TROPHIES: Temporal Reconstruction of Places, Humans, and Cameras from Multi-view Videos
Pith reviewed 2026-06-28 15:01 UTC · model grok-4.3
The pith
A unified framework jointly reconstructs dynamic humans, static scenes, and camera poses from multi-view videos in one global frame.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TROPHIES achieves globally aligned, physically plausible 4D reconstructions by jointly estimating dynamic humans, static scenes, and camera poses in one global coordinate frame from multi-view videos, outperforming existing paradigms in global fidelity and human-scene consistency.
What carries the argument
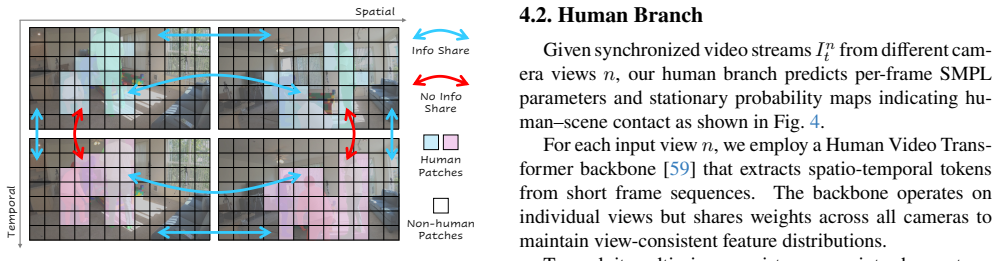
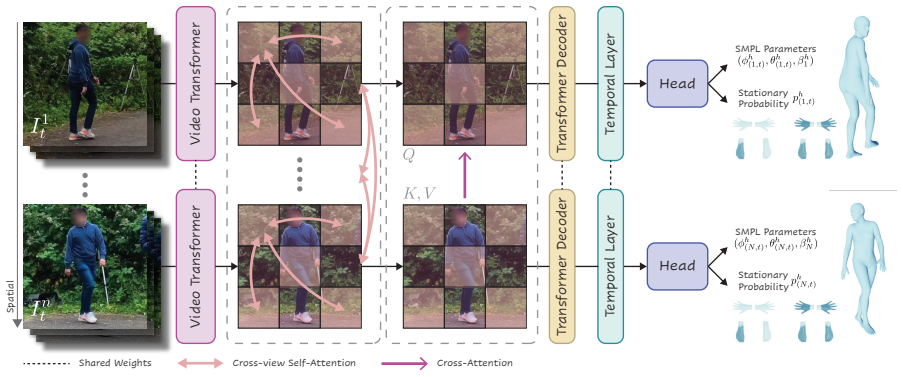
TROPHIES framework with Human Branch for temporal and spatial human modeling, Scene Branch for static geometry with human-aware attention, and global alignment module enforcing scale consistency, contact priors, and cross-view temporal coherence.
If this is right
- Joint estimation produces coherent geometry and stable motion across humans and scenes.
- Enforces physically aligned trajectories for dynamic elements in a shared coordinate frame.
- Yields higher global fidelity and human-scene consistency than decoupled methods on EgoHuman and EgoExo4D.
- Establishes a new unified task that couples human, scene, and camera reconstruction.
Where Pith is reading between the lines
- This joint approach could support more reliable motion prediction in extended video sequences by maintaining cross-view temporal coherence.
- Applications in robotics might benefit from the enforced contact priors to improve interaction planning with environments.
- Testing on videos with varying numbers of views could reveal the minimum overlap needed for stable alignment.
Load-bearing premise
Multi-view videos supply enough overlapping information and constraints to allow joint estimation of dynamic humans, static scenes, and camera poses in one global frame without the inconsistencies that arise when these elements are decoupled.
What would settle it
If the output 4D models exhibit scale inconsistencies or non-physical human-scene contacts when tested against ground-truth measurements from held-out multi-view video sequences.
