Network Learning with Semi-relaxed Gromov-Wasserstein
Pith reviewed 2026-06-28 15:35 UTC · model grok-4.3
The pith
Semi-relaxed Gromov-Wasserstein recovers network generative mechanisms with an optimality gap vanishing at rate O(1/n).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
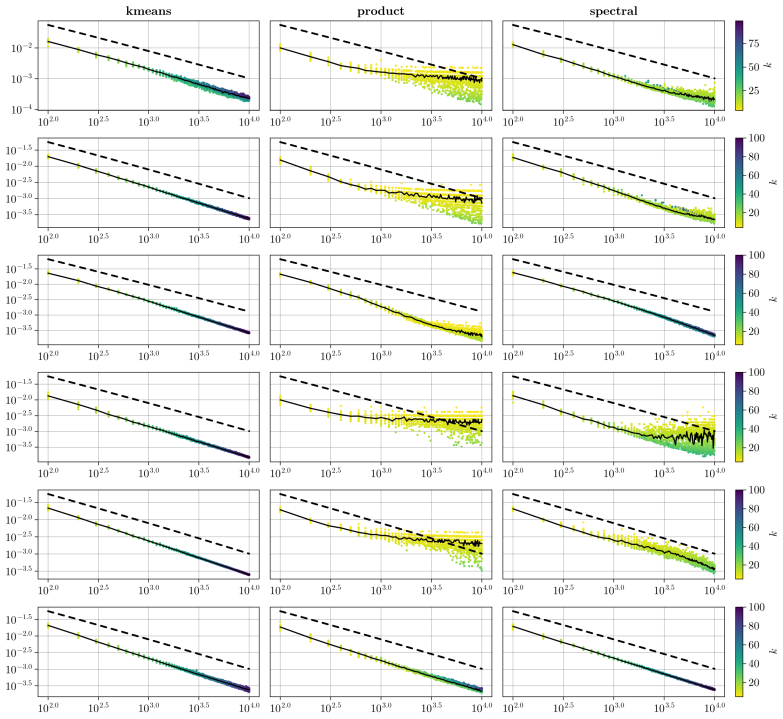
The semi-relaxed Gromov-Wasserstein objective relaxes the combinatorial node-assignment problem to probabilistic couplings and thereby yields a tractable estimator for the generative mechanism of a network. Despite the relaxation, the resulting solution is typically deterministic because the optimality gap to the true deterministic assignment vanishes at rate O(1/n). This property permits rigorous statistical analysis that establishes consistency and minimax-optimal convergence rates for both stochastic block models and Hölder-smooth graphons.
What carries the argument
semi-relaxed Gromov-Wasserstein objective that relaxes node assignment to probabilistic couplings
If this is right
- The block-coordinate conditional gradient algorithm computes the estimator efficiently and scales with the number of nodes.
- The method recovers the underlying model consistently for stochastic block models.
- Minimax-optimal convergence rates hold for both stochastic block models and Hölder-smooth graphons.
- The low-dimensional representation obtained from the objective captures the essential generative structure.
Where Pith is reading between the lines
- The same relaxation technique could support statistical guarantees for other random-graph families if comparable gap bounds can be established.
- The formulation may extend to other graph-matching tasks where exact combinatorial alignment remains intractable.
- Empirical checks on networks whose structure deviates from the assumed classes would test how quickly the O(1/n) gap bound degrades.
Load-bearing premise
The network is generated from a stochastic block model or a Hölder-smooth graphon.
What would settle it
A sequence of networks drawn from a stochastic block model for which the estimation error fails to attain the claimed minimax rate or for which the optimality gap does not vanish at rate O(1/n).
