Unified Context Evolution for LLM Agents
Pith reviewed 2026-06-28 14:45 UTC · model grok-4.3
The pith
UCE builds a typed external library of experience units so LLM agents retain strategies across episodes instead of resetting each time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
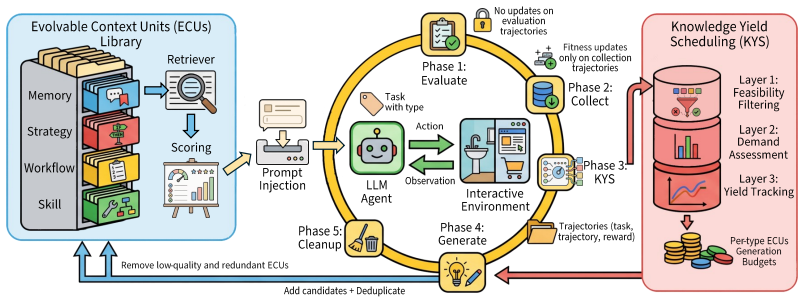
The paper claims that decomposing agent trajectories into four complementary experience types stored as Evolvable Context Units, then managing them through usage-based scoring, pruning of low-value items, and a scheduling module that allocates generation budget to the weakest categories, enables agents to accumulate and reuse knowledge across episodes and raises performance on multi-step interactive tasks.
What carries the argument
Evolvable Context Units (ECUs) of four types (Memory, Strategy, Workflow, Skill) together with usage scoring, pruning, and a scheduling module that targets generation to library gaps.
If this is right
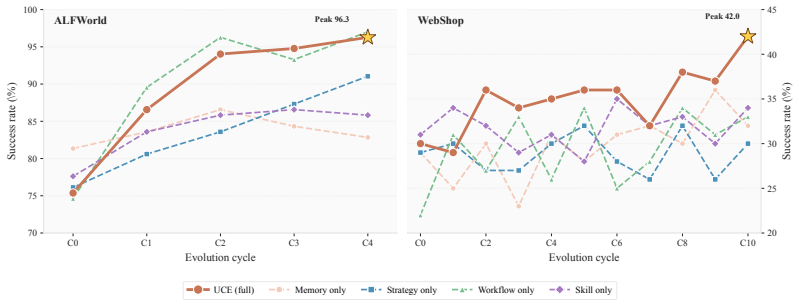
- ALFWorld success rises from 75.4% to 96.3%.
- WebShop task score rises from 45.1% to 61.3%.
- Libraries built under one actor transfer to other actor backbones without retraining.
- Generation effort is focused on the experience types the current library needs most rather than applied uniformly.
- Experience is kept separate by type instead of pooled in a single untyped store.
Where Pith is reading between the lines
- The same library could support continual improvement over sequences of hundreds of distinct tasks without any model parameter updates.
- Typed offloading of experience might become a standard way to manage context length limits in long-horizon agent planning.
- If the four-type distinction holds across domains, it could serve as a reusable template for organizing memory in other agent architectures.
Load-bearing premise
The four-type split together with usage-based scoring and pruning produces more helpful retrievals than noise or interference.
What would settle it
On ALFWorld or WebShop, enabling the full UCE library produces no improvement or a drop relative to the same actor without the library.
Figures


read the original abstract
LLM-based agents can solve multi-step interactive tasks by combining reasoning with environment feedback, yet each episode starts from the same fixed context and any useful strategy discovered along the way is lost once the task ends. Existing approaches either limit learning to the current task or pool all experience into a single untyped store, without distinguishing knowledge types, tracking quality through use, or balancing what the library still lacks. We introduce Unified Context Evolution (UCE), a gradient-free framework that externalizes agent experience into an evolving library of typed Evolvable Context Units (ECUs). UCE decomposes experience into four complementary types (Memory, Strategy, Workflow, and Skill), each generated from trajectories under type-specific conditions, retrieved at decision time, scored through repeated usage outcomes, and pruned when no longer valuable. A scheduling module allocates each cycle's generation budget toward the types where the library is weakest. Across two interactive benchmarks, UCE raises ALFWorld success from 75.4% to 96.3% and WebShop task score from 45.1% to 61.3%, and the accumulated library transfers to alternative actor backbones without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Unified Context Evolution (UCE), a gradient-free framework that externalizes LLM agent experience into an evolving library of typed Evolvable Context Units (ECUs) decomposed into four types (Memory, Strategy, Workflow, Skill). Each type is generated from trajectories under type-specific conditions, retrieved at decision time, scored via usage outcomes, pruned when unvaluable, and scheduled by allocating generation budget to library weaknesses. The central empirical claims are large gains on two interactive benchmarks (ALFWorld success from 75.4% to 96.3%; WebShop task score from 45.1% to 61.3%) plus transfer of the accumulated library to alternative actor backbones without retraining.
