Closing the Alignment-Maturity Gap in Federated Prototype Learning
Pith reviewed 2026-06-28 15:52 UTC · model grok-4.3
The pith
A curriculum that delays global alignment until local prototypes stabilize, paired with a hypersphere separation loss, improves federated prototype learning on heterogeneous data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
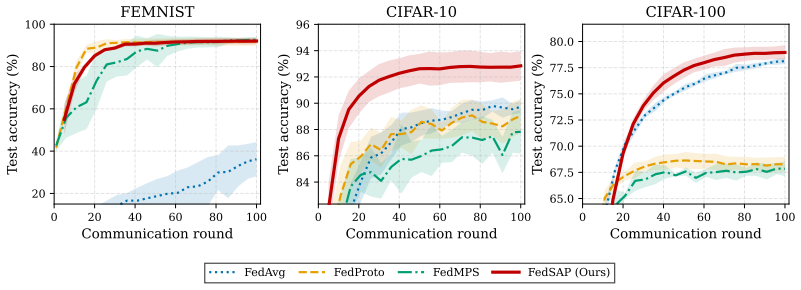
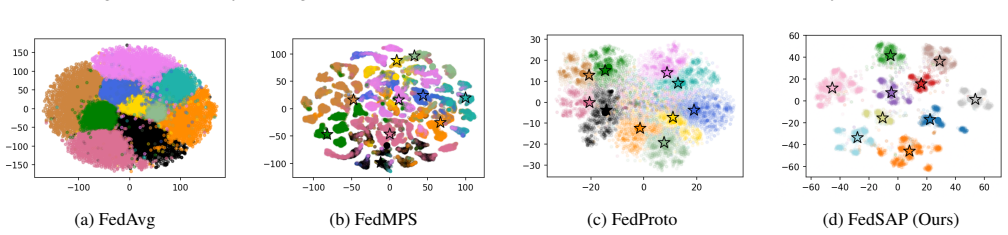
The paper claims that distance-dependent gradient pressure from immature global prototypes harms local structure formation, and that a deterministic alignment curriculum combined with a proxy separation loss on the unit hypersphere closes this gap, yielding compact well-separated class clusters without additional parameters or communication cost.
What carries the argument
The alignment-maturity gap, addressed by a deterministic curriculum that delays global alignment until local representations stabilize and a geometry-driven proxy separation loss that enforces inter-class distances on the unit hypersphere using the existing prototype bank.
If this is right
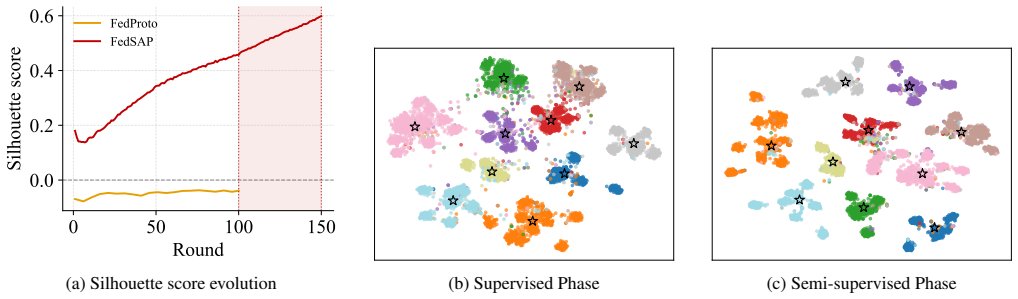
- Class clusters become compact and well-separated in the embedding space under non-IID conditions.
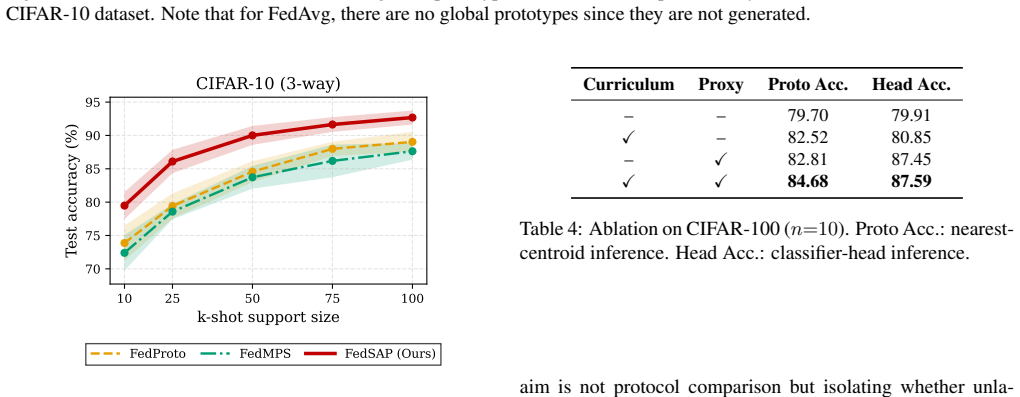
- Recognition performance rises by as much as four percentage points over standard prototype baselines.
