PeAR: A Static Binary Rewriting Framework for Binary-Only Fuzzing
Pith reviewed 2026-06-28 14:07 UTC · model grok-4.3
The pith
Accurate static binary instrumentation enables effective binary-only fuzzing without dynamic overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
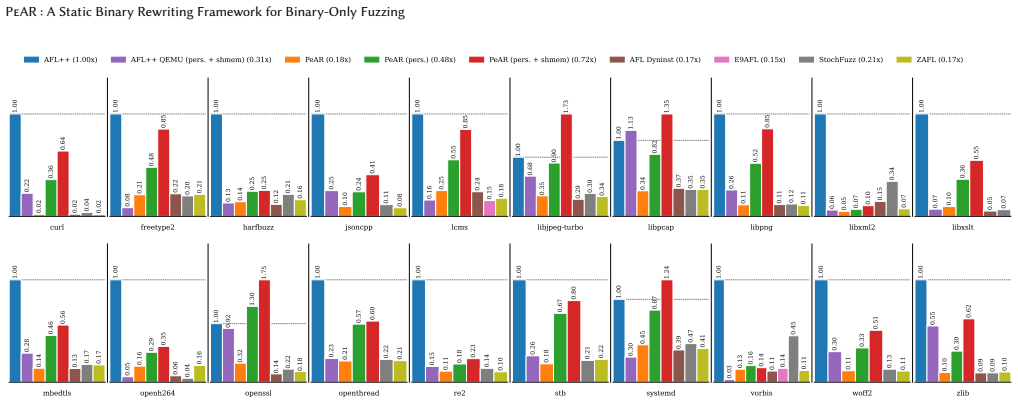
PeAR applies static binary rewriting to deliver the instrumentation required for coverage-guided fuzzing, including the implementation of deferred initialization, persistent mode, and shared-memory fuzzing. On the FUZZBENCH suite the resulting system instruments 88 percent of targets, produces a median fourfold throughput increase under persistent and shared-memory operation, and attains code coverage comparable to that obtained from compiler-based instrumentation.
What carries the argument
PeAR, the extensible fuzzing framework that performs complex, high-granularity instrumentation through static binary rewriting.
If this is right
- Binary-only fuzzing no longer needs to accept the runtime cost of dynamic instrumentation for coverage guidance.
- Advanced fuzzer features such as persistent mode can be realized statically with negligible performance penalty.
- Closed-source targets can receive coverage feedback at a scale and speed previously associated only with source-available builds.
Where Pith is reading between the lines
- The same static-rewriting base could support other dynamic-analysis tools that currently rely on instrumentation at runtime.
- Wider use of static methods may shift tooling choices away from dynamic frameworks in security testing pipelines.
- Replicating the evaluation on a broader set of real-world closed-source binaries would test whether the reported success rate generalizes.
Load-bearing premise
Existing static binary rewriting tools can produce instrumentation accurate enough that any errors do not meaningfully reduce a fuzzer's ability to discover bugs.
What would settle it
On the same set of FUZZBENCH programs, a direct head-to-head run shows the static approach either instruments far fewer targets or yields measurably lower coverage and fewer crashes than a dynamic-instrumentation baseline.
Figures

read the original abstract
Binary-only fuzzing is a key technique for finding bugs in close-source software. Without access to source code, the fuzzer must rely on static or dynamic binary instrumentation for coverage guidance. In practice, most fuzzers favor dynamic binary instrumentation (DBI), accepting runtime overhead to avoid the perceived accuracy and soundness challenges associated with static binary instrumentation (SBI). We show that these concerns are unwarranted, and that accurate, scalable~SBI is achievable using off-the-shelf frameworks. Building on these frameworks, we develop PeAR, an extensible binary-only fuzzing framework. We demonstrate PeAR's versatility by implementing several modern fuzzer features -- including, deferred initialization, persistent mode, and shared-memory fuzzing. We evaluate PeAR over 4.25 CPU-yrs of fuzzing on the FUZZBENCH benchmark and find that PeAR: (i) successfully instruments 88% of FUZZBENCH targets, comparable to the best SBI-based fuzzers; (ii) achieves a median throughput improvement of 4x when using persistent mode and shared memory fuzzing; and (iii) attains coverage comparable to compiler-based instrumentation. Our results show that SBI is a practical and effective technique for binary-only fuzzing, and that modern binary rewriting frameworks can apply complex instrumentation with high granularity and negligible performance compromise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PeAR, a static binary rewriting framework for binary-only fuzzing built on off-the-shelf tools. It claims that accuracy and soundness concerns with static binary instrumentation (SBI) are unwarranted, demonstrates implementation of features such as deferred initialization, persistent mode, and shared-memory fuzzing, and reports evaluation results on FUZZBENCH over 4.25 CPU-years: 88% instrumentation success rate (comparable to best SBI fuzzers), median 4x throughput improvement with persistent/shared-memory modes, and coverage comparable to compiler-based instrumentation.
