-token world model. Experiments on NAVSIM show improved reconstruction fidelity and representation consistency, competitive planning performance under a fixed decoder, and better generative quality under matched settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a representation-guided and geometry-enhanced discrete tokenizer (UDT) for driving world models and planning. The tokenizer aligns its discrete bottleneck to a frozen DINO feature space via feature decoding, preserves appearance through RGB reconstruction with perceptual and adversarial losses, injects geometric cues via adjacent-frame depth and relative-pose supervision, and stabilizes training with multi-codebook quantization. The same tokens are evaluated via a lightweight planning readout and a GPT-style next-token world model, with experiments on NAVSIM reporting improved reconstruction fidelity, representation consistency, competitive planning performance under a fixed decoder, and better generative quality under matched settings relative to standard image-generation tokenizers.
Significance. If the empirical claims hold, the work addresses a practical gap between pixel-reconstruction tokenizers and tokens useful for driving decisions, potentially benefiting token-based world models and planners in autonomous driving. The joint supervision strategy, use of frozen external models (DINO), and evaluation protocol with a fixed decoder plus matched generative settings are clear strengths that support reproducibility and direct comparison.
minor comments (3)
- [§3] §3 (Method): the description of multi-codebook quantization and its role in stabilizing the joint DINO/depth/pose objectives would benefit from an explicit equation or diagram showing codebook assignment and loss weighting.
- [Table 2 / §4.2] Table 2 / §4.2: the planning readout results should report the exact decoder architecture and whether any hyper-parameters were re-tuned when swapping tokenizers, to confirm the 'fixed decoder' claim.
- [§4.3] §4.3: the generative quality comparison would be strengthened by stating the exact number of tokens per frame and the context length used for the GPT-style model.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our Unified Driving Tokens work, the recognition of its strengths in joint supervision and evaluation protocol, and the recommendation for minor revision. No major comments appear in the provided report.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical training procedure for a discrete tokenizer that incorporates external frozen DINO features, RGB reconstruction losses, adjacent-frame depth, and relative-pose supervision, stabilized by multi-codebook quantization. These are independent inputs, not derived from the tokenizer outputs themselves. Evaluation proceeds via separate planning readout and world-model experiments on NAVSIM with matched baselines; no equation or claim reduces a prediction to a fitted parameter by construction, nor does any load-bearing premise rest on self-citation chains. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
Discrete-WAM unifies world modeling and policy learning for autonomous driving by representing observations, states, decisions, and actions as tokens in one space and using hierarchical token editing for planning.
Reference graph
Works this paper leans on
-
[1]
In: Advances in Neural Information Processing Systems (2020) Unified Driving Tokens 15
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. In: Advances in Neural Information Processing Systems (2020) Unified Driving Tokens 15
2020
-
[2]
arXiv preprint arXiv:2106.11810 (2021)
Caesar, H., Kabzan, J., Tan, K.S., Fong, W.K., Wolff, E., Lang, A., Fletcher, L., Beijbom, O., Omari, S.: nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810 (2021)
Pith/arXiv arXiv 2021
-
[3]
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: Masked genera- tiveimagetransformer.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[4]
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H.: End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence46, 10164–10183 (2024).https://doi.org/10.1109/TPAMI. 2024.3435937
