Model Multiplicity and Predictive Arbitrariness in Recidivism Risk Assessment
Pith reviewed 2026-06-28 15:41 UTC · model grok-4.3
The pith
Multiple accurate recidivism models agree on predictions far more than worst-case theory requires.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
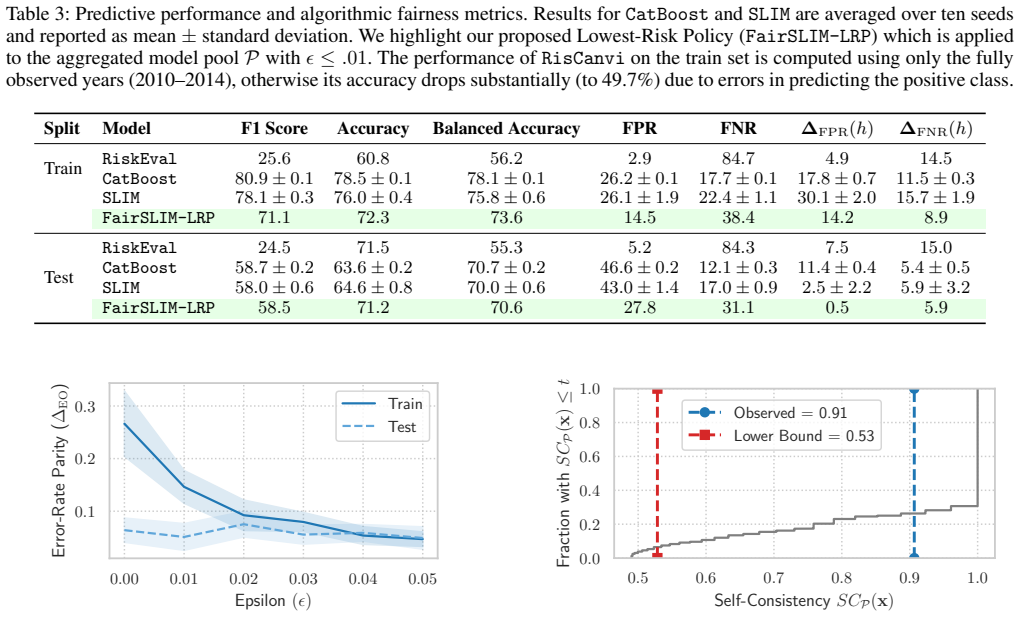
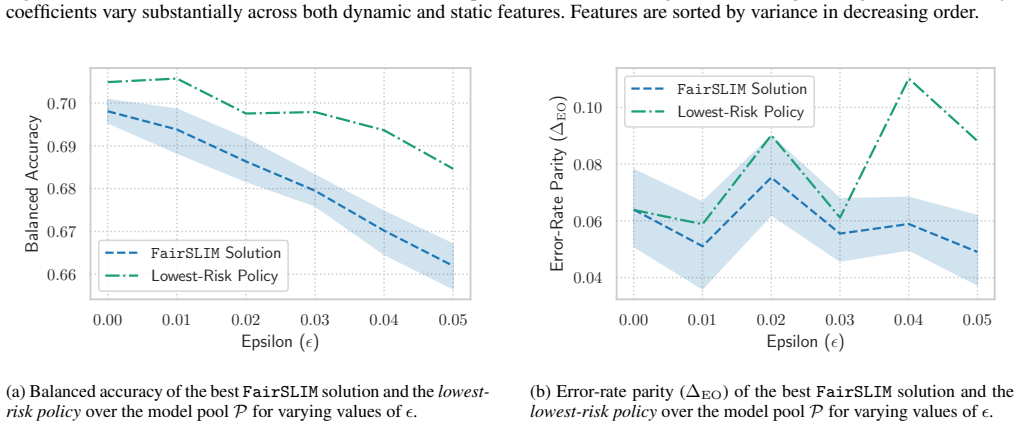
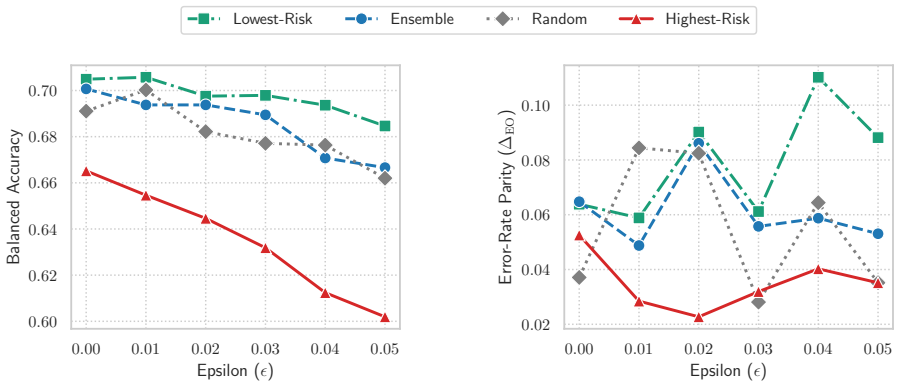
The authors establish that in recidivism risk assessment the existence of many similarly accurate models with comparable error-rate disparities does not necessarily produce severe predictive multiplicity. A derived tight lower bound on expected predictive agreement is not realized in practice; empirical models exhibit substantially higher agreement than the bound guarantees. Assigning each inmate the lowest risk score among the models resolves predictive arbitrariness while preserving the models' performance and fairness properties.