Figures



read the original abstract
Reconstructing humans and their surrounding environments in a globally consistent 4D space is essential for comprehensive perception. However, prior works typically assume single-view inputs or decouple humans, scenes, and cameras, making them unable to recover coherent geometry, stable motion, and physically aligned trajectories. These limitations motivate us to introduce a new task: unified human-scene-camera reconstruction from multi-view videos, which aims to jointly estimate dynamic humans, static scenes, and camera poses in one global coordinate frame. We propose TROPHIES--Temporal Reconstruction of Places, Humans, and Cameras from Multi-view Videos-a unified framework tailored for this task. TROPHIES features a Human Branch that models humans through temporal and spatial reasoning, and a Scene Branch that reconstructs static geometry with human-aware attention. A global alignment and optimization module couples both branches by enforcing scale consistency, contact priors, and cross-view temporal coherence. Experiments on EgoHuman and EgoExo4D demonstrate that TROPHIES achieves globally aligned, physically plausible 4D reconstructions and consistently outperforms existing paradigms in both global fidelity and human-scene consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a new task of unified human-scene-camera reconstruction from multi-view videos. It proposes the TROPHIES framework consisting of a Human Branch for temporal and spatial reasoning on dynamic humans, a Scene Branch for static geometry reconstruction using human-aware attention, and a global alignment and optimization module that couples the branches via scale consistency, contact priors, and cross-view temporal coherence. Experiments on EgoHuman and EgoExo4D are reported to yield globally aligned, physically plausible 4D reconstructions that outperform prior decoupled approaches in global fidelity and human-scene consistency.
Significance. If the quantitative claims hold under full scrutiny, the work is significant for addressing inconsistencies that arise from separately estimating humans, scenes, and cameras. The explicit coupling mechanisms target a recognized limitation in the field and could enable more coherent 4D models for downstream applications. The framework's design choices around contact priors and temporal coherence represent a direct response to the weakest assumption noted in the stress test.
minor comments (3)
- The abstract states that TROPHIES 'consistently outperforms existing paradigms' but does not name the specific baselines or report numerical deltas; the experiments section should include a clear comparison table with metrics and error bars.
- Implementation details for the human-aware attention mechanism and the optimization module (e.g., loss weights, convergence criteria) are referenced at a high level; adding pseudocode or a dedicated subsection would improve reproducibility.
- The manuscript should explicitly discuss failure cases or limitations when multi-view overlap is limited, to address the weakest assumption about sufficient overlapping information.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of TROPHIES, the recognition of its significance in addressing inconsistencies in decoupled human-scene-camera estimation, and the recommendation for minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity identified
full rationale
The paper introduces a new task of unified human-scene-camera reconstruction and describes TROPHIES as a framework with separate Human and Scene Branches plus a global alignment module that enforces scale consistency, contact priors, and temporal coherence. All performance claims are presented as empirical results on the external datasets EgoHuman and EgoExo4D rather than as quantities derived by construction from fitted parameters or prior self-citations. No equations, ansatzes, or uniqueness theorems are shown that reduce the central outputs to the inputs by definition, and the construction is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visual imi- tation enables contextual humanoid control
Arthur Allshire, Hongsuk Choi, Junyi Zhang, David McAllis- ter, Anthony Zhang, Chung Min Kim, Trevor Darrell, Pieter Abbeel, Jitendra Malik, and Angjoo Kanazawa. Visual imi- tation enables contextual humanoid control. InCoRL, 2025. 2
