Ego-METAS: Egocentric online Multimodal Energy-efficient Temporal Action Segmentation benchmark
Pith reviewed 2026-06-28 22:35 UTC · model grok-4.3
The pith
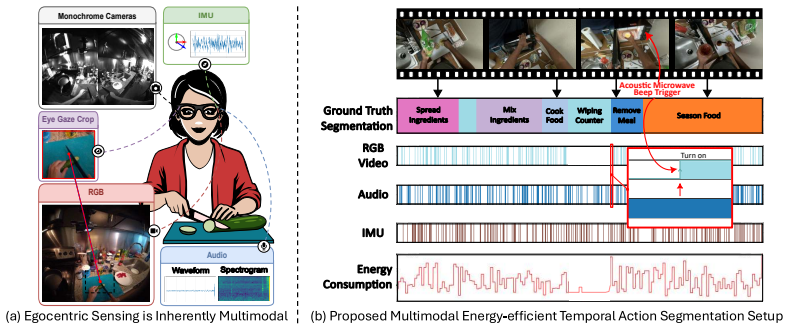
Ego-METAS requires models to dynamically choose sensors at each timestep in long egocentric videos while staying inside fixed energy budgets for temporal action segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
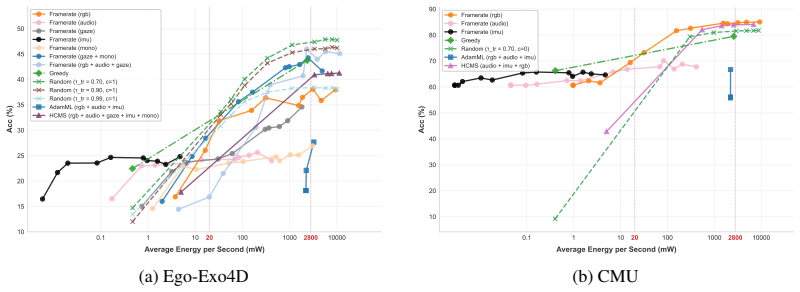
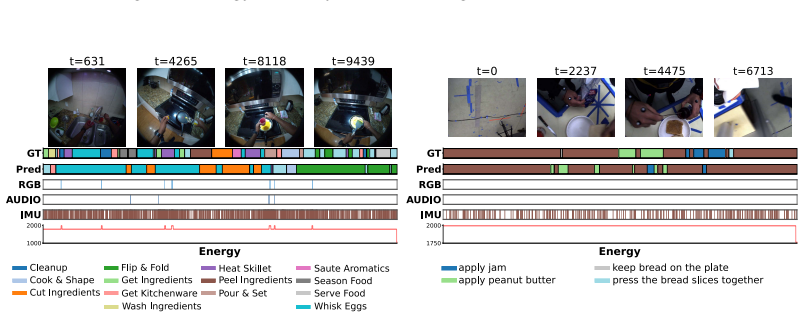
Ego-METAS supplies unified data, splits, and features for an online multimodal temporal action segmentation task in which models must select which of five sensors to activate at each timestep without exceeding representative energy budgets; the released baselines indicate that optimal routing is highly scenario-dependent, that prior policy-learning approaches do not adapt well to untrimmed streams, and that simple dynamic fusion of complementary modalities is already effective at meeting the budgets while preserving accuracy.
What carries the argument
Dynamic sensor selection policy that routes among RGB, audio, gaze, IMU, and monochrome inputs at every timestep under strict per-step energy limits.
If this is right
- Any policy must operate continuously on long untrimmed streams rather than on short pre-segmented clips.
- Complementary modalities must be treated as interchangeable resources that can be turned on or off to stay inside the budget.
- Scenario-specific adaptation becomes necessary because no single routing rule works across all environments and budgets.
- Policy-learning algorithms require redesign to handle the lack of clear episode boundaries in always-on settings.
