RL-ACRGNet: Reinforcement Learning-Based Chest Radiology Report Generation Network
Pith reviewed 2026-06-28 14:21 UTC · model grok-4.3
The pith
RL-ACRGNet places an off-policy reinforcement learning loop around a DenseNet-LSTM encoder-decoder to refine visual-semantic embeddings for chest radiology reports via metric rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
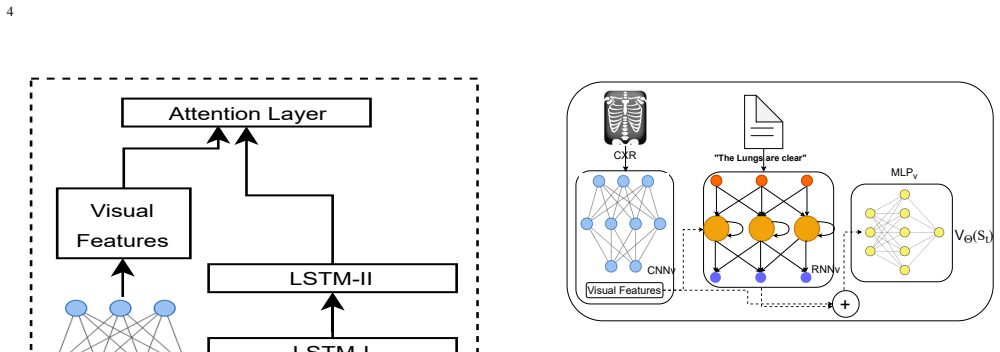
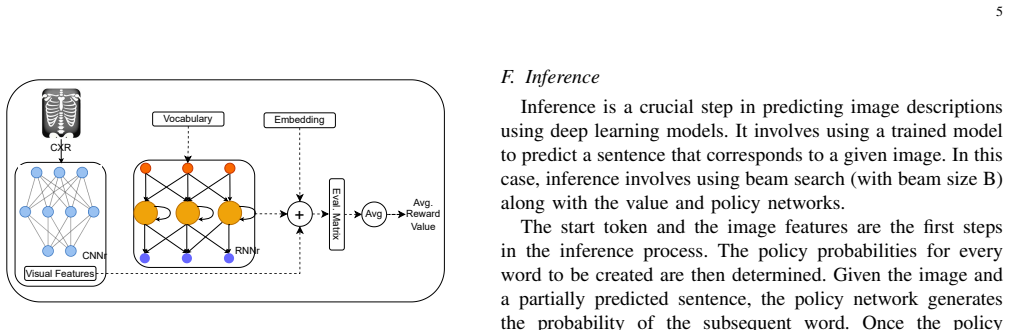
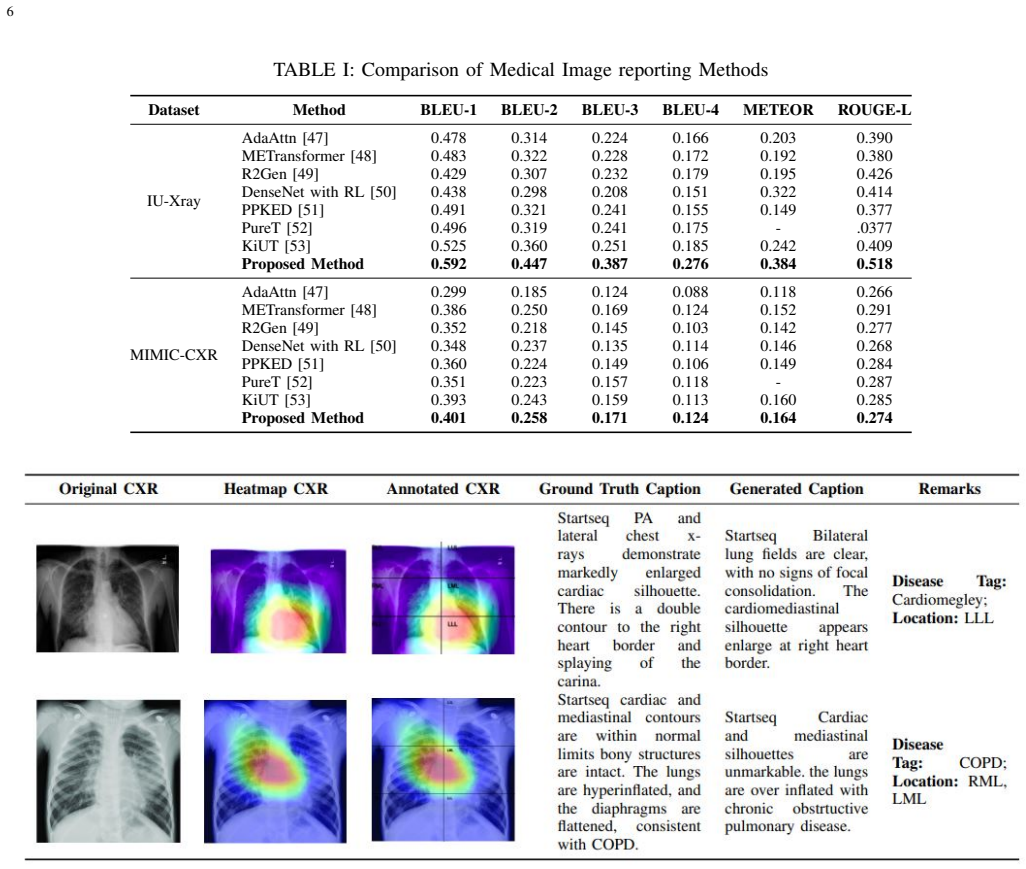
RL-ACRGNet integrates a pre-trained DenseNet encoder with a multilevel LSTM decoder inside an off-policy reinforcement learning framework. A dual-network mechanism refines visual-semantic embeddings through a metric-based reward signal, producing reports that score higher than prior models on the IU-Xray dataset and maintain performance when tested on the larger MIMIC-CXR collection.
What carries the argument
The dual-network refinement of visual-semantic embeddings through metric-based rewards inside the off-policy RL training loop.
If this is right
- Higher BLEU-4, METEOR and ROUGE-L scores on the IU-Xray test set compared with prior encoder-decoder systems.
- Stable performance when the same model is evaluated on the much larger MIMIC-CXR collection without retraining.
- Production of reports described as high-quality and clinically relevant by the evaluation protocol used in the paper.
Where Pith is reading between the lines
- If the reward mechanism truly captures clinical coherence, the same dual-network RL wrapper could be attached to other medical-report generators without changing the underlying encoder or decoder.
- The reported gains on two different datasets suggest the method may reduce the need for dataset-specific fine-tuning when moving between hospital systems.
- Direct radiologist preference studies would be a natural next measurement to check whether the automatic metric improvements translate into fewer corrections in real workflows.
Load-bearing premise
The chosen reward metrics are sufficient to steer the model toward clinically coherent text that remains reliable on data drawn from different hospitals and scanners.