Significance. If the central empirical claims hold, the work would establish SBI as a practical, lower-overhead alternative to dynamic binary instrumentation for closed-source fuzzing and show that modern static rewriting frameworks can support complex, high-granularity instrumentation reliably. The scale of the FUZZBENCH evaluation (4.25 CPU-years) provides a substantial empirical basis for the practicality argument.
major comments (2)
- [Abstract] Abstract and evaluation: the reported 88% instrumentation success, 4x throughput, and 'comparable coverage' rest on aggregate metrics without visible details on target selection criteria, failure modes for the 12% of targets, or statistical controls for variability; this makes it impossible to assess whether post-hoc choices or unrepresentative targets affect the claim that SBI concerns are unwarranted.
- [Evaluation] The central claim that static rewriting produces instrumentation whose coverage is sound and complete enough to match compiler-based results (without introducing errors that change fuzzing behavior) requires explicit validation on edge cases such as indirect control flow, PIC, exceptions, or obfuscated code; aggregate 'comparable coverage' metrics alone do not confirm equivalence or rule out systematic disassembly/relocation errors.
minor comments (2)
- Clarify the exact definition of 'successfully instruments' (e.g., whether it requires full relocation of all code or only coverage-relevant blocks) and how coverage is measured against compiler instrumentation.
- The manuscript would benefit from a short table or paragraph listing the specific off-the-shelf rewriting frameworks used and any custom extensions in PeAR.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation: the reported 88% instrumentation success, 4x throughput, and 'comparable coverage' rest on aggregate metrics without visible details on target selection criteria, failure modes for the 12% of targets, or statistical controls for variability; this makes it impossible to assess whether post-hoc choices or unrepresentative targets affect the claim that SBI concerns are unwarranted.
Authors: FUZZBENCH is a fixed, community-defined benchmark; our evaluation used every target in the suite with no post-hoc filtering or exclusion. We will add an expanded evaluation subsection that lists per-target success rates, enumerates the concrete failure modes for the 12% (primarily relocation and exception-handling issues in a small number of targets), and details the statistical controls (median over 10 runs per configuration with inter-quartile ranges). revision: yes
-
Referee: [Evaluation] The central claim that static rewriting produces instrumentation whose coverage is sound and complete enough to match compiler-based results (without introducing errors that change fuzzing behavior) requires explicit validation on edge cases such as indirect control flow, PIC, exceptions, or obfuscated code; aggregate 'comparable coverage' metrics alone do not confirm equivalence or rule out systematic disassembly/relocation errors.
Authors: The FUZZBENCH programs contain substantial indirect control flow, PIC, and exception handling; coverage parity with compiler instrumentation across this diverse set already supplies evidence against systematic disassembly or relocation errors. We will add a short discussion subsection that explicitly maps these language features to the benchmark targets and notes the absence of observable behavioral divergence. A full synthetic edge-case suite would be a useful addition but exceeds the scope of the current major-revision request; we therefore treat this as a partial revision. revision: partial
Circularity Check
No circularity: empirical tool evaluation with no derivations or fitted parameters
full rationale
The paper presents an engineering artifact (PeAR framework) and reports empirical results on instrumentation success rate (88%), throughput (4x median), and coverage comparability on FUZZBENCH. No equations, parameters, or self-citation chains appear in the abstract or described claims; the central assertions rest on direct measurement against external benchmarks rather than any reduction of outputs to inputs by construction. This matches the default expectation for non-circular empirical systems papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Erick Bauman, Zhiqiang Lin, Kevin W Hamlen, et al. 2018. Superset Disassembly: Statically Rewriting x86 Binaries Without Heuristics. InNetwork and Distributed System Security Symposium (NDSS). The Internet Society
2018
-
[2]
Fabrice Bellard. 2005. QEMU, a Fast and Portable Dynamic Translator. InAnnual Technical Conference (ATC). USENIX, 41
