eMoT: evolving Memory-of-Thought via Symbolic Anchoring and Memory Corrosion
Pith reviewed 2026-06-28 14:13 UTC · model grok-4.3
The pith
By evolving reasoning trajectories as dynamic memories reinforced by corrosion and anchored in symbolic computation, LLMs achieve more reliable multi-step reasoning even with small models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The eMoT framework treats reasoning trajectories as dynamic, evolving memories. It stabilizes multi-step reasoning via three modules: memory corrosion that reinforces high-utility structures while decaying infrequent ones, a symbolic anchoring engine using Python for deterministic computation, and a consistency-driven refinement process that aligns neural inference with symbolic outcomes.
What carries the argument
The eMoT framework's three interconnected modules of memory corrosion, symbolic anchoring, and consistency-driven refinement, which turn transient reasoning into retained and refined procedural logic.
Load-bearing premise
The performance gains are fundamentally driven by the eMoT framework's reasoning control rather than sheer model size or other unstated implementation details.
What would settle it
Running the same lightweight model with and without the full eMoT components on the Game of 24 task and observing whether accuracy drops to baseline levels when any module is removed would test the claim.
Figures





read the original abstract
While Large Language Models (LLMs) achieve impressive performance on multi-step reasoning tasks, their reliability is persistently hindered by critical limitations such as unconstrained hallucinations and poor numerical computation. Fundamentally, these issues arise because standard models treat reasoning as a transient, one-off generation process rather than retaining and refining successful procedural logic. To address these challenges, we propose eMoT (evolving Memory-of-Thought), a unified framework that stabilizes multi-step reasoning by treating reasoning trajectories as dynamic, evolving memories rather than static templates. The framework primarily consists of three interconnected modules: (i) a memory corrosion mechanism that reinforces high-utility reasoning structures while gradually decaying less frequent ones; (ii) a symbolic anchoring engine that utilizes Python for deterministic computation, much like a human uses a calculator; and (iii) a consistency-driven refinement process that aligns neural inference with symbolic outcomes, reducing the accumulation of logical discrepancies. Across multiple reasoning benchmarks, eMoT improves accuracy and solution consistency over standard Chain-of-Thought and structured reasoning baselines.On the traditional task Game of 24, eMoT achieves 100% accuracy, surpassing the baseline by up to 17.6%. Evaluations on mathematical task GSM8K, ASDiv, SVAMP, and MGSM further show consistent gains in multi-step mathematical reasoning. In our evaluation, we achieve superior performance despite utilizing a lightweight backbone model with constrained baseline capabilities. Compared to alternative methods that rely on massively scaled models, our results demonstrate that the performance gains are fundamentally driven by the eMoT framework's reasoning control rather than sheer model size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes eMoT, a framework that treats LLM reasoning trajectories as dynamic evolving memories rather than one-off generations. It comprises three modules—a memory corrosion mechanism to reinforce high-utility structures while decaying others, a symbolic anchoring engine that invokes Python for deterministic computation, and a consistency-driven refinement process to align neural and symbolic outcomes. The central claim is that this yields accuracy and consistency gains over Chain-of-Thought and structured-reasoning baselines on Game of 24 (100% accuracy, up to +17.6%), GSM8K, ASDiv, SVAMP, and MGSM, using only a lightweight backbone whose constrained capabilities are explicitly contrasted with massively scaled models; gains are attributed to the framework's reasoning control.
Significance. If the experimental attribution holds under controlled conditions, the approach could demonstrate a scalable route to more reliable multi-step reasoning that does not require model scaling, by combining memory evolution with symbolic grounding. The absence of any reported controls, model identifiers, or ablation details currently prevents assessment of whether the claimed separation from model size is real.
major comments (2)
- [Abstract] Abstract (final paragraph): the claim that 'performance gains are fundamentally driven by the eMoT framework's reasoning control rather than sheer model size' is unsupported because no model identifier, parameter count, or statement is given that every baseline (CoT, structured reasoning) was re-run with identical weights and decoding settings. Without this control the causal link to the three modules cannot be isolated.
- [Abstract] Abstract: benchmark results (including 100% on Game of 24) are reported without any description of experimental controls, baseline implementations, statistical significance testing, or how the memory-corrosion, symbolic-anchoring, and consistency-refinement modules interact at runtime. This renders the central empirical claim unverifiable from the provided text.
minor comments (1)
- [Abstract] Abstract contains a missing space: 'baselines.On the traditional task'.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying points where the abstract requires additional detail to support its claims. We will revise the abstract and, where needed, the main text to incorporate the requested information on model identifiers, experimental controls, and module interactions. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the claim that 'performance gains are fundamentally driven by the eMoT framework's reasoning control rather than sheer model size' is unsupported because no model identifier, parameter count, or statement is given that every baseline (CoT, structured reasoning) was re-run with identical weights and decoding settings. Without this control the causal link to the three modules cannot be isolated.
