An NLP-Driven Framework for Curriculum-Labor Market Alignment: Schema-Constrained LLM Extraction, ESCO-Anchored Semantic Matching, and Multi-Dimensional Gap Quantification
Pith reviewed 2026-06-28 14:30 UTC · model grok-4.3
The pith
A schema-constrained LLM pipeline extracts 400 competencies from an 85-course CS study plan and aligns them to 30 job postings with 0.79 kappa reliability, revealing 25% gaps in transversal skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
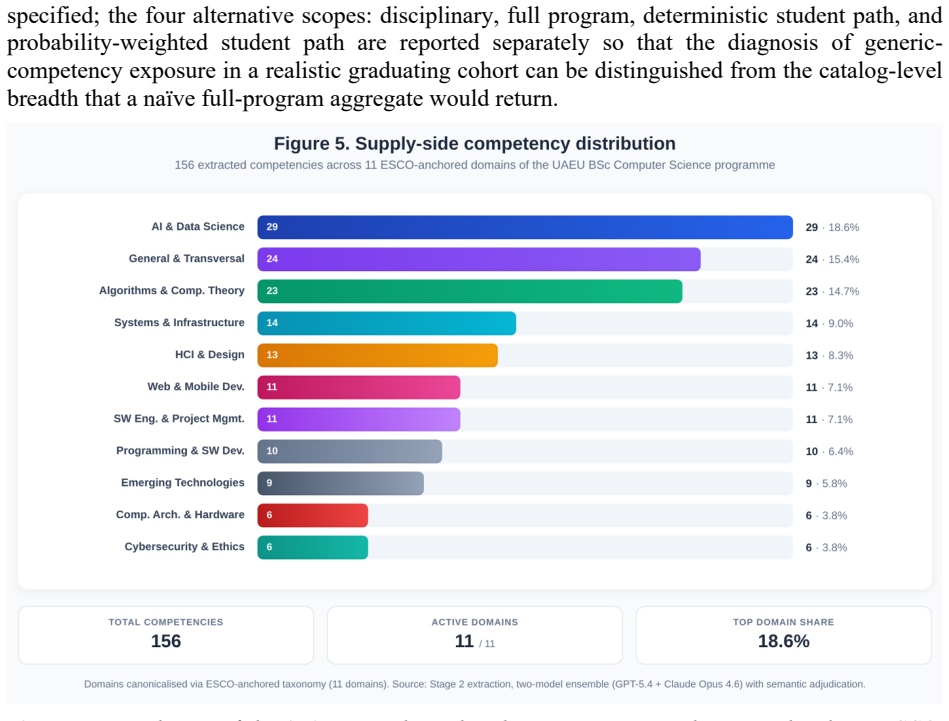
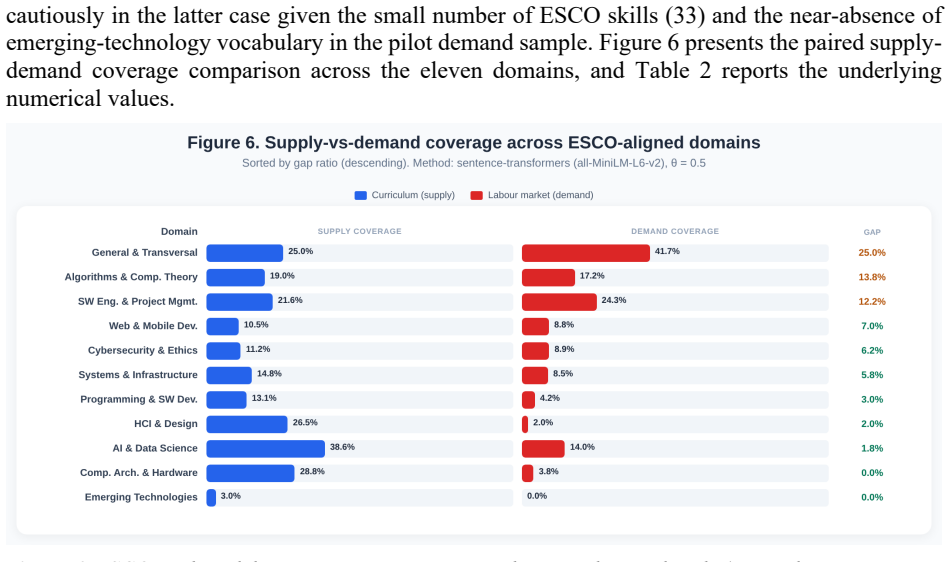
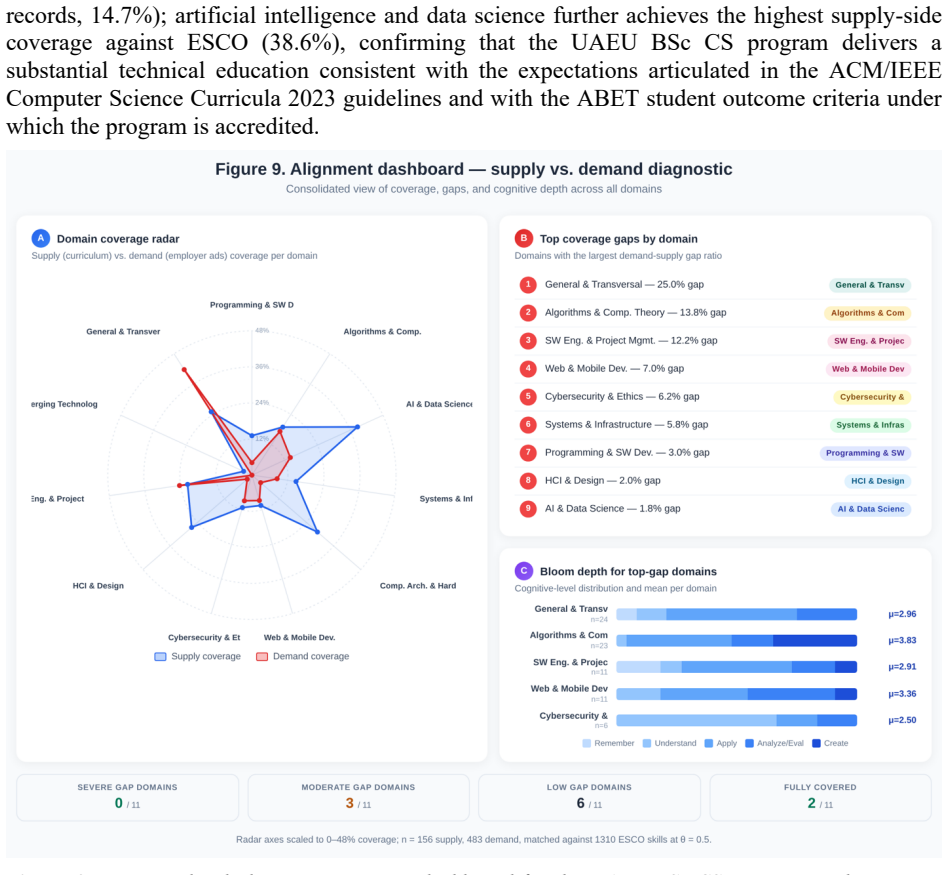
The framework extracts 400 competency records from the 85-course 2025-2026 study plan with 100% schema conformance and 100% document-level completeness, achieves Cohen's kappa of 0.79 on the skill slot, and aligns the records to 483 requirement clauses from 30 job postings at an SBERT cosine threshold of 0.50, producing interpretable gaps of 25.0% in general and transversal skills, 13.8% in algorithms and computational theory, 12.2% in software engineering and project management, and a near-zero 1.8% gap in artificial intelligence and data science despite 38.6% supply coverage.
What carries the argument
The seven-slot competency formalism enforced through schema-constrained LLM prompting, followed by SBERT cosine similarity matching to the eleven-domain ESCO v1.2.1 vocabulary and a two-tier adjudication protocol.
If this is right
- Curriculum committees can identify and address specific under-supplied areas such as transversal skills while reducing over-coverage in AI and data science.
