Aligned Training: A Parameter-Free Method to Improve Feature Quality and Stability of Sparse Autoencoders (SAE)
Pith reviewed 2026-06-30 18:23 UTC · model grok-4.3
The pith
Enforcing unit inner product between each encoder and decoder direction removes degeneracy in sparse autoencoders and eliminates dead features without new hyperparameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
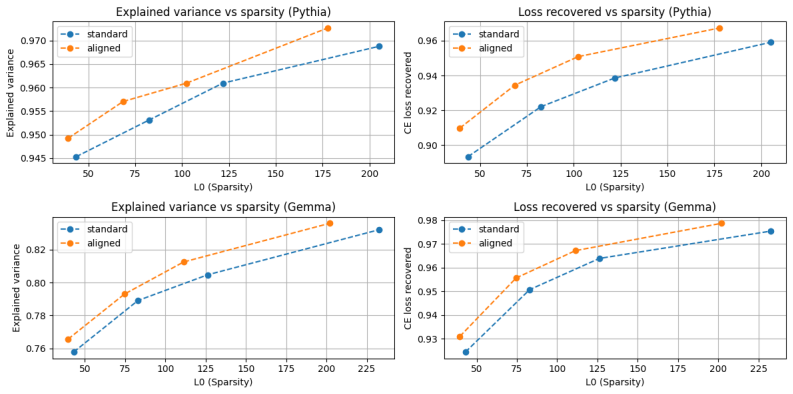
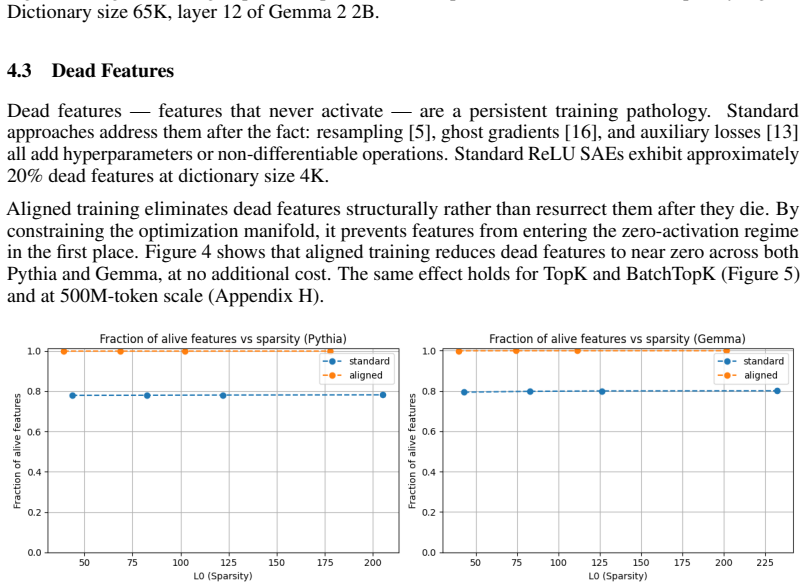
The central claim is that the bimodal distribution of alignment scores reveals a harmful degeneracy in which some encoder-decoder pairs are misaligned, and that reparameterizing the SAE to enforce an inner product of exactly one for every feature removes this degeneracy, yielding zero dead features, higher stability across seeds, and better reconstruction without any added hyperparameters or computational cost.
What carries the argument
Aligned training, a reparameterization that normalizes the decoder and adjusts the encoder so the inner product between each encoder and decoder direction equals one.
If this is right
- Dead features disappear across dictionary sizes and sparsity levels.