2025
-
[2]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M¨ uller. Zoedepth: Zero-shot trans- fer by combining relative and metric depth.arXiv preprint arXiv:2302.12288, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Behave: Dataset and method for tracking human object in- teractions
Bharat Lal Bhatnagar, Xianghui Xie, Ilya Petrov, Cristian Sminchisescu, Christian Theobalt, and Gerard Pons-Moll. Behave: Dataset and method for tracking human object in- teractions. InCVPR, 2022. 3
2022
-
[4]
Bedlam: A synthetic dataset of bodies exhibiting detailed lifelike animated motion
Michael J Black, Priyanka Patel, Joachim Tesch, and Jinlong Yang. Bedlam: A synthetic dataset of bodies exhibiting detailed lifelike animated motion. InCVPR, 2023. 7
2023
-
[5]
Easi3r: Estimating disentangled motion from dust3r without training.arXiv preprint arXiv:2503.24391,
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3r: Estimating disentangled motion from dust3r without training.arXiv preprint arXiv:2503.24391,
-
[6]
Human3r: Everyone everywhere all at once.arXiv preprint arXiv:2510.06219, 2025
Yue Chen, Xingyu Chen, Yuxuan Xue, Anpei Chen, Yuliang Xiu, and Pons-Moll Gerard. Human3r: Everyone everywhere all at once.arXiv preprint arXiv:2510.06219, 2025. 2
-
[7]
Beyond static features for temporally consistent 3d human pose and shape from a video
Hongsuk Choi, Gyeongsik Moon, Ju Yong Chang, and Ky- oung Mu Lee. Beyond static features for temporally consistent 3d human pose and shape from a video. InCVPR, 2021. 2
2021
-
[8]
Hsc4d: Human-centered 4d scene capture in large-scale indoor-outdoor space using wearable imus and lidar
Yudi Dai, Yitai Lin, Chenglu Wen, Siqi Shen, Lan Xu, Jingyi Yu, Yuexin Ma, and Cheng Wang. Hsc4d: Human-centered 4d scene capture in large-scale indoor-outdoor space using wearable imus and lidar. InCVPR, 2022. 3
2022
-
[9]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 1981
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 1981. 5, 6
1981
-
[10]
Humans in 4D: Reconstructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4D: Reconstructing and tracking humans with transformers. In ICCV, 2023. 2, 8
2023
-
[11]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InCVPR, 2024. 6, 7
2024
-
[12]
Human poseitioning system (hps): 3d human pose estimation and self-localization in large scenes from body-mounted sensors
Vladimir Guzov, Aymen Mir, Torsten Sattler, and Gerard Pons-Moll. Human poseitioning system (hps): 3d human pose estimation and self-localization in large scenes from body-mounted sensors. InCVPR, 2021. 3
2021
-
[13]
Real-time deep dynamic charac- ters
Marc Habermann and et al. Real-time deep dynamic charac- ters. InSIGGRAPH, 2021. 1
2021
-
[14]
Populating 3d scenes by learn- ing human-scene interaction
Mohamed Hassan, Partha Ghosh, Joachim Tesch, Dimitrios Tzionas, and Michael J Black. Populating 3d scenes by learn- ing human-scene interaction. InCVPR, 2021. 3
2021
-
[15]
Populating 3d scenes by learn- ing human-scene interaction
Mohamed Hassan, Partha Ghosh, Joachim Tesch, Dimitrios Tzionas, and Michael J Black. Populating 3d scenes by learn- ing human-scene interaction. InCVPR, 2021. 1, 3
2021
-
[16]
Deep learning for character motion synthesis
Daniel Holden and et al. Deep learning for character motion synthesis. InSIGGRAPH, 2016. 1
2016
-
[17]
Reconstructing groups of people with hypergraph relational reasoning
Buzhen Huang, Jingyi Ju, Zhihao Li, and Yangang Wang. Reconstructing groups of people with hypergraph relational reasoning. InICCV, 2023. 1
2023
-
[18]
Huang, Hongwei Yi, Markus H ¨oschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J
Chun-Hao P. Huang, Hongwei Yi, Markus H ¨oschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J. Black. Capturing and inferring dense full-body human-scene contact. InCVPR, 2022. 2
2022
-
[19]
Black, and Dim- itrios Tzionas
Yinghao Huang, Omid Taheri, Michael J. Black, and Dim- itrios Tzionas. InterCap: Joint markerless 3D tracking of humans and objects in interaction. InGCPR, 2022. 3
2022
-
[20]
Black, and Dim- itrios Tzionas
Yinghao Huang, Omid Taheri, Michael J. Black, and Dim- itrios Tzionas. InterCap: Joint markerless 3D tracking of humans and objects in interaction from multi-view RGB-D images.IJCV, 2024. 3
2024
-