Figures










read the original abstract
Estimating the generative mechanism of large-scale networks is a fundamental challenge in statistical machine learning. It requires the identification of the latent connectivity structure, which is in general an NP-hard combinatorial problem due to the absence of canonical node labels. We address this challenge by allowing for probabilistic couplings, thereby relaxing the assignment problem. Our estimation framework can be formulated as a semi-relaxed Gromov-Wasserstein objective and provides a low-dimensional representation of the generative structure. We solve this via a block-coordinate conditional gradient algorithm. Despite the relaxation, the resulting solution is typically deterministic: in fact, we show that the optimality gap between the relaxed solution and the deterministic assignment vanishes at rate $O(1/n)$, where $n$ is the number of nodes. This allows for tractable recovery of the underlying model and enables rigorous statistical analysis: we establish consistency and minimax-optimal convergence rates for both stochastic block models and Holder-smooth graphons. Our implementation scales efficiently with $n$, as demonstrated on both synthetic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a semi-relaxed Gromov-Wasserstein objective to estimate the generative mechanism of large networks by relaxing the combinatorial assignment problem to probabilistic couplings. It is solved via a block-coordinate conditional gradient algorithm. The central theoretical claims are that the optimality gap to a deterministic assignment vanishes at rate O(1/n) and that this enables consistency plus minimax-optimal rates under stochastic block models and Hölder-smooth graphons. Experiments on synthetic and real data are mentioned to illustrate scalability.
Significance. If the O(1/n) gap result and the accompanying consistency/minimax statements hold, the work would supply a computationally attractive relaxation of network alignment that still recovers deterministic structure asymptotically, together with nonparametric rates under standard generative assumptions. This would be a useful bridge between optimal transport relaxations and statistical graphon estimation.
major comments (2)
- [Abstract] Abstract: the existence of proofs for the O(1/n) optimality gap and for minimax rates is asserted, yet no derivation steps, explicit assumption list, or equation references are supplied; the central claims therefore cannot be verified from the available text.
- [Abstract] Abstract: the consistency and minimax statements are conditioned on the generative mechanism belonging to the class of stochastic block models or Hölder-smooth graphons; no discussion is given of what occurs when this modeling assumption is violated, which is load-bearing for the recovery guarantees.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on the abstract. We address the two major comments point by point below.
read point-by-point responses
-
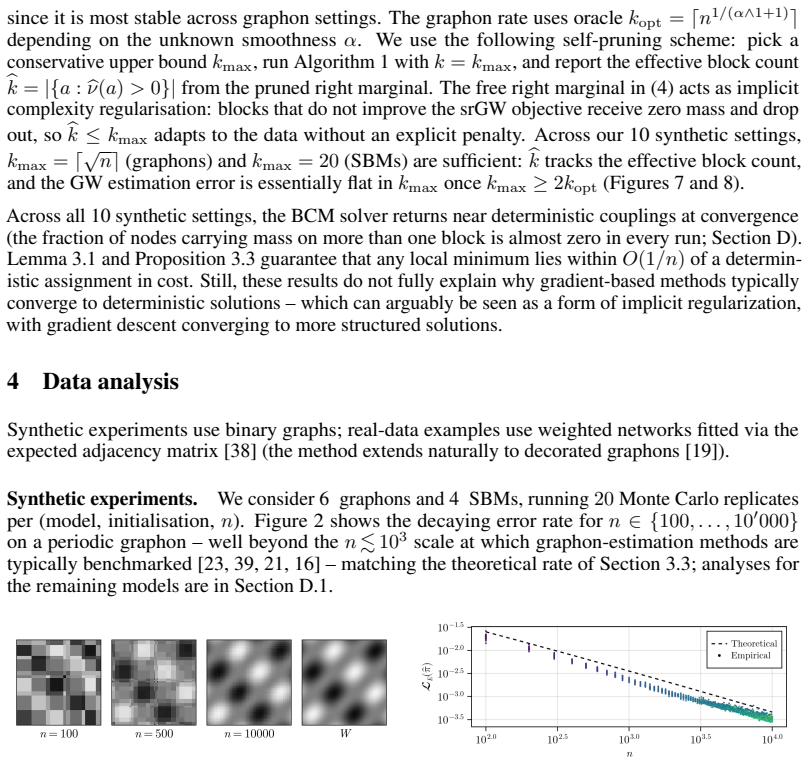
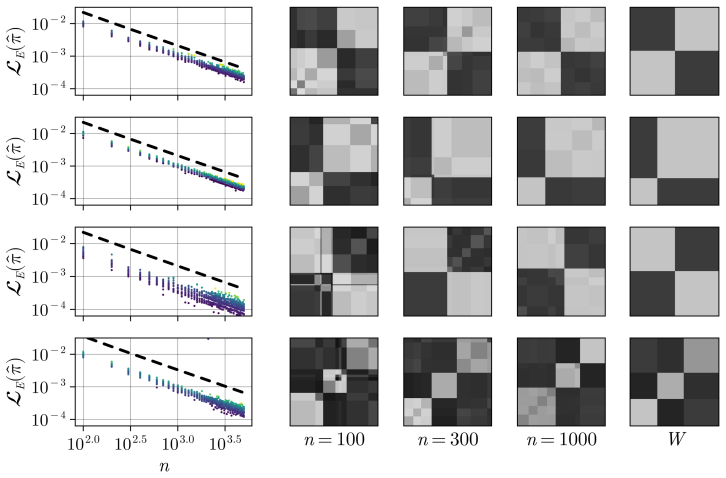
Referee: [Abstract] Abstract: the existence of proofs for the O(1/n) optimality gap and for minimax rates is asserted, yet no derivation steps, explicit assumption list, or equation references are supplied; the central claims therefore cannot be verified from the available text.