- The five-scope analysis ranging from computing core to probability-weighted student trajectories enables differentiated alignment views for different student paths.
- The verification layer combining Cohen's kappa, schema conformance, and completeness audits supplies quantifiable confidence scores for each alignment result.
- The pipeline can be re-run on updated study plans or new job postings to produce time-series gap measurements.
Where Pith is reading between the lines
- The same extraction and matching steps could be applied to non-CS programs if the seven-slot schema is adjusted for domain-specific terminology.
- Integration with live job-posting APIs would allow continuous rather than snapshot monitoring of curriculum-market drift.
- The reported gaps could inform targeted interventions such as new elective modules or cross-disciplinary requirements.
Load-bearing premise
The seven-slot competency formalism combined with schema-constrained prompting of frontier LLMs can reliably recover implicit competencies from course and job documents without significant loss or hallucination.
What would settle it
Independent expert annotation of a random sample of course descriptions and job postings, followed by direct comparison of the resulting competencies against the LLM output to test whether the reported per-slot kappa, schema conformance, and gap percentages are reproduced.
Figures



read the original abstract
Schema-constrained information extraction from diverse educational and labor-market corpora remains an open challenge in natural language processing because existing pipelines rely primarily on lexical-surface methods that cannot recover implicit competencies, lack grounding in shared taxonomies, and provide no formal measures of extraction reliability or document-level completeness. To address these limitations, this paper proposes a four-stage NLP framework that combines (i) schema-constrained prompting of a two-model frontier-LLM ensemble against a JSON Schema-enforced seven-slot competency formalism, (ii) Sentence-BERT (SBERT) alignment of the extracted records against an eleven-domain ESCO v1.2.1 controlled vocabulary, (iii) a two-tier adjudication protocol that resolves inter-model disagreements, and (iv) a verification mechanism that combines per-slot Cohen's kappa, schema conformance, and document-level completeness audits. The framework is instantiated for a critical application in higher-education quality assurance, namely curriculum-labor market alignment for the ABET-accredited BSc Computer Science program at the United Arab Emirates University. The pipeline extracts 400 competency records from the 85-course 2025-2026 study plan and aligns them, under a five-scope analysis ranging from the computing core to a probability-weighted student trajectory, with 30 job postings (483 requirement clauses) at an SBERT cosine threshold of 0.50. The extractor achieves Cohen's kappa of 0.79 on the skill slot, with 100% schema conformance and 100% document-level completeness. The alignment surfaces interpretable supply-demand gaps of 25.0% in general and transversal skills, 13.8% in algorithms and computational theory, and 12.2% in software engineering and project management, with a near-zero 1.8% gap in artificial intelligence and data science despite 38.6% supply coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a four-stage NLP framework for curriculum-labor market alignment. It uses schema-constrained prompting of a two-LLM ensemble to extract competencies into a seven-slot JSON schema from educational and job corpora, aligns them to ESCO using SBERT at cosine threshold 0.50, applies adjudication, and verifies with Cohen's kappa, schema conformance, and completeness. Applied to an 85-course CS study plan and 30 job postings, it extracts 400 records, achieves kappa 0.79 on skills, 100% conformance, and reports gaps such as 25.0% in general/transversal skills and 1.8% in AI/data science.
Significance. If the extraction reliability holds, the work offers a grounded, interpretable approach to quantifying alignment gaps using a shared taxonomy (ESCO), with strengths in schema enforcement and multi-scope analysis (computing core to student trajectory). It demonstrates application to ABET-accredited program with concrete metrics, potentially aiding higher-education QA. The use of frontier LLMs with internal consistency checks is a practical contribution.
major comments (2)
- [Abstract / verification mechanism] Abstract, verification mechanism: The central claim that the seven-slot formalism with schema-constrained LLM prompting reliably recovers implicit competencies without significant loss or hallucination rests on three internal metrics (per-slot Cohen's kappa of 0.79 between the two LLMs, 100% JSON schema conformance, and 100% document-level completeness). These assess agreement and format compliance but do not establish accuracy against human-annotated ground truth; shared LLM biases can produce high agreement on both correct and incorrect extractions. No human validation sample or precision/recall evaluation on the skill or knowledge slots is reported to support the reliability claims.