[21]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3. 6m: Large scale datasets and predic- tive methods for 3d human sensing in natural environments. PAMI, 2013. 7
2013
-
[22]
Kaiyang Ji, Ye Shi, Zichen Jin, Kangyi Chen, Lan Xu, Yuexin Ma, Jingyi Yu, and Jingya Wang. Towards immersive human- x interaction: A real-time framework for physically plausible motion synthesis.arXiv preprint arXiv:2508.02106, 2025. 1
-
[23]
H4d: Human 4d modeling by learning neural compositional representation
Boyan Jiang, Yinda Zhang, Xingkui Wei, Xiangyang Xue, and Yanwei Fu. H4d: Human 4d modeling by learning neural compositional representation. InCVPR, 2022. 3
2022
-
[24]
Scaling up dynamic human-scene interaction mod- eling
Nan Jiang, Zhiyuan Zhang, Hongjie Li, Xiaoxuan Ma, Zan Wang, Yixin Chen, Tengyu Liu, Yixin Zhu, and Siyuan Huang. Scaling up dynamic human-scene interaction mod- eling. InCVPR, 2024. 1
2024
-
[25]
Black, David W
Angjoo Kanazawa, Michael J. Black, David W. Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InCVPR, 2018. 2, 8
2018
-
[26]
Ego-humans: An ego- centric 3d multi-human benchmark
Rawal Khirodkar, Aayush Bansal, Lingni Ma, Richard New- combe, Minh Vo, and Kris Kitani. Ego-humans: An ego- centric 3d multi-human benchmark. InICCV, 2023. 6, 7
2023
-
[27]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll´ar, and Ross Girshick. Segment anything.arXiv:2304.02643, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Muhammed Kocabas, Nikos Athanasiou, and Michael J. Black. Vibe: Video inference for human body pose and shape estimation. InCVPR, 2020. 2
2020
-
[29]
Huang, Otmar Hilliges, and Michael J
Muhammed Kocabas, Chun-Hao P. Huang, Otmar Hilliges, and Michael J. Black. PARE: Part attention regressor for 3D human body estimation. InICCV, 2021. 2
2021
-
[30]
Huang, Joachim Tesch, Lea M¨ uller, Otmar Hilliges, and Michael J
Muhammed Kocabas, Chun-Hao P. Huang, Joachim Tesch, Lea M¨ uller, Otmar Hilliges, and Michael J. Black. SPEC: 9 Seeing people in the wild with an estimated camera. In ICCV, 2021. 6
2021
-
[31]
Learning to reconstruct 3d human pose and shape via model-fitting in the loop
Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop. InICCV, 2019. 2
2019
-
[32]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InECCV, 2024. 1, 2
2024
-
[33]
Joint Optimization for 4D Human-Scene Reconstruction in the Wild
Zhizheng Liu, Joe Lin, Wayne Wu, and Bolei Zhou. Joint optimization for 4d human-scene reconstruction in the wild. arXiv preprint arXiv:2501.02158, 2025. 2, 3
work page internal anchor Pith review arXiv 2025
-
[34]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi- person linear model.SIGGRAPH Asia, 2015. 2, 3
2015
-
[35]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold
Dominic Maggio, Hyungtae Lim, and Luca Carlone. Vggt- slam: Dense rgb slam optimized on the sl (4) manifold.arXiv preprint arXiv:2505.12549, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis. InECCV, 2020. 2
2020
-
[38]
Reconstructing people, places, and cameras.arXiv:2412.17806, 2024
Lea M¨ uller, Hongsuk Choi, Anthony Zhang, Brent Yi, Jiten- dra Malik, and Angjoo Kanazawa. Reconstructing people, places, and cameras.arXiv:2412.17806, 2024. 2, 3, 5, 7
-
[39]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3d hands, face, and body from a single image. InCVPR, 2019. 2, 3
2019
-
[40]
Black, and G¨ ul Varol
Mathis Petrovich, Michael J. Black, and G¨ ul Varol. TMR: Text-to-motion retrieval using contrastive 3D human motion synthesis. InICCV, 2023. 2
2023
-
[41]
Sam 2: Segment anything in images and videos, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll ´ar, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos, 2024. 7
2024
-
[42]
Slahmr: Scale-aware human motion recovery from monocular videos
Davis Rempe and et al. Slahmr: Scale-aware human motion recovery from monocular videos. InCVPR, 2023. 2, 4
2023
-
[43]
Grounding dino 1.5: Advance the ”edge” of open-set object detection, 2024
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wen- long Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, Yuda Xiong, Hao Zhang, Feng Li, Peijun Tang, Kent Yu, and Lei Zhang. Grounding dino 1.5: Advance the ”edge” of open-set object detection, 2024. 7
2024
-
[44]
Grounded sam: Assembling open-world models for diverse visual tasks,
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks,
-
[45]
Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied hands: Modeling and capturing hands and bodies together.SIGGRAPH Asia, 2017. 2
2017
-
[46]
Schonberger and Jan-Michael Frahm
Johannes L. Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InCVPR, 2016. 2
2016
-
[47]
A multi-view stereo benchmark with high- resolution images and multi-camera videos
Thomas Schops, Johannes L Schonberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and An- dreas Geiger. A multi-view stereo benchmark with high- resolution images and multi-camera videos. InCVPR, 2017. 2
2017
-
[48]
World-grounded human motion recovery via gravity-view co- ordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view co- ordinates. InSIGGRAPH Asia, 2024. 2, 4, 8
2024
-
[49]
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J. Black. WHAM: Reconstructing world-grounded humans with accu- rate 3D motion. InCVPR, 2024. 2, 4, 6
2024
-
[50]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InECCV,
-
[51]
Flag3d: A 3d fitness activity dataset with language instruction
Yansong Tang, Jinpeng Liu, Aoyang Liu, Bin Yang, Wenxun Dai, Yongming Rao, Jiwen Lu, Jie Zhou, and Xiu Li. Flag3d: A 3d fitness activity dataset with language instruction. In CVPR, 2023. 1
2023
-
[52]
Flag3d++: A benchmark for 3d fitness activity comprehension with lan- guage instruction.PAMI, 2025
Yansong Tang, Aoyang Liu, Jinpeng Liu, Shiyi Zhang, Wenxun Dai, Jie Zhou, Xiu Li, and Jiwen Lu. Flag3d++: A benchmark for 3d fitness activity comprehension with lan- guage instruction.PAMI, 2025. 1
2025
-
[53]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.NIPS, 2021
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.NIPS, 2021. 2, 5
2021
-
[54]
Recovering ac- curate 3d human pose in the wild using imus and a moving camera
Timo Von Marcard, Roberto Henschel, Michael J Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering ac- curate 3d human pose in the wild using imus and a moving camera. InECCV, 2018. 7
2018
-
[55]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025. 1
2025
-
[56]
Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. InNIPS, 2021. 2
2021
-
[57]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InCVPR, 2025. 2, 3, 4, 5, 7, 8
2025
-
[58]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InCVPR, 2024. 1, 2, 3, 4, 5, 7, 8
2024
-
[59]
Tram: Global trajectory and motion of 3d humans from in- the-wild videos
Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis. Tram: Global trajectory and motion of 3d humans from in- the-wild videos. InECCV, 2024. 2, 4, 6, 7, 8
2024
-
[60]
Uni- fied human-scene interaction via prompted chain-of-contacts
Zeqi Xiao, Tai Wang, Jingbo Wang, Jinkun Cao, Wenwei Zhang, Bo Dai, Dahua Lin, and Jiangmiao Pang. Uni- fied human-scene interaction via prompted chain-of-contacts. arXiv preprint arXiv:2309.07918, 2023. 1
-
[61]
ViT- Pose: Simple vision transformer baselines for human pose estimation
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. ViT- Pose: Simple vision transformer baselines for human pose estimation. InAdvances in Neural Information Processing Systems, 2022. 6
2022
-
[62]
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vit- pose+: Vision transformer foundation model for generic body pose estimation.arXiv preprint arXiv:2212.04246, 2022. 6 10
-
[63]
Staf: 3d human mesh recovery from video with spatio- temporal alignment fusion.TCSVT, 2024
Wei Yao, Hongwen Zhang, Yunlian Sun, and Jinhui Tang. Staf: 3d human mesh recovery from video with spatio- temporal alignment fusion.TCSVT, 2024. 1, 4
2024
-
[64]
Human-aware object placement for visual environment reconstruction
Hongwei Yi, Chun-Hao P Huang, Dimitrios Tzionas, Muhammed Kocabas, Mohamed Hassan, Siyu Tang, Justus Thies, and Michael J Black. Human-aware object placement for visual environment reconstruction. InCVPR, 2022. 1
2022
-
[65]
Monst3r: A simple approach for estimating geometry in the presence of motion.ICLR, 2025
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jam- pani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming- Hsuan Yang. Monst3r: A simple approach for estimating geometry in the presence of motion.ICLR, 2025. 1, 2, 3, 4, 5, 7, 8
2025
-
[66]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Lu Jingwan, Yang Jimei, and Li Hao. On the continuity of rotation representations in neural networks. InCVPR, 2019. 5 11
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.