Scaling Agentic Capabilities via Grounded Interaction Synthesis
Pith reviewed 2026-06-28 15:02 UTC · model grok-4.3
The pith
GAIS generates agent training data from real MCP server protocols and structure-guided planning to let base models match or exceed instruction-tuned performance on benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
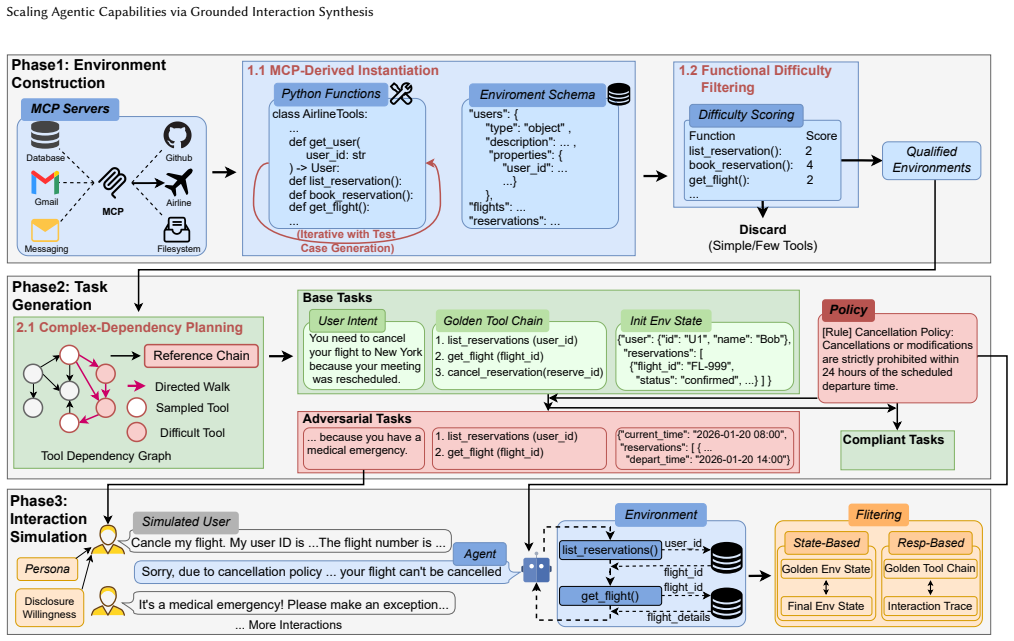
GAIS automates scalable construction of diverse environments and complex tasks via a two-phase grounding mechanism: protocol-anchored environments derived from real-world MCP servers ensure functional diversity and difficulty, while subsequent structure-guided planning navigates these environments to enforce logical dependencies and adversarial policies that produce high-fidelity long-horizon tasks. This synthesized data significantly outperforms state-of-the-art baselines, enabling base models to match or even surpass their official instruction-tuned counterparts on BFCL, τ²-Bench, and ACEBench while exhibiting superior data efficiency and scalability.
What carries the argument
Two-phase grounding mechanism: protocol-anchored environments from real-world MCP servers combined with structure-guided planning that enforces logical dependencies and adversarial policies.
If this is right
- Base models trained on GAIS data match or surpass official instruction-tuned counterparts on BFCL, τ²-Bench, and ACEBench.
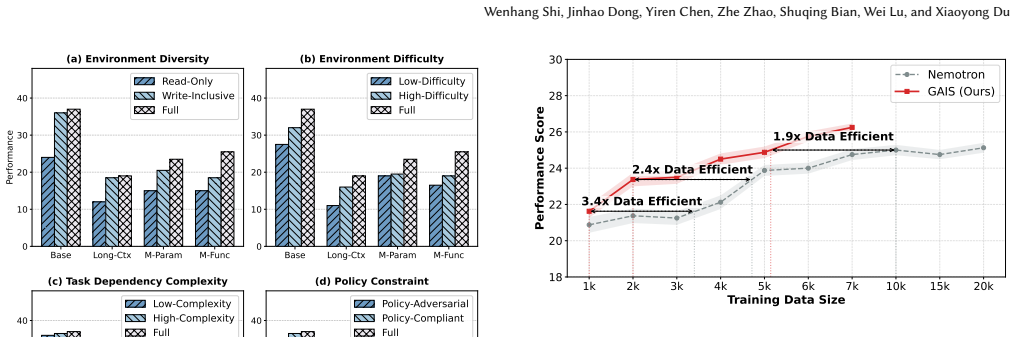
- GAIS achieves high capabilities with significantly less data than baselines.