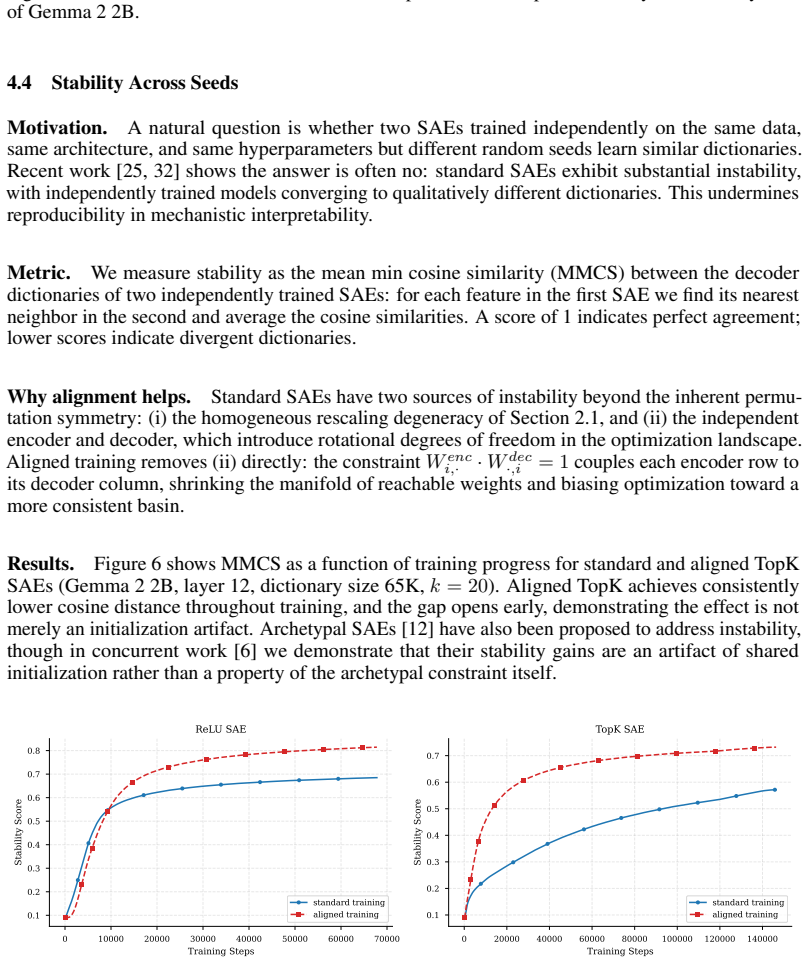
- Training becomes stable across different random seeds.
- Reconstruction quality and SAEBench scores improve without extra cost.
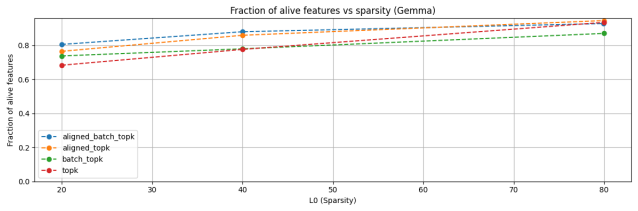
- The method combines directly with Top-K, BatchTop-K, and p-annealing variants.
Where Pith is reading between the lines
- The same reparameterization could be tested on other dictionary-learning objectives that also learn paired encoder and decoder matrices.
- If the unit-alignment constraint proves robust, it could become a default preprocessing step before applying any SAE variant for interpretability work.
- The observation of bimodality may motivate further geometric analysis of how feature directions interact during training.
Load-bearing premise
The bimodal distribution of alignment scores indicates a harmful degeneracy that is best corrected by forcing every alignment score exactly to one rather than some other fixed value or no constraint at all.
What would settle it
A controlled comparison on the same models and data in which aligned training still produces dead features or lower stability than the baseline SAE.
Figures





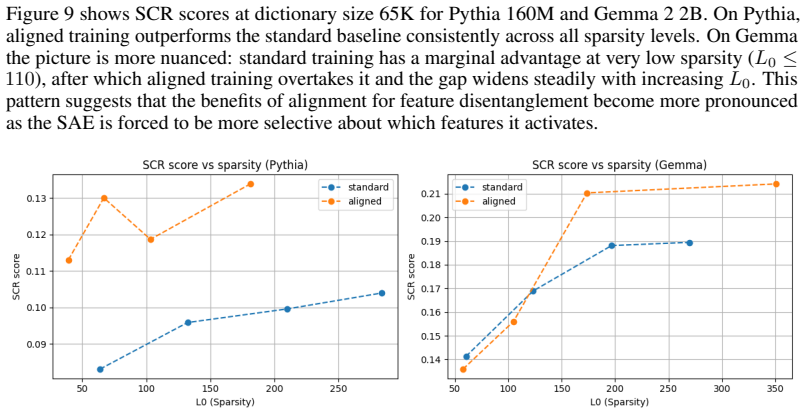

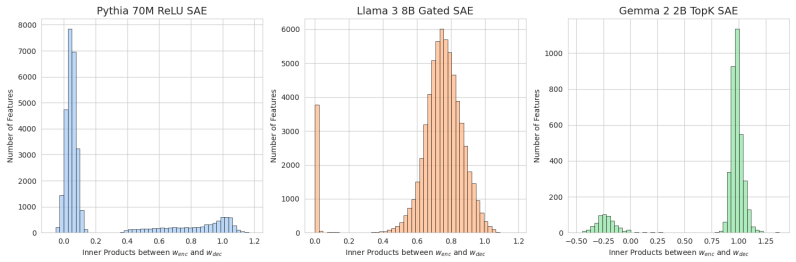
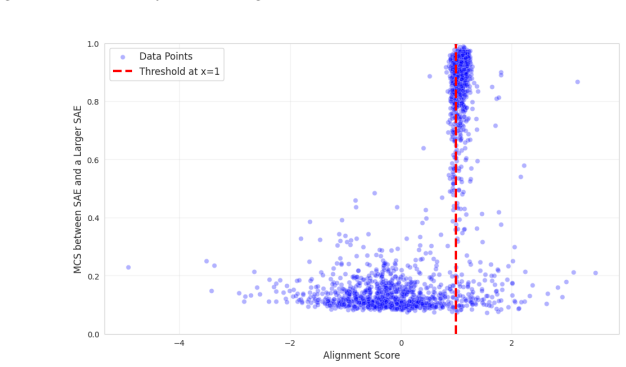
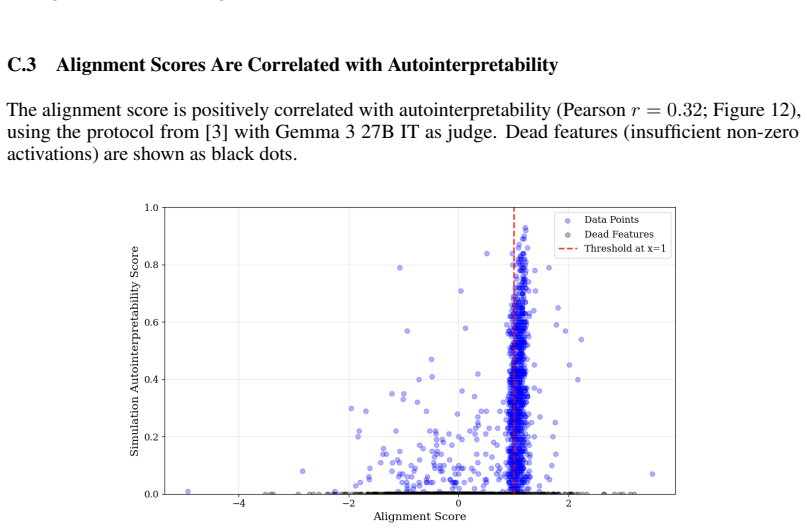









read the original abstract
Sparse autoencoders (SAEs) are one of the main methods to interpret the inner workings of deep neural networks (DNNs), decomposing activations into higher-dimensional features. However, they exhibit critical shortcomings where a large fraction of features are never activated and are unstable. Despite variants of SAEs that attempt to mitigate these issues, they require additional data, resampling, or training. We propose the \textbf{aligned training}, a