What would settle it
An experiment in which board-certified radiologists rate the factual accuracy and clinical usefulness of RL-ACRGNet reports lower than reports from the best non-RL baseline on a held-out set of cases would falsify the central claim.
Figures


read the original abstract
Medical imaging interpretation is a foundational pillar of modern clinical diagnostics, yet the manual generation of radiology reports remains a time-consuming process prone to interpretation inconsistencies. Within the field of medical AI, automating these descriptions through deep learning promises to streamline clinical workflows and standardise diagnostic output. However, accurate disease detection and precise report generation remain significant challenges due to limitations in capturing fine-grained visual features and ensuring clinical coherence. To address these issues, we propose RL-ACRGNet, an improved encoder-decoder model that integrates a pre-trained DenseNet encoder with a multilevel LSTM decoder within an off-policy reinforcement learning framework. Using a dual-network approach to refine visual-semantic embeddings through a metric-based reward mechanism, we demonstrate that RL-ACRGNet consistently outperforms state-of-the-art baselines on the IU-Xray dataset, achieving quantitative improvements in BLEU-4 (0.47%), METEOR (0.17%) and ROUGE-L (0.518). Furthermore, comprehensive evaluations on the large-scale MIMIC-CXR data set confirm the robust generalisation of the model and its ability to generate high-quality, clinically relevant reports
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RL-ACRGNet, an encoder-decoder model that combines a pre-trained DenseNet encoder with a multilevel LSTM decoder inside an off-policy reinforcement learning framework. A dual-network design refines visual-semantic embeddings via a metric-based reward. The central empirical claim is that the model outperforms state-of-the-art baselines on IU-Xray (BLEU-4 +0.47%, METEOR +0.17%, ROUGE-L +0.518) and exhibits robust generalization on MIMIC-CXR for high-quality, clinically relevant reports.