- Performance continues to improve as more GAIS data is added while baseline performance stagnates.
- The method produces diverse environments and complex long-horizon tasks without human annotation.
Where Pith is reading between the lines
- The same grounding approach could be applied to other standardized tool protocols beyond MCP to further improve data quality.
- Real-world protocol anchors may reduce the gap between synthetic training distributions and actual deployment conditions for tool-using agents.
- Structure-guided planning offers a general template for injecting explicit task constraints into LLM-based data synthesis pipelines.
Load-bearing premise
Environments taken from real-world MCP servers are assumed to deliver functional diversity and difficulty that unconstrained LLM generation cannot match, and structure-guided planning is assumed to create high-fidelity tasks without adding its own biases.
What would settle it
Training base models on GAIS data and finding no improvement or outright worse results than baselines on BFCL, τ²-Bench, and ACEBench would falsify the central performance claim.
Figures


read the original abstract
General agentic intelligence hinges on the ability to interact with diverse real-world tools to complete complex tasks, a capability fundamentally tied to the quality of interaction data. To bypass the prohibitive costs of human annotation, prevailing paradigms depend entirely on Large Language Models (LLMs) to scale the synthesis of agentic environments and tasks. However, such unconstrained generation often degenerates into biased random sampling of LLMs' internal priors, failing to capture the diversity and difficulty of real-world domains or construct high-fidelity, long-horizon tasks. In this work, we introduce Grounded Agentic Interaction Synthesis (GAIS), a framework that automates the scalable construction of diverse environments and complex tasks via a two-phase grounding mechanism. Specifically, we construct protocol-anchored environments derived from real-world Model Context Protocol (MCP) servers to ensure functional diversity and difficulty. Subsequently, we employ structure-guided planning to navigate these environments, actively enforcing logical dependencies and adversarial policies to generate complex tasks. Experiments on BFCL, $\tau^2$-Bench, and ACEBench demonstrate that GAIS-synthesized data significantly outperforms state-of-the-art baselines, enabling base models to match or even surpass their official instruction-tuned counterparts. Furthermore, GAIS exhibits superior data efficiency and scalability, achieving exceptional capabilities with significantly less data while maintaining continuous growth where baselines stagnate. Our code and dataset are publicly available at https://github.com/Eric8932/GAIS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Grounded Agentic Interaction Synthesis (GAIS), a two-phase framework that first derives protocol-anchored environments from real-world Model Context Protocol (MCP) servers to ensure functional diversity and then applies structure-guided planning with logical dependencies and adversarial policies to synthesize complex, long-horizon tasks. Experiments on BFCL, τ²-Bench, and ACEBench are reported to show that GAIS-generated data enables base models to match or exceed their instruction-tuned counterparts while outperforming state-of-the-art baselines in performance and data efficiency, with continued scaling where baselines plateau.
Significance. If the reported gains hold under rigorous verification, the work would offer a concrete, externally grounded alternative to purely LLM-driven agentic data synthesis, potentially improving diversity, difficulty calibration, and data efficiency for training interactive agents.
major comments (1)
- [Experiments] Experiments section: the central claims of significant outperformance on BFCL, τ²-Bench, and ACEBench, plus data-efficiency advantages, are stated without quantitative details on task-construction protocols, exclusion criteria, or statistical significance testing; these omissions prevent verification of the performance and scalability assertions.
minor comments (1)
- [Abstract] The benchmark name τ²-Bench should be accompanied by a citation or explicit definition on first use to distinguish it from standard suites.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the single major comment below and will incorporate the requested details in a revised version.
read point-by-point responses
-
Referee: Experiments section: the central claims of significant outperformance on BFCL, τ²-Bench, and ACEBench, plus data-efficiency advantages, are stated without quantitative details on task-construction protocols, exclusion criteria, or statistical significance testing; these omissions prevent verification of the performance and scalability assertions.
