Honey, I Shrunk the Arc de Triomphe!
Pith reviewed 2026-06-28 14:50 UTC · model grok-4.3
The pith
A dataset from internet photos and stereo pairs with geo-scale fixes scale-collapse when fine-tuning monocular depth models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
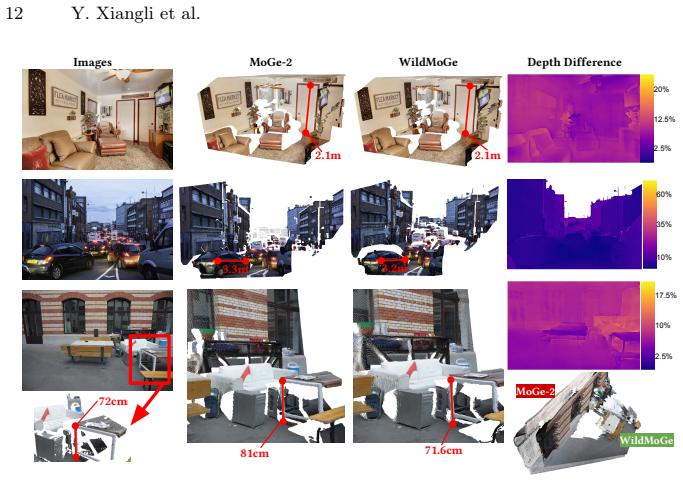
MetricScenes supplies metrically grounded training examples drawn from unconstrained real-world sources; fine-tuning MoGe-2 on this data significantly reduces scale-collapse for distant landmarks and vast landscapes while retaining state-of-the-art accuracy on standard benchmarks.
What carries the argument
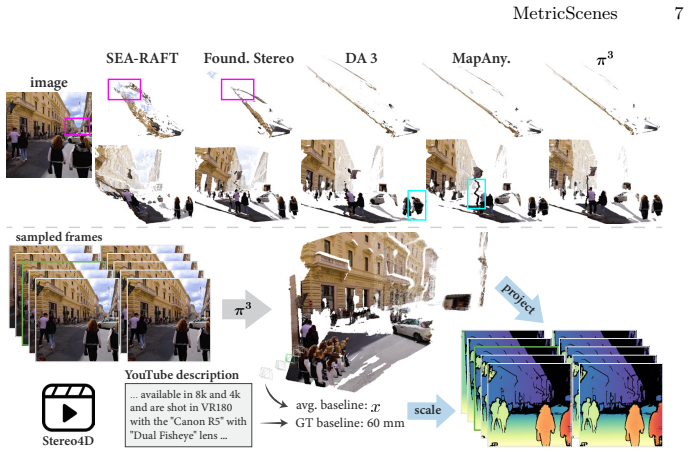
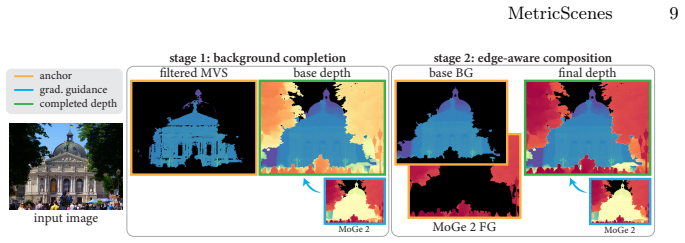
MetricScenes dataset that recovers absolute scale from geo-tagged metadata together with known stereo camera baselines, augmented by two-stage Poisson completion to refine depth maps.
If this is right
- Scale-collapse is mitigated for unconstrained open-domain scenes containing distant landmarks and landscapes.
- Superior metric accuracy is obtained while state-of-the-art performance on standard benchmarks is maintained.
- Two-stage Poisson completion measurably improves the quality of depth maps derived from the collected scenes.
- Diverse real-world sources can supply the metric ground truth that current hardware-constrained datasets lack.
Where Pith is reading between the lines
- The same curation strategy could be applied to fine-tune other monocular geometry foundation models beyond MoGe-2.
- Geo-tagged imagery may become a scalable route for expanding metric training data without new hardware campaigns.
- Outdoor robotics and augmented-reality systems could gain practical metric reliability in large environments once such data is widely used.
Load-bearing premise
Absolute scale recovered from geo-tagged metadata and known stereo baselines is accurate enough to serve as reliable ground truth even when pose estimates come from off-the-shelf methods.
What would settle it
If models fine-tuned on MetricScenes continue to show large metric underestimation when evaluated against independent high-accuracy scale measurements such as LiDAR in new open-domain scenes, the central claim would be falsified.