Where Pith is reading between the lines
- The benchmark could be used to measure how much accuracy is lost when real hardware energy traces replace the modeled budgets.
- Methods developed here might transfer to other always-on embodied tasks such as navigation or object search that also face sensor-selection trade-offs.
- Extending the testbed with measured power draw on specific chips would let researchers check whether the current budgets are conservative or optimistic.
Load-bearing premise
The energy budgets used in the benchmark match the actual power limits of resource-constrained hardware and the chosen videos expose the main difficulties of continuous always-on operation.
What would settle it
A controlled run in which a single fixed sensor schedule meets the same energy budgets yet matches or exceeds the accuracy of all dynamic routing policies across the full untrimmed test set.
Figures

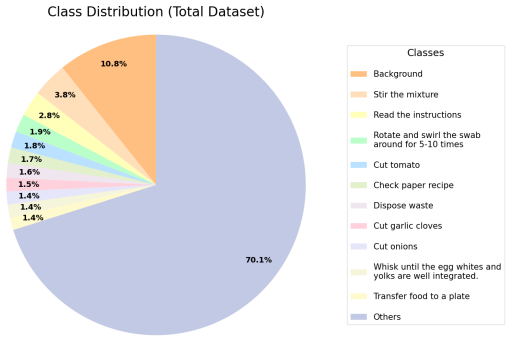
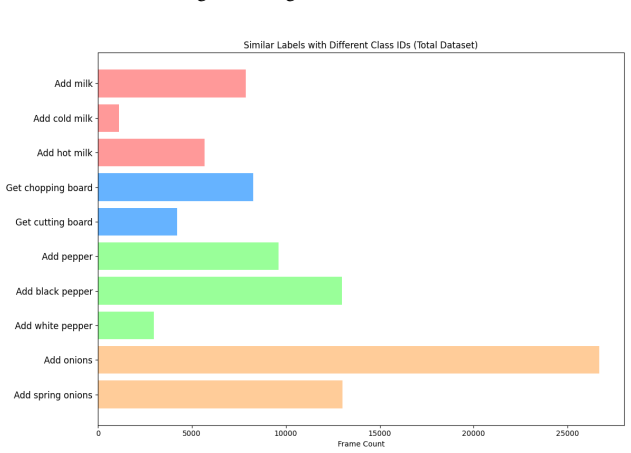
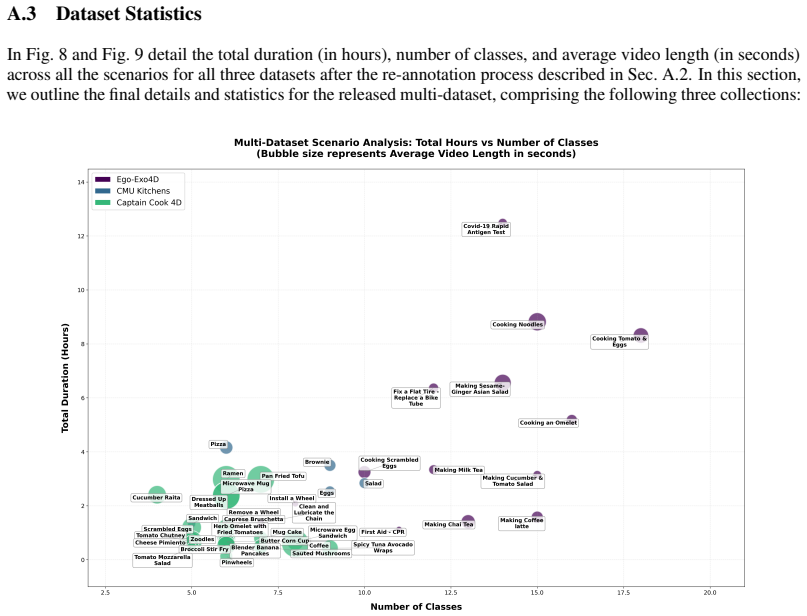
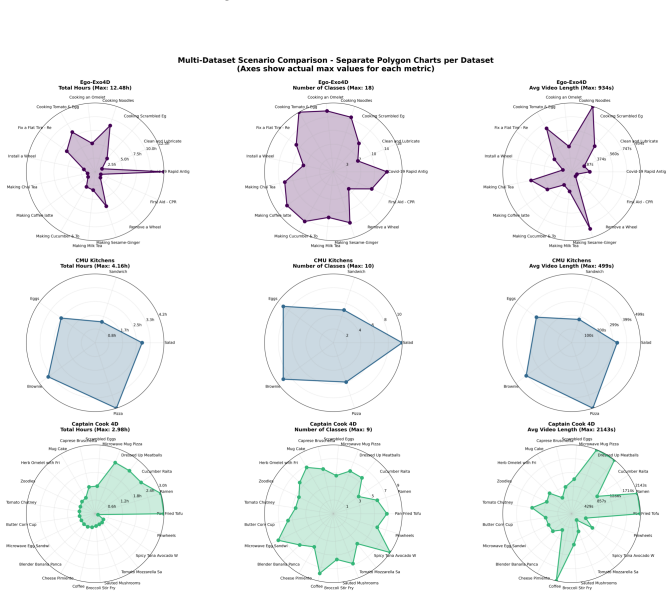




read the original abstract
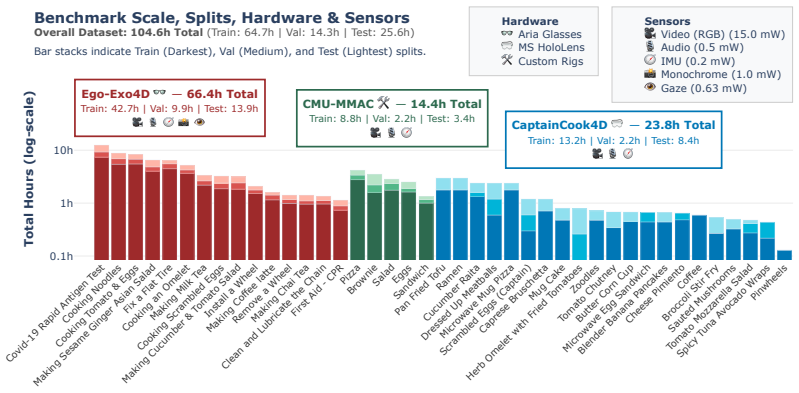
To operate in the physical world, embodied agents must perceive their environment in an "always-on" fashion, selectively accessing the most informative sensors to balance energy constraints and task accuracy. Despite its importance for resource-constrained devices, energy-aware perception remains under-explored, with most prior work assuming unlimited compute. To address this, we introduce Ego-METAS: the first Egocentric online Multimodal Energy-efficient Temporal Action Segmentation benchmark. Ego-METAS provides a unified testbed of more than 100 hours of untrimmed egocentric