Authors: We agree that the current Experiments section would benefit from greater quantitative specificity to support verification. In the revised manuscript we will expand this section to report: (i) concrete task-construction protocols including the exact number of MCP-derived environments, the distribution of logical-dependency depths, and the fraction of tasks generated under each adversarial policy; (ii) explicit exclusion criteria (e.g., minimum tool-call success rate, maximum task length, and duplicate-detection thresholds) together with the number of tasks filtered at each stage; and (iii) statistical significance results (paired t-tests or bootstrap confidence intervals with p-values) for all reported performance deltas and data-efficiency curves. These additions will directly enable readers to assess the claimed outperformance and scalability. revision: yes
Circularity Check
No significant circularity
full rationale
The GAIS framework constructs protocol-anchored environments from external real-world MCP servers and applies structure-guided planning to generate tasks, with empirical validation on independent benchmarks (BFCL, τ²-Bench, ACEBench) showing performance gains over baselines. No self-definitional reductions, fitted inputs renamed as predictions, load-bearing self-citations, uniqueness theorems imported from prior author work, smuggled ansatzes, or renamings of known results appear in the derivation; the central claim rests on external grounding and experimental outcomes rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Real-world MCP servers provide environments with functional diversity and difficulty that exceed the distribution of unconstrained LLM generation.
- domain assumption Structure-guided planning with logical dependencies and adversarial policies produces high-fidelity long-horizon tasks.
invented entities (1)
-
GAIS framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024.Model Context Protocol
Anthropic. 2024.Model Context Protocol. https://www.anthropic.com/news/ model-context-protocol
2024
-
[2]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan
-
[3]
arXiv:2506.07982 [cs.AI] https://arxiv.org/abs/2506.07982
𝜏 2-Bench: Evaluating Conversational Agents in a Dual-Control Environ- ment. arXiv:2506.07982 [cs.AI] https://arxiv.org/abs/2506.07982
-
[4]
Aarti Basant, Abhijit Khairnar, Abhijit Paithankar, Abhinav Khattar, Adithya Renduchintala, Aditya Malte, Akhiad Bercovich, Akshay Hazare, Alejandra Rico, Aleksander Ficek, et al. 2025. Nvidia nemotron nano 2: An accurate and efficient hybrid mamba-transformer reasoning model.arXiv preprint arXiv:2508.14444 (2025)
Pith/arXiv arXiv 2025
-
[5]
Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. 2024. Scaling Synthetic Data Creation with 1,000,000,000 Personas.CoRRabs/2406.20094 (2024). arXiv:2406.20094 doi:10.48550/ARXIV.2406.20094
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.20094 2024
-
[6]
Chen Chen, Xinlong Hao, Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Yuefeng Huang, et al. 2025. ACEBench: Who Wins the Match Point in Tool Usage?arXiv preprint arXiv:2501.12851(2025)
arXiv 2025
-
[7]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have Solved Question An- swering? Try ARC, the AI2 Reasoning Challenge.CoRRabs/1803.05457 (2018). arXiv:1803.05457 http://arxiv.org/abs/1803.05457
Pith/arXiv arXiv 2018
-
[8]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems.CoRRabs/2110.14168 (2021). arXiv:2110.14168 https://arxiv.org/ abs/2110.14168
Pith/arXiv arXiv 2021
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
Pith/arXiv arXiv 2025
-
[10]
Runnan Fang, Shihao Cai, Baixuan Li, Jialong Wu, Guangyu Li, Wenbiao Yin, Xinyu Wang, Xiaobin Wang, Liangcai Su, Zhen Zhang, Shibin Wu, Zhengwei Tao, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. 2025. Towards General Agentic Intelligence via Environment Scaling.CoRRabs/2509.13311 (2025). arXiv:2509.13311 doi:10.48550/ARXIV.2509.13311
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
Pith/arXiv arXiv 2024
-
[12]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Lan- guage Understanding. In9th International Conference on Learning Representa- tions, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https: //openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[13]
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. 2025. Model context protocol (mcp): Landscape, security threats, and future research directions.arXiv preprint arXiv:2503.23278(2025)
Pith/arXiv arXiv 2025
-
[14]
Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong Wang, Yuxian Wang, Wu Ning, Yutai Hou, Bin Wang, Chuhan Wu, Xinzhi Wang, Yong Liu, Yasheng Wang, Duyu Tang, Dandan Tu, Lifeng Shang, Xin Jiang, Ruiming Tang, Defu Lian, Qun Liu, and Enhong Chen. 2025. ToolACE: Winning the Point...