Significance. If the reported metric gains are shown to be statistically significant, exceed run-to-run variance, and correlate with clinical accuracy rather than n-gram overfitting, the work would offer incremental evidence that RL with metric rewards can improve radiology report generation. No machine-checked proofs, parameter-free derivations, or reproducible code artifacts are described.
major comments (2)
- [Abstract] Abstract: the outperformance claim rests on absolute gains of 0.47% BLEU-4, 0.17% METEOR and 0.518 ROUGE-L, yet no baseline scores, standard deviations across seeds, or statistical significance tests are supplied; without these the improvements cannot be distinguished from noise.
- [Abstract] Abstract: the generalization statement to MIMIC-CXR assumes that lifts in n-gram overlap metrics imply clinically coherent reports that transfer beyond the training distribution, but no clinical accuracy metrics, radiologist preference studies, or error analysis on MIMIC-CXR are referenced to support this.
minor comments (1)
- [Abstract] Abstract: absolute baseline values for each metric should be stated alongside the reported deltas so readers can judge the practical magnitude of the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the outperformance claim rests on absolute gains of 0.47% BLEU-4, 0.17% METEOR and 0.518 ROUGE-L, yet no baseline scores, standard deviations across seeds, or statistical significance tests are supplied; without these the improvements cannot be distinguished from noise.
Authors: We agree that the abstract claim would be strengthened by including baseline values, standard deviations, and significance tests. The full manuscript reports comparisons against baselines in the results tables, but these details are not summarized in the abstract. In the revised version we will update the abstract to reference the baseline scores and add standard deviations plus statistical significance tests (e.g., paired t-tests) to both the abstract and the experimental section. This directly addresses the possibility that reported gains reflect run-to-run variance. revision: yes
-
Referee: [Abstract] Abstract: the generalization statement to MIMIC-CXR assumes that lifts in n-gram overlap metrics imply clinically coherent reports that transfer beyond the training distribution, but no clinical accuracy metrics, radiologist preference studies, or error analysis on MIMIC-CXR are referenced to support this.
Authors: We acknowledge that n-gram metrics alone provide limited evidence of clinical coherence or true out-of-distribution generalization. The manuscript reports quantitative results on MIMIC-CXR and includes qualitative examples, yet does not contain dedicated clinical accuracy metrics, radiologist studies, or a focused error analysis for that dataset. In revision we will expand Section 4 to include an error analysis on MIMIC-CXR reports that links metric improvements to specific clinical findings. New radiologist preference studies, however, lie outside the scope of the current experiments. revision: partial
- New radiologist preference studies or clinical accuracy metrics on MIMIC-CXR beyond n-gram overlaps and error analysis
Circularity Check
No circularity; empirical claims rest on standard train/eval splits
full rationale
The provided abstract and text contain no equations, self-citations, or derivation steps. The central claim is an empirical report of metric improvements on IU-Xray and MIMIC-CXR after training an RL model with a metric-based reward; this is a conventional ML evaluation on external benchmarks and does not reduce any result to its own inputs by construction. No load-bearing self-citation chains or fitted-input-as-prediction patterns are present.
Axiom & Free-Parameter Ledger
free parameters (1)
- metric-based reward weights
axioms (1)
- domain assumption Pre-trained DenseNet features plus multilevel LSTM suffice to capture fine-grained visual-semantic correspondences needed for coherent reports.