-
[5]
arXiv preprint arXiv:2402.13243 (2024)
Chen,S.,Jiang,B.,Gao,H.,Liao,B.,Xu,Q.,Zhang,Q.,Huang,C.,Liu,W.,Wang, X.: Vadv2: End-to-end vectorized autonomous driving via probabilistic planning. arXiv preprint arXiv:2402.13243 (2024)
Pith/arXiv arXiv 2024
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Y., Wang, Y., Zhang, Z.: Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 26890–26900 (2025)
2025
-
[7]
IEEE trans- actions on pattern analysis and machine intelligence45(11), 12878–12895 (2022)
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A.: Transfuser: Imi- tation with transformer-based sensor fusion for autonomous driving. IEEE trans- actions on pattern analysis and machine intelligence45(11), 12878–12895 (2022)
2022
-
[8]
In: Proceedings of the Conference on Com- puter Vision and Pattern Recognition, Vancouver, Canada
Contributors, O.: Openscene: The largest up-to-date 3d occupancy prediction benchmark in autonomous driving. In: Proceedings of the Conference on Com- puter Vision and Pattern Recognition, Vancouver, Canada. pp. 18–22 (2023)
2023
-
[9]
Advances in Neural Information Processing Systems37, 28706–28719 (2024)
Dauner, D., Hallgarten, M., Li, T., Weng, X., Huang, Z., Yang, Z., Li, H., Gilitschenski, I., Ivanovic, B., Pavone, M., et al.: Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. Advances in Neural Information Processing Systems37, 28706–28719 (2024)
2024
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[11]
arXiv preprint arXiv:2501.11260 (2025)
Feng, T., Wang, W., Yang, Y.: A survey of world models for autonomous driving. arXiv preprint arXiv:2501.11260 (2025)
arXiv 2025
-
[12]
In: Advances in Neural Information Processing Systems (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems (2020)
2020
-
[13]
arXiv preprint arXiv:2309.17080 (2023)
Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., Corrado, G.: Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 (2023)
Pith/arXiv arXiv 2023
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17853– 17862 (2023)
2023
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Lee, D., Kim, C., Kim, S., Cho, M., Han, W.S.: Autoregressive image genera- tion using residual quantization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[16]
arXiv preprint arXiv:2503.12820 (2025)
Li, K., Li, Z., Lan, S., Xie, Y., Zhang, Z., Liu, J., Wu, Z., Yu, Z., Alvarez, J.M.: Hydra-mdp++: Advancing end-to-end driving via expert-guided hydra-distillation. arXiv preprint arXiv:2503.12820 (2025)
arXiv 2025
-
[17]
arXiv preprint arXiv:2510.12796 (2025) 16 Z
Li, Y., Shang, S., Liu, W., Zhan, B., Wang, H., Wang, Y., Chen, Y., Wang, X., An, Y., Tang, C., et al.: Drivevla-w0: World models amplify data scaling law in autonomous driving. arXiv preprint arXiv:2510.12796 (2025) 16 Z. Yao et al
Pith/arXiv arXiv 2025
-
[18]
Li, Y., Wang, Y., Liu, Y., He, J., Fan, L., Zhang, Z.: End-to-end driving with onlinetrajectoryevaluationviabevworldmodel.In:ProceedingsoftheIEEE/CVF International Conference on Computer Vision. pp. 27137–27146 (2025)
2025
-
[19]
Liao, B., Chen, S., Yin, H., Jiang, B., Wang, C., Yan, S., Zhang, X., Li, X., Zhang, Y., Zhang, Q., et al.: Diffusiondrive: Truncated diffusion model for end-to-end au- tonomousdriving.In:ProceedingsoftheComputerVisionandPatternRecognition Conference. pp. 12037–12047 (2025)
2025
-
[20]
In: Advances in Neu- ral Information Processing Systems (2025),https://openreview.net/forum?id= f6aOPkGE8L
Ma, C., Jiang, Y., Wu, J., Yang, J., Yu, X., Yuan, Z., Peng, B., Qi, X.: Unitok: A unified tokenizer for visual generation and understanding. In: Advances in Neu- ral Information Processing Systems (2025),https://openreview.net/forum?id= f6aOPkGE8L
2025
-
[21]
arXiv preprint arXiv:2507.13162 (2025)
Mousakhan, A., Mittal, S., Galesso, S., Farid, K., Brox, T.: Orbis: Overcom- ing challenges of long-horizon prediction in driving world models. arXiv preprint arXiv:2507.13162 (2025)
arXiv 2025
-
[23]
In: Advances in Neural Information Processing Systems (2017)