- [five-scope analysis] five-scope analysis: The reported supply-demand gaps (e.g., 13.8% in algorithms and computational theory, 12.2% in software engineering) are derived under a five-scope analysis ranging from the computing core to a probability-weighted student trajectory, but the manuscript provides insufficient detail on how the scopes are defined, how the probability-weighted parameters are selected, or how the alignment is aggregated across scopes. This undermines interpretability of the gap quantifications.
minor comments (1)
- The SBERT cosine threshold of 0.50 is fixed without reported sensitivity analysis showing how the gap percentages vary with threshold choice.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of validation and methodological transparency that we will address through targeted revisions to strengthen the work.
read point-by-point responses
-
Referee: [Abstract / verification mechanism] Abstract, verification mechanism: The central claim that the seven-slot formalism with schema-constrained LLM prompting reliably recovers implicit competencies without significant loss or hallucination rests on three internal metrics (per-slot Cohen's kappa of 0.79 between the two LLMs, 100% JSON schema conformance, and 100% document-level completeness). These assess agreement and format compliance but do not establish accuracy against human-annotated ground truth; shared LLM biases can produce high agreement on both correct and incorrect extractions. No human validation sample or precision/recall evaluation on the skill or knowledge slots is reported to support the reliability claims.
Authors: We appreciate the referee's distinction between inter-model reliability and external validity. The two-LLM ensemble (from distinct providers) was selected specifically to mitigate single-model bias, yielding kappa 0.79 on skills. However, we acknowledge that this does not fully rule out correlated errors. In revision, we will add a human validation subsection: a stratified random sample of 50 extracted records will be annotated by two independent CS domain experts, with precision, recall, and F1 reported against the LLM outputs, plus inter-annotator agreement. This directly addresses potential shared biases. revision: yes
-
Referee: [five-scope analysis] five-scope analysis: The reported supply-demand gaps (e.g., 13.8% in algorithms and computational theory, 12.2% in software engineering) are derived under a five-scope analysis ranging from the computing core to a probability-weighted student trajectory, but the manuscript provides insufficient detail on how the scopes are defined, how the probability-weighted parameters are selected, or how the alignment is aggregated across scopes. This undermines interpretability of the gap quantifications.
Authors: We agree that greater detail on the five-scope analysis is required for interpretability and reproducibility. The scopes progress from mandatory computing-core courses through elective clusters to a probability-weighted student trajectory (derived from historical enrollment data). In the revised manuscript, we will expand the relevant methods subsection with explicit definitions of each scope, the source and selection of probability parameters, and the aggregation procedure (weighted averaging of per-scope gaps). A summary table of scope definitions and parameters will also be added. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper applies its four-stage pipeline (schema-constrained LLM extraction, SBERT-ESCO alignment, adjudication, and verification) directly to independent external inputs: the 85-course 2025-2026 study plan yielding 400 records and 30 job postings with 483 clauses. Reported quantities (Cohen's kappa 0.79, 100% schema conformance, supply-demand gaps of 25.0%/13.8%/12.2%/1.8%) are computed from that application rather than being redefined in terms of themselves or forced by self-citation chains. No equations, fitted parameters presented as predictions, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the abstract or described derivation; the results remain statistically independent of the input corpora.
Axiom & Free-Parameter Ledger
free parameters (2)
- SBERT cosine threshold =
0.50
- Probability-weighted student trajectory parameters
axioms (2)
- domain assumption The eleven-domain ESCO v1.2.1 vocabulary provides an appropriate and complete anchor for competency matching
- domain assumption Frontier LLMs with schema-constrained prompting can extract structured competency data with high fidelity from unstructured text
Forward citations
Cited by 1 Pith paper
-
Measuring Curriculum Alignment across Topical Coverage, Competency, and Cognitive Depth: A Longitudinal Framework Applied to CS2013 and CS2023
A retrieve-then-confirm framework applied to one CS program finds ~50% coverage of both CS2013 and CS2023, ~88% competency articulation, and lower cognitive depth under the newer guideline (76% vs 95%).