Reference graph
Works this paper leans on
-
[1]
Chronic obstructive pulmonary disease: molecular and cellularmechanisms,
P. J. Barnes, S. D. Shapiro, and R. A. Pauwels, “Chronic obstructive pulmonary disease: molecular and cellularmechanisms,”European Res- piratory Journal, vol. 22, no. 4, pp. 672–688, 2003
2003
-
[2]
Benchmarking saliency methods for chest x-ray interpretation,
A. Saporta, X. Gui, A. Agrawal, A. Pareek, S. Q. Truong, C. D. Nguyen, V .-D. Ngo, J. Seekins, F. G. Blankenberg, A. Y . Nget al., “Benchmarking saliency methods for chest x-ray interpretation,”Nature Machine Intelligence, vol. 4, no. 10, pp. 867–878, 2022
2022
-
[3]
Automated radiology report generation: A review of recent advances,
P. Sloan, P. Clatworthy, E. Simpson, and M. Mirmehdi, “Automated radiology report generation: A review of recent advances,”IEEE Reviews in Biomedical Engineering, vol. 18, pp. 368–387, 2025
2025
-
[4]
A survey on deep learning and explainability for automatic report generation from medical images,
P. Messina, P. Pino, D. Parra, A. Soto, C. Besa, S. Uribe, M. And ´ıa, C. Tejos, C. Prieto, and D. Capurro, “A survey on deep learning and explainability for automatic report generation from medical images,” ACM Computing Surveys (CSUR), vol. 54, no. 10s, pp. 1–40, 2022
2022
-
[5]
Fir-rad: Fine- grained reinforcement with structured reasoning for chest x-ray report generation,
X. Mei, L. Yang, D. Gao, X. Cai, J. Han, and T. Liu, “Fir-rad: Fine- grained reinforcement with structured reasoning for chest x-ray report generation,”IEEE Transactions on Medical Imaging, 2026
2026
-
[6]
Initial assessment and treatment with the airway, breathing, circulation, disability, exposure (abcde) approach,
T. Thim, N. H. V . Krarup, E. L. Grove, C. V . Rohde, and B. Løfgren, “Initial assessment and treatment with the airway, breathing, circulation, disability, exposure (abcde) approach,”International journal of general medicine, pp. 117–121, 2012
2012
-
[7]
Automated radiology report generation using conditioned transformers,
O. Alfarghaly, R. Khaled, A. Elkorany, M. Helal, and A. Fahmy, “Automated radiology report generation using conditioned transformers,” Informatics in Medicine Unlocked, vol. 24, p. 100557, 2021
2021
-
[9]
Adapter-enhanced hierarchical cross-modal pre-training for lightweight medical report generation,
T. Yu, W. Lu, Y . Yang, W. Han, Q. Huang, J. Yu, and K. Zhang, “Adapter-enhanced hierarchical cross-modal pre-training for lightweight medical report generation,”IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[10]
Diagnostic captioning by cooperative task interactions and sample-graph consistency,
Z. Wang, L. Wang, X. Li, and L. Zhou, “Diagnostic captioning by cooperative task interactions and sample-graph consistency,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[11]
A logical calculus of the ideas immanent in nervous activity,
W. S. McCulloch and W. Pitts, “A logical calculus of the ideas immanent in nervous activity,”The bulletin of mathematical biophysics, vol. 5, pp. 115–133, 1943
1943
-
[12]
Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position,
K. Fukushima, “Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position,” Biological cybernetics, vol. 36, no. 4, pp. 193–202, 1980
1980
-
[13]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2017, pp. 4700–4708
2017
-
[14]
Learning repre- sentations by back-propagating errors,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning repre- sentations by back-propagating errors,”nature, vol. 323, no. 6088, pp. 533–536, 1986
1986
-
[15]
Reinforcement learning: an introduction, by sutton, rs and barto, ag,
P. R. Montague, “Reinforcement learning: an introduction, by sutton, rs and barto, ag,”Trends in cognitive sciences, vol. 3, no. 9, p. 360, 1999
1999
-
[16]
Deep reinforce- ment learning-based image captioning with embedding reward,
Z. Ren, X. Wang, N. Zhang, X. Lv, and L.-J. Li, “Deep reinforce- ment learning-based image captioning with embedding reward,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 290–298
2017
-
[17]
Multi-grained radiology report generation with sentence-level image-language contrastive learning,