van den Oord, A., Vinyals, O., Kavukcuoglu, K.: Neural discrete representation learning. In: Advances in Neural Information Processing Systems (2017)
2017
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
2023
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Qu, L., Zhang, H., Liu, Y., Wang, X., Jiang, Y., Gao, Y., Ye, H., Du, D.K., Yuan, Z., Wu, X.: Tokenflow: Unified image tokenizer for multimodal understanding and generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[28]
arXiv preprint arXiv:2508.10104 (2025)
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
Pith/arXiv arXiv 2025
-
[29]
arXiv preprint arXiv:2104.09864 (2021)
Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. arXiv preprint arXiv:2104.09864 (2021)
Pith/arXiv arXiv 2021
-
[30]
arXiv preprint arXiv:2406.06525 (2024)
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
Pith/arXiv arXiv 2024
-
[31]
In: Advances in Neural Information Processing Systems (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (2017)
2017
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Wang, J., Vedaldi, A., Zisserman, A., et al.: Vggt: Visual geometry grounded trans- former. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Wang, Y., He, J., Fan, L., Li, H., Chen, Y., Zhang, Z.: Driving into the future: Mul- tiview visual forecasting and planning with world model for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Weng, X., Ivanovic, B., Wang, Y., Wang, Y., Pavone, M.: Para-drive: Parallelized architecture for real-time autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15449–15458 (2024) Unified Driving Tokens 17
2024
-
[35]
arXiv preprint arXiv:2512.23421 (2025)
Xia, T., Li, Y., Zhou, L., Yao, J., Xiong, K., Sun, H., Wang, B., Ma, K., Chen, G., Ye, H., et al.: Drivelaw: Unifying planning and video generation in a latent driving world. arXiv preprint arXiv:2512.23421 (2025)
Pith/arXiv arXiv 2025
-
[36]
arXiv preprint arXiv:2506.06659 (2025)
Yao, W., Li, Z., Lan, S., Wang, Z., Sun, X., Alvarez, J.M., Wu, Z.: Drivesuprim: Towards precise trajectory selection for end-to-end planning. arXiv preprint arXiv:2506.06659 (2025)
arXiv 2025
-
[37]
arXiv preprint arXiv:2408.03601 (2024)
Yuan, C., Zhang, Z., Sun, J., Sun, S., Huang, Z., Lee, C.D.W., Li, D., Han, Y., Wong, A., Tee, K.P., et al.: Drama: An efficient end-to-end motion planner for autonomous driving with mamba. arXiv preprint arXiv:2408.03601 (2024)
arXiv 2024
-
[38]
arXiv preprint arXiv:2602.10884 (2026)
Zhang, J., Fu, Z., Xu, Z., Dai, W., Liu, Q., Wang, Y.: Resworld: Temporal residual world model for end-to-end autonomous driving. arXiv preprint arXiv:2602.10884 (2026)
arXiv 2026
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, K., Tang, Z., Hu, X., Pan, X., Guo, X., Liu, Y., Huang, J., Yuan, L., Zhang, Q., Long, X.X., et al.: Epona: Autoregressive diffusion world model for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27220–27230 (2025)
2025
-
[40]
arXiv preprint arXiv:2510.19654 (2025)
Zhao, Z., Fu, T., Wang, Y., Wang, L., Lu, H.: From forecasting to plan- ning: Policy world model for collaborative state-action prediction. arXiv preprint arXiv:2510.19654 (2025)
arXiv 2025
-
[41]
In: Advances in Neural Information Processing Systems (2025),https://openreview
Zheng, A., Wen, X., Zhang, X., Ma, C., Wang, T., Yu, G., Zhang, X., Qi, X.: Vision foundation models as effective visual tokenizers for autoregressive generation. In: Advances in Neural Information Processing Systems (2025),https://openreview. net/pdf?id=PESrAH82Zh
2025
-
[42]
In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV) (2025)
Zheng, Y., Yang, P., Xing, Z., Zhang, Q., Zheng, Y., Gao, Y., Li, P., Zhang, T.: World4drive: End-to-end autonomous driving via intention-aware physical latent world model. In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV) (2025)
2025
-
[43]
arXiv preprint arXiv:2512.16919 (2025)
Zuo, S., Xie, Z., Zheng, W., Xu, S., Li, F., Jiang, S., Chen, L., Yang, Z.X., Lu, J.: Dvgt: Driving visual geometry transformer. arXiv preprint arXiv:2512.16919 (2025)
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.