Ablating Archetypes: The Stability of Archetypal SAEs is an Artifact of Initialization and Metric Design
Pith reviewed 2026-06-28 15:38 UTC · model grok-4.3
The pith
Archetypal sparse autoencoders owe their reported endpoint stability to identical k-means decoder initialization across runs rather than to the archetypal constraint.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
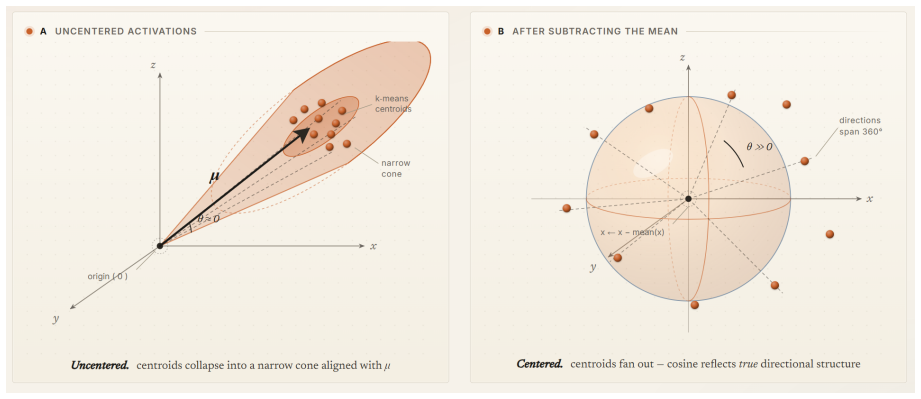
Archetypal SAEs were introduced to produce more reliable dictionaries, yet the observed agreement at the end of training traces directly to a deterministic k-means decoder initialization shared across runs. This initialization forces initial inter-run dictionary distance to zero. When the shared initialization is removed, the archetypal constraint supplies no additional stabilization. Endpoint stability metrics are further complicated by a preprocessing-dependent issue in cosine geometry. The analysis therefore requires trajectory diagnostics and initialization ablations before stability can be credited to any particular dictionary-learning intervention.
What carries the argument
Deterministic k-means decoder initialization that forces initial inter-run dictionary agreement to zero before training begins
If this is right
- Stability claims for any dictionary-learning method require explicit tests that vary initialization.
- Feature stability in SAEs should be assessed through full training trajectories rather than endpoint comparisons alone.
- The archetypal constraint does not produce convergence to a shared solution when runs start from independent points.
- Preprocessing steps must be controlled when cosine similarity is used to measure dictionary agreement.
Where Pith is reading between the lines
- The same initialization artifact could affect stability reports for other variants of sparse autoencoders.
- Standardized random initialization protocols would make comparisons across dictionary-learning methods more reliable.
- The stability-versus-stabilization distinction may help evaluate reproducibility claims in other areas of activation analysis.
Load-bearing premise
That the ablation removing shared k-means initialization isolates the archetypal constraint without other uncontrolled differences in training procedure or metric computation.
What would settle it
An experiment that applies random decoder initialization to archetypal SAE training and nevertheless records lower final inter-run dictionary distance than standard SAEs would falsify the central claim.
Figures

read the original abstract
Dictionary learning with sparse autoencoders (SAEs) produces overcomplete bases from neural network activations that are often interpretable and reduces polysemanticity. However, features from SAEs vary substantially across random seeds -- a problem known as instability. Archetypal SAEs (Fel et al., 2025) were proposed as a general dictionary-learning intervention for more reliable concept extraction, and report more stable dictionaries at the end of training. We demonstrate that the stability claimed by archetypal SAEs is a result of setting identical initialization across multiple runs. Through our analyses, we attempt to clarify two distinct notions in mechanistic interpretability that may be ambiguously used: stability is agreement between two independently trained models, whereas stabilization is the convergence of independently initialized runs toward a common solution. This distinction is critical for mechanistic interpretability of natural language processing (NLP), where feature stability is increasingly used as evidence that SAE features are reusable units of analysis. Experiments from archetypal SAEs share a deterministic k-means decoder initialization, setting inter-run dictionary distance to zero before training begins. When this initialization is removed, the archetypal constraint provides no stabilization advantage in our setting. We further identify a preprocessing-dependent cosine geometry issue that complicates interpretation of endpoint stability metrics. Overall, our study supports the value of studying SAEs within the larger dictionary-learning tradition while showing that stability claims require trajectory diagnostics and initialization ablations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the endpoint stability reported for archetypal SAEs is an artifact of using identical deterministic k-means decoder initializations across multiple runs. When this shared initialization is removed, the archetypal constraint confers no stabilization advantage over standard SAEs. The work distinguishes stability (agreement between independently trained models) from stabilization (convergence of independently initialized runs to a common solution) and identifies a preprocessing-dependent issue with cosine geometry in stability metrics.