video from EgoExo4D, CMU-MMAC, and CaptainCook4D, spanning 5 modalities (RGB, audio, gaze, IMU, and monochrome camera). We formulate an online temporal action segmentation task where models must dynamically select which sensors to activate at each timestep while strictly adhering to hardware-representative energy budgets. Alongside the benchmark, we release unified splits, cleaned annotations, pre-extracted features, and a diverse suite of baseline routing policies. Our evaluations show that optimal routing is highly scenario-dependent, and that existing policy-learning methods, designed primarily for trimmed clips, struggle to adapt to continuous, untrimmed environments. However, even simple dynamic fusion of complementary modalities (e.g., via random routing) proves critical for balancing predictive accuracy against strict energy budgets. Ultimately, Ego-METAS provides a standardized foundation to develop robust, cost-aware policies for autonomous, always-on embodied AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ego-METAS, the first benchmark for egocentric online multimodal energy-efficient temporal action segmentation. It aggregates >100 hours of untrimmed video from EgoExo4D, CMU-MMAC, and CaptainCook4D across five modalities (RGB, audio, gaze, IMU, monochrome), formulates an online TAS task in which models must dynamically activate sensors at each timestep while respecting fixed hardware-representative energy budgets, releases unified splits, cleaned annotations, features, and a suite of routing-policy baselines, and reports that routing is highly scenario-dependent while even simple dynamic fusion (e.g., random routing) is critical for trading accuracy against strict energy limits.