Figures




read the original abstract
Metric scale monocular geometry estimation has seen significant progress through large-scale data aggregation, yet current foundation models suffer from a persistent ''scale-collapse'' phenomenon: distant landmarks and vast landscapes are metrically underestimated. We hypothesize that this performance gap stems from a training data bottleneck, where existing metric-scale datasets are hardware-constrained to homogenous vehicle-captured LiDAR or short-range indoor scans, or consist of synthetic data that lacks the semantic complexity of the physical world. To bridge this gap, we curate a new metrically-grounded, in-the-wild dataset that we call MetricScenes, gathered from a variety of sources including Internet photo collections and stereo imagery. We estimate camera poses and initial depth maps for each scene using off-the-shelf methods, and recover absolute scale from geo-tagged metadata as well as known stereo camera baselines. We also improve the quality of depth maps derived from MetricScenes via a new two-stage Poisson completion method. Fine-tuning MoGe-2 on our dataset significantly mitigates scale-collapse and achieves superior metric accuracy in unconstrained, open-domain scenes while maintaining state-of-the-art performance on standard benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MetricScenes, a new in-the-wild dataset for metric-scale monocular depth and geometry estimation, constructed from internet photo collections and stereo imagery. Absolute scale is recovered from geo-tagged metadata and known stereo baselines after running off-the-shelf pose and depth estimators; a two-stage Poisson completion method is proposed to improve depth map quality. The central claim is that fine-tuning MoGe-2 on this dataset significantly mitigates scale-collapse in open-domain scenes while preserving SOTA performance on standard benchmarks.
Significance. If the recovered metric ground truth proves reliable, the work would address a recognized limitation of current foundation models (underestimation of distant structure) by providing training data with semantic complexity beyond vehicle LiDAR or indoor scans. The approach of leveraging consumer geo-tags and stereo baselines for scale recovery, if validated, could be broadly enabling for metric monocular estimation.
major comments (2)
- [Abstract / §3] Abstract and §3 (Dataset construction): the headline claim of 'superior metric accuracy' after fine-tuning rests on the assumption that absolute scales recovered from geo-tagged metadata plus off-the-shelf pose estimators are accurate to the precision needed. No quantitative validation (e.g., consistency checks across overlapping views, comparison to independent range sensors, or error statistics on the recovered scales) is reported, making it impossible to distinguish genuine improvement from fitting to noisy labels.
- [§4] §4 (Experiments): the abstract asserts 'significantly mitigates scale-collapse' and 'superior metric accuracy' yet supplies no numerical results, baselines, error bars, or ablation tables in the provided text. Without these, the central empirical claim cannot be assessed.
minor comments (1)
- [§3.2] Notation for the two-stage Poisson completion procedure is introduced without an equation or pseudocode block; a compact algorithmic description would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger validation of the recovered scales and clearer presentation of empirical results. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Dataset construction): the headline claim of 'superior metric accuracy' after fine-tuning rests on the assumption that absolute scales recovered from geo-tagged metadata plus off-the-shelf pose estimators are accurate to the precision needed. No quantitative validation (e.g., consistency checks across overlapping views, comparison to independent range sensors, or error statistics on the recovered scales) is reported, making it impossible to distinguish genuine improvement from fitting to noisy labels.
Authors: We agree that the current manuscript lacks quantitative validation of the recovered metric scales. While scale is recovered from geo-tags and stereo baselines, no consistency checks or error statistics were reported. In the revision we will add these analyses (overlapping-view consistency and available independent sensor comparisons) to substantiate the ground-truth quality. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract asserts 'significantly mitigates scale-collapse' and 'superior metric accuracy' yet supplies no numerical results, baselines, error bars, or ablation tables in the provided text. Without these, the central empirical claim cannot be assessed.
Authors: The provided excerpt omitted the numerical tables and figures from §4. The full manuscript does contain baseline comparisons and ablations, but we acknowledge the abstract and main text should present explicit metrics (e.g., scale-error reductions with error bars). We will expand both the abstract and §4 with these quantitative results and additional ablations in the revision. revision: yes
Circularity Check
No circularity: scale recovery uses external geo-tags and stereo baselines
full rationale
The paper's central claim is that fine-tuning on MetricScenes (with absolute scale recovered from geo-tagged metadata and known stereo baselines via off-the-shelf pose estimators) mitigates scale-collapse. This recovery step is external to the model and not derived from or fitted to the model's own outputs or predictions. No equations, self-citations, or ansatzes reduce the metric improvement result to a tautology or fitted input by construction. The derivation chain remains independent of the target result.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.