A. Liu, Y . Guo, J.-h. Yong, and F. Xu, “Multi-grained radiology report generation with sentence-level image-language contrastive learning,” IEEE Transactions on Medical Imaging, vol. 43, no. 7, pp. 2657–2669, 2024
2024
-
[18]
Lhr-rfl: Linear hybrid-reward-based reinforced focal learning for automatic radiology report generation,
X. Yi, Y . Fu, J. Yu, R. Liu, H. Zhang, and R. Hua, “Lhr-rfl: Linear hybrid-reward-based reinforced focal learning for automatic radiology report generation,”IEEE Transactions on Medical Imaging, vol. 44, no. 3, pp. 1494–1504, 2024
2024
-
[19]
Enhancing radiology report generation via multi-phased supervision,
Z. Chen, Y . Li, Z. Wang, P. Gao, J. Barthelemy, L. Zhou, and L. Wang, “Enhancing radiology report generation via multi-phased supervision,” IEEE Transactions on Medical Imaging, 2025
2025
-
[20]
Cnn-o-elmnet: Optimized lightweight and generalized model for lung disease classification and severity assessment,
S. Agarwal, K. Arya, and Y . K. Meena, “Cnn-o-elmnet: Optimized lightweight and generalized model for lung disease classification and severity assessment,”IEEE Transactions on Medical Imaging, 2024
2024
-
[21]
Multifusionnet: multilayer multimodal fusion of deep neural networks for chest x-ray image classification,
——, “Multifusionnet: multilayer multimodal fusion of deep neural networks for chest x-ray image classification,”Soft Computing, pp. 1–17, 2024
2024
-
[22]
Cxrnet: Cnn-attention based cxr image classifier,
S. Agarwal and K. Arya, “Cxrnet: Cnn-attention based cxr image classifier,”Expert Systems, p. e13423, 2024
2024
-
[23]
A com- prehensive survey of deep learning in the field of medical imaging and medical natural language processing: Challenges and research directions,
B. Pandey, D. K. Pandey, B. P. Mishra, and W. Rhmann, “A com- prehensive survey of deep learning in the field of medical imaging and medical natural language processing: Challenges and research directions,”Journal of King Saud University-Computer and Information Sciences, vol. 34, no. 8, pp. 5083–5099, 2022
2022
-
[24]
Deep learning approaches to auto- matic radiology report generation: A systematic review,
Y . Liao, H. Liu, and I. Spasi ´c, “Deep learning approaches to auto- matic radiology report generation: A systematic review,”Informatics in Medicine Unlocked, p. 101273, 2023
2023
-
[25]
Trans- parency of deep neural networks for medical image analysis: A review of interpretability methods,
Z. Salahuddin, H. C. Woodruff, A. Chatterjee, and P. Lambin, “Trans- parency of deep neural networks for medical image analysis: A review of interpretability methods,”Computers in biology and medicine, vol. 140, p. 105111, 2022
2022
-
[26]
On the automatic generation of medical imaging reports,
B. Jing, P. Xie, and E. Xing, “On the automatic generation of medical imaging reports,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2018. [Online]. Available: http://dx.doi.org/10.18653/v1/P18-1240
-
[27]
Explainable artificial intelligence (xai) in deep learning-based medical image analysis,
B. H. Van der Velden, H. J. Kuijf, K. G. Gilhuijs, and M. A. Viergever, “Explainable artificial intelligence (xai) in deep learning-based medical image analysis,”Medical Image Analysis, vol. 79, p. 102470, 2022
2022
-
[28]
Efficient evolving deep ensemble medical image captioning network,
D. Singh, M. Kaur, J. M. Alanazi, A. A. AlZubi, and H.-N. Lee, “Efficient evolving deep ensemble medical image captioning network,” IEEE Journal of Biomedical and Health Informatics, vol. 27, no. 2, pp. 1016–1025, 2022. 9
2022
-
[29]
Translating medical im- age to radiological report: Adaptive multilevel multi-attention approach,
G. O. Gajbhiye, A. V . Nandedkar, and I. Faye, “Translating medical im- age to radiological report: Adaptive multilevel multi-attention approach,” Computer Methods and Programs in Biomedicine, vol. 221, p. 106853, 2022
2022
-
[30]
Tienet: Text- image embedding network for common thorax disease classification and reporting in chest x-rays,
X. Wang, Y . Peng, L. Lu, Z. Lu, and R. M. Summers, “Tienet: Text- image embedding network for common thorax disease classification and reporting in chest x-rays,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9049–9058