Significance. If the energy budgets are shown to be derived from actual device measurements, the benchmark would supply a much-needed standardized testbed for always-on, resource-constrained multimodal perception in embodied settings, directly addressing the gap between trimmed-clip policy learning and continuous untrimmed operation.
major comments (2)
- [Benchmark formulation / energy-budget definition] Benchmark formulation / energy-budget definition: the manuscript repeatedly invokes 'hardware-representative energy budgets' as the central constraint that makes the task realistic, yet provides no derivation, table, or appendix that maps per-modality per-timestep costs to published datasheets, power traces, or mobile-SoC measurements (e.g., IMU vs. RGB on typical egocentric hardware). This omission is load-bearing for the claim that conclusions about random routing or policy learning reflect real embodied constraints.
- [Experimental results] Experimental results: the evaluations are described only qualitatively ('optimal routing is highly scenario-dependent', 'simple dynamic fusion proves critical'); no quantitative tables report mAP, energy consumption, or latency numbers under the stated budgets, nor do they compare against an oracle or static baseline with the same total energy envelope. Without these numbers the central empirical claim cannot be assessed.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction use 'untrimmed egocentric video' and 'continuous, untrimmed environments' interchangeably; a short clarification of the precise temporal granularity (frame rate, segment length) would help readers map the task to existing online TAS literature.
- [Data release paragraph] The list of released artifacts (splits, annotations, features, baselines) is mentioned but not accompanied by a table or repository link with checksums or version numbers; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on Ego-METAS. The two major comments highlight important areas for strengthening the manuscript's claims about hardware realism and empirical evaluation. We address each point below and commit to revisions that incorporate the requested details without altering the core contributions.
read point-by-point responses
-
Referee: [Benchmark formulation / energy-budget definition] Benchmark formulation / energy-budget definition: the manuscript repeatedly invokes 'hardware-representative energy budgets' as the central constraint that makes the task realistic, yet provides no derivation, table, or appendix that maps per-modality per-timestep costs to published datasheets, power traces, or mobile-SoC measurements (e.g., IMU vs. RGB on typical egocentric hardware). This omission is load-bearing for the claim that conclusions about random routing or policy learning reflect real embodied constraints.
Authors: We agree that explicit derivation of the energy budgets is necessary to substantiate the hardware-representative claim. In the revised manuscript we will add a dedicated appendix (and corresponding table in the main text) that maps per-modality per-timestep power costs to published datasheets and mobile-SoC measurements for representative egocentric devices. This will include the specific sources and assumptions used to set the fixed budgets. revision: yes
-
Referee: [Experimental results] Experimental results: the evaluations are described only qualitatively ('optimal routing is highly scenario-dependent', 'simple dynamic fusion proves critical'); no quantitative tables report mAP, energy consumption, or latency numbers under the stated budgets, nor do they compare against an oracle or static baseline with the same total energy envelope. Without these numbers the central empirical claim cannot be assessed.