What carries the argument
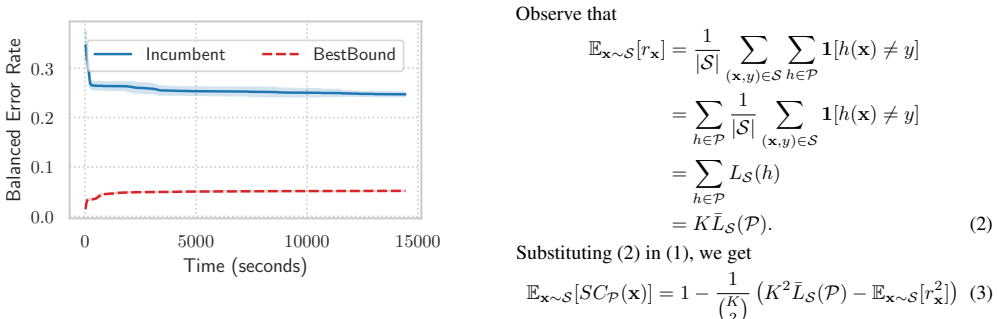
The tight lower bound on expected predictive agreement of any finite set of models over a dataset, together with the min-risk assignment policy that selects the lowest predicted risk for each individual.
Load-bearing premise
The algorithmically generated post-release labels accurately match the true recidivist or non-recidivist outcomes that would be observed in practice.
What would settle it
Collecting fresh post-release recidivism records for a new cohort and finding that the models disagree on those real labels at rates close to the theoretical lower bound would falsify the empirical claim of substantially higher agreement.
Figures







read the original abstract
Prediction tasks over individual futures, which are inherently noisy, often admit multiple similarly accurate models. When these models produce different predictions for the same individual, they raise concerns of arbitrariness in decision-making. How severe can this arbitrariness be, in theory and in practice? How can it be resolved to support high-stakes risk assessment? We address these questions through a study of a machine learning-based decision support system for recidivism risk assessment that has been in use for over 15 years. By translating complex legal rules into an algorithm for labeling post release outcomes (recidivist or non-recidivist), we first construct a dataset of thousands of inmate releases. Using this dataset, we learn interpretable models that improve predictive performance, reduce error-rate disparities between groups, and ensure that rehabilitative progress lowers risk scores. Next, we study predictive multiplicity, by first deriving a tight lower bound on the expected predictive agreement of any finite set of models over a dataset, and then by evaluating the extent to which structural diversity (e.g., different model coefficients) within this set translates to predictive multiplicity (i.e., different predictions for the same individual). Our experiments indicate that the existence of many similarly accurate models with comparable error-rate disparities does not necessarily translate into severe predictive multiplicity. Empirically, similarly performant models can exhibit substantially higher predictive agreement than worst-case theoretical guarantees suggest. We find that a simple policy that assigns each inmate the lowest risk among these models is effective for addressing predictive arbitrariness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a recidivism dataset by translating legal rules into an algorithmic procedure for labeling post-release outcomes as recidivist or non-recidivist. It trains interpretable models that improve predictive performance, reduce error-rate disparities, and incorporate rehabilitative progress. It derives a tight lower bound on expected predictive agreement for any finite set of models and evaluates structural diversity versus predictive multiplicity on the dataset, concluding that similarly accurate models exhibit substantially higher agreement than the worst-case bound and that a min-risk policy mitigates arbitrariness.