2005
-
[3]
Michael Chesser, Surya Nepal, and Damith C. Ranasinghe. 2023. Icicle: A Re- Designed Emulator for Grey-Box Firmware Fuzzing. InInternational Symposium on Software Testing and Analysis (ISSTA). ACM, 76–88. doi:10.1145/3597926.3598 039
-
[4]
Sushant Dinesh, Nathan Burow, Dongyan Xu, and Mathias Payer. 2020. Retro- write: Statically instrumenting cots binaries for fuzzing and sanitization. In Security and Privacy (S&P). IEEE, 1497–1511. doi:10.1109/SP40000.2020.00009
-
[5]
Brendan Dolan-Gavitt, Patrick Hulin, Engin Kirda, Tim Leek, Andrea Mambretti, Wil Robertson, Frederick Ulrich, and Ryan Whelan. 2016. Lava: Large-scale automated vulnerability addition. InSecurity and Privacy (S&P). IEEE, 110–121
2016
-
[6]
Gregory J Duck, Xiang Gao, and Abhik Roychoudhury. 2020. Binary Rewriting Without Control Flow Recovery. InProgramming Language Design and Imple- mentation (PLDI). ACM, 151–163. doi:10.1145/3385412.3385972
-
[7]
Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. 2020. {AFL++}: Combining incremental steps of fuzzing research. InWorkshop on Offensive Technologies (WOOT). USENIX
2020
-
[8]
Antonio Flores-Montoya and Eric Schulte. 2020. Datalog disassembly. InSecurity Symposium (SEC). USENIX, 1075–1092
2020
-
[9]
Xiang Gao, Gregory J Duck, and Abhik Roychoudhury. 2021. Scalable fuzzing of program binaries with E9AFL. InAutomated Software Engineering (ASE). IEEE, 1247–1251. doi:10.1109/ASE51524.2021.9678913
-
[10]
GrammaTech. [n. d.]. gtirb-rewriting. https://github.com/GrammaTech/gtirb- rewriting
-
[11]
William H. Hawkins, Jason D. Hiser, Michele Co, Anh Nguyen-Tuong, and Jack W. Davidson. 2017. Zipr: Efficient Static Binary Rewriting for Security. InDependable Systems and Networks (DSN). 559–566. doi:10.1109/DSN.2017.27
-
[12]
Marc Heuse. 2021. American Fuzzy Lop + Dyninst == AFL Fuzzing blackbox binaries. https://github.com/vanhauser-thc/afl-dyninst
2021
-
[13]
Jinho Jung, Stephen Tong, Hong Hu, Jungwon Lim, Yonghwi Jin, and Taesoo Kim. 2021. WINNIE : Fuzzing Windows Applications with Harness Synthesis and Fast Cloning. InNetwork and Distributed System Security Symposium (NDSS). The Internet Society
2021
-
[14]
Hyungseok Kim, Soomin Kim, Junoh Lee, Kangkook Jee, and Sang Kil Cha
-
[15]
InUSENIX Security Symposium (SEC)
Reassembly is Hard: A Reflection on Challenges and Strategies. InUSENIX Security Symposium (SEC). USENIX, 1469–1486
-
[16]
Chi-Keung Luk, Robert Cohn, Robert Muth, Harish Patil, Artur Klauser, Ge- off Lowney, Steven Wallace, Vijay Janapa Reddi, and Kim Hazelwood. 2005. Pin: building customized program analysis tools with dynamic instrumentation. (2005), 190–200. doi:10.1145/1065010.1065034
-
[17]
Jonathan Metzman, László Szekeres, Laurent Simon, Read Sprabery, and Ab- hishek Arya. 2021. Fuzzbench: an open fuzzer benchmarking platform and service. InProceedings of the 29th ACM joint meeting on European software en- gineering conference and symposium on the foundations of software engineering. 1393–1403
2021
-
[18]
Hiser, Jack W
Stefan Nagy, Anh Nguyen-Tuong, Jason D. Hiser, Jack W. Davidson, and Matthew Hicks. 2021. Breaking Through Binaries: Compiler-quality Instrumentation for Better Binary-only Fuzzing. InSecurity Symposium (SEC). USENIX, 1683–1700
2021
-
[19]
Paradyn Tools Project. 2018. Dyninst. https://dyninst.org/
2018
-
[20]
Soumyakant Priyadarshan, Huan Nguyen, and R. Sekar. 2024. Accurate Disas- sembly of Complex Binaries Without Use of Compiler Metadata. InArchitectural Support for Programming Languages and Operating Systems (ASPLOS). 1–18. doi:10.1145/3623278.3624766
-
[21]
Eric Schulte, Michael D. Brown, and Vlad Folts. 2022. A Broad Comparative Evaluation of X86-64 Binary Rewriters. InCyber Security Experimentation and Test (CSET). ACM, 129–144. doi:10.1145/3546096.3546112
-
[22]
Eric Schulte, Jonathan Dorn, Antonio Flores-Montoya, Aaron Ballman, and Tom Johnson. 2020. GTIRB: intermediate representation for binaries.arXiv preprint arXiv:1907.02859(2020)
arXiv 2020
-
[23]
Shuai Wang, Pei Wang, and Dinghao Wu. 2015. Reassembleable Disassembling. In24th USENIX Security Symposium, USENIX Security 15, Washington, D.C., USA, August 12-14, 2015, Jaeyeon Jung and Thorsten Holz (Eds.). USENIX Association, 627–642. https://www.usenix.org/conference/usenixsecurity15/technical- sessions/presentation/wang-shuai
2015
-
[24]
Zhuo Zhang, Wei You, Guanhong Tao, Yousra Aafer, Xuwei Liu, and Xiangyu Zhang. 2021. StochFuzz: Sound and Cost-effective Fuzzing of Stripped Binaries by Incremental and Stochastic Rewriting. InSecurity and Privacy (S&P). IEEE, 659–676. doi:10.1109/SP40001.2021.00109 8
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.