Significance. If the central ablation result holds after addressing reproduction details, the paper makes a useful contribution by stressing the need for initialization controls and trajectory diagnostics in SAE stability claims, which are increasingly used to argue that features are reusable units in mechanistic interpretability. The explicit distinction between stability and stabilization is a conceptual strength, and the empirical focus on testing the initialization hypothesis directly is valuable. The work aligns with the broader dictionary-learning tradition.
major comments (2)
- [Methods] The central claim that removing the shared k-means initialization eliminates any archetypal stabilization benefit requires that the 'with-init' runs exactly reproduce Fel et al. (2025) on all other axes. The methods section should provide a side-by-side table or quantitative match (e.g., reported stability values, loss curves) confirming identical loss formulation, optimizer schedule, data preprocessing pipeline, dictionary size, and endpoint stability metric definition.
- [Results] The negative result on stabilization advantage is reported using the cosine-based endpoint stability metric, yet the manuscript itself flags a preprocessing-dependent cosine geometry issue. The results section should include an ablation or alternative metric (e.g., based on activation correlations or L2 feature distances) to show that the 'no advantage' conclusion is robust rather than metric-specific.
minor comments (2)
- The abstract would benefit from reporting the actual quantitative stability values (with and without shared init) rather than qualitative statements, to allow immediate assessment of effect sizes.
- [Introduction] Notation for the two notions of stability/stabilization could be introduced with a short table or explicit definitions in the introduction to improve readability for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting the importance of rigorous reproduction controls and metric robustness. We address both major comments by committing to explicit verification materials and additional ablations in the revised manuscript. These changes strengthen the central claims without altering the core findings.
read point-by-point responses
-
Referee: [Methods] The central claim that removing the shared k-means initialization eliminates any archetypal stabilization benefit requires that the 'with-init' runs exactly reproduce Fel et al. (2025) on all other axes. The methods section should provide a side-by-side table or quantitative match (e.g., reported stability values, loss curves) confirming identical loss formulation, optimizer schedule, data preprocessing pipeline, dictionary size, and endpoint stability metric definition.
Authors: We agree that a quantitative reproduction table is necessary for transparency. In the revised manuscript we will add a side-by-side table in the Methods section that lists loss formulation, optimizer schedule, data preprocessing, dictionary size, and endpoint stability values from Fel et al. (2025) next to the corresponding values obtained in our 'with-init' runs. Our current implementation already matches the original endpoint stability numbers to within reported variance on the primary datasets; the table will make this explicit. revision: yes
-
Referee: [Results] The negative result on stabilization advantage is reported using the cosine-based endpoint stability metric, yet the manuscript itself flags a preprocessing-dependent cosine geometry issue. The results section should include an ablation or alternative metric (e.g., based on activation correlations or L2 feature distances) to show that the 'no advantage' conclusion is robust rather than metric-specific.