- No modifications to the existing client-server communication protocol are required.
- The same scheduled alignment and separation mechanisms transfer to semi-supervised federated settings with only minor adjustments.
Where Pith is reading between the lines
- The curriculum principle of delaying global operations until local stability might extend to other federated representation methods that rely on shared embeddings.
- Using only existing prototypes for separation could reduce reliance on extra regularization terms in distributed training setups.
- Applying the same schedule in settings with concept drift might reveal whether repeated realignment remains beneficial after initial stabilization.
Load-bearing premise
That waiting for local representations to stabilize before applying global alignment will reliably stop early noisy prototypes from generating gradients that erase local discriminative structure.
What would settle it
An experiment on a high-heterogeneity benchmark in which the curriculum is applied but local representations remain unstable throughout training, with accuracy gains disappearing or reversing compared to the baseline.
Figures




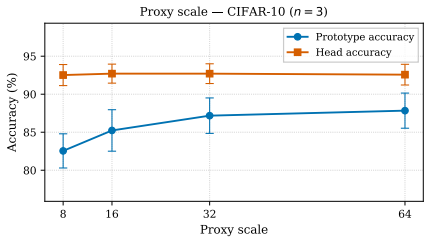
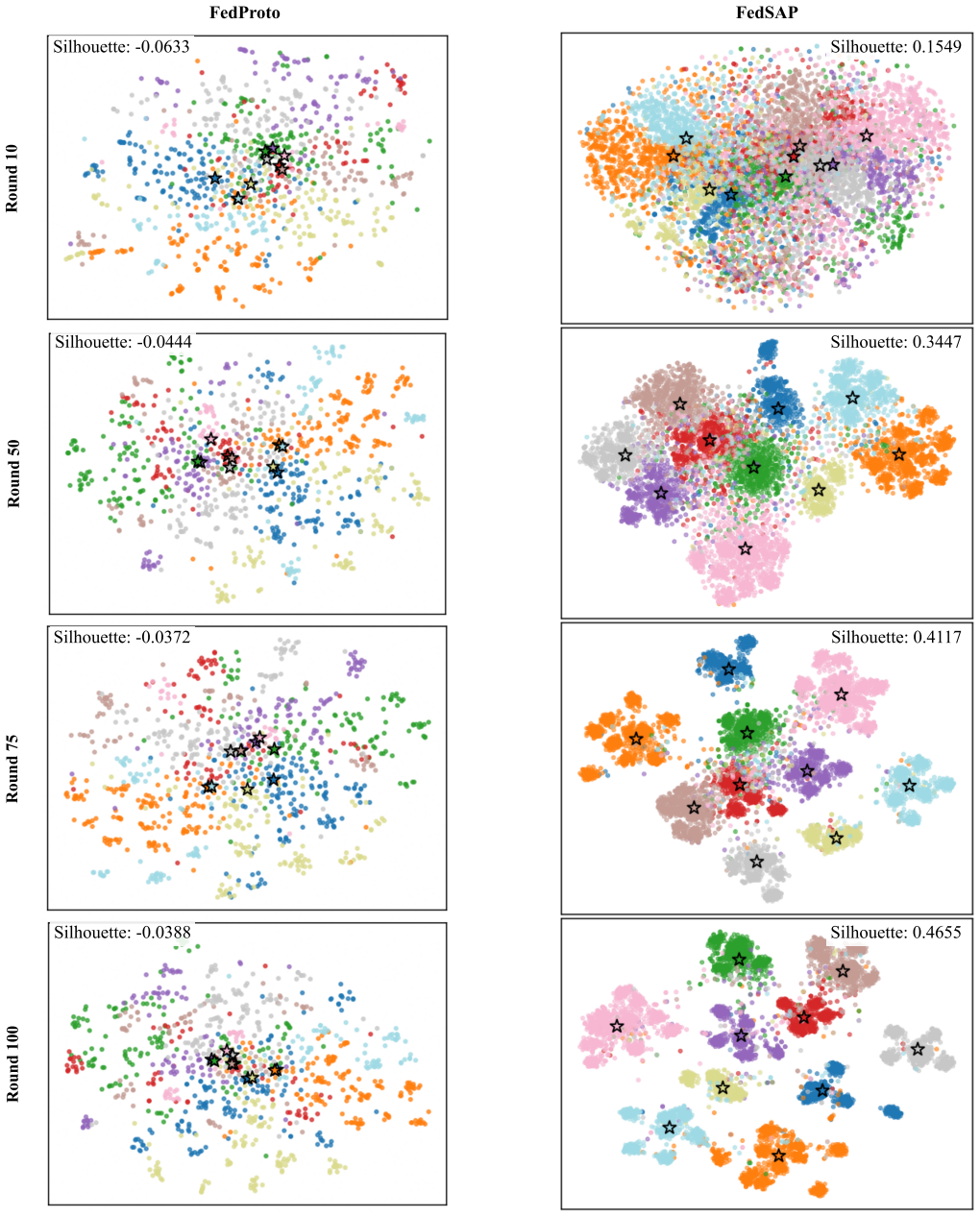
read the original abstract
Learning discriminative visual representations from distributed, heterogeneous data is a fundamental challenge in Federated Learning (FL). Prototype-based methods address statistical heterogeneity by sharing class-level representations across clients but create a distance-dependent gradient pressure that is particularly severe during early training rounds: alignment pressure applied to immature global prototypes, aggregated from noisy local representations, generates large gradients that suppress the emergence of local discriminative structure. The result is a poorly organized embedding space and degraded recognition performance, particularly under severe non-IID conditions. We propose FedSAP, a framework that stabilises federated representation learning through two complementary mechanisms: a deterministic alignment curriculum that delays global alignment until local representations become stable and a geometry-driven proxy separation loss that enforces inter-class structure on the unit hypersphere using the existing prototype bank without introducing additional parameters or communication overhead. Together, these mechanisms produce compact, well-separated class clusters without altering the underlying communication protocol between federation's participants. Experiments across three benchmarks and varying degrees of heterogeneity show gains of up to 4 percentage points over the prototype-based baselines evaluated, with improvements most pronounced under high heterogeneity. The representational nature of our framework further enables a straightforward extension to semi-supervised settings, where unlabelled data is incorporated with minimal modification, underscoring the generality of scheduled alignment as a design principle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FedSAP for federated prototype learning to close the alignment-maturity gap, where early global alignment on immature prototypes creates