Parameter-efficient Dual-encoder Architecture with Differentiable Choquet Integral Fusion for Underwater Acoustic Classification
Pith reviewed 2026-06-28 12:34 UTC · model grok-4.3
The pith
A dual-encoder architecture fused by differentiable Choquet integral improves underwater acoustic classification accuracy with fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
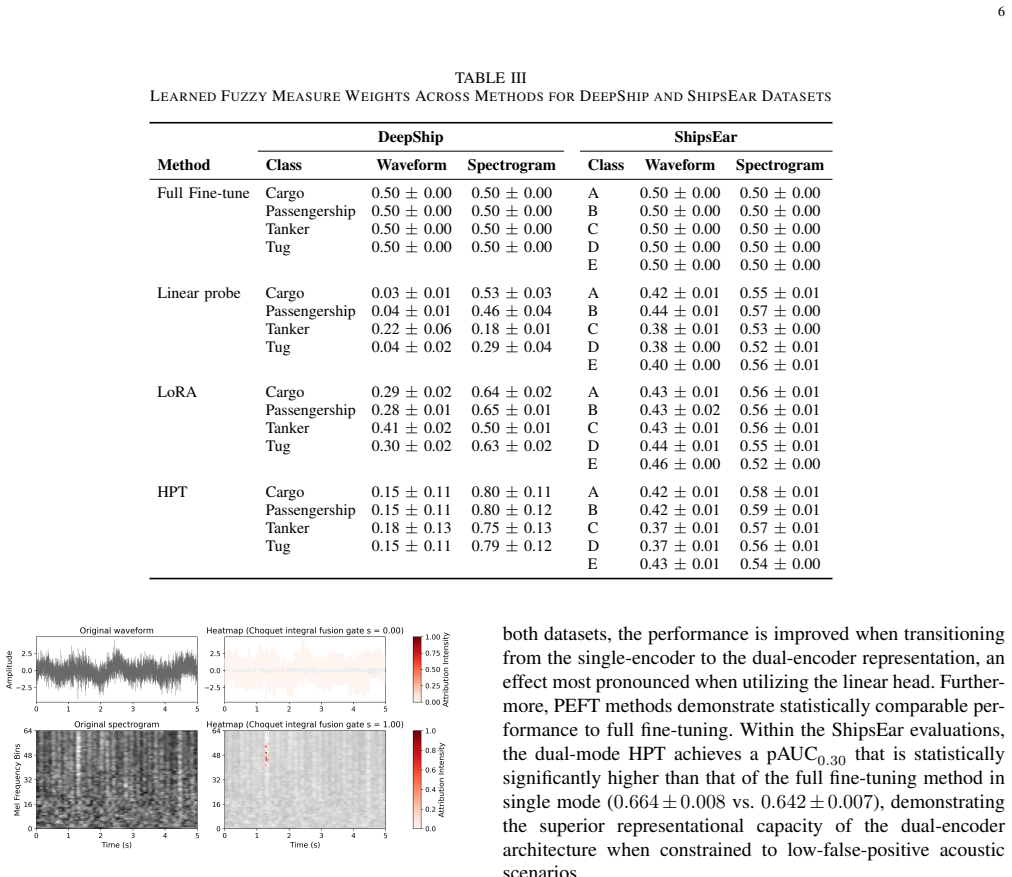
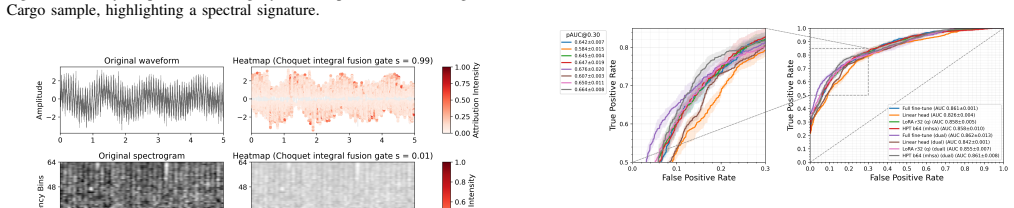
The paper claims that simultaneously processing waveform and spectrogram representations in a dual-encoder setup, adapted via parameter-efficient fine-tuning and fused with a differentiable Choquet integral, produces classification improvements over independent single-encoder baselines on underwater acoustic datasets while limiting the trainable parameter count and revealing class-specific representation reliance through the learned fuzzy measures.