Significance. If the constructed labels are a faithful proxy for observed recidivism, the work supplies a parameter-free theoretical bound on agreement together with empirical evidence that multiplicity is milder than worst-case analysis predicts in this domain, plus a simple mitigation policy. This would strengthen the literature on model multiplicity for high-stakes risk assessment.
major comments (2)
- [Abstract, paragraph 2] Abstract, paragraph 2: all empirical claims (higher-than-bound agreement rates, effectiveness of the lowest-risk policy, error-rate disparity measurements) are computed exclusively on labels produced by an algorithmic translation of legal rules. No comparison to actual observed post-release recidivism events, no sensitivity analysis to labeling-rule perturbations, and no external validation are described; this is load-bearing for the central empirical conclusion that real models exceed the theoretical guarantee.
- [Lower-bound derivation (referenced in abstract)] The derivation of the tight lower bound on expected predictive agreement is presented as independent of the data-generating process, yet the subsequent claim that observed models exceed this bound is evaluated only on the same constructed distribution. Without an explicit statement of the assumptions under which the bound remains tight when the label distribution is itself algorithmically defined, the reported gap between theory and experiment cannot be interpreted as evidence about real recidivism.
minor comments (1)
- [Abstract] Abstract provides no equations for the lower bound, no dataset size or class-balance statistics, and no error bars or confidence intervals on the reported agreement rates or policy performance.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. Below we respond point-by-point to the two major comments, clarifying the scope of our empirical claims on the rule-constructed dataset and proposing targeted revisions to the abstract, theoretical section, and discussion to address concerns about interpretation and assumptions.
read point-by-point responses
-
Referee: [Abstract, paragraph 2] Abstract, paragraph 2: all empirical claims (higher-than-bound agreement rates, effectiveness of the lowest-risk policy, error-rate disparity measurements) are computed exclusively on labels produced by an algorithmic translation of legal rules. No comparison to actual observed post-release recidivism events, no sensitivity analysis to labeling-rule perturbations, and no external validation are described; this is load-bearing for the central empirical conclusion that real models exceed the theoretical guarantee.
Authors: We agree that all reported empirical results, including agreement rates, the min-risk policy, and disparity measurements, rely exclusively on the dataset whose labels were produced by algorithmic translation of legal rules. The manuscript does not include comparisons to observed post-release events, sensitivity analyses, or external validation. We will revise the abstract, introduction, and conclusion to explicitly state that the empirical findings apply to this constructed proxy and do not claim correspondence to real observed recidivism without additional validation. This is a partial revision that tempers the interpretation while preserving the paper's focus on multiplicity within the studied setting. revision: partial
-
Referee: [Lower-bound derivation (referenced in abstract)] The derivation of the tight lower bound on expected predictive agreement is presented as independent of the data-generating process, yet the subsequent claim that observed models exceed this bound is evaluated only on the same constructed distribution. Without an explicit statement of the assumptions under which the bound remains tight when the label distribution is itself algorithmically defined, the reported gap between theory and experiment cannot be interpreted as evidence about real recidivism.
Authors: The lower bound is a purely mathematical result on the minimum expected agreement for any finite collection of models given their accuracies; it holds for arbitrary label distributions and makes no reference to how labels are generated. We will insert an explicit clarifying statement in the theoretical section noting that the bound's tightness is with respect to worst-case model sets and is independent of the label-generation mechanism. We will also revise the abstract and discussion to limit claims about the observed gap to the constructed distribution, removing any implication that the gap constitutes evidence about real recidivism beyond the proxy. This revision will be made. revision: yes
Circularity Check
No circularity: theoretical bound derived independently; empirical evaluation uses externally constructed labels
full rationale
The paper first derives a lower bound on expected predictive agreement as a general theoretical result applying to any finite set of models, then separately constructs a dataset via algorithmic translation of legal rules (independent of model training) and evaluates agreement on models fit to that dataset. No quoted step reduces a claimed prediction or first-principles result to a fitted parameter, self-citation chain, or definitional renaming; the bound is presented as worst-case and the empirical excess over the bound is measured on proxy labels whose construction does not embed the multiplicity statistics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The algorithm that translates complex legal rules into recidivist/non-recidivist labels produces ground-truth outcomes that match what would be observed in practice.