Authors: The abstract is a concise summary and therefore omits detailed derivations, assumption lists, and equation references. The full manuscript supplies these elements in the theoretical development (proof of the O(1/n) gap, explicit assumptions, and minimax statements with equation references). To improve verifiability directly from the abstract, we will add brief references to the relevant theorems. revision: yes
-
Referee: [Abstract] Abstract: the consistency and minimax statements are conditioned on the generative mechanism belonging to the class of stochastic block models or Hölder-smooth graphons; no discussion is given of what occurs when this modeling assumption is violated, which is load-bearing for the recovery guarantees.
Authors: The consistency and minimax results are derived under the stated generative assumptions, which are standard for obtaining sharp rates. The manuscript does not analyze behavior under misspecification. We agree that a discussion of this limitation is warranted and will add a short paragraph in the discussion section noting that the guarantees may not hold, or may degrade, when the network is not generated from an SBM or Hölder-smooth graphon. revision: yes
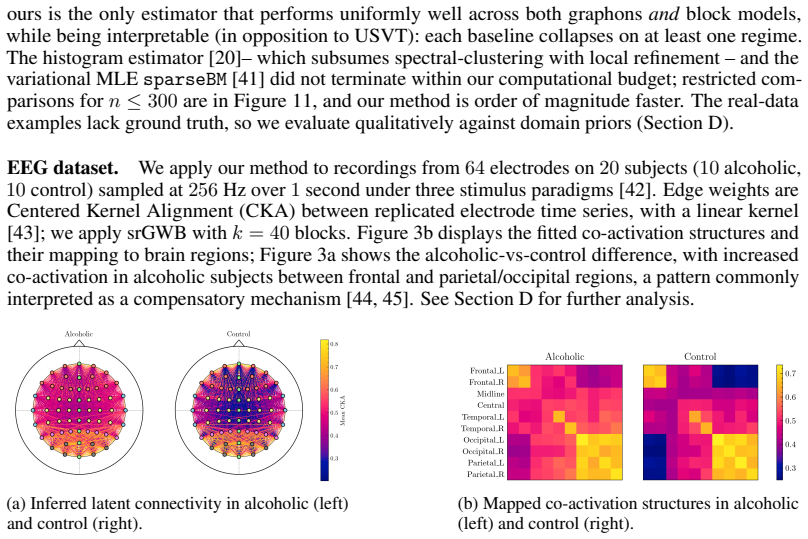
Circularity Check
No significant circularity detected
full rationale
The derivation chain begins from the semi-relaxed GW objective, proceeds to a block-coordinate conditional gradient solver, then establishes an O(1/n) optimality gap to deterministic assignments via direct analysis of the relaxation, and finally invokes standard consistency arguments under explicit SBM or Hölder graphon assumptions. No equation reduces to a fitted parameter renamed as prediction, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled via prior work by the same authors. The statistical rates are conditioned on the model class in the usual nonparametric manner and do not collapse to the method's own inputs by construction. The provided abstract and claims contain no self-definitional or renaming steps, confirming the central results are independent of the inputs.
