Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories
Pith reviewed 2026-06-28 14:10 UTC · model grok-4.3
The pith
DRIFT tracks agent claims and their evidence support to locate error spans up to 30 points more accurately than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
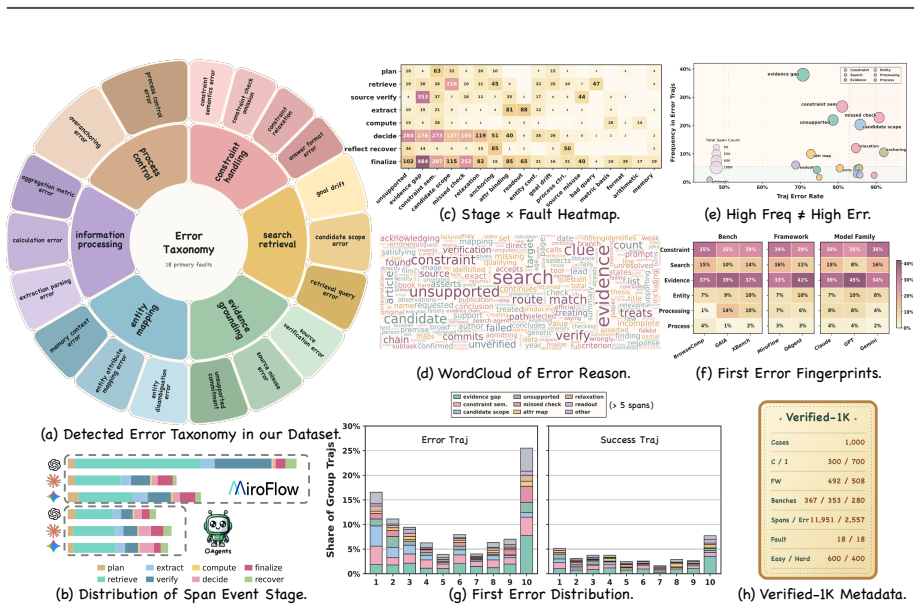
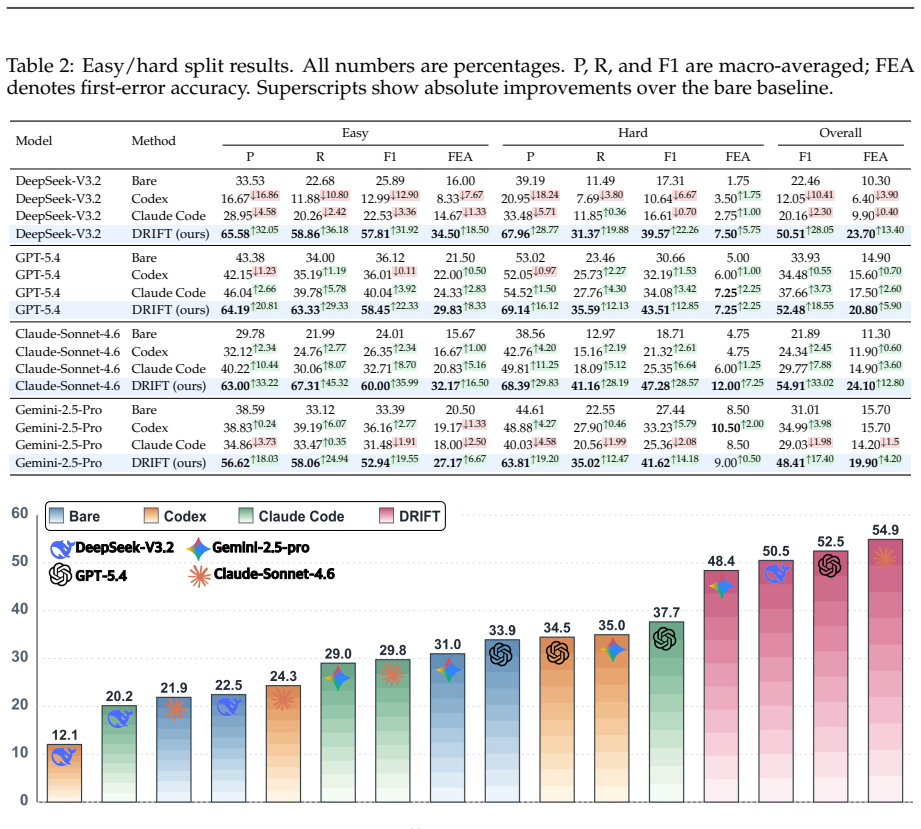
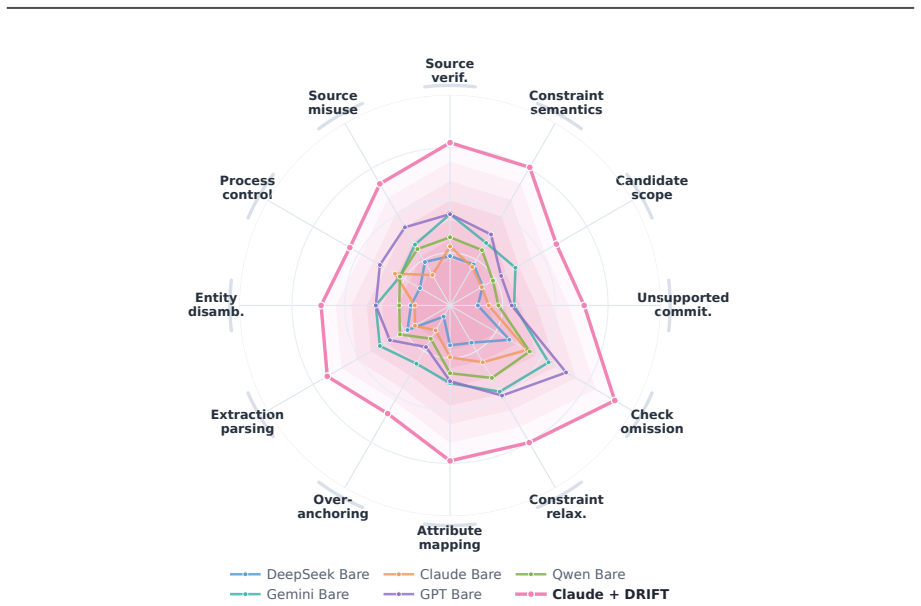
The central claim is that DRIFT, by tracking the claims an agent advances through its trajectory, checking their support against collected evidence, and marking the spans where unsupported or conflicting claims shape the answer path, achieves up to 30 percentage points higher span-level error localization and first-error accuracy than existing auditing frameworks on the TELBench benchmark built from 2,790 annotated trajectories across three agent frameworks, three backbone models, and three benchmarks.
What carries the argument
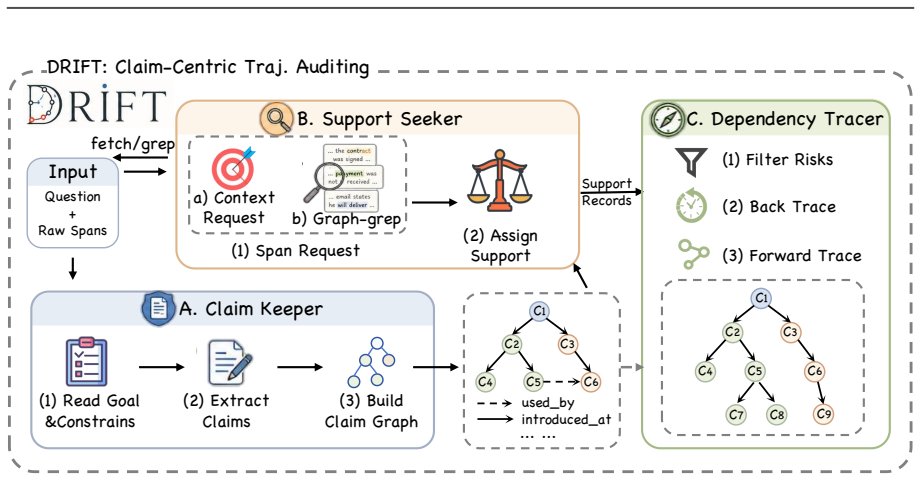
DRIFT, a claim-centric auditing framework that tracks agent claims, checks their support in trajectory evidence, and marks spans where unsupported or conflicting claims affect the answer path.
If this is right
- Evaluation of deep-research agents can shift from final-answer success to identifying the specific trajectory spans that introduce unreliability.
- First-error detection improves, enabling earlier diagnosis of where an agent path diverges from reliable evidence.
- The same claim-support auditing approach applies across different backbone models and agent frameworks without retraining.
- Process-level reliability metrics become feasible for long-horizon agent tasks that combine search, tool use, and synthesis.
Where Pith is reading between the lines
- DRIFT-style claim tracking could be inserted into agent training loops to penalize or correct unsupported steps before they reach the final answer.
- The TELBench construction method offers a template for building similar error-span benchmarks in other multi-step domains such as code generation or scientific reasoning agents.