Authors: We acknowledge that the current presentation relies on qualitative statements. The revised version will include new quantitative tables reporting mAP, energy consumption, and latency under the fixed budgets, together with direct comparisons against both an oracle policy and static baselines constrained to the same total energy envelope. These additions will allow readers to assess the empirical claims directly. revision: yes
Circularity Check
No circularity: benchmark definition with no derivation chain
full rationale
The manuscript defines a new benchmark (Ego-METAS), releases data splits and features, and formulates an online TAS task with fixed energy-budget constraints. No equations, parameter fits, uniqueness theorems, or predictions are presented that could reduce to their own inputs by construction. The phrase 'hardware-representative energy budgets' is used as a task constraint without any claimed derivation or self-referential fitting step. This matches the default case of a self-contained data-release paper whose central contribution does not rely on a closed-loop mathematical argument.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Structured pruning of deep convolutional neural networks.ACM Journal on Emerging Technologies in Computing Systems (JETC), 13(3):1–18, 2017
Sajid Anwar, Kyuyeon Hwang, and Wonyong Sung. Structured pruning of deep convolutional neural networks.ACM Journal on Emerging Technologies in Computing Systems (JETC), 13(3):1–18, 2017
2017
-
[2]
xlstm: Extended long short-term memory.Advances in Neural Information Processing Systems, 37:107547–107603, 2024
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xlstm: Extended long short-term memory.Advances in Neural Information Processing Systems, 37:107547–107603, 2024
2024
-
[3]
Retina: Low-power eye tracking with event camera and spiking hardware
Pietro Bonazzi, Sizhen Bian, Giovanni Lippolis, Yawei Li, Sadique Sheik, and Michele Magno. Retina: Low-power eye tracking with event camera and spiking hardware. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5684–5692, 2024
2024
-
[4]
Gatehub: Gated history unit with background suppression for online action detection
Junwen Chen, Gaurav Mittal, Ye Yu, Yu Kong, and Mei Chen. Gatehub: Gated history unit with background suppression for online action detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19925–19934, June 2022
2022
-
[5]
A survey of computer vision detection, visual slam algorithms, and their applications in energy-efficient autonomous systems.Energies, 17(20):5177, 2024
Lu Chen, Gun Li, Weisi Xie, Jie Tan, Yang Li, Junfeng Pu, Lizhu Chen, Decheng Gan, and Weimin Shi. A survey of computer vision detection, visual slam algorithms, and their applications in energy-efficient autonomous systems.Energies, 17(20):5177, 2024
2024
-
[6]
Egoadapt: Adaptive multisensory distillation and policy learning for efficient egocentric perception
Sanjoy Chowdhury, Subrata Biswas, Sayan Nag, Tushar Nagarajan, Calvin Murdock, Ishwarya Anan- thabhotla, Yijun Qian, Vamsi Krishna Ithapu, Dinesh Manocha, and Ruohan Gao. Egoadapt: Adaptive multisensory distillation and policy learning for efficient egocentric perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 107...
2025
-
[7]
A cmos ultra-low power vision sensor with image compression and embedded event-driven energy-management
Nicola Cottini, Leonardo Gasparini, Marco De Nicola, Nicola Massari, and Massimo Gottardi. A cmos ultra-low power vision sensor with image compression and embedded event-driven energy-management. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 1(3):299–307, 2011
2011
-
[8]
Training deep neural networks with low precision multiplications
Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. Training deep neural networks with low precision multiplications.arXiv preprint arXiv:1412.7024, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[9]
EM 2: Efficient multimodal sensing via adaptive sensor-computation activation.IEEE Transactions on Mobile Computing, 2025