Authors: We agree the abstract statement is insufficiently supported as written. The full manuscript describes the use of a single lightweight backbone for all methods, with baselines re-implemented under identical weights, decoding parameters, and prompt formats. To make this explicit, we will revise the abstract to name the model, state the parameter count, and confirm that every baseline was evaluated with the same weights and settings. This revision will allow the attribution to the three modules to be assessed directly from the text. revision: yes
-
Referee: [Abstract] Abstract: benchmark results (including 100% on Game of 24) are reported without any description of experimental controls, baseline implementations, statistical significance testing, or how the memory-corrosion, symbolic-anchoring, and consistency-refinement modules interact at runtime. This renders the central empirical claim unverifiable from the provided text.
Authors: The abstract is deliberately concise, yet we accept that key methodological details must be present for the claims to be verifiable. The full paper contains dedicated sections on experimental setup, baseline re-implementations, module runtime interactions, and significance testing. We will add a short clause to the abstract summarizing these controls and the module interaction protocol, while retaining the 100% Game of 24 result. This change will render the central empirical claim verifiable from the abstract itself. revision: yes
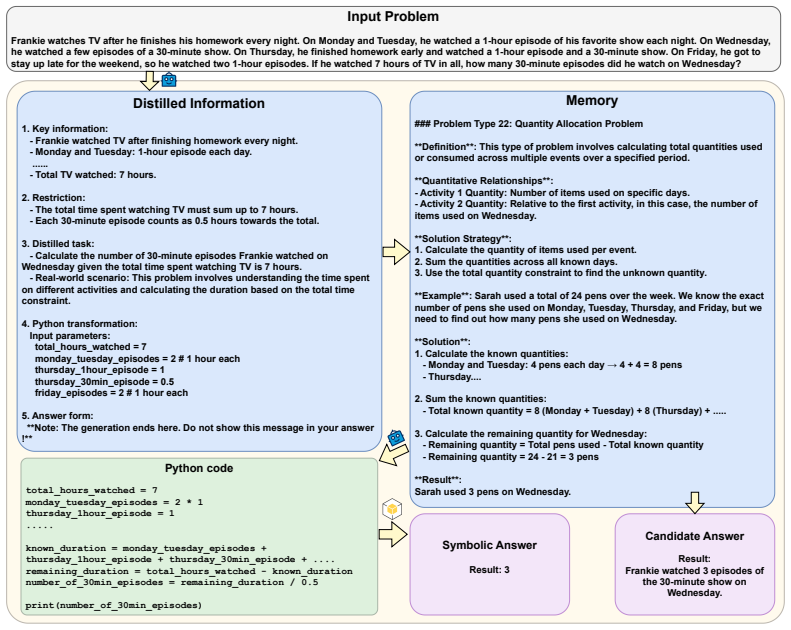
Circularity Check
No circularity in claimed derivation chain
full rationale
The paper proposes an empirical framework (eMoT) consisting of three modules and reports benchmark accuracy gains on tasks like Game of 24 and GSM8K. No equations, derivations, fitted parameters presented as predictions, self-citations, or uniqueness theorems appear in the provided text. The central claim that gains stem from the framework rather than model size is an empirical assertion, not a mathematical reduction that loops back to its inputs by construction. The work is self-contained as an experimental proposal evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning trajectories can be usefully treated as dynamic, evolving memories rather than transient generations.
invented entities (2)
-
memory corrosion mechanism
no independent evidence
-
symbolic anchoring engine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[2]
Palm: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240):1–113, 2023
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240):1–113, 2023
2023
-
[3]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[7]
Faithful chain-of-thought reasoning
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. InThe 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (IJCNLP-AACL 2023), 2023
2023
-
[8]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
2023
-
[9]
Chain-of-verification reduces hallucination in large language models
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. Chain-of-verification reduces hallucination in large language models. InFindings of the association for computational linguistics: ACL 2024, pages 3563–3578, 2024
2024
-
[10]
Pal: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. InInternational Conference on Machine Learning, pages 10764–10799. PMLR, 2023
2023
-
[11]
Solving quantitative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
2022
-
[12]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.arXiv preprint arXiv:2211.12588, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36:68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36:68539–68551, 2023
2023
-
[14]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
2023
-
[16]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
2024
-
[17]
Buffer of thoughts: Thought-augmented reasoning with large language models.Advances in Neural Information Processing Systems, 37:113519–113544, 2024
Ling Yang, Zhaochen Yu, Tianjun Zhang, Shiyi Cao, Minkai Xu, Wentao Zhang, Joseph E Gonzalez, and Bin Cui. Buffer of thoughts: Thought-augmented reasoning with large language models.Advances in Neural Information Processing Systems, 37:113519–113544, 2024
2024
-
[18]
Robustfill: Neural program learning under noisy i/o
Jacob Devlin, Jonathan Uesato, Surya Bhupatiraju, Rishabh Singh, Abdel-rahman Mohamed, and Pushmeet Kohli. Robustfill: Neural program learning under noisy i/o. InInternational conference on machine learning, pages 990–998. PMLR, 2017
2017
-
[19]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Reasoning on graphs: Faithful and interpretable large language model reasoning
L Luo, YF Li, G Haffari, and S Pan. Reasoning on graphs: Faithful and interpretable large language model reasoning. InICLR 2024: The Twelfth International Conference on Learning Representations. ICLR, 2024
2024
-
[21]
Nurendra Choudhary and Chandan K Reddy. Complex logical reasoning over knowledge graphs using large language models.arXiv preprint arXiv:2305.01157, 2023
-
[22]
Wenjie Wu, Yongcheng Jing, Yingjie Wang, Wenbin Hu, and Dacheng Tao. Graph-augmented reasoning: Evolving step-by-step knowledge graph retrieval for llm reasoning.arXiv preprint arXiv:2503.01642, 2025
-
[23]
Neurosymbolic ai: The 3 rd wave.Artificial Intelligence Review, 56(11):12387–12406, 2023