parameter-free reparameterization of SAEs that simultaneously improves reconstruction quality, eliminates dead features, and significantly enhances stability across training seeds. Our approach is motivated by an overlooked observation that SAE feature quality, measured by the inner product between encoder and decoder directions (which we call the \textbf{alignment score}), follows a bimodal distribution across all modern architectures. The proposed aligned training enforces a geometric constraint between the encoder and decoder such that their inner product equals one for every feature, which removes a source of degeneracy in the SAE training without adding any hyperparameters. Across multiple models, dictionary sizes, and sparsity levels, the aligned training shows Pareto improvements on the SAEBench benchmarks. Beyond improving dead features, stability and reconstruction, our method readily integrates with techniques in mechanical interpretability such as Top/BatchTop-K architectures and p-Annealing. Overall, the aligned training substantially improves feature quality and stability of SAE without computational complexity or cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes aligned training, a parameter-free reparameterization of sparse autoencoders (SAEs) that enforces the inner product between each feature's encoder and decoder vectors to equal exactly 1. Motivated by an observed bimodal distribution of these alignment scores, the method is claimed to eliminate dead features, improve reconstruction quality and training stability across seeds, and deliver Pareto improvements on SAEBench benchmarks across models, dictionary sizes, and sparsity levels. It integrates with existing SAE variants such as TopK and p-Annealing without added hyperparameters or computational cost.