Jinyi Cui and Tianyue Zheng. EM 2: Efficient multimodal sensing via adaptive sensor-computation activation.IEEE Transactions on Mobile Computing, 2025
2025
-
[10]
Primus: Pretraining imu encoders with multimodal self-supervision
Arnav M Das, Chi Ian Tang, Fahim Kawsar, and Mohammad Malekzadeh. Primus: Pretraining imu encoders with multimodal self-supervision. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[11]
Online action detection
Roeland De Geest, Efstratios Gavves, Amir Ghodrati, Zhenyang Li, Cees Snoek, and Tinne Tuytelaars. Online action detection. InEuropean Conference on Computer Vision, pages 269–284. Springer, 2016
2016
-
[12]
Guide to the carnegie mellon university multimodal activity (cmu-mmac) database
Fernando De la Torre, Jessica Hodgins, Adam Bargteil, Xavier Martin, Justin Macey, Alex Collado, and Pep Beltran. Guide to the carnegie mellon university multimodal activity (cmu-mmac) database. 2009
2009
-
[13]
Temporal Action Segmentation: An Analysis of Modern Techniques.IEEE Trans
Guodong Ding, Fadime Sener, and Angela Yao. Temporal Action Segmentation: An Analysis of Modern Techniques.IEEE Trans. Pattern Anal. Mach. Intell., 46(2):1011–1030, February 2024. ISSN 0162-8828. doi: 10.1109/TPAMI.2023.3327284. URLhttps://doi.org/10.1109/TPAMI.2023.3327284
-
[14]
Lightnn: Filling the gap between conventional deep neural networks and binarized networks
Ruizhou Ding, Zeye Liu, Rongye Shi, Diana Marculescu, and RD Blanton. Lightnn: Filling the gap between conventional deep neural networks and binarized networks. InProceedings of the Great Lakes Symposium on VLSI 2017, pages 35–40, 2017
2017
-
[15]
Ultra-low-power accelerometer STMicroelectronics MIS2DU12
Mouser Electronics. Ultra-low-power accelerometer STMicroelectronics MIS2DU12. https://www.mouser.es/new/semiconductors/sensor-ics/ stmicroelectronics-mis2du12-accelerometer/n-6gixyZ2kgkdg , 2024. Acess: 4th of May of 2026
2024
-
[16]
Ms-tcn: Multi-stage temporal convolutional network for action segmentation
Yazan Abu Farha and Jurgen Gall. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3575–3584, 2019. 10
2019
-
[17]
X3d: Expanding architectures for efficient video recognition
Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 203–213, 2020
2020
-
[18]
Frameexit: Conditional early exiting for efficient video recognition
Amir Ghodrati, Babak Ehteshami Bejnordi, and Amirhossein Habibian. Frameexit: Conditional early exiting for efficient video recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15608–15618, 2021
2021
-
[19]
A survey of methods for low-power deep learning and computer vision
Abhinav Goel, Caleb Tung, Yung-Hsiang Lu, and George K Thiruvathukal. A survey of methods for low-power deep learning and computer vision. In2020 IEEE 6th World Forum on Internet of Things (WF-IoT), pages 1–6. IEEE, 2020
2020
-
[20]
Ssast: Self-supervised audio spectrogram transformer
Yuan Gong, Cheng-I Lai, Yu-An Chung, and James Glass. Ssast: Self-supervised audio spectrogram transformer. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 10699– 10709, 2022
2022
-
[21]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
2024
-
[22]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
M-llm based video frame selection for efficient video understanding
Kai Hu, Feng Gao, Xiaohan Nie, Peng Zhou, Son Tran, Tal Neiman, Lingyun Wang, Mubarak Shah, Raffay Hamid, Bing Yin, et al. M-llm based video frame selection for efficient video understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 13702–13712, 2025
2025
-
[25]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size.arXiv preprint arXiv:1602.07360, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
Thop: Pytorch-opcounter, 2026
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. Thop: Pytorch-opcounter, 2026. URL https://github. com/ultralytics/thop
2026
-
[28]
Scsampler: Sampling salient clips from video for efficient action recognition
Bruno Korbar, Du Tran, and Lorenzo Torresani. Scsampler: Sampling salient clips from video for efficient action recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6232–6242, 2019
2019
-
[29]
Boosting multi-modal model performance with adaptive gradient modulation