Reference graph
Works this paper leans on
-
[1]
Statistical Modeling: The Two Cultures , urldate =
Leo Breiman , journal =. Statistical Modeling: The Two Cultures , urldate =
-
[2]
Setting the
Jackson, Eugenie and Mendoza, Christina , journal =. Setting the. 2020 , month =
2020
-
[3]
2023 , month = jul, day =
Hamilton, Melissa and Ugwudike, Pamela , title =. 2023 , month = jul, day =
2023
-
[4]
Proceedings of the 38th International Conference on Machine Learning , pages =
Characterizing Fairness Over the Set of Good Models Under Selective Labels , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[5]
Proceedings of the 41st International Conference on Machine Learning , pages =
Position: Amazing Things Come From Having Many Good Models , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[6]
Journal of Machine Learning Research , year =
Aaron Fisher and Cynthia Rudin and Francesca Dominici , title =. Journal of Machine Learning Research , year =
-
[7]
Black, Emily and Raghavan, Manish and Barocas, Solon , title =. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2022 , isbn =. doi:10.1145/3531146.3533149 , abstract =
-
[8]
and Kim, Yea-Seul and D'Antoni, Loris and Albarghouthi, Aws , title =
Meyer, Anna P. and Kim, Yea-Seul and D'Antoni, Loris and Albarghouthi, Aws , title =. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , articleno =. 2025 , isbn =. doi:10.1145/3706598.3713524 , abstract =
-
[9]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author=
Systemizing Multiplicity: The Curious Case of Arbitrariness in Machine Learning , volume=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author=. 2025 , month=. doi:10.1609/aies.v8i2.36609 , number=
-
[10]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author=
Fairness and Sparsity Within Rashomon Sets: Enumeration-Free Exploration and Characterization , volume=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author=. 2025 , month=. doi:10.1609/aies.v8i2.36653 , number=
-
[11]
Andrés-Pueyo, Antonio and Arbach-Lucioni, Karin and Redondo, Santiago , publisher =. The RisCanvi , booktitle =. doi:https://doi.org/10.1002/9781119184256.ch13 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/9781119184256.ch13 , year =
-
[12]
Dwork, Cynthia and Hardt, Moritz and Pitassi, Toniann and Reingold, Omer and Zemel, Richard , title =. Proceedings of the 3rd Innovations in Theoretical Computer Science Conference , pages =. 2012 , isbn =. doi:10.1145/2090236.2090255 , abstract =
-
[13]
Equality of Opportunity in Supervised Learning , url =
Hardt, Moritz and Price, Eric and Srebro, Nati , booktitle =. Equality of Opportunity in Supervised Learning , url =
-
[14]
Fairness and Machine Learning: Limitations and Opportunities , author =
-
[15]
Advances in neural information processing systems , volume=
Exploring and interacting with the set of good sparse generalized additive models , author=. Advances in neural information processing systems , volume=
-
[16]
Watson-Daniels, Jamelle and Parkes, David C. and Ustun, Berk , year=. Predictive Multiplicity in Probabilistic Classification , volume=. doi:10.1609/aaai.v37i9.26227 , booktitle=
-
[17]
Proceedings of the 37th International Conference on Machine Learning , pages =
Predictive Multiplicity in Classification , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[18]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages =
Gillis, Talia B and Meursault, Vitaly and Ustun, Berk , title =. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2024 , isbn =. doi:10.1145/3630106.3658912 , abstract =
-
[19]
Dai, Gordon and Ravishankar, Pavan and Yuan, Rachel and Black, Emily and Neill, Daniel B. , title =. Proceedings of the 5th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization , pages =. 2025 , isbn =. doi:10.1145/3757887.3763011 , abstract =
-
[20]
Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages =
Black, Emily and Fredrikson, Matt , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2021 , isbn =. doi:10.1145/3442188.3445894 , abstract =
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Arbitrariness and Social Prediction: The Confounding Role of Variance in Fair Classification , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2024 , month=. doi:10.1609/aaai.v38i20.30203 , abstractNote=