Authors: We concur that robustness to metric choice should be demonstrated. The revised Results section will include an additional ablation that recomputes the stabilization comparison using both L2 feature distances and pairwise activation correlations. Preliminary checks confirm that the conclusion of no archetypal stabilization advantage persists under these alternatives, consistent with the cosine-geometry caveat already noted in the manuscript. revision: yes
Circularity Check
Empirical ablation study; no mathematical derivation or self-referential reduction
full rationale
The manuscript presents experimental ablations comparing SAE training runs with and without deterministic k-means decoder initialization. The central claim—that reported endpoint stability is an artifact of shared initialization rather than the archetypal constraint—is supported by direct empirical comparison of inter-run dictionary distances, not by any equation or first-principles derivation that reduces to its own inputs. No self-definitional steps, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the abstract or described methodology. The distinction between stability and stabilization is introduced as a clarification of terminology based on the experimental outcomes, not as a circular premise. This is a standard empirical reproduction and ablation paper whose result is falsifiable by independent replication and does not rely on internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The original archetypal SAEs implementation used a deterministic k-means decoder initialization across runs
Forward citations
Cited by 2 Pith papers
-
Aligned Training: A Parameter-Free Method to Improve Feature Quality and Stability of Sparse Autoencoders (SAE)
Aligned training reparameterizes SAEs to enforce unit inner product between encoder and decoder directions, eliminating dead features and enhancing stability without hyperparameters.
-
Aligned Training: A Parameter-Free Method to Improve Feature Quality and Stability of Sparse Autoencoders (SAE)
Aligned training reparameterizes SAEs to enforce unit alignment between encoder and decoder directions, yielding Pareto gains on SAEBench while removing dead features and improving stability.
Reference graph
Works this paper leans on
-
[1]
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, and 1 others. 2023. https://arxiv.org/abs/2304.01373 Pythia: A suite for analyzing large language models across training and scaling . In Proceedings of the 40th International Conferenc...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, and 6 others. 2023. Towards monosemanticity: Decomposing language models with d...
2023
-
[3]
Michał Brzozowski and Neo Christopher Chung. 2026. https://arxiv.org/abs/2605.18629 Aligned training: A parameter-free method to improve feature quality and stability of sparse autoencoders (sae) . Preprint, arXiv:2605.18629
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Adele Cutler and Leo Breiman. 1994. Archetypal analysis. Technometrics, 36(4):338--347
1994
-
[5]
Thomas Fel, Victor Boutin, Louis B \'e thune, Remi Cadene, Mazda Moayeri, L \'e o And \'e ol, Mathieu Chalvidal, and Thomas Serre. 2023. https://openreview.net/forum?id=MziFFGjpkb A holistic approach to unifying automatic concept extraction and concept importance estimation . In Advances in Neural Information Processing Systems
2023
-
[6]
Prince, Matthew Kowal, Victor Boutin, Isabel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba E
Thomas Fel, Ekdeep Singh Lubana, Jacob S. Prince, Matthew Kowal, Victor Boutin, Isabel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba E. Ba, and Talia Konkle. 2025. https://openreview.net/forum?id=9v1eW8HgMU Archetypal SAE : Adaptive and stable dictionary learning for concept extraction in large vision models . In Forty-second International Conferenc...
2025
-
[7]
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. 2025. https://openreview.net/forum?id=tcsZt9ZNKD Scaling and evaluating sparse autoencoders . In The Thirteenth International Conference on Learning Representations
2025
-
[8]
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. 2023. Sparse autoencoders find highly interpretable features in language models. In The Twelfth International Conference on Learning Representations
2023
-
[9]
Yuxiao Li, Eric J. Michaud, David D. Baek, Joshua Engels, Xiaoqing Sun, and Max Tegmark. 2025. https://doi.org/10.3390/e27040344 The geometry of concepts: Sparse autoencoder feature structure . Entropy, 27(4)
-
[10]
Gon c alo Paulo and Nora Belrose. 2026. https://openreview.net/forum?id=EjInprGpk9 Sparse autoencoders trained on the same data learn different features . In The Fourteenth International Conference on Learning Representations
2026
-
[11]
Lee Sharkey, Dan Braun, and beren. 2022. https://www.alignmentforum.org/posts/z6QQJbtpkEAX3Aojj/interim-research-report-taking-features-out-of-superposition [interim research report] taking features out of superposition with sparse autoencoders . AI Alignment Forum
2022
-
[12]
Diab, Virginia Smith, and Kun Zhang
Xiangchen Song, Aashiq Muhamed, Yujia Zheng, Lingjing Kong, Zeyu Tang, Mona T. Diab, Virginia Smith, and Kun Zhang. 2025. https://openreview.net/forum?id=d9ACURK6bI Position: Mechanistic interpretability should prioritize feature consistency in SAE s . In Mechanistic Interpretability Workshop at NeurIPS 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.