Significance. If the central claims hold under rigorous verification, the contribution would be significant for mechanistic interpretability: SAEs remain a core tool for feature extraction, and the well-documented problems of dead features and seed instability have previously required ad-hoc fixes with extra hyperparameters or data. A truly parameter-free geometric constraint that simultaneously improves multiple metrics would be a practical advance, especially given its claimed compatibility with other architectures.
major comments (3)
- [Abstract, §3] Abstract and §3 (method): The load-bearing premise that the bimodal alignment-score distribution signals a harmful degeneracy best removed by forcing every inner product exactly to 1 is not supported by comparative evidence. The manuscript should demonstrate (via ablation) that target=1 outperforms other fixed targets, the per-feature mean, or the unconstrained baseline; without this, the observed gains could stem from altered gradient flow or capacity rather than removal of the cited degeneracy.
- [§4] §4 (experiments): The Pareto-improvement claim on SAEBench is presented across multiple models and settings, but the paper does not report whether the aligned-training runs were matched for total compute or whether the baseline SAEs used identical hyperparameter sweeps; if the baselines were under-optimized, the relative gains are overstated.
- [§4.2] §4.2 (dead-feature results): The assertion that aligned training 'eliminates' dead features requires a precise operational definition and quantitative comparison (e.g., fraction of features with activation frequency < threshold); the current description leaves open whether the improvement is absolute or merely relative to a particular baseline.
minor comments (2)
- [§2] Notation: the term 'alignment score' is introduced in the abstract but should be formally defined with an equation (e.g., a_i = <e_i, d_i>) at first use in §2 or §3.
- [Figure 1] Figure clarity: the histogram of alignment scores (presumably Figure 1) should include the post-aligned-training distribution for direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point below and will incorporate clarifications and additional evidence in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): The load-bearing premise that the bimodal alignment-score distribution signals a harmful degeneracy best removed by forcing every inner product exactly to 1 is not supported by comparative evidence. The manuscript should demonstrate (via ablation) that target=1 outperforms other fixed targets, the per-feature mean, or the unconstrained baseline; without this, the observed gains could stem from altered gradient flow or capacity rather than removal of the cited degeneracy.
Authors: The target of exactly 1 follows directly from the geometric requirement that each decoder vector equals its corresponding encoder direction (removing the observed bimodality where some features have near-zero alignment). We agree that explicit ablations would strengthen this claim. In the revision we will add a controlled ablation comparing fixed targets of 0.5, 1.0 and 1.5, the per-feature mean alignment, and the unconstrained baseline, reporting effects on dead-feature rate, seed stability, and SAEBench scores. revision: yes
-
Referee: [§4] §4 (experiments): The Pareto-improvement claim on SAEBench is presented across multiple models and settings, but the paper does not report whether the aligned-training runs were matched for total compute or whether the baseline SAEs used identical hyperparameter sweeps; if the baselines were under-optimized, the relative gains are overstated.
Authors: All runs used identical training budgets (same step count, batch size, and optimizer schedule). Hyperparameter grids for sparsity, learning rate, and dictionary size were swept identically for both aligned and baseline models. We will add an explicit statement in §4 confirming matched compute and identical sweep protocols. revision: yes
-
Referee: [§4.2] §4.2 (dead-feature results): The assertion that aligned training 'eliminates' dead features requires a precise operational definition and quantitative comparison (e.g., fraction of features with activation frequency < threshold); the current description leaves open whether the improvement is absolute or merely relative to a particular baseline.
Authors: We will revise §4.2 to define dead features as those with activation frequency below 10^{-5} on the held-out evaluation set and will report the exact fractions for aligned training versus each baseline across all model sizes and sparsity levels, demonstrating that the reduction is absolute (near-zero dead features) rather than merely relative. revision: yes
Circularity Check
No significant circularity; aligned training is a direct geometric reparameterization with empirical results
full rationale
The paper's chain starts from an empirical observation of bimodal alignment scores (inner product between encoder and decoder) and introduces a reparameterization that directly enforces this inner product to equal 1 for all features. This constraint is imposed as a training modification rather than derived from or equivalent to any fitted parameters, prior predictions, or self-referential equations. Claimed benefits (elimination of dead features, stability, Pareto gains on SAEBench) are shown via external benchmark evaluations across models and settings, not by algebraic reduction to the input assumptions. No self-citations, uniqueness theorems, or ansatzes from prior author work are used to justify the core method or target value of 1. The derivation remains self-contained as an independent geometric intervention.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The bimodal distribution of alignment scores indicates a source of degeneracy best addressed by enforcing inner product exactly equal to one for every feature.