-
[22]
A Path to Simpler Models Starts With Noise , url =
Semenova, Lesia and Chen, Harry and Parr, Ronald and Rudin, Cynthia , booktitle =. A Path to Simpler Models Starts With Noise , url =
-
[23]
Proceedings of the international AAAI conference on web and social media , volume=
Big questions for social media big data: Representativeness, validity and other methodological pitfalls , author=. Proceedings of the international AAAI conference on web and social media , volume=
-
[24]
2016 , journal=
Machine bias , author=. 2016 , journal=
2016
-
[25]
Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) , year =
2024
-
[26]
2022 , address =
Karimi-Haghighi, Marzieh , title =. 2022 , address =
2022
-
[27]
Ustun, Berk and Rudin, Cynthia , title =. Machine Learning , year =. doi:10.1007/s10994-015-5528-6 , url =
-
[28]
Harvard Data Science Review , volume=
The age of secrecy and unfairness in recidivism prediction , author=. Harvard Data Science Review , volume=. 2020 , publisher=
2020
-
[29]
arXiv preprint arXiv:2106.05498 , year=
It's compaslicated: The messy relationship between rai datasets and algorithmic fairness benchmarks , author=. arXiv preprint arXiv:2106.05498 , year=
-
[30]
Georgetown Law Journal , year =
Black, Emily and Koepke, John Logan and Kim, Pauline and Barocas, Solon and Hsu, Mingwei , title =. Georgetown Law Journal , year =. doi:10.2139/ssrn.4590481 , url =
-
[31]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
Algorithmic fairness from the perspective of legal anti-discrimination principles , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[32]
The Modern Law Review , volume =
Adams-Prassl, Jeremias and Binns, Reuben and Kelly-Lyth, Aislinn , title =. The Modern Law Review , volume =. doi:https://doi.org/10.1111/1468-2230.12759 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/1468-2230.12759 , abstract =
-
[33]
Andrews, D. A. and Bonta, James and Hoge, R. D. , title =. Criminal Justice and Behavior , volume =. 1990 , doi =
1990
-
[34]
Artificial Intelligence and Law , year =
Portela, Manuel and Castillo, Carlos and Tolan, Song. Artificial Intelligence and Law , year =. doi:10.1007/s10506-024-09393-y , url =
-
[35]
Proceedings of the Conference on Fairness, Accountability, and Transparency , pages =
Ustun, Berk and Spangher, Alexander and Liu, Yang , title =. Proceedings of the Conference on Fairness, Accountability, and Transparency , pages =. 2019 , isbn =. doi:10.1145/3287560.3287566 , abstract =
-
[36]
Proceedings of the 1st Conference on Fairness, Accountability and Transparency , pages =
Interventions over Predictions: Reframing the Ethical Debate for Actuarial Risk Assessment , author =. Proceedings of the 1st Conference on Fairness, Accountability and Transparency , pages =. 2018 , editor =
2018
-
[37]
2017 , month = jun, day =
Wexler, Rebecca , title =. 2017 , month = jun, day =
2017
-
[38]
2024 , publisher=
Algorithmic institutionalism: the changing rules of social and political life , author=. 2024 , publisher=
2024
-
[39]
Criminal Justice and Behavior , volume =
Zachary Hamilton and Alex Kigerl and Michael Campagna and Robert Barnoski and Stephen Lee and Jacqueline van Wormer and Lauren Block , title =. Criminal Justice and Behavior , volume =. 2016 , doi =
2016
-
[40]
Peter B. Hoffman , abstract =. Twenty years of operational use of a risk prediction instrument: The United States parole commission's salient factor score , journal =. 1994 , issn =. doi:https://doi.org/10.1016/0047-2352(94)90090-6 , url =
-
[41]
The age and crime relationship: Social variation, social explanations
Ulmer, \ Jeffery T.\ and Darrell Steffensmeier. The age and crime relationship: Social variation, social explanations. The Nurture Versus Biosocial Debate in Criminology. 2014. doi:10.4135/9781483349114.n23
-
[42]
CatBoost: unbiased boosting with categorical features , url =
Prokhorenkova, Liudmila and Gusev, Gleb and Vorobev, Aleksandr and Dorogush, Anna Veronika and Gulin, Andrey , booktitle =. CatBoost: unbiased boosting with categorical features , url =
-
[43]
2024 , month = jan, url =
2024
-
[44]
2026 , month = mar, day =
Jimenez Arandia, Pablo , title =. 2026 , month = mar, day =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.