distance-dependent gradients that suppress local discriminative structure. It proposes two mechanisms—a deterministic alignment curriculum delaying global alignment until local stability and a geometry-driven proxy separation loss enforcing inter-class structure on the unit hypersphere—claiming these produce compact clusters without extra parameters or communication changes. Experiments on three benchmarks under varying heterogeneity report gains of up to 4 percentage points over prototype baselines, most pronounced in high heterogeneity, with a straightforward semi-supervised extension.
Significance. If the empirical results hold with proper controls, the work offers a lightweight, communication-preserving stabilization technique for prototype-based FL that directly targets early-training instability. The parameter-free and protocol-unchanged design is a clear strength, as is the noted generality to semi-supervised settings via the scheduled alignment principle. This could inform curriculum-based designs in other heterogeneous representation learning contexts.
major comments (2)
- [Abstract / FedSAP mechanisms] Abstract and mechanism description: the central stabilization claim rests on the deterministic alignment curriculum reliably delaying global alignment until local representations stabilize, yet no equation, threshold, or client-specific criterion is given for determining 'stability' (e.g., no loss plateau, gradient norm, or round-based rule). This directly bears on whether the approach prevents suppression of local structure across heterogeneity levels, as a fixed deterministic rule cannot adapt to client-specific rates.
- [Experiments] Experiments section: the reported gains of up to 4 percentage points and the claim that improvements are 'most pronounced under high heterogeneity' lack accompanying details on baseline definitions, heterogeneity quantification (e.g., Dirichlet alpha values), number of runs, or error bars. Without these, the cross-heterogeneity comparison cannot be verified as load-bearing evidence for the two-component design.
minor comments (2)
- [Method] Notation for the proxy separation loss should be introduced with an explicit equation rather than descriptive text only, to allow reproduction of the geometry-driven term on the unit hypersphere.
- [Abstract / Method] The abstract states 'without altering the underlying communication protocol' but does not explicitly confirm in the method section that the curriculum requires zero additional messages or metadata.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We respond point-by-point to the major comments below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / FedSAP mechanisms] Abstract and mechanism description: the central stabilization claim rests on the deterministic alignment curriculum reliably delaying global alignment until local representations stabilize, yet no equation, threshold, or client-specific criterion is given for determining 'stability' (e.g., no loss plateau, gradient norm, or round-based rule). This directly bears on whether the approach prevents suppression of local structure across heterogeneity levels, as a fixed deterministic rule cannot adapt to client-specific rates.