Hong Li, Xingyu Li, Pengbo Hu, Yinuo Lei, Chunxiao Li, and Yi Zhou. Boosting multi-modal model performance with adaptive gradient modulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22214–22224, 2023
2023
-
[30]
Fact: Frame-action cross-attention temporal modeling for efficient action segmentation
Zijia Lu and Ehsan Elhamifar. Fact: Frame-action cross-attention temporal modeling for efficient action segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18175–18185, 2024
2024
-
[31]
Modselect: Automatic modality selection for synthetic-to-real domain generalization
Zdravko Marinov, Alina Roitberg, David Schneider, and Rainer Stiefelhagen. Modselect: Automatic modality selection for synthetic-to-real domain generalization. InEuropean Conference on Computer Vision, pages 326–346. Springer, 2022
2022
-
[32]
Battery life on ai glasses
Meta. Battery life on ai glasses. https://www.ray-ban.com/usa/l/ discover-ray-ban-meta-ai-glasses. Accessed: 2026-05-05
2026
-
[33]
Sensor-augmented egocentric-video captioning with dynamic modal attention
Katsuyuki Nakamura, Hiroki Ohashi, and Mitsuhiro Okada. Sensor-augmented egocentric-video captioning with dynamic modal attention. InProceedings of the 29th ACM International Conference on Multimedia, pages 4220–4229, 2021
2021
-
[34]
Adamml: Adaptive multi-modal learning for efficient video recognition
Rameswar Panda, Chun-Fu Richard Chen, Quanfu Fan, Ximeng Sun, Kate Saenko, Aude Oliva, and Rogerio Feris. Adamml: Adaptive multi-modal learning for efficient video recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 7576–7585, 2021. 11
2021
-
[35]
Captaincook4d: A dataset for understanding errors in procedural activities.Advances in Neural Information Processing Systems, 37: 135626–135679, 2024
Rohith Peddi, Shivvrat Arya, Bharath Challa, Likhitha Pallapothula, Akshay Vyas, Bhavya Gouripeddi, Qifan Zhang, Jikai Wang, Vasundhara Komaragiri, Eric Ragan, et al. Captaincook4d: A dataset for understanding errors in procedural activities.Advances in Neural Information Processing Systems, 37: 135626–135679, 2024
2024
-
[36]
An Outlook into the Future of Egocentric Vision
Chiara Plizzari, Gabriele Goletto, Antonino Furnari, Siddhant Bansal, Francesco Ragusa, Giovanni Maria Farinella, Dima Damen, and Tatiana Tommasi. An Outlook into the Future of Egocentric Vision. International Journal of Computer Vision, 132(11):4880–4936, November 2024. ISSN 0920-5691, 1573-1405. doi: 10.1007/s11263-024-02095-7. URL https://link.springer...
-
[37]
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. Egovlpv2: Egocentric video-language pre-training with fusion in the backbone. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5285–5297, 2023
2023
-
[38]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[39]
Multi-modal temporal action segmen- tation for manufacturing scenarios.Engineering Applications of Artificial Intelligence, 148:110320, May
Laura Romeo, Roberto Marani, Anna Gina Perri, and Juergen Gall. Multi-modal temporal action segmen- tation for manufacturing scenarios.Engineering Applications of Artificial Intelligence, 148:110320, May
-
[40]
doi: 10.1016/j.engappai.2025.110320
ISSN 09521976. doi: 10.1016/j.engappai.2025.110320. URL https://linkinghub.elsevier. com/retrieve/pii/S0952197625003203
-
[41]
Guerrero, and Simone Schaub-Meyer
Maria Santos-Villafranca, Dustin Carrión-Ojeda, Alejandro Perez-Yus, Jesus Bermudez-Cameo, Jose J. Guerrero, and Simone Schaub-Meyer. Multimodal knowledge distillation for egocentric action recognition robust to missing modalities. InProceedings of the IEEE International Conference on Robotics & Automation (ICRA), 2026
2026
-
[42]
Shen and E
Y . Shen and E. Elhamifar. Progress-aware online action segmentation for egocentric procedural task videos. IEEE Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[43]
Progress-aware online action segmentation for egocentric procedural task videos
Yuhan Shen and Ehsan Elhamifar. Progress-aware online action segmentation for egocentric procedural task videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18186–18197, 2024
2024
-