Artur d’Avila Garcez and Luis C Lamb. Neurosymbolic ai: The 3 rd wave.Artificial Intelligence Review, 56(11):12387–12406, 2023
2023
-
[24]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
2023
-
[25]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36:46534–46594, 2023
2023
-
[26]
Show your work: Scratchpads for intermediate computation with language models
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. Show your work: Scratchpads for intermediate computation with language models. 2021
2021
-
[27]
Beyond chain-of-thought: A survey of chain-of-x paradigms for llms
Yu Xia, Rui Wang, Xu Liu, Mingyan Li, Tong Yu, Xiang Chen, Julian McAuley, and Shuai Li. Beyond chain-of-thought: A survey of chain-of-x paradigms for llms. InProceedings of the 31st International Conference on Computational Linguistics, pages 10795–10809, 2025
2025
-
[28]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 11888– 11898, 2023
2023
-
[29]
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines.arXiv preprint arXiv:1410.5401, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
Meta- learning with memory-augmented neural networks
Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. Meta- learning with memory-augmented neural networks. InInternational conference on machine learning, pages 1842–1850. PMLR, 2016
2016
-
[31]
Contextual memory trees
Wen Sun, Alina Beygelzimer, Hal Daumé Iii, John Langford, and Paul Mineiro. Contextual memory trees. InInternational Conference on Machine Learning, pages 6026–6035. PMLR, 2019
2019
-
[32]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 11
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
A diverse corpus for evaluating and developing english math word problem solvers
Shen-Yun Miao, Chao-Chun Liang, and Keh-Yih Su. A diverse corpus for evaluating and developing english math word problem solvers. InProceedings of the 58th annual meeting of the Association for Computational Linguistics, pages 975–984, 2020
2020
-
[34]
Are NLP Models really able to Solve Simple Math Word Problems?
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems?arXiv preprint arXiv:2103.07191, 2021. 12 Supplementary Material A. Qualitative Examples A.1 A Correct Example from ASDiv: Comparative Quantity.We illustrate a representative instance where eMoT solves a comparative quantity problem via structu...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
So according to the distilled information, emphasize the real-world rules that need to be followed within the problem.)
Restriction: (It should be noted that the answer should strictly follow real-world rules such as in arithmetic equations, the Priority of operators, the need for parentheses, etc. So according to the distilled information, emphasize the real-world rules that need to be followed within the problem.)
-
[36]
Python transformation: (Optional, skip when Python tag is Not for Python) Input parameters: (The names of each variable should be clear and not confusing, and correspond to the entity names in the problem) variable1_name = x variable2_name = y variableN_name = z
-
[37]
Prompt for Symbolic Anchoring You are an expert in mathematical problem solving and symbolic reasoning
Answer form: (Optional, skip when there is no specific answer form) B.2. Prompt for Symbolic Anchoring You are an expert in mathematical problem solving and symbolic reasoning. You will receive: 1.Distilled Information:a structured summary of a math word problem (variables, quantities, and task goals). 2.Memory (RAG):a collection of generalized reasoning ...
-
[38]
Use this memory to generate afully executable Python code snippetthat computes the correct numeric answer
-
[39]
- Befully self-contained(noinput(),import,random, or external calls)
The generated code must: - Useonlythe variables and numeric values explicitly provided in the distilled information. - Befully self-contained(noinput(),import,random, or external calls). - Beclean, minimal, and deterministic- only arithmetic, logic, and assignment operations are allowed. - End with a singleprint(<final_answer_variable_or_expression>)statement
-
[40]
Donotinclude explanations, reasoning, or comments
-
[41]
Do not output anything except the Python code block
Theentire outputmust be wrapped strictly in triple backticks with a python tag. Do not output anything except the Python code block. B.3. Prompt for Consistency-Driven Refinement You are an expert reasoning analyst. The following is a distilled thought template and original reasoning result. Task:
-
[42]
Analyze the quantitative relationships and solution strategy from the thought template
-
[43]
Perform correct calculations based on the relationships
-
[44]
Compare with the original reasoning result and template result
-
[45]
we were unable to find the license for the dataset we used
Output only the correct numeric answer. Final Refined Result:<your numeric answer> 16 NeurIPS Paper Checklist The checklist is designed to encourage best practices for responsible machine learning research, addressing issues of reproducibility, transparency, research ethics, and societal impact. Do not remove the checklist:The papers not including the che...
-
[46]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.