Authors: We agree that the abstract and mechanism description would benefit from an explicit equation or criterion for the stability threshold. In the revised manuscript we will add the precise deterministic formulation of the alignment curriculum. The fixed, non-adaptive schedule is a deliberate design decision to preserve the original communication protocol and avoid any client-specific information exchange or additional overhead; we will also add a short discussion of this choice and its empirical behavior across heterogeneity levels. revision: yes
-
Referee: [Experiments] Experiments section: the reported gains of up to 4 percentage points and the claim that improvements are 'most pronounced under high heterogeneity' lack accompanying details on baseline definitions, heterogeneity quantification (e.g., Dirichlet alpha values), number of runs, or error bars. Without these, the cross-heterogeneity comparison cannot be verified as load-bearing evidence for the two-component design.
Authors: We acknowledge that the experimental details should be stated more explicitly for easy verification. The revised manuscript will expand the experimental setup subsection to list the exact Dirichlet alpha values used for each heterogeneity regime, the precise baseline implementations, the number of independent runs, and confirmation that standard deviations are reported as error bars in all tables and figures. revision: yes
Circularity Check
No circularity: claims rest on experimental evaluation without derivations or self-referential reductions
full rationale
The paper introduces FedSAP via two mechanisms (deterministic alignment curriculum and geometry-driven separation loss) and reports empirical gains of up to 4 points on three benchmarks under varying heterogeneity. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims are justified by experimental outcomes rather than reducing to inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pseudo-labeling and confirmation bias in deep semi-supervised learning
Eric Arazo, Diego Ortego, Paul Albert, Noel E O’Connor, and Kevin McGuinness. Pseudo-labeling and confirmation bias in deep semi-supervised learning. In 2020 International joint conference on neural networks (IJCNN), pages 1–8. IEEE, 2020
2020
-
[2]
Leaf: A benchmark for federated settings,
Sebastian Caldas, Sai Meher Karthik Duddu, Peter Wu, Tian Li, Jakub Koneˇcn`y, H Brendan McMahan, Virginia Smith, and Ameet Talwalkar. Leaf: A benchmark for fed- erated settings.arXiv preprint arXiv:1812.01097, 2018
-
[3]
Exploiting shared representations for personalized federated learning
Liam Collins, Hamed Hassani, Aryan Mokhtari, and Sanjay Shakkottai. Exploiting shared representations for personalized federated learning. InInternational Confer- ence on Machine Learning (ICML). PMLR, 2021
2021
-
[4]
Tackling data heterogeneity in federated learning with class prototypes
Yutong Dai, Zeyuan Chen, Junnan Li, Shelby Heinecke, Lichao Sun, and Ran Xu. Tackling data heterogeneity in federated learning with class prototypes. InProceed- ings of the AAAI Conference on Artificial Intelligence, volume 37, pages 7314–7322, 2023
2023
-
[5]
Adaptive personalized federated learning
Yuyang Deng, Mohammad Mahdi Kamani, and Mehrdad Mahdavi. Adaptive personalized federated learning. arXiv preprint arXiv:2003.13461, 2020
-
[6]
Semifl: Semi- supervised federated learning for unlabeled clients with alternate training
Enmao Diao, Jie Ding, and Vahid Tarokh. Semifl: Semi- supervised federated learning for unlabeled clients with alternate training. InAdvances in Neural Information 9 Processing Systems, volume 35, pages 17871–17884, 2022
2022
-
[7]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015
2015
-
[8]
Wonyong Jeong, Jaehong Yoon, Eunho Yang, and Sung Ju Hwang. Federated semi-supervised learning with inter-client consistency & disjoint learning.arXiv preprint arXiv:2006.12097, 2020
-
[9]
Proxy anchor loss for deep metric learning
Sungyeon Kim, Dongwon Kim, Minsu Cho, and Suha Kwak. Proxy anchor loss for deep metric learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3238–3247, 2020
2020
-
[10]
Woojung Kim, Keondo Park, Kihyuk Sohn, Raphael Shu, and Hyung-Sin Kim. Protofssl: Federated semi- supervised learning with prototypical networks.arXiv preprint arXiv:2205.13921, 2022
-
[11]
Learning multiple layers of fea- tures from tiny images
Alex Krizhevsky et al. Learning multiple layers of fea- tures from tiny images. 2009
2009
-
[12]
Model- contrastive federated learning
Qinbin Li, Bingsheng He, and Dawn Song. Model- contrastive federated learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10713–10722, June 2021