[44]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
C2f-tcn: A framework for semi-and fully-supervised temporal action segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10): 11484–11501, 2023
Dipika Singhania, Rahul Rahaman, and Angela Yao. C2f-tcn: A framework for semi-and fully-supervised temporal action segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10): 11484–11501, 2023
2023
-
[46]
Leaving some stones unturned: dynamic feature prioritization for activity detection in streaming video
Yu-Chuan Su and Kristen Grauman. Leaving some stones unturned: dynamic feature prioritization for activity detection in streaming video. InEuropean Conference on Computer Vision, pages 783–800. Springer, 2016
2016
-
[47]
Mnasnet: Platform-aware neural architecture search for mobile
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2820–2828, 2019
2019
-
[48]
Egodistill: Egocentric head motion distillation for efficient video understanding.Advances in Neural Information Processing Systems, 36:33485–33498, 2023
Shuhan Tan, Tushar Nagarajan, and Kristen Grauman. Egodistill: Egocentric head motion distillation for efficient video understanding.Advances in Neural Information Processing Systems, 36:33485–33498, 2023
2023
-
[49]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Training deep neural networks with 8-bit floating point numbers.Advances in neural information processing systems, 31, 2018
Naigang Wang, Jungwook Choi, Daniel Brand, Chia-Yu Chen, and Kailash Gopalakrishnan. Training deep neural networks with 8-bit floating point numbers.Advances in neural information processing systems, 31, 2018
2018
-
[51]
Computation-efficient deep learning for computer vision: A survey.Cybernetics and intelligence, 2024
Yulin Wang, Yizeng Han, Chaofei Wang, Shiji Song, Qi Tian, and Gao Huang. Computation-efficient deep learning for computer vision: A survey.Cybernetics and intelligence, 2024. 12
2024
-
[52]
Zejia Weng, Zuxuan Wu, Hengduo Li, Jingjing Chen, and Yu-Gang Jiang. HCMS: Hierarchical and Conditional Modality Selection for Efficient Video Recognition.ACM Transactions on Multimedia Computing, Communications, and Applications, 20(2):1–18, February 2024. ISSN 1551-6857, 1551-6865. doi: 10.1145/3572776. URLhttps://dl.acm.org/doi/10.1145/3572776
-
[53]
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning.arXiv preprint arXiv:2404.16994, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Dynamic multimodal fusion
Zihui Xue and Radu Marculescu. Dynamic multimodal fusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2575–2584, 2023
2023
-
[55]
Efficient deep visual and inertial odometry with adaptive visual modality selection
Mingyu Yang, Yu Chen, and Hun-Seok Kim. Efficient deep visual and inertial odometry with adaptive visual modality selection. InEuropean conference on computer vision, pages 233–250. Springer, 2022
2022
-
[56]
Nisp: Pruning networks using neuron importance score propagation
Ruichi Yu, Ang Li, Chun-Fu Chen, Jui-Hsin Lai, Vlad I Morariu, Xintong Han, Mingfei Gao, Ching- Yung Lin, and Larry S Davis. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 9194–9203, 2018
2018
-
[57]
Onlinetas: An online baseline for temporal action segmenta- tion.Advances in Neural Information Processing Systems, 37:58984–59005, 2024
Qing Zhong, Guodong Ding, and Angela Yao. Onlinetas: An online baseline for temporal action segmenta- tion.Advances in Neural Information Processing Systems, 37:58984–59005, 2024
2024
-
[58]
First Aid -CPR
Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8697–8710, 2018. 13 A Supplementary material A.1 Motivation for the new benchmark The proposed benchmark builds upon the initial Energy-effi...
2018
-
[59]
we selected only those videos that cointain video, audio and IMU information. Therefore, a considerable amount of videos were discarded, and neither of the official proposed splits were large enough for training and evaluating (see Tab. 42). For that reason, we do not train on a per-scenario basis, and instead the full dataset had to be trained jointly. T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.