Significance. If the reported benchmark lifts are attributable to the typed decomposition, usage scoring, pruning, and scheduling rather than generic increases in context volume, the work would offer a practical, non-gradient method for cumulative cross-episode learning in LLM agents. The cross-model transfer result is a concrete strength that would support broader applicability if validated.
major comments (2)
- [§4] §4 (Experiments) and associated tables: the reported lifts on ALFWorld and WebShop are presented without ablations that hold total retrieved tokens or retrieval frequency fixed while ablating the four-type distinctions or the adaptive scheduler. This leaves open whether the gains derive from the specific ECU typing and usage-based rules or from simply maintaining a larger evolving context store.
- [§3.2–3.4] §3.2–3.4 (ECU generation, scoring, and scheduling): the claim that the four-type decomposition plus usage scoring and pruning produce net-positive retrievals is load-bearing for the framework but is supported only by end-to-end benchmark numbers; no controlled comparison isolates the contribution of type-specific generation conditions versus a single untyped store of equivalent size.
minor comments (1)
- [Abstract, §1] The abstract and §1 would benefit from a one-sentence statement of the total context budget or token limit used in the UCE runs versus baselines to allow immediate comparison of context volume.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the empirical claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the reported lifts on ALFWorld and WebShop are presented without ablations that hold total retrieved tokens or retrieval frequency fixed while ablating the four-type distinctions or the adaptive scheduler. This leaves open whether the gains derive from the specific ECU typing and usage-based rules or from simply maintaining a larger evolving context store.
Authors: We agree that the current presentation does not include ablations that explicitly control for total retrieved tokens or retrieval frequency. While our main results compare UCE against baselines that do not use an evolving typed library, additional controls would better isolate the contributions of the four-type structure and the scheduler. We will add these ablations in the revised version of the paper. revision: yes
-
Referee: [§3.2–3.4] §3.2–3.4 (ECU generation, scoring, and scheduling): the claim that the four-type decomposition plus usage scoring and pruning produce net-positive retrievals is load-bearing for the framework but is supported only by end-to-end benchmark numbers; no controlled comparison isolates the contribution of type-specific generation conditions versus a single untyped store of equivalent size.
Authors: The manuscript provides the design rationale for type-specific generation in sections 3.2-3.4, but we acknowledge that a direct head-to-head comparison with an untyped store of matched size is not present. Such a comparison would clarify the benefit of the decomposition. We will conduct and report this controlled experiment in the revision. revision: yes
Circularity Check
No circularity; empirical benchmark results are independent of internal definitions
full rationale
The paper introduces UCE as an engineering framework that decomposes experience into four ECU types, applies usage scoring and pruning, and reports measured success-rate lifts on fixed external benchmarks (ALFWorld, WebShop). No equations, fitted parameters, or self-citations are presented whose outputs are definitionally identical to their inputs; the performance numbers are external observations, not quantities forced by the method's own rules. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Experience can be cleanly partitioned into four non-overlapping types (Memory, Strategy, Workflow, Skill) that each improve retrieval when stored separately.
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[2]
AgentsCoDriver: Large Language Model Empowered Collaborative Driving with Lifelong Learning, 2024
Senkang Hu, Zhengru Fang, Zihan Fang, Yiqin Deng, Xianhao Chen, and Yuguang Fang. AgentsCoDriver: Large Language Model Empowered Collaborative Driving with Lifelong Learning, 2024. 10
2024
-
[3]
Senkang Hu, Zhengru Fang, Zihan Fang, Yiqin Deng, Xianhao Chen, Yuguang Fang, and Sam Tak Wu Kwong. AgentsCoMerge: Large Language Model Empowered Collaborative Decision Making for Ramp Merging.IEEE Transactions on Mobile Computing, 24(10):9791–9805, 2025. doi: 10.1109/TMC.2025.3564163
-
[4]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 6...
2023
-
[5]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 11809–11822. Curran Associates, Inc., 2023
2023
-
[6]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning, 2026
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning, 2026
2026
-
[7]
SLEA-RL: Step-Level Experience Augmented Reinforce- ment Learning for Multi-Turn Agentic Training, 2026
Prince Zizhuang Wang and Shuli Jiang. SLEA-RL: Step-Level Experience Augmented Reinforce- ment Learning for Multi-Turn Agentic Training, 2026
2026
-
[8]
Reflex- ion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflex- ion: Language Agents with Verbal Reinforcement Learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 8634–8652. Curran Associates, Inc., 2023
2023
-
[9]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-Refine: Iterative Refinement with Self-Feedback. In A. Oh, T. Naumann, A. Globerson, K. Saenko, ...