What carries the argument
Differentiable Choquet integral fusion mechanism that aggregates outputs from two parameter-efficient fine-tuned encoders processing waveform and spectrogram inputs.
Load-bearing premise
That pre-trained models from other domains adapt effectively to underwater acoustics through the parameter-efficient modules and that the fuzzy measures learned by the Choquet integral reliably indicate class-specific representation preferences.
What would settle it
Running the single-encoder baselines and the proposed dual-encoder on the same datasets with identical pre-trained backbones and showing no accuracy improvement, or that the fuzzy measures do not change consistently with introduced channel distortions.
Figures



read the original abstract
Underwater acoustic classification has a wide array of oceanic applications, but faces challenges due to an increasingly complex acoustic environment. Waveform and spectrogram representations have been primarily used as acoustic data features for classification tasks in this domain. Spectrograms model harmonic dependencies, but these reduced representations can filter out acoustic features relevant for discrimination. While phase information from the waveform allows full characterization of the signal, the original waveform can be noisy and complex, rendering this representation difficult for models to process directly. This paper proposes a dual-encoder neural architecture to simultaneously process acoustic waveforms and spectrograms, leveraging pre-trained backbones and parameter-efficient fine-tuning modules, enabling a domain adaptation. To combine these adapted branches, a novel differentiable fuzzy aggregation mechanism based on the Choquet integral is introduced to balance the temporal and spectral representations. This fusion strategy not only yields higher classification accuracy but also provides interpretability. Specifically, by analyzing the learned fuzzy measures, insights are revealed about class-specific shifts in the network's representation reliance. By dynamically shifting attention to the representation least corrupted by potential asymmetric channel distortions, the proposed gating mechanism mitigates the non-stationary challenges of the underwater environment. Evaluations on the DeepShip and ShipsEar datasets demonstrate that the proposed architecture achieves classification improvements over independent single-encoder baselines, while simultaneously restricting the trainable parameter space. This mitigates the risk of overfitting on limited acoustic datasets while alleviating the computational costs associated with fully fine-tuning foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a dual-encoder architecture for underwater acoustic classification that processes raw waveforms and spectrograms in parallel using pre-trained backbones adapted via parameter-efficient fine-tuning modules. These branches are fused with a novel differentiable Choquet integral that learns class-specific fuzzy measures, yielding both higher accuracy than single-encoder baselines and interpretability about representation reliance. Experiments on DeepShip and ShipsEar are reported to show accuracy gains while restricting the number of trainable parameters.
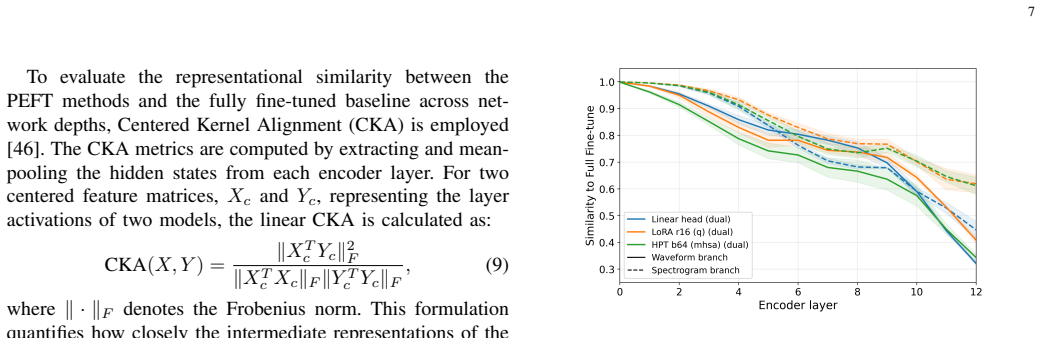
Significance. If the empirical claims hold after the requested controls, the work would demonstrate a practical route for domain adaptation of foundation models to data-scarce acoustic tasks and would supply an interpretable, non-linear fusion operator whose learned measures can be inspected per class. The parameter-efficiency aspect directly addresses overfitting risk on limited underwater datasets.
major comments (3)
- [§4] §4 (Experiments): No ablation is presented that replaces the pre-trained encoders with randomly initialized counterparts of identical architecture. Without this control, the reported gains over single-encoder baselines cannot be attributed to successful domain adaptation rather than simply to the added capacity or regularization of the dual-branch design.