Reference graph
Works this paper leans on
-
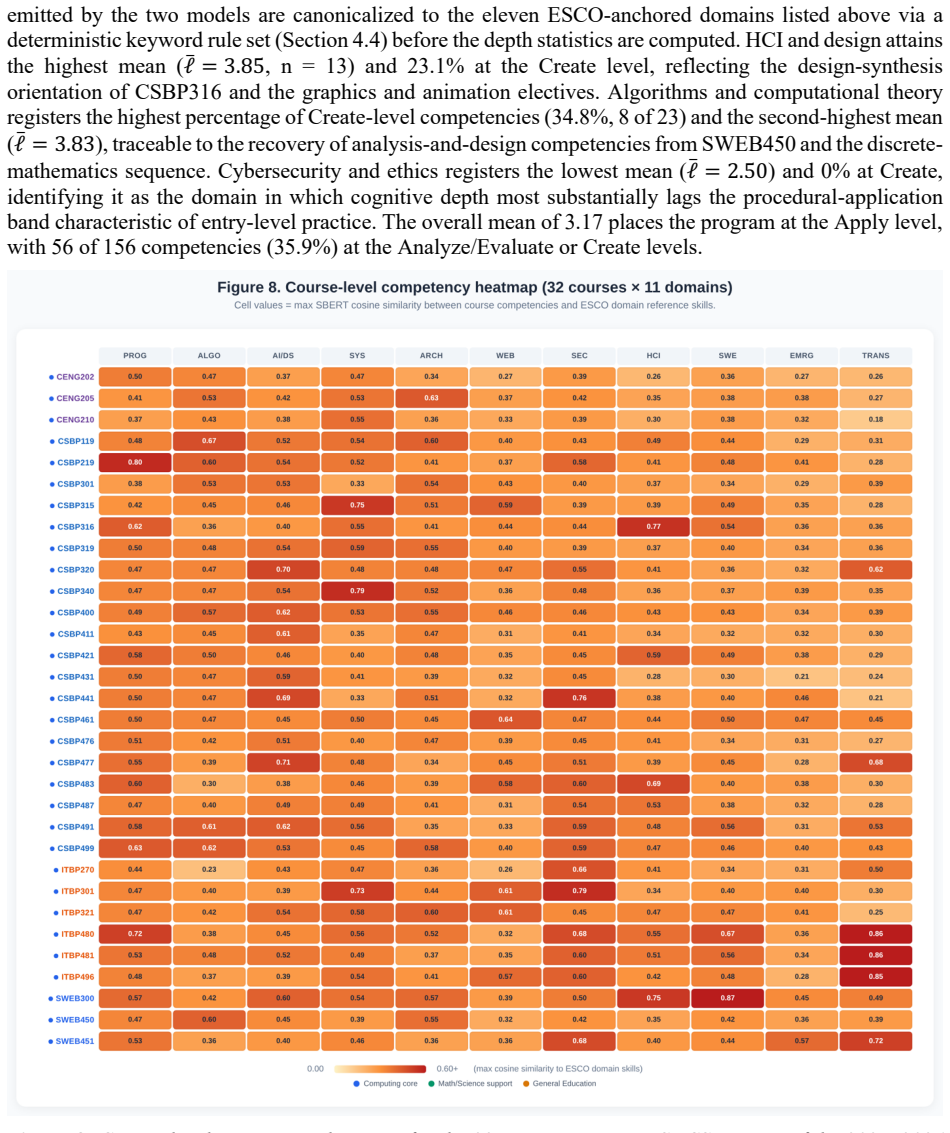
[1]
Course-level competency heatmap for the 32 computing-core BSc CS courses of the 2025–2026 UAEU Online Catalog. Rows represent individual courses (grouped by department: CSSE, SWEB, CNE, ISS) and columns represent the eleven ESCO-aligned domains (the ten computing domains together with General and Transversal Skills). Cell color encodes the SBERT cosine si...