Forward citations
Cited by 1 Pith paper
-
Ablating Archetypes: The Stability of Archetypal SAEs is an Artifact of Initialization and Metric Design
Archetypal SAEs appear stable only because of shared deterministic initialization; removing it eliminates any stabilization benefit from the archetypal constraint.
Reference graph
Works this paper leans on
-
[1]
Addressing feature suppression in saes.AI Alignment Forum, 2024
Lee Sharkey Benjamin Wright. Addressing feature suppression in saes.AI Alignment Forum, 2024. URL https://www.alignmentforum.org/posts/3JuSjTZyMzaSeTxKk/ addressing-feature-suppression-in-saes
2024
-
[2]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023
2023
-
[3]
Language models can explain neu- rons in language models, 2023
Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu, and William Saunders. Language models can explain neu- rons in language models, 2023. URL https://openaipublic.blob.core.windows.net/ neuron-explainer/paper/index.html
2023
-
[4]
Joseph Bloom, Curt Tigges, Anthony Duong, and David Chanin. Saelens. https://github. com/jbloomAus/SAELens, 2024
2024
-
[5]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
2023
-
[6]
Michał Brzozowski and Neo Christopher Chung. Ablating archetypes: The stability of archety- pal saes is an artifact of initialization and metric design, 2026. URL https://arxiv.org/ abs/2606.02061
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Batchtopk sparse autoencoders
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders. InNeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning, 2024. URL https: //openreview.net/forum?id=d4dpOCqybL
2024
-
[8]
Update on dictionary learning improvements.Transformer Circuits Thread, 2024
Tom Conerly, Adly Templeton, Trenton Bricken, Jonathan Marcus, and Tom Henighan. Update on dictionary learning improvements.Transformer Circuits Thread, 2024. URL https: //transformer-circuits.pub/2024/april-update/index.html#training-saes
2024
-
[9]
Autointerpretation finds sparse coding beats alternatives.AI Alignment Forum, 2023
Hoagy Cunningham. Autointerpretation finds sparse coding beats alternatives.AI Alignment Forum, 2023. URL https://www.alignmentforum.org/posts/ursraZGcpfMjCXtnn/ autointerpretation-finds-sparse-coding-beats-alternatives
2023
-
[10]
[replication] conjec- ture’s sparse coding in small transformers.Less Wrong, 2023
Hoagy Cunningham and Logan Riggs. [replication] conjec- ture’s sparse coding in small transformers.Less Wrong, 2023. URL https://www.lesswrong.com/posts/vBcsAw4rvLsri3JAj/ replication-conjecture-s-sparse-coding-in-small-transformers
2023
-
[11]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread, 2022. URL https: //transformer-circuits.pub/20...
2022
-
[12]
Prince, Matthew Kowal, Victor Boutin, Is- abel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba E
Thomas Fel, Ekdeep Singh Lubana, Jacob S. Prince, Matthew Kowal, Victor Boutin, Is- abel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba E. Ba, and Talia Konkle. Archetypal SAE: Adaptive and stable dictionary learning for concept extraction in large vi- sion models. InForty-second International Conference on Machine Learning, 2025. URL https://openrev...