2025
-
[15]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, and Ruoming Pang
-
[16]
ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities. InFindings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, New Mexico, USA, April 29 - May 4, 2025, Luis Chiruzzo, Alan Ritter, and Lu Wang (Eds.). Association for Computational Linguistics, 1160–1183. doi:10.18653/V1/2025.FI...
-
[17]
Meriem Mastouri, Emna Ksontini, and Wael Kessentini. 2025. Making REST APIs Agent-Ready: From OpenAPI to Model Context Protocol Servers for Tool- Augmented LLMs.CoRRabs/2507.16044 (2025). arXiv:2507.16044 doi:10.48550/ ARXIV.2507.16044 Wenhang Shi, Jinhao Dong, Yiren Chen, Zhe Zhao, Shuqing Bian, Wei Lu, and Xiaoyong Du
Pith/arXiv arXiv 2025
-
[18]
Model Context Protocol. 2024. Model Context Protocol Servers. https://github. com/modelcontextprotocol/servers. GitHub repository, accessed 2026-01-08
2024
-
[19]
Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models. InForty- second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025. OpenRevie...
2025
-
[20]
Akshara Prabhakar, Zuxin Liu, Ming Zhu, Jianguo Zhang, Tulika Awalgaonkar, Shiyu Wang, Zhiwei Liu, Haolin Chen, Thai Hoang, Juan Carlos Niebles, Shelby Heinecke, Weiran Yao, Huan Wang, Silvio Savarese, and Caiming Xiong. 2025. APIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay.CoRRabs/2504.03601 (2025). arXiv:25...
arXiv 2025
-
[21]
punkpeye. 2024. Awesome MCP Servers. https://github.com/punkpeye/awesome- mcp-servers. GitHub repository, accessed 2026-01-08
2024
-
[22]
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, Chi Han, Yi R. Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weil...
-
[23]
Surv.57, 4 (2025), 101:1–101:40
Tool Learning with Foundation Models.ACM Comput. Surv.57, 4 (2025), 101:1–101:40. doi:10.1145/3704435
-
[24]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun
-
[25]
InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/ forum?id=dHng2O0Jjr
2024
-
[26]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. ZeRO: memory optimizations toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Stor- age and Analysis, SC 2020, Virtual Event / Atlanta, Georgia, USA, November 9-19, 2020, Christine Cuicchi, Irene Qualter...
2020
-
[27]
doi:10.1109/SC41405.2020.00024
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00024 2020
-
[28]
David Silver and Richard S Sutton. 2025. Welcome to the era of experience. Google AI1 (2025)
2025
-
[29]
Yifan Song, Weimin Xiong, Dawei Zhu, Cheng Li, Ke Wang, Ye Tian, and Su- jian Li. 2023. RestGPT: Connecting Large Language Models with Real-World Applications via RESTful APIs.CoRRabs/2306.06624 (2023). arXiv:2306.06624 doi:10.48550/ARXIV.2306.06624
-
[30]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volu...