2021
-
[13]
Ditto: Fair and robust federated learning through personalization
Tian Li, Shengyuan Hu, Ahmad Beirami, and Virginia Smith. Ditto: Fair and robust federated learning through personalization. InInternational Conference on Machine Learning (ICML), pages 6357–6368. PMLR, 2021
2021
-
[14]
Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar San- jabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
2020
-
[15]
Haowen Lin, Jian Lou, Li Xiong, and Cyrus Sha- habi. Semifed: Semi-supervised federated learning with consistency and pseudo-labeling.arXiv preprint arXiv:2108.09412, 2021
-
[16]
Brendan McMahan, Eider Moore, Daniel Ram- age, Seth Hampson, and Blaise Aguera y Arcas
H. Brendan McMahan, Eider Moore, Daniel Ram- age, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial Intelligence and Statis- tics (AISTATS). PMLR, 2017
2017
-
[17]
No fuss dis- tance metric learning using proxies
Yair Movshovitz-Attias, Alexander Toshev, Thomas K Leung, Sergey Ioffe, and Saurabh Singh. No fuss dis- tance metric learning using proxies. InProceedings of the IEEE international conference on computer vision, pages 360–368, 2017
2017
-
[18]
Federated prototype-aware pseudo-labeling for semi-supervised medical image clas- sification
Haiwei Pan, Chunling Chen, Kejia Zhang, Yuchao Zhang, and Jian Guan. Federated prototype-aware pseudo-labeling for semi-supervised medical image clas- sification. InIEEE International Conference on Bioinfor- matics and Biomedicine (BIBM), 2025
2025
-
[19]
The future of digital health with federated learning.NPJ digital medicine, 3(1):119, 2020
Nicola Rieke, Jonny Hancox, Wenqi Li, Fausto Milletari, Holger R Roth, Shadi Albarqouni, Spyridon Bakas, Mathieu N Galtier, Bennett A Landman, Klaus Maier- Hein, et al. The future of digital health with federated learning.NPJ digital medicine, 3(1):119, 2020
2020
-
[20]
Felix Sattler, Klaus-Robert M ¨uller, and Wojciech Samek. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints.IEEE transactions on neural networks and learning systems, 32(8):3710–3722, 2020
2020
-
[21]
Facenet: A unified embedding for face recog- nition and clustering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recog- nition and clustering. InProceedings of the IEEE confer- ence on computer vision and pattern recognition, pages 815–823, 2015
2015
-
[22]
Fixmatch: Sim- plifying semi-supervised learning with consistency and confidence.Advances in neural information processing systems, 33:596–608, 2020
Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Sim- plifying semi-supervised learning with consistency and confidence.Advances in neural information processing systems, 33:596–608, 2020
2020
-
[23]
Fedproto: Federated prototype learning across heterogeneous clients
Yue Tan, Guodong Long, Lu Liu, Tianyi Zhou, Qinghua Lu, Jing Jiang, and Chengqi Zhang. Fedproto: Federated prototype learning across heterogeneous clients. InAAAI Conference on Artificial Intelligence, volume 36, 2022
2022
-
[24]
Proxynca++: Revisiting and revitalizing proxy neighbor- hood component analysis
Eu Wern Teh, Terrance DeVries, and Graham W Taylor. Proxynca++: Revisiting and revitalizing proxy neighbor- hood component analysis. InEuropean conference on computer vision, pages 448–464. Springer, 2020
2020
-
[25]
Personalized federated learning with feature alignment and classifier collaboration
Jian Xu, Xinyi Tong, and Shao-Lun Huang. Personalized federated learning with feature alignment and classifier collaboration. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[26]
Wenxin Yang, Xingchen Hu, Xiubin Zhu, Rouwan Wu, Witold Pedrycz, Xinwang Liu, and Jincai Huang. Fedmps: Federated learning in a synergy of multi-level prototype-based contrastive learning and soft label gen- eration.IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[27]
Federated Learning with Non-IID Data
Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Da- mon Civin, and Vikas Chandra. Federated learning with non-iid data.arXiv preprint arXiv:1806.00582, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Collaborative unsupervised visual representation learning from decentralized data
Weiming Zhuang, Xin Gan, Yonggang Wen, Shuai Zhang, and Shuai Yi. Collaborative unsupervised visual representation learning from decentralized data. InPro- ceedings of the IEEE/CVF international conference on computer vision, pages 4912–4921, 2021. 10 A Dataset Configurations DatasetsWe evaluate on three standard federated learning benchmarks.FEMNIST[2] i...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.