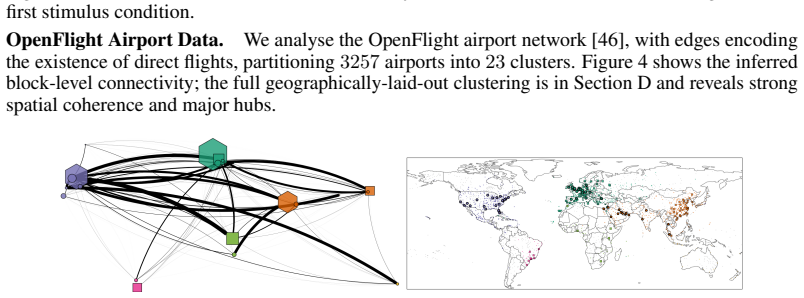
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Network observations are generated exactly from an SBM or Holder-smooth graphon
Reference graph
Works this paper leans on
-
[1]
Social structure of facebook networks
Amanda L Traud, Peter J Mucha, and Mason A Porter. Social structure of facebook networks. Physica A: Statistical Mechanics and its Applications, 391(16):4165–4180, 2012
2012
-
[2]
Modeling polypharmacy side effects with graph convolutional networks.Bioinformatics, 34(13):i457–i466, 2018
Marinka Zitnik, Monica Agrawal, and Jure Leskovec. Modeling polypharmacy side effects with graph convolutional networks.Bioinformatics, 34(13):i457–i466, 2018
2018
-
[3]
Large-scale analysis of disease pathways in the human interactome
Monica Agrawal, Marinka Zitnik, and Jure Leskovec. Large-scale analysis of disease pathways in the human interactome. InPacific Symposium on Biocomputing. Pacific Symposium on Biocomputing, volume 23, page 111, 2018
2018
-
[4]
Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
2017
-
[5]
Hierarchical graph learning for protein–protein interaction
Ziqi Gao, Chenran Jiang, Jiawen Zhang, Xiaosen Jiang, Lanqing Li, Peilin Zhao, Huanming Yang, Yong Huang, and Jia Li. Hierarchical graph learning for protein–protein interaction. Nature Communications, 14(1):1093, 2023
2023
-
[6]
Graph convolutional neural networks for web-scale recommender systems
Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 974–983, 2018
2018
-
[7]
Diffusion convolutional recurrent neural network: Data-driven traffic forecasting
Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. InProceedings of the International Conference on Learning Representations (ICLR), 2018
2018
-
[8]
Chao Gao, Yu Lu, and Harrison H. Zhou. Rate-Optimal Graphon Estimation.The Annals of Statistics, 43(6):2624–2652, 2015. ISSN 0090-5364. doi: 10.1214/15-AOS1354
-
[9]
doi: https://doi.org/10.1016/0378-8733(83)90021-7
Paul W Holland, Kathryn Blackmond Laskey, and Samuel Leinhardt. Stochastic blockmodels: First steps.Social Networks, 5(2):109–137, 1983. doi: 10.1016/0378-8733(83)90021-7
-
[10]
American Mathematical Soc.,
L´aszl´o Lov´asz.Large networks and graph limits, volume 60. American Mathematical Soc.,
-
[11]
Gromov–Wasserstein Distances and the Metric Approach to Object Matching
Facundo M´emoli. Gromov–Wasserstein Distances and the Metric Approach to Object Matching. Foundations of Computational Mathematics, 11(4):417–487, August 2011. ISSN 1615-3383. doi: 10.1007/s10208-011-9093-5
-
[12]
Gromov-Wasserstein Averaging of Kernel and Distance Matrices
Gabriel Peyr´e, Marco Cuturi, and Justin Solomon. Gromov-Wasserstein Averaging of Kernel and Distance Matrices. InProceedings of The 33rd International Conference on Machine Learning, pages 2664–2672. PMLR, June 2016
2016
-
[13]
Gromov-Wasserstein Learning for Graph Matching and Node Embedding
Hongteng Xu, Dixin Luo, Hongyuan Zha, and Lawrence Carin Duke. Gromov-Wasserstein Learning for Graph Matching and Node Embedding. InProceedings of the 36th International Conference on Machine Learning, pages 6932–6941. PMLR, May 2019
2019
-
[14]
Fused Gromov-Wasserstein Distance for Structured Objects.Algorithms, 13(9):212, August 2020