- If the claim-support check proves robust, it could serve as a lightweight runtime monitor that halts or reroutes an agent when an unsupported claim appears.
Load-bearing premise
The LLM-assisted expert review process produces reliable ground-truth labels for harmful error spans in the collected trajectories.
What would settle it
An independent large-scale human re-annotation of a random subset of TELBench spans that shows substantial disagreement with the LLM-assisted labels, or a replication study on fresh trajectories where DRIFT shows no accuracy gain over baselines.
Figures





read the original abstract
Deep-research agents solve tasks through long trajectories of search, tool use, evidence inspection, and answer synthesis. Evaluation based on final answers shows whether an agent succeeds, but not which parts of the trajectory make the answer unreliable. We study span-level error localization for deep-research agents. We collect 2,790 real trajectories from two agent frameworks, three backbone models, and three benchmarks, convert raw logs into semantic spans, and annotate harmful error spans through LLM-assisted expert review. From these annotations, we build TELBench, a 1,000-instance benchmark for identifying error spans among normal exploration, failed searches, tentative hypotheses, and harmless noise. We further propose DRIFT, a claim-centric auditing framework that tracks agent claims, checks their support in trajectory evidence, and marks spans where unsupported or conflicting claims affect the answer path. Experiments across model families and auditing frameworks show that DRIFT improves span-level error localization and first-error accuracy by up to 30 percentage points. Our work provides a process-level view of reliability in deep-research agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TELBench, a 1,000-instance benchmark for span-level error localization in deep-research agent trajectories, built from 2,790 trajectories collected from two agent frameworks, three backbone models, and three benchmarks. Trajectories are converted to semantic spans and annotated for harmful errors using LLM-assisted expert review, resulting in a 1,000-instance test set. The authors propose DRIFT, a claim-centric auditing framework that tracks claims, verifies support in evidence, and identifies error spans. Experiments demonstrate that DRIFT achieves up to 30 percentage point improvements in span-level error localization and first-error accuracy compared to other auditing frameworks across different models.
Significance. Should the central empirical claims be substantiated, this work would make a meaningful contribution by shifting evaluation of deep-research agents from outcome-based to process-based analysis. Identifying specific error spans in long trajectories could aid in debugging and improving agent reliability. The multi-framework, multi-model data collection is a positive aspect, as is the focus on claim support checking in DRIFT. However, the significance is tempered by the need to establish the reliability of the benchmark labels independently of the proposed method.
major comments (3)
- [Benchmark Construction] The paper's reliance on LLM-assisted expert review to annotate harmful error spans in TELBench (as described in the abstract) introduces a risk of circularity. The reported gains of DRIFT are measured against these labels, yet no validation of the annotation process (e.g., inter-annotator agreement or comparison to pure human annotations) is mentioned. If the LLM component shares biases with the auditing frameworks, the 30pp improvement may not reflect true superiority.
- [Experimental Evaluation] The claim of up to 30 percentage points improvement in span-level error localization and first-error accuracy lacks supporting details on baselines, data splits for the 1,000-instance TELBench, statistical significance, or variance across the three backbone models. This makes it difficult to evaluate the robustness of the results.
- [DRIFT Framework] The description of how DRIFT 'marks spans where unsupported or conflicting claims affect the answer path' is high-level and does not provide the algorithmic details or pseudocode necessary to understand or replicate the claim-checking and span-marking process.
minor comments (2)
- [Abstract] The abstract mentions 'three benchmarks' but does not specify which ones; this should be clarified early in the paper.
- Consider adding a limitations section discussing the generalizability of TELBench beyond the collected 2,790 trajectories.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of TELBench and DRIFT.
read point-by-point responses
-
Referee: [Benchmark Construction] The paper's reliance on LLM-assisted expert review to annotate harmful error spans in TELBench (as described in the abstract) introduces a risk of circularity. The reported gains of DRIFT are measured against these labels, yet no validation of the annotation process (e.g., inter-annotator agreement or comparison to pure human annotations) is mentioned. If the LLM component shares biases with the auditing frameworks, the 30pp improvement may not reflect true superiority.
Authors: We acknowledge the risk of circularity. The process used LLM assistance solely for initial candidate span identification, with all final labels determined by expert reviewers applying explicit guidelines focused on harmful errors that affect answer reliability. To address this, the revision will include a detailed annotation protocol section describing expert instructions and bias-mitigation steps. We will also add a small-scale validation comparing LLM-assisted labels against independent pure-human annotations on a held-out subset of trajectories. This directly substantiates label reliability independent of DRIFT. revision: yes
-
Referee: [Experimental Evaluation] The claim of up to 30 percentage points improvement in span-level error localization and first-error accuracy lacks supporting details on baselines, data splits for the 1,000-instance TELBench, statistical significance, or variance across the three backbone models. This makes it difficult to evaluate the robustness of the results.