- [§3.2 and §4.3] §3.2 (Choquet fusion) and §4.3 (Interpretability analysis): The claim that learned fuzzy measures reveal class-specific shifts in representation reliance is not externally validated against known acoustic channel effects (e.g., frequency-dependent absorption or multipath). The manuscript therefore provides no evidence that the per-class measure differences are trustworthy rather than artifacts of the optimization.
- [Table 2] Table 2 (main results): The comparison against single-encoder baselines does not include a domain-specific pre-training baseline or a fully fine-tuned (non-PEFT) dual-encoder control. Consequently it remains unclear whether the observed accuracy improvements and parameter savings are jointly attributable to the proposed fusion mechanism.
minor comments (2)
- [Abstract] Abstract: quantitative metrics, error bars, and the exact number of trainable parameters are omitted, making it impossible to assess the magnitude of the claimed improvements from the abstract alone.
- [§3.1] Notation in §3.1: the distinction between the two PEFT modules applied to waveform versus spectrogram branches is not made explicit in the equations, complicating reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the contributions and limitations of our work on the parameter-efficient dual-encoder architecture with differentiable Choquet integral fusion. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): No ablation is presented that replaces the pre-trained encoders with randomly initialized counterparts of identical architecture. Without this control, the reported gains over single-encoder baselines cannot be attributed to successful domain adaptation rather than simply to the added capacity or regularization of the dual-branch design.
Authors: We agree this control would strengthen attribution of gains specifically to domain adaptation. In the revised manuscript, we will add the requested ablation in §4, replacing pre-trained backbones with randomly initialized counterparts of identical architecture while retaining the dual-encoder structure and Choquet fusion. This will isolate the role of pre-training. revision: yes
-
Referee: [§3.2 and §4.3] §3.2 (Choquet fusion) and §4.3 (Interpretability analysis): The claim that learned fuzzy measures reveal class-specific shifts in representation reliance is not externally validated against known acoustic channel effects (e.g., frequency-dependent absorption or multipath). The manuscript therefore provides no evidence that the per-class measure differences are trustworthy rather than artifacts of the optimization.
Authors: The fuzzy measures offer model-internal interpretability of representation reliance per class, supported by accuracy gains and cross-dataset consistency. Direct external validation against specific acoustic phenomena would require new controlled experiments integrating physical channel models, which exceeds the current scope. We will revise §4.3 to explicitly note this as a limitation and direction for future work. revision: partial
-
Referee: [Table 2] Table 2 (main results): The comparison against single-encoder baselines does not include a domain-specific pre-training baseline or a fully fine-tuned (non-PEFT) dual-encoder control. Consequently it remains unclear whether the observed accuracy improvements and parameter savings are jointly attributable to the proposed fusion mechanism.