Titouan Vayer, Laetitia Chapel, Remi Flamary, Romain Tavenard, and Nicolas Courty. Fused Gromov-Wasserstein Distance for Structured Objects.Algorithms, 13(9):212, August 2020. ISSN 1999-4893. doi: 10.3390/a13090212
-
[15]
The Z-Gromov-Wasserstein Distance, January 2025
Martin Bauer, Facundo M´emoli, Tom Needham, and Mao Nishino. The Z-Gromov-Wasserstein Distance, January 2025
2025
-
[16]
Hongteng Xu, Dixin Luo, Lawrence Carin, and Hongyuan Zha. Learning Graphons via Structured Gromov-Wasserstein Barycenters.Proceedings of the AAAI Conference on Artificial Intelligence, 35(12):10505–10513, May 2021. ISSN 2374-3468. doi: 10.1609/aaai.v35i12. 17257
-
[17]
G-Mixup: Graph Data Augmentation for Graph Classification
Xiaotian Han, Zhimeng Jiang, Ninghao Liu, and Xia Hu. G-Mixup: Graph Data Augmentation for Graph Classification. InProceedings of the 39th International Conference on Machine Learning, pages 8230–8248. PMLR, June 2022. 10
2022
-
[18]
Tsybakov, and Nicolas Verzelen
Olga Klopp, Alexandre B. Tsybakov, and Nicolas Verzelen. Oracle inequalities for network models and sparse graphon estimation.The Annals of Statistics, 45(1):316–354, February 2017. ISSN 0090-5364, 2168-8966. doi: 10.1214/16-AOS1454
-
[19]
Charles Dufour and Sofia C. Olhede. Inference for decorated graphs and application to multiplex networks, August 2024
2024
-
[20]
Sofia C. Olhede and Patrick J. Wolfe. Network histograms and universality of blockmodel approximation.Proceedings of the National Academy of Sciences, 111(41):14722–14727, October 2014. doi: 10.1073/pnas.1400374111
-
[21]
Matrix estimation by Universal Singular Value Thresholding.The Annals of Statistics, 43(1):177–214, February 2015
Sourav Chatterjee. Matrix estimation by Universal Singular Value Thresholding.The Annals of Statistics, 43(1):177–214, February 2015. ISSN 0090-5364, 2168-8966. doi: 10.1214/ 14-AOS1272
2015
-
[22]
Arash A. Amini and Elizaveta Levina. On semidefinite relaxations for the block model. The Annals of Statistics, 46(1):149–179, February 2018. ISSN 0090-5364, 2168-8966. doi: 10.1214/17-AOS1545
-
[23]
A Consistent Histogram Estimator for Exchangeable Graph Models
Stanley Chan and Edoardo Airoldi. A Consistent Histogram Estimator for Exchangeable Graph Models. InProceedings of the 31st International Conference on Machine Learning, pages 208–216. PMLR, January 2014
2014
-
[24]
Alain Celisse, Jean-Jacques Daudin, and Laurent Pierre. Consistency of maximum-likelihood and variational estimators in the stochastic block model.Electronic Journal of Statistics, 6: 1847–1899, 2012. doi: 10.1214/12-EJS729
-
[25]
Spectral clustering and the high-dimensional stochastic blockmodel.The Annals of Statistics, 39(4):1878–1915, 2011
Karl Rohe, Sourav Chatterjee, and Bin Yu. Spectral clustering and the high-dimensional stochastic blockmodel.The Annals of Statistics, 39(4):1878–1915, 2011. doi: 10.1214/ 11-AOS887
1915
-
[26]
Consistency of spectral clustering in stochastic block models
Jing Lei and Alessandro Rinaldo. Consistency of spectral clustering in stochastic block models. The Annals of Statistics, 43(1):215–237, 2015. doi: 10.1214/14-AOS1274
-
[27]