Authors: We agree additional experimental details are required. The revision will specify the exact train/dev/test splits of the 1,000-instance TELBench, enumerate all baselines, report per-setting results with statistical significance tests, and break down performance and variance across the three backbone models. The reported maximum of 30 percentage points is the largest observed delta; full tables will clarify the distribution of gains. revision: yes
-
Referee: [DRIFT Framework] The description of how DRIFT 'marks spans where unsupported or conflicting claims affect the answer path' is high-level and does not provide the algorithmic details or pseudocode necessary to understand or replicate the claim-checking and span-marking process.
Authors: We will expand the DRIFT section with explicit algorithmic steps and pseudocode covering claim extraction, evidence verification against trajectory spans, conflict detection, and the marking of spans that influence the final answer path. This will enable full replication. revision: yes
Circularity Check
No circularity; benchmark labels and evaluations are externally grounded
full rationale
The paper constructs TELBench by collecting 2,790 trajectories, converting them to semantic spans, and applying LLM-assisted expert review to produce ground-truth harmful error span labels. DRIFT is then defined as a separate claim-centric auditing process that tracks claims and checks support in evidence. Experiments measure DRIFT's improvements against these pre-existing labels on held-out instances. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the central empirical claims rest on independent annotations rather than quantities defined in terms of DRIFT itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-assisted expert review produces accurate labels for harmful error spans
invented entities (2)
-
TELBench
no independent evidence
-
DRIFT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Seeing the Whole Elephant: A Benchmark for Failure Attribution in LLM-based Multi-Agent Systems
URLhttps://api.semanticscholar.org/CorpusID:281830069. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, editors,International Conference on Learning Representation...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/coli.07-034-r2 2024
-
[2]
The trajectory first explores several snooker events and players, but introduces the 2021 UK Championship Final before validating the complete conjunction of constraints
2021
-
[3]
Luca Brecel as a strong candidate and begins extracting facts about that match
It then treats Zhao Xintong vs. Luca Brecel as a strong candidate and begins extracting facts about that match
-
[4]
The decisive local contradiction appears when Zhao Xintong’s professional year is used for the losing-player constraint, although Zhao was the winner
-
[5]
Later retrieval focuses on the referee and tries to patch the same candidate branch instead of reopening the match search
-
[6]
strong candidate
The final answer fails because the trajectory never recovers from the initial wrong-candidate commitment. Local trajectory slice. s001 – Premature candidate introduction(wrong candidate commitment) Trace excerpt.The trajectory searches professional years and break statistics, tries Kyren Wilson, Luca Brecel, and 2020 World Championship routes, then introd...
2020
-
[7]
The main agent starts from the distinctive 2018–2019 Siege of Leningrad talks condition and delegates a worker search
2018
-
[8]
The worker claims to have identified Alexis Peri as a seven-talk match
-
[9]
The visible trajectory does not provide enough retrieval evidence for the full seven-talk claim
-
[10]
The main agent nevertheless adopts the worker result and extends it with additional verification-style statements
-
[11]
Local trajectory slice
The final answer string is correct, but the trajectory overstates what has been verified. Local trajectory slice. s001 – Constraint decomposition Trace excerpt.The main agent decomposes the question and decides to start from the distinctive 2018–2019 Siege of Leningrad talks condition, then delegates a worker search. Role in chain.This is a reasonable sea...
2018
-
[12]
The trajectory first identifies the ocean liner inThe Last Voyageand links it to the October 1949 breakfast menu
1949
-
[13]
It then tries to identify fruits inEmbroidery from Uzbekistan
-
[14]
The first marked error occurs when the agent accepts an incomplete fruit list: watermelon, pears, and lemons
-
[15]
Later spans continue searching for image evidence and specifically mention pears and bananas, so the conflict is visible in the local trajectory
-
[16]
What fruits are depicted in the painting Embroidery from Uzbekistan by Janet Fish?
The second marked error occurs when the agent resolves that conflict incorrectly: it asserts that there are no bananas and treats the prompt as impossible. Local trajectory slice.Only the spans most relevant to the error chain are shown below; therefore, the numbering follows the original trajectory and is not necessarily consecutive. s001 – Task setup Tr...
1949
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.