2018
-
[31]
Topic-oriented image captioning based on order-embedding,
N. Yu, X. Hu, B. Song, J. Yang, and J. Zhang, “Topic-oriented image captioning based on order-embedding,”IEEE Transactions on Image Processing, vol. 28, no. 6, pp. 2743–2754, 2018
2018
-
[32]
Retrieval topic recurrent memory network for remote sensing image captioning,
B. Wang, X. Zheng, B. Qu, and X. Lu, “Retrieval topic recurrent memory network for remote sensing image captioning,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 13, pp. 256–270, 2020
2020
-
[33]
Vaa: Visual aligning attention model for remote sensing image captioning,
Z. Zhang, W. Zhang, W. Diao, M. Yan, X. Gao, and X. Sun, “Vaa: Visual aligning attention model for remote sensing image captioning,” IEEE Access, vol. 7, pp. 137 355–137 364, 2019
2019
-
[34]
Re-caption: Saliency-enhanced image captioning through two-phase learning,
L. Zhou, Y . Zhang, Y .-G. Jiang, T. Zhang, and W. Fan, “Re-caption: Saliency-enhanced image captioning through two-phase learning,”IEEE Transactions on Image Processing, vol. 29, pp. 694–709, 2019
2019
-
[35]
Cross-domain image captioning via cross- modal retrieval and model adaptation,
W. Zhao, X. Wu, and J. Luo, “Cross-domain image captioning via cross- modal retrieval and model adaptation,”IEEE Transactions on Image Processing, vol. 30, pp. 1180–1192, 2020
2020
-
[36]
Mul- titask learning for cross-domain image captioning,
M. Yang, W. Zhao, W. Xu, Y . Feng, Z. Zhao, X. Chen, and K. Lei, “Mul- titask learning for cross-domain image captioning,”IEEE Transactions on Multimedia, vol. 21, no. 4, pp. 1047–1061, 2018
2018
-
[37]
Self-guiding multimodal lstm—when we do not have a perfect training dataset for image captioning,
Y . Xian and Y . Tian, “Self-guiding multimodal lstm—when we do not have a perfect training dataset for image captioning,”IEEE Transactions on Image Processing, vol. 28, no. 11, pp. 5241–5252, 2019
2019
-
[38]
Deep Reinforcement Learning: An Overview
Y . Li, “Deep reinforcement learning: An overview,”arXiv preprint arXiv:1701.07274, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Clinically accurate chest x-ray report generation,
G. Liu, T.-M. H. Hsu, M. McDermott, W. Boag, W.-H. Weng, P. Szolovits, and M. Ghassemi, “Clinically accurate chest x-ray report generation,” inMachine Learning for Healthcare Conference. PMLR, 2019, pp. 249–269
2019
-
[40]
Reinforced transformer for medical image captioning,
Y . Xiong, B. Du, and P. Yan, “Reinforced transformer for medical image captioning,” inMachine Learning in Medical Imaging: 10th International Workshop, MLMI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, October 13, 2019, Proceedings 10. Springer, 2019, pp. 673–680
2019
-
[41]
An ensemble of generation-and retrieval-based image captioning with dual generator generative adversarial network,
M. Yang, J. Liu, Y . Shen, Z. Zhao, X. Chen, Q. Wu, and C. Li, “An ensemble of generation-and retrieval-based image captioning with dual generator generative adversarial network,”IEEE Transactions on Image Processing, vol. 29, pp. 9627–9640, 2020
2020
-
[42]
Exploring multi-level attention and se- mantic relationship for remote sensing image captioning,
Z. Yuan, X. Li, and Q. Wang, “Exploring multi-level attention and se- mantic relationship for remote sensing image captioning,”IEEE Access, vol. 8, pp. 2608–2620, 2019
2019
-
[43]
Denoising-based multiscale feature fusion for remote sensing image captioning,
W. Huang, Q. Wang, and X. Li, “Denoising-based multiscale feature fusion for remote sensing image captioning,”IEEE Geoscience and Remote Sensing Letters, vol. 18, no. 3, pp. 436–440, 2020
2020
-
[44]
Multimodal transformer with multi- view visual representation for image captioning,
J. Yu, J. Li, Z. Yu, and Q. Huang, “Multimodal transformer with multi- view visual representation for image captioning,”IEEE transactions on circuits and systems for video technology, vol. 30, no. 12, pp. 4467– 4480, 2019
2019
-
[45]
Medical image captioning using cvt and distillgpt2,
K. Kar, S. Nishad, J. Rout, A. Soni, and S. K. Nanda, “Medical image captioning using cvt and distillgpt2,” in2024 Second International Conference on Advances in Information Technology (ICAIT), vol. 1. IEEE, 2024, pp. 1–6