Optimal Transport for structured data with application on graphs
Vayer Titouan, Nicolas Courty, Romain Tavenard, Chapel Laetitia, and R´emi Flamary. Optimal Transport for structured data with application on graphs. InProceedings of the 36th International Conference on Machine Learning, pages 6275–6284. PMLR, May 2019
2019
-
[28]
Semi- relaxed Gromov Wasserstein divergence with applications on graphs
C´edric Vincent-Cuaz, R´emi Flamary, Marco Corneli, Titouan Vayer, and Nicolas Courty. Semi- relaxed Gromov Wasserstein divergence with applications on graphs. InICLR 2022 - 10th International Conference on Learning Representations, pages 1–28, Virtual, France, April 2022
2022
-
[29]
Online graph dictionary learning
C´edric Vincent-Cuaz, Titouan Vayer, R´emi Flamary, Marco Corneli, and Nicolas Courty. Online graph dictionary learning. InInternational conference on machine learning, pages 10564–10574. PMLR, 2021
2021
-
[30]
Generalized dimension reduction using semi-relaxed Gromov-Wasserstein distance
Ranthony A Clark, Tom Needham, and Thomas Weighill. Generalized dimension reduction using semi-relaxed Gromov-Wasserstein distance. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 16082–16090, 2025. ISBN 2374-3468
2025
-
[31]
Distributional reduction: Unifying dimensionality reduction and clustering with gromov-wasserstein.Transactions on Machine Learning Research, 2025
Hugues Van Assel, C´edric Vincent-Cuaz, Nicolas Courty, R´emi Flamary, Pascal Frossard, and Titouan Vayer. Distributional reduction: Unifying dimensionality reduction and clustering with gromov-wasserstein.Transactions on Machine Learning Research, 2025. ISSN 2835-8856
2025
-
[32]
On probabilistic embeddings in optimal dimension reduction
Ryan Murray and Adam Pickarski. On probabilistic embeddings in optimal dimension reduction. Journal of Machine Learning Research, 26(234):1–39, 2025
2025
-
[33]
Peter J Bickel and Aiyou Chen. A nonparametric view of network models and Newman– Girvan and other modularities.Proceedings of the National Academy of Sciences, 106(50): 21068–21073, 2009. doi: 10.1073/pnas.0907096106
-
[34]
Peter Orbanz and Daniel M. Roy. Bayesian Models of Graphs, Arrays and Other Exchangeable Random Structures.IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(2): 437–461, February 2015. ISSN 1939-3539. doi: 10.1109/TPAMI.2014.2334607. 11
-
[35]
Emmanuel Abbe, Afonso S. Bandeira, and Georgina Hall. Exact recovery in the stochastic block model.IEEE Transactions on Information Theory, 62(1):471–487, 2016. doi: 10.1109/ TIT.2015.2490670
-
[36]
Convergence Rate of Frank-Wolfe for Non-Convex Objectives, July 2016
Simon Lacoste-Julien. Convergence Rate of Frank-Wolfe for Non-Convex Objectives, July 2016
2016
-
[37]
Alaya, Aur´elie Boisbunon, Stanislas Chambon, Laetitia Chapel, Adrien Corenflos, Kilian Fatras, Nemo Fournier, L ´eo Gautheron, Nathalie T
R´emi Flamary, Nicolas Courty, Alexandre Gramfort, Mokhtar Z. Alaya, Aur´elie Boisbunon, Stanislas Chambon, Laetitia Chapel, Adrien Corenflos, Kilian Fatras, Nemo Fournier, L ´eo Gautheron, Nathalie T. H. Gayraud, Hicham Janati, Alain Rakotomamonjy, Ievgen Redko, Antoine Rolet, Antony Schutz, Vivien Seguy, Danica J. Sutherland, Romain Tavenard, Alexander ...