Authors: We will add a fully fine-tuned (non-PEFT) dual-encoder control to Table 2 to better demonstrate parameter-efficiency benefits of the PEFT approach. Domain-specific pre-training is not included as our focus is efficient adaptation of general pre-trained models; we will add a clarifying note on the absence of suitable large-scale unlabeled underwater datasets for such baselines. revision: partial
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The manuscript presents an empirical architecture combining dual encoders, PEFT modules, and a differentiable Choquet integral fusion layer. All performance claims rest on dataset evaluations rather than any derivation that reduces a result to its own fitted parameters or self-citations by construction. No equations are shown that define a quantity in terms of itself or rename a fitted input as a prediction; the fusion mechanism is introduced as an independent component whose interpretability is asserted from learned measures without tautological reduction to the single-encoder baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Testolin, D. Kipnis, and R. Diamant, “Detecting submerged objects using active acoustics and deep neural networks: A test case for pelagic fish,”IEEE Transactions on Mobile Computing, vol. 21, no. 8, pp. 2776– 2788, 2022, doi: 10.1109/TMC.2020.3044397
-
[2]
Multilabel classification of heterogeneous under- water soundscapes with bayesian deep learning,
B. Beckleret al., “Multilabel classification of heterogeneous under- water soundscapes with bayesian deep learning,”IEEE Journal of Oceanic Engineering, vol. 47, no. 4, pp. 1143–1154, 2022, doi: 10.1109/JOE.2022.3177850
-
[3]
R. J. Urick,Principles of Underwater Sound, 3rd ed. McGraw-Hill, 1983
1983
-
[4]
A survey of underwater acoustic target recognition methods based on machine learning,
X. Luo, L. Chen, H. Zhou, and H. Cao, “A survey of underwater acoustic target recognition methods based on machine learning,”Journal of Marine Science and Engineering, vol. 11, no. 2, p. 384, 2023, doi: 10.3390/jmse11020384
-
[5]
DEMON feature extraction of acoustic vector signal based on 3/2-d spectrum,
L. Sichun and Y . Desen, “DEMON feature extraction of acoustic vector signal based on 3/2-d spectrum,” in2007 2nd IEEE Conference on Industrial Electronics and Applications. IEEE, 2007, pp. 2239–2243, doi: 10.1109/ICIEA.2007.4318809
-
[6]
M. A. R. Hashmi and R. H. Raza, “Novel DEMON spectra analysis tech- niques and empirical knowledge based reference criterion for acoustic signal classification,”Journal of Electrical Engineering & Technology, vol. 18, no. 1, pp. 561–578, 2023, doi: 10.1007/s42835-022-01167-3
-
[7]
F. B. Jensen, W. A. Kuperman, M. B. Porter, and H. Schmidt,Compu- tational Ocean Acoustics, 2nd ed. New York, NY: Springer, 2011, doi: 10.1007/978-1-4419-8678-8
-
[8]
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”Nature, vol. 521, no. 7553, pp. 436–444, 2015, doi: 10.1038/nature14539
-
[9]
Machine learning in acoustics,
M. J. Bianco, P. Gerstoft, J. Traer, E. Ozanich, M. A. Roch, S. Gannot, and C.-A. Deledalle, “Machine learning in acoustics,”The Journal of the Acoustical Society of America, vol. 146, no. 5, pp. 3590–3631, 2019
2019
-
[10]
Deep learning in underwater acoustics: A review,
H. Niu, E. Reeves, and P. Gerstoft, “Deep learning in underwater acoustics: A review,”The Journal of the Acoustical Society of America, vol. 152, no. 1, pp. 751–793, 2022
2022
-
[11]
Y . Xie, J. Xu, J. Ren, and J. Li, “Adversarial multi-task underwater acoustic target recognition: towards robustness against various influential factors,”The Journal of the Acoustical Society of America, vol. 156, no. 1, pp. 299–312, 2024, doi: 10.1121/10.0026598
-
[12]
Deep learning for underwater acoustics: A review,
M. van Kootenet al., “Deep learning for underwater acoustics: A review,”The Journal of the Acoustical Society of America, vol. 150, no. 3, pp. 1600–1615, 2021, doi: 10.1121/10.0006240
-
[13]
Deep convolution stack for waveform in underwater acoustic target recognition,
Y . Songet al., “Deep convolution stack for waveform in underwater acoustic target recognition,”Scientific Reports, vol. 11, no. 1, p. 9614, 2021, doi: 10.1038/s41598-021-88799-z
-
[14]
Un- derwater radiated noise from modern commercial ships,