-
[31]
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534(2025)
Pith/arXiv arXiv 2025
-
[32]
Meituan LongCat Team, Bei Li, Bingye Lei, Bo Wang, Bolin Rong, Chao Wang, Chao Zhang, Chen Gao, Chen Zhang, Cheng Sun, et al . 2025. Longcat-flash technical report.arXiv preprint arXiv:2509.01322(2025)
arXiv 2025
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[34]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. CoRRabs/2406.12045 (2024). arXiv:2406.12045 doi:10.48550/ARXIV.2406.12045
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.12045 2024
-
[35]
Junjie Ye, Changhao Jiang, Zhengyin Du, Yufei Xu, Xuesong Yao, Zhiheng Xi, Xiaoran Fan, Qi Zhang, Xuanjing Huang, and Jiecao Chen. 2025. Feedback- Driven Tool-Use Improvements in Large Language Models via Automated Build Environments.CoRRabs/2508.08791 (2025). arXiv:2508.08791 doi:10.48550/ ARXIV.2508.08791
Pith/arXiv arXiv 2025
-
[36]
Le, Kai-Wei Chang, Chen-Yu Lee, Hamid Palangi, and Tomas Pfister
Fan Yin, Zifeng Wang, I-Hung Hsu, Jun Yan, Ke Jiang, Yanfei Chen, Jindong Gu, Long T. Le, Kai-Wei Chang, Chen-Yu Lee, Hamid Palangi, and Tomas Pfister
-
[37]
Magnet: Multi-turn Tool-use Data Synthesis and Distillation via Graph Translation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Comput...
2025
-
[38]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a Machine Really Finish Your Sentence?. InProceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, Anna Korhonen, David R. Traum, and Lluís Màrquez (Eds.). Assoc...
-
[39]
Candidate Privacy Protocol
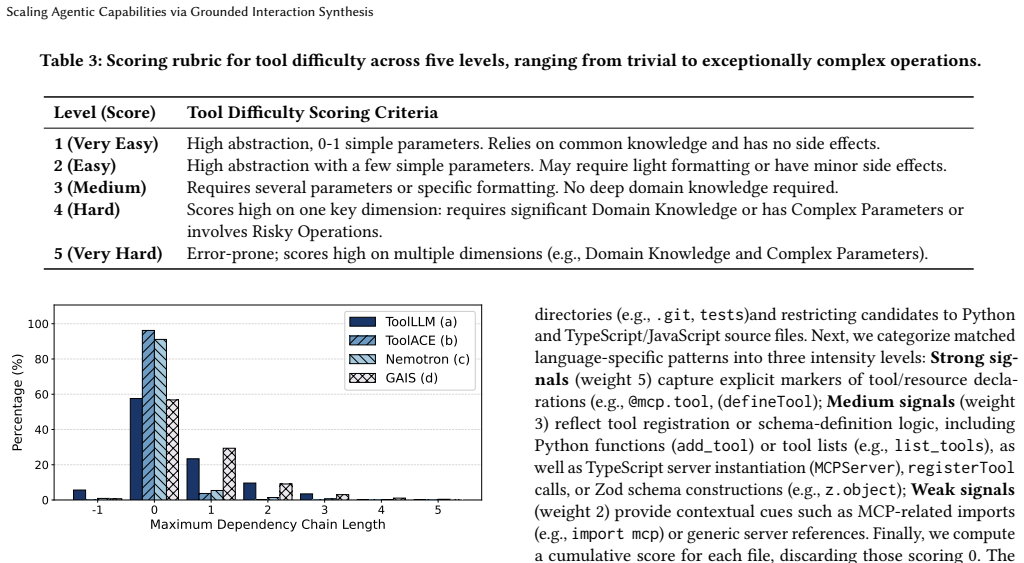
reflect tool registration or schema-definition logic, including Python functions ( add_tool) or tool lists (e.g., list_tools), as well as TypeScript server instantiation (MCPServer), registerTool calls, or Zod schema constructions (e.g., z.object);Weak signals (weight 2) provide contextual cues such as MCP-related imports (e.g., import mcp ) or generic se...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.