2024
-
[46]
Chestx-transcribe: a multimodal transformer for automated radiology report generation from chest x-rays,
P. Singh and S. Singh, “Chestx-transcribe: a multimodal transformer for automated radiology report generation from chest x-rays,”Frontiers in Digital Health, vol. 7, p. 1535168, 2025
2025
-
[47]
Knowing when to look: Adaptive attention via a visual sentinel for image captioning,
J. Lu, C. Xiong, D. Parikh, and R. Socher, “Knowing when to look: Adaptive attention via a visual sentinel for image captioning,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 375–383
2017
-
[48]
Metransformer: Radiology report generation by transformer with multiple learnable expert tokens,
Z. Wang, L. Liu, L. Wang, and L. Zhou, “Metransformer: Radiology report generation by transformer with multiple learnable expert tokens,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 558–11 567
2023
-
[49]
Generating radiology re- ports via memory-driven transformer,
Z. Chen, Y . Song, T.-H. Chang, and X. Wan, “Generating radiology re- ports via memory-driven transformer,”arXiv preprint arXiv:2010.16056, 2020
-
[50]
Hybrid retrieval-generation reinforced agent for medical image report generation,
Y . Li, X. Liang, Z. Hu, and E. P. Xing, “Hybrid retrieval-generation reinforced agent for medical image report generation,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[51]
Exploring and distilling posterior and prior knowledge for radiology report generation,
F. Liu, X. Wu, S. Ge, W. Fan, and Y . Zou, “Exploring and distilling posterior and prior knowledge for radiology report generation,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13 753–13 762
2021
-
[52]
Automated radiographic report generation purely on transformer: A multicriteria supervised approach,
Z. Wang, H. Han, L. Wang, X. Li, and L. Zhou, “Automated radiographic report generation purely on transformer: A multicriteria supervised approach,”IEEE Transactions on Medical Imaging, vol. 41, no. 10, pp. 2803–2813, 2022
2022
-
[53]
Kiut: Knowledge-injected u- transformer for radiology report generation,
Z. Huang, X. Zhang, and S. Zhang, “Kiut: Knowledge-injected u- transformer for radiology report generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 809–19 818
2023
-
[54]
Preparing a collection of radiology examinations for distribution and retrieval,
D. Demner-Fushman, M. D. Kohli, M. B. Rosenman, S. E. Shooshan, L. Rodriguez, S. Antani, G. R. Thoma, and C. J. McDonald, “Preparing a collection of radiology examinations for distribution and retrieval,” Journal of the American Medical Informatics Association, vol. 23, no. 2, pp. 304–310, 2016
2016
-
[55]
Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports,
A. E. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Greenbaum, M. P. Lungren, C.-y. Deng, R. G. Mark, and S. Horng, “Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports,”Scientific Data, vol. 6, no. 1, p. 317, 2019
2019
-
[56]
Automated generation of accurate\& fluent medical x-ray reports,
H. T. Nguyen, D. Nie, T. Badamdorj, Y . Liu, Y . Zhu, J. Truong, and L. Cheng, “Automated generation of accurate\& fluent medical x-ray reports,”ArXiv preprint arXiv:2108.12126, 2021
-
[57]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
2002
-
[58]
Cider: Consensus- based image description evaluation,
R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus- based image description evaluation,” inProceedings of the IEEE confer- ence on Computer Vision and Pattern Recognition, 2015, pp. 4566–4575
2015
-
[59]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” inText summarization branches out, 2004, pp. 74–81
2004
-
[60]
Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,” inProceedings of the ACL workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72
2005
-
[61]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inProceedings of the IEEE International Conference on Computer Vision, 2017, pp. 618–626
2017
-
[62]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in3rd International Conference on Learning Representations, ICLR, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.