2025
-
[2]
DISCUSSION The pilot study results reported in Section 4.5 demonstrate that the proposed framework can transform heterogeneous curricular documents, including syllabi, catalog descriptions, CLO inventories, and accreditation mappings, into structured, taxonomy-grounded competency profiles and produce alignment diagnostics that are both quantitatively prec...
2023
-
[3]
gap / no gap
Program-level alignment summary dashboard for the UAEU BSc CS program at the primary computing-core scope (N = 156). Panel (a) displays a radar chart of the eleven competency domains, with the supply-side coverage polygon (solid line) overlaid on the demand-side coverage polygon (dashed line); the shaded region between the two polygons represents the aggr...
2013
-
[4]
CONCLUSION 6.1 Summary of Contributions This paper has addressed the problem of curriculum-labor market misalignment through the design and pilot evaluation of an end-to-end NLP-driven framework that transforms heterogeneous curricular and labor-market documents into structured, taxonomy-grounded competency profiles and produces multi-dimensional alignmen...
-
[5]
https://doi.org/10.1038/s41467-024-45563-x Deng, R., Jiang, M., Yu, X., Lu, Y., & Liu, S. (2025). Does ChatGPT enhance student learning? A systematic review and meta-analysis of experimental studies. Computers & Education, 227, 105224. https://doi.org/10.1016/j.compedu.2024.105224 Kavargyris, D. C., Georgiou, K., Papaioannou, E., Petrakis, K., Mittas, N.,...
-
[6]
https://doi.org/10.1038/s41539-025-00300-x Jaiswal, K., Kuzminykh, I., & Modgil, S. (2025). Understanding the skills gap between higher education and industry in the UK artificial intelligence sector. Industry and Higher Education, 39(2), 234–246. https://doi.org/10.1177/09504222241280441 James, J. (2025). Counting on consensus: Selecting the right inter-...
-
[7]
https://doi.org/10.3390/app12147139 Kasneci, E., Sessler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., Gasser, U., Groh, G., Günnemann, S., Hüllermeier, E., Krusche, S., Kutyniok, G., Michaeli, T., Nerdel, C., Pfeffer, J., Poquet, O., Sailer, M., Schmidt, A., Seidel, T., … Kasneci, G. (2023). ChatGPT for good? On opportunities and challeng...
-
[8]
Lecture Notes in Computer Science, 15778. Springer, Cham. https://doi.org/10.1007/978-3-031-93724-8_15 Mahbub, M., Dams, G., Arnold, J., Rizy, C. et al. (2026). A multi-stage validation framework for trustworthy large-scale clinical information extraction using large language models. arXiv preprint, arXiv:2604.06028. https://arxiv.org/abs/2604.06028 Moham...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-031-93724-8_15 2026
-
[9]
https://doi.org/10.3390/info16030167 Radermacher, A., & Walia, G. (2013). Gaps between industry expectations and the abilities of graduates. In Proceeding of the 44th ACM technical symposium on Computer science education (SIGCSE ‘13). ACM, 525–530. https://doi.org/10.1145/2445196.2445351 Schedlbauer, J., Raptis, G., & Ludwig, B. (2021). Medical informatic...
-
[10]
https://ceur-ws.org/Vol-3853/paper2.pdf Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., & Zhou, D. (2023). Self-consistency improves chain of thought reasoning in language models. In Proceedings of the 11th International Conference on Learning Representations (ICLR 2023). https://openreview.net/forum?id=1PL1NIMMrw Wang, S., ...
-
[11]
World Economic Forum. https://www.weforum.org/publications/the-future-of-jobs-report-2025/ Xu, D., Chen, W., Peng, W., Zhang, C., Xu, B., Zhao, X., Wu, X., Zheng, Y., Wang, Y., & Chen, E. (2024). Large language models for generative information extraction: A survey. Frontiers of Computer Science, 18, 186357. https://doi.org/10.1007/s11704-024-40555-y Xu, ...
-
[12]
LNCS, Vol 15160. Springer, Cham. https://doi.org/10.1007/978-3-031-72312-4_2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.