2023
-
[10]
Expel: LLM agents are experiential learners,
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM Agents Are Experiential Learners.journaltitle = Proceedings of the AAAI Conference on Artificial Intelligence,, 38(17):19632–19642, 2024. ISSN 2374-3468, 2159-5399. doi: 10.1609/aaai.v38i17.29936
-
[11]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An Open-Ended Embodied Agent with Large Language Models. journaltitle = Transactions on Machine Learning Research,, pages 1–41, 2024. ISSN 2835-8856
2024
-
[12]
Agent Workflow Memory, 2024
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent Workflow Memory, 2024
2024
-
[13]
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory, 2026
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, Feiyu Xiong, Yutao Qi, Bo Tang, and Muning Wen. MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory, 2026
2026
-
[14]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. In International Conference on Learning Representations, 2021
2021
-
[15]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 20744–20757. Curran Associates, Inc., 2022
2022
-
[16]
WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Jiadai Sun, Xinyue Yang, Yu Yang, Shuntian Yao, Wei Xu, Jie Tang, and Yuxiao Dong. WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, p...
2025
-
[17]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning, 2025
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning, 2025
2025
-
[18]
HiPER: Hierarchical Reinforcement Learning with Explicit Credit Assignment for Large Language Model Agents, 2026
Jiangweizhi Peng, Yuanxin Liu, Ruida Zhou, Charles Fleming, Zhaoran Wang, Alfredo Garcia, and Mingyi Hong. HiPER: Hierarchical Reinforcement Learning with Explicit Credit Assignment for Large Language Model Agents, 2026
2026
-
[19]
Senkang Hu, Yong Dai, Xudong Han, Zhengru Fang, Yuzhi Zhao, Sam Tak Wu Kwong, and Yuguang Fang. Self-Induced Outcome Potential: Turn-Level Credit Assignment for Agents without Verifiers.arXiv preprint arXiv:2605.04984, 2026
Pith/arXiv arXiv 2026
-
[20]
Senkang Hu, Yong Dai, Yuzhi Zhao, Yihang Tao, Yu Guo, Zhengru Fang, Sam Tak Wu Kwong, and Yuguang Fang. Optimizing Agentic Reasoning with Retrieval via Synthetic Semantic Information Gain Reward.arXiv preprint arXiv:2602.00845, 2026
arXiv 2026
-
[21]
Donglai Xu, Hongzheng Yang, Yuzhi Zhao, Pingping Zhang, Jinpeng Chen, Wenao Ma, Zhi- jian Hou, Mengyang Wu, Xiaolei Li, Senkang Hu, et al. From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training.arXiv preprint arXiv:2511.07738, 2025
arXiv 2025
-
[22]
Inference-Time Budget Control for LLM Search Agents.arXiv preprint arXiv:2605.05701, 2026
Zhengru Fang, Senkang Forest Hu, Zhonghao Chang, Yu Guo, Yihang Tao, Hongyao Liu, Mengzhe Ruan, Jun Huang, and Yuguang Fang. Inference-Time Budget Control for LLM Search Agents.arXiv preprint arXiv:2605.05701, 2026
Pith/arXiv arXiv 2026
-
[23]
Distribution-Aligned Decoding for Efficient LLM Task Adaptation
Senkang Hu, Xudong Han, Jinqi Jiang, Yihang Tao, Zihan Fang, Yong Dai, Sam Kwong, and Yuguang Fang. Distribution-Aligned Decoding for Efficient LLM Task Adaptation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[24]
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Re- flection
Jeonghye Kim, Sojeong Rhee, Minbeom Kim, Dohyung Kim, Sangmook Lee, Youngchul Sung, and Kyomin Jung. ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Re- flection. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 33421– 33453. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.emnlp-main.1697
-
[25]
MPO: Boosting LLM Agents with Meta Plan Optimization
Weimin Xiong, Yifan Song, Qingxiu Dong, Bingchan Zhao, Feifan Song, XWang, and Sujian Li. MPO: Boosting LLM Agents with Meta Plan Optimization. InFindings of the Association for Computational Linguistics: EMNLP, pages 3914–3935. Association for Computational Linguistics,
-
[26]
doi: 10.18653/v1/2025.findings-emnlp.210
-
[27]
Self-Generated in-Context Examples Improve LLM Agents for Sequential Decision-Making Tasks
Vishnu Sarukkai, Zhiqiang Xie, and Kayvon Fatahalian. Self-Generated in-Context Examples Improve LLM Agents for Sequential Decision-Making Tasks. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P . Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume 38, pages 64392–64425. Curran Associates, Inc., 2025
2025
-
[28]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, 2025
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, 2025
2025
-
[29]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, and Tomas Pfister. ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory. InThe Fourteenth International Conference on Learning Representat...