M. F. McKenna, D. Ross, S. M. Wiggins, and J. A. Hildebrand, “Un- derwater radiated noise from modern commercial ships,”The Journal of the Acoustical Society of America, vol. 131, no. 1, pp. 92–103, 2012, doi: 10.1121/1.3664100
-
[15]
Self-supervised learning for underwater acoustic signal classification with mixup,
Q. Xuet al., “Self-supervised learning for underwater acoustic signal classification with mixup,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 17, pp. 3458–3470, 2024, doi: 10.1109/JSTARS.2023.3325921
-
[16]
WaveNet: A generative model for raw audio,
A. van den Oordet al., “WaveNet: A generative model for raw audio,”arXiv preprint arXiv:1609.03499, 2016. [Online]. Available: https://arxiv.org/abs/1609.03499
Pith/arXiv arXiv 2016
-
[17]
Deep learning for audio signal processing,
H. Purwins, B. Li, T. Virtanen, J. Schl ¨uter, S.-Y . Chang, and T. Sainath, “Deep learning for audio signal processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 206–219, 2019, doi: 10.1109/JSTSP.2019.2908700
-
[18]
Underwater acoustic target recog- nition method based on feature fusion and residual cnn,
Y . Yang, Q. Yao, and Y . Wang, “Underwater acoustic target recog- nition method based on feature fusion and residual cnn,”IEEE Sensors Journal, vol. 24, no. 22, pp. 37 342–37 357, 2024, doi: 10.1109/JSEN.2024.3464754
-
[19]
Q. Zhu, Q. Xu, B. Zhu, Z. Gao, L. Zeng, and K. Xu, “SSAST-Adapter: A parameter-efficient incremental learning algorithm for underwater acoustic target recognition,” inProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5. [Online]. Available: https://ieeexplore.ieee.org/document/10887650/
arXiv 2025
-
[20]
LoRA: Low-rank adaptation of large language models,
E. J. Huet al., “LoRA: Low-rank adaptation of large language models,” inProc. International Conference on Learning Representations (ICLR), 2022. [Online]. Available: https://openreview.net/forum?id= nZeVKeeFYf9
2022
-
[21]
Histogram-based parameter-efficient tuning for passive and active sonar classification,
A. Mohammadi, D. Carreiro, A. Van Dine, and J. Peeples, “Histogram-based parameter-efficient tuning for passive and active sonar classification,”arXiv preprint arXiv:2504.15214, 2025. [Online]. Available: https://arxiv.org/abs/2504.15214
Pith/arXiv arXiv 2025
-
[22]
Segmentation pseudolabel generation using the multiple instance learning choquet integral,
C. H. McCurley and A. Zare, “Segmentation pseudolabel generation using the multiple instance learning choquet integral,”IEEE Trans- actions on Fuzzy Systems, vol. 32, no. 1, pp. 182–195, 2024, doi: 10.1109/TFUZZ.2023.3338049
-
[23]
The application of fuzzy integrals in multicriteria decision making,
M. Grabisch, “The application of fuzzy integrals in multicriteria decision making,”European Journal of Operational Research, vol. 89, no. 3, pp. 445–456, 1996, doi: 10.1016/0377-2217(95)00176-X
-
[24]
Y . Gong, Y .-A. Chung, and J. Glass, “AST: Audio spectro- gram transformer,” inProc. Interspeech, 2021, pp. 571–575, doi: 10.21437/Interspeech.2021-698
-
[25]
CNN architectures for large-scale audio clas- sification,
S. Hersheyet al., “CNN architectures for large-scale audio clas- sification,” inProc. IEEE ICASSP, 2017, pp. 131–135, doi: 10.1109/ICASSP.2017.7952132
-
[26]
An auditory-based time-dilated convolution neural network for ship-radiated noise,
G. Huet al., “An auditory-based time-dilated convolution neural network for ship-radiated noise,”The Journal of the Acoustical Society of Amer- ica, vol. 148, no. 3, pp. 1556–1566, 2020, doi: 10.1121/10.0001924
-
[27]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020. [Online]. Available: https://proceedings.neurips. cc/paper/2020/hash/92d1e1eb1cd6f9fba3227870bb6d7f07-Abstract.html
2020
-
[28]
ShipsEar: An underwater vessel noise database,
D. Santos-Dom ´ınguezet al., “ShipsEar: An underwater vessel noise database,”Applied Acoustics, vol. 113, pp. 64–69, 2016, doi: 10.1016/j.apacoust.2016.06.008
-
[29]
DeepShip: An underwater acoustic benchmark dataset,
M. Irfanet al., “DeepShip: An underwater acoustic benchmark dataset,” Expert Systems with Applications, vol. 183, p. 115270, 2021, doi: 10.1016/j.eswa.2021.115270
-
[30]
Underwater acoustic target recognition based on a joint neural network,