2021
-
[38]
Dalalyan, Francis Kramarz, Philippe Chon ´e, and Xavier D’Haultfoeuille
Etienne Donier-Meroz, Arnak S. Dalalyan, Francis Kramarz, Philippe Chon ´e, and Xavier D’Haultfoeuille. Graphon Estimation in bipartite graphs with observable edge labels and unobservable node labels, September 2023
2023
-
[39]
Yuan Zhang, Elizaveta Levina, and Ji Zhu. Estimating network edge probabilities by neigh- bourhood smoothing.Biometrika, 104(4):771–783, December 2017. ISSN 0006-3444. doi: 10.1093/biomet/asx042
-
[40]
Antoine Channarond, Jean-Jacques Daudin, and St´ephane Robin. Classification and estimation in the Stochastic Blockmodel based on the empirical degrees.Electronic Journal of Statistics, 6 (none):2574–2601, January 2012. ISSN 1935-7524, 1935-7524. doi: 10.1214/12-EJS753
-
[41]
SparseBM: A Python Module for Handling Sparse Graphs with Block Models
Gabriel Frisch, Jean-Benoist Leger, and Yves Grandvalet. SparseBM: A Python Module for Handling Sparse Graphs with Block Models. 2022
2022
-
[42]
EEG Database, 1995
Henri Begleiter. EEG Database, 1995
1995
-
[43]
Similarity of Neural Network Representations Revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of Neural Network Representations Revisited. InProceedings of the 36th International Conference on Machine Learning, pages 3519–3529. PMLR, May 2019
2019
-
[44]
Remapping the brain to compensate for impairment in recovering alcoholics.Cerebral cortex, 23(1):97–104, 2013
Sandra Chanraud, Anne-Lise Pitel, Eva M M¨uller-Oehring, Adolf Pfefferbaum, and Edith V Sullivan. Remapping the brain to compensate for impairment in recovering alcoholics.Cerebral cortex, 23(1):97–104, 2013
2013
-
[45]
Rui Cao, Zheng Wu, Haifang Li, Jie Xiang, and Junjie Chen. Disturbed connectivity of eeg functional networks in alcoholism: A graph-theoretic analysis.Bio-Medical Materials and Engineering, 24(6):2927–2936, 2014. doi: 10.3233/BME-141112
-
[46]
Openflights airports database
OpenFlights. Openflights airports database. https://openflights.org/data.html, 2017. Accessed: 2026-01-14
2017
-
[47]
Yunpeng Zhao, Elizaveta Levina, and Ji Zhu. Consistency of community detection in networks under degree-corrected stochastic block models.The Annals of Statistics, 40(4):2266–2292, August 2012. ISSN 0090-5364, 2168-8966. doi: 10.1214/12-AOS1036
-
[48]
Graphons, cut norm and distance, couplings and rearrangements, June 2011
Svante Janson. Graphons, cut norm and distance, couplings and rearrangements, June 2011
2011
-
[49]
Limits of compact decorated graphs, October 2010
L ´aszl´o Lov´asz and Bal´azs Szegedy. Limits of compact decorated graphs, October 2010
2010
-
[50]
Probability-graphons: Limits of large dense weighted graphs, December 2023
Romain Abraham, Jean-Franc ¸ois Delmas, and Julien Weibel. Probability-graphons: Limits of large dense weighted graphs, December 2023
2023
-
[51]
Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization
Martin Jaggi. Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization. In Proceedings of the 30th International Conference on Machine Learning, pages 427–435. PMLR, February 2013. 12 A Background A.1 Generative models for networks Generative models for networks provide a probabilistic framework for describing graph-valued data. In this section ...
2013
-
[52]
For (j, d) = (i, a), π′ i,a =π i,a +Pki b=2 πi,b ≥0
(Nonnegativity):For (j, d)/∈ {(i, a),(i, b)} we have π′ j,d =π j,d ≥0 . For (j, d) = (i, a), π′ i,a =π i,a +Pki b=2 πi,b ≥0 . For (j, d) = (i, b), π′ i,b =π i,b −π i,b = 0. Hence, π′ j,d ≥0 for allj, d
-
[53]
Pk d=1 πj,d = 1/n for every j
(Left marginal)By assumption π has left marginal uniform, i.e. Pk d=1 πj,d = 1/n for every j. For any fixed j̸=i we have ψj,d = 0 for all d, henceP d π′ j,d =P d πj,d = 1/n. For j=i ,Pk d=1 π′ i,d =P d πi,d +P d ψi,d = 1 n + 0 = 1 n , since ψ has zero total mass. Therefore, the left marginal ofπ ′ is still uniform on[n]
-
[54]
15 Since LE, ˜B is quadratic in the coupling, we can split it into what is essentially a Taylor decomposition in the first and second-order variations ofL E, ˜B
(Total mass)Since the left marginal is preserved for every j, the total mass P j,d π′ j,d remainsP j(1/n) = 1, soπ ′ is normalized as a coupling. 15 Since LE, ˜B is quadratic in the coupling, we can split it into what is essentially a Taylor decomposition in the first and second-order variations ofL E, ˜B. Explicitly, one can see that: LE, ˜B(π′) =L E, ˜B...
-
[55]
0.2 0.8 0.8 0.2 # 2. h 0.5 0.5 i
also showed more results for constrained least square estimators. An interesting question is whether we could get such an estimator using a penalized version of the srGWB, where we add a penalty term to the objective that penalizes small partitions. We leave this question for future work. C Algorithmic details C.1 On implicit regularization toward determi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.