2025
-
[13]
Kunihiko Fukushima. Neocognitron: A hierarchical neural network capable of visual pat- tern recognition.Neural Networks, 1(2):119–130, 1988. ISSN 0893-6080. doi: https://doi. org/10.1016/0893-6080(88)90014-7. URL https://www.sciencedirect.com/science/ article/pii/0893608088900147. 10
-
[14]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The Pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. InThe Thirteenth International Conference on Learning Representations, 2025. URL https:// openreview.net/forum?id=tcsZt9ZNKD
2025
-
[16]
[research update] sparse autoencoder features are bimodal.From AI to ZI, 2023
Robert Huben. [research update] sparse autoencoder features are bimodal.From AI to ZI, 2023. URLhttps://aizi.substack.com/p/research-update-sparse-autoencoder
2023
-
[17]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[18]
Ghost grads: An improvement on resampling.Transformer Circuits Thread, 2024
Adam Jermyn and Adly Templeton. Ghost grads: An improvement on resampling.Transformer Circuits Thread, 2024. URL https://transformer-circuits.pub/2024/jan-update/ index.html#dict-learning-resampling
2024
-
[19]
Evaluating sparse autoencoders on targeted concept erasure tasks, 2024
Adam Karvonen, Can Rager, Samuel Marks, and Neel Nanda. Evaluating sparse autoencoders on targeted concept erasure tasks, 2024. URLhttps://arxiv.org/abs/2411.18895
-
[20]
Measuring progress in dictionary learning for language model interpretability with board game models
Adam Karvonen, Benjamin Wright, Can Rager, Rico Angell, Jannik Brinkmann, Logan Riggs Smith, Claudio Mayrink Verdun, David Bau, and Samuel Marks. Measuring progress in dictionary learning for language model interpretability with board game models. InICML 2024 Workshop on Mechanistic Interpretability, 2024. URL https://openreview.net/forum? id=qzsDKwGJyB
2024
-
[21]
Saebench: A comprehensive benchmark for sparse autoencoders in language model interpretability, 2025
Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum McDougall, Kola Ayonrinde, Demian Till, Matthew Wearden, Arthur Conmy, Samuel Marks, and Neel Nanda. Saebench: A comprehensive benchmark for sparse autoencoders in language model interpretability, 2025. URL https://arxiv.org/abs/2503. 09532
2025
-
[22]
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791
-
[23]
Luke Marks, Alasdair Paren, David Krueger, and Fazl Barez. Enhancing neural network interpretability with feature-aligned sparse autoencoders, 2024. URL https://arxiv.org/ abs/2411.01220
-
[24]
Sparse feature circuits: Discovering and editing interpretable causal graphs in language models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=I4e82CIDxv
2025
-
[25]
Sparse autoencoders trained on the same data learn different features
Gonçalo Paulo and Nora Belrose. Sparse autoencoders trained on the same data learn different features. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=EjInprGpk9
2026
-
[26]
Improving sparse decomposition of lan- guage model activations with gated sparse autoencoders
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. Improving sparse decomposition of lan- guage model activations with gated sparse autoencoders. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sy...
2024
-
[27]
Jumping ahead: Improving reconstruction fidelity with jumpreLU sparse autoencoders, 2025
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, Janos Kramar, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumpreLU sparse autoencoders, 2025. URL https://openreview.net/forum?id= mMPaQzgzAN. 11
2025
-
[28]
(tentatively) found 600+ monosemantic features in a small lm using sparse autoencoders.AI Alignment Forum, 2023
Logan Riggs. (tentatively) found 600+ monosemantic features in a small lm using sparse autoencoders.AI Alignment Forum, 2023. URL https://www.alignmentforum.org/posts/wqRqb7h6ZC48iDgfK/ tentatively-found-600-monosemantic-features-in-a-small-lm
2023
-
[29]
Einops: Clear and reliable tensor manipulations with einstein-like notation
Alex Rogozhnikov. Einops: Clear and reliable tensor manipulations with einstein-like notation. InInternational Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=oapKSVM2bcj
2022
-
[30]
dictionary_learning, 2024
Adam Karvonen Samuel Marks and Aaron Mueller. dictionary_learning, 2024. URL https: //github.com/saprmarks/dictionary_learning
2024
-
[31]
Taking features out of superposition with sparse autoencoders.Alignment Forum, 2023
Lee Sharkey, Dan Braun, and Beren Millidge. Taking features out of superposition with sparse autoencoders.Alignment Forum, 2023. URL https://www.alignmentforum.org/posts/z6QQJbtpkEAX3Aojj/ interim-research-report-taking-features-out-of-superposition
2023
-
[32]
Diab, Virginia Smith, and Kun Zhang
Xiangchen Song, Aashiq Muhamed, Yujia Zheng, Lingjing Kong, Zeyu Tang, Mona T. Diab, Virginia Smith, and Kun Zhang. Position: Mechanistic interpretability should prioritize feature consistency in SAEs. InMechanistic Interpretability Workshop at NeurIPS 2025, 2025. URL https://openreview.net/forum?id=d9ACURK6bI
2025
-
[33]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsitsulin, Nino Vieillard, Piotr Stanczyk, Sertan Girgin, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
activation_dim -1␣ dict_size
Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D Manning, and Christopher Potts. Axbench: Steering LLMs? even simple base- 12 lines outperform sparse autoencoders. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=K2CckZjNy0. A Implementation Details All SA...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.