X. Hanet al., “Underwater acoustic target recognition based on a joint neural network,”PLoS One, vol. 17, no. 2, p. e0264445, 2022, doi: 10.1371/journal.pone.0264445
-
[31]
Robust underwater target recognition with uncertainty- aware fusion,
Y . Sunet al., “Robust underwater target recognition with uncertainty- aware fusion,”Information Fusion, vol. 98, p. 101846, 2023, doi: 10.1016/j.inffus.2023.101846
-
[32]
Attentional multidomain fea- ture fusion for underwater acoustic signal classification,
Y . Miao, Y . Li, and Y . Zakharov, “Attentional multidomain fea- ture fusion for underwater acoustic signal classification,”IEEE Jour- nal of Oceanic Engineering, vol. 51, no. 1, pp. 11–22, 2025, doi: 10.1109/JOE.2025.3619304
-
[33]
Y . Duan, X. Shen, H. Wang, and Y . Yan, “Multilabel recognition method for ship-radiated noise signals based on multidomain information fusion with deep equilibrium models,”IEEE Journal of Oceanic Engineering, 2025, doi: 10.1109/JOE.2025.3545239
-
[34]
Multiple instance choquet integral classifier fusion and regression for remote sensing applications,
X. Du and A. Zare, “Multiple instance choquet integral classifier fusion and regression for remote sensing applications,”IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 5, pp. 2741–2753, 2018, doi: 10.1109/tgrs.2018.2876687
-
[35]
Fuzzy integral in multicriteria decision making,
M. Grabisch, “Fuzzy integral in multicriteria decision making,”Fuzzy Sets and Systems, vol. 69, no. 3, pp. 279–298, 1995, doi: 10.1016/0165- 0114(94)00174-R
-
[36]
Audio Set: An ontology and human-labeled dataset for audio events
J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human- labeled dataset for audio events,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 776–780, doi: 10.1109/ICASSP.2017.7952261
-
[37]
ImageNet: A Large-Scale Hierarchical Image Database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255, doi: 10.1109/CVPR.2009.5206848
-
[38]
The Uniqueness Problem of Physical Law Learning
M. Hagiwara, “Aves: Animal vocalization encoder based on self- supervision,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5, doi: 10.1109/ICASSP49357.2023.10095166
-
[39]
FSD50K: an open dataset of human-labeled sound events,
E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra, “FSD50K: an open dataset of human-labeled sound events,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 829–852, 2021, doi: 10.1109/TASLP.2021.3133208
-
[40]
Specaugment on large scale datasets
H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “VGGSound: A large- scale audio-visual dataset,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 721–725, doi: 10.1109/ICASSP40776.2020.9053169
-
[41]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778, doi: 10.1109/CVPR.2016.90
-
[42]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “Convnext v2: Co-designing and scaling convnets with masked autoen- coders,” inProceedings of the IEEE/CVF Conference on Computer 9 Vision and Pattern Recognition (CVPR), 2023, pp. 16 133–16 142, doi: 10.1109/CVPR52729.2023.01548
-
[43]
PANNs: Large-scale pretrained audio neural networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumbley, “PANNs: Large-scale pretrained audio neural networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020, doi: 10.1109/TASLP.2020.3030497
-
[44]
SSAST: Self- supervised audio spectrogram transformer,
Y . Gong, C.-I. J. Lai, Y .-A. Chung, and J. Glass, “SSAST: Self- supervised audio spectrogram transformer,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 10, 2022, pp. 10 699– 10 709, doi: 10.1609/aaai.v36i10.21315
-
[45]
Towards better understanding of gradient-based attribution methods for deep neural networks,
M. Ancona, E. Ceolini, C. ¨Oztireli, and M. Gross, “Towards better understanding of gradient-based attribution methods for deep neural networks,” inInternational Conference on Learning Representations (ICLR), 2018. [Online]. Available: https://openreview.net/forum?id= Sy21R9JAW
2018
-
[46]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of neural network representations revisited,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 3519–3529. [Online]. Available: http://proceedings.mlr.press/v97/kornblith19a/kornblith19a.pdf Amirmohammad Mohammadireceived his M.Sc. in Electrical Engineering from Sharif University o...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.