2026
-
[30]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[31]
Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su
Boyuan Zheng, Michael Y. Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. SkillWeaver: Web Agents Can Self-Improve by Discovering and Honing Skills, 2025
2025
-
[32]
Introducing GPT-4.1 in the API, April 2025.https://openai.com/index/gpt-4-1/
OpenAI. Introducing GPT-4.1 in the API, April 2025.https://openai.com/index/gpt-4-1/
2025
-
[33]
Introducing GPT-5.2, December 2025
OpenAI. Introducing GPT-5.2, December 2025. https://openai.com/index/ introducing-gpt-5-2/. 12
2025
-
[34]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings Using Siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3980–3990. Association for Computational Linguistics, 2019. doi: 10.18653/...
-
[35]
Reasoning Models Can Be Effective without Thinking, 2025
Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. Reasoning Models Can Be Effective without Thinking, 2025
2025
-
[36]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Chris Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyamagundlu, Timothy Lillicrap, and Oriana Riva. AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu,...
2025
-
[37]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 881–905. Association for Computatio...
-
[38]
Yao Fu, Dong-Ki Kim, Jaekyeom Kim, Sungryull Sohn, Lajanugen Logeswaran, Kyunghoon Bae, and Honglak Lee. AutoGuide: Automated Generation and Selection of Context-Aware Guidelines for Large Language Model Agents. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, ...
-
[39]
RAP: Retrieval-Augmented Planning with Contextual Memory for Multimodal LLM Agents, 2024
Tomoyuki Kagaya, Thong Jing Yuan, Yuxuan Lou, Jayashree Karlekar, Sugiri Pranata, Akira Kinose, Koki Oguri, Felix Wick, and Yang You. RAP: Retrieval-Augmented Planning with Contextual Memory for Multimodal LLM Agents, 2024
2024
-
[40]
AutoManual: Constructing Instruction Manuals by LLM Agents via Interactive Environmental Learning
Minghao Chen, Yihang Li, Yanting Yang, Shiyu Yu, Binbin Lin, and Xiaofei He. AutoManual: Constructing Instruction Manuals by LLM Agents via Interactive Environmental Learning. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 589–631. Curran As...
-
[41]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2609–2634. Association for Computational Linguistics,
-
[42]
Plan-and-solve prompting: Improving zero-shot Chain-of-Thought reasoning by Large Lan- guage Models
doi: 10.18653/v1/2023.acl-long.147. 13 A Benchmark Details A.1 ALFWorld ALFWorld [14] is a text-based household environment in which an agent receives natural- language observations and produces natural-language actions to complete domestic tasks such as cleaning, heating, cooling, and placement. Following the standard protocol used by ExpeL [10], we eval...
-
[43]
What the failed agent did wrong (with exact action)
-
[44]
What the successful agent did instead (with exact action)
-
[45]
Analyze the common failure patterns:
The general rule that explains the difference Prompt G.13: Strategy analysis mode — failure only You have ONLY failed trajectories. Analyze the common failure patterns:
-
[46]
Identify repeated mistakes across trajectories
-
[47]
Hypothesize the correct approach based on error feedback
-
[48]
Identify the shared NON-OBVIOUS choices and counter-intuitive actions that all successful agents performed:
Extract rules that would prevent these failures Prompt G.14: Strategy analysis mode — success only You have ONLY successful trajectories. Identify the shared NON-OBVIOUS choices and counter-intuitive actions that all successful agents performed:
-
[49]
What actions did successful agents take that a naive agent might skip or do differently?
-
[50]
Were there any steps where the environment behaved unexpectedly but all agents handled it correctly?
-
[51]
{ task_type}
Generalize into decision rules for this task type 28 Prompt G.15: Workflow generation prompt You are extracting a STANDARD TASK PROCEDURE from multiple successful "{ task_type}" task trajectories. == WHAT TO EXTRACT == Identify the COMMON step sequence shared across all successful trajectories and output it as a numbered procedure template. - Use generic ...
-
[52]
FAILS (DO NOT output): -
Verify price is within budget 6. Click ’Buy Now’ to complete purchase" FAILS (DO NOT output): - "1. Search ’deodorant’ 2. Click B078GWRC1J 3. Select ’bright citrus’ 4. Click ’Buy Now’" --- uses specific product IDs and options from one session - "1. Search 2. Buy the first result" --- too vague to be actionable 35 Prompt G.24: WebShop reshuffle test — Ski...
-
[53]
AVOID skill protocols that require an analysis pass before any action: -
if it still fails, abandon this listing and open a different search result." - "Stale-state escape: when the page becomes a generic [Search] control with no result list, click ’Search’ once to reload; if the result list does not return after one reload, issue a fresh search query rather than continuing to click." AVOID skill protocols that require an anal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.