A Local Perturbation Theory for Cross-Domain Interference and Recovery in Multi-Domain RL
Pith reviewed 2026-06-28 15:35 UTC · model grok-4.3
The pith
Later-domain RL training harms earlier domains mainly through a second-order damage term concentrated in a low-dimensional shared conflict subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the local perturbation model of multi-domain RL, later-domain training harms an earlier domain mainly through a second-order damage term that, given the observed sparse route structure, concentrates in a low-dimensional shared conflict subspace. A brief domain refresh contracts this harmful component, enabling selective recovery, while a training-free rollback on a sparse proxy conflict coordinate set provides direct evidence of localized damage.
What carries the argument
the second-order damage term within the local perturbation model, which concentrates interference in the low-dimensional shared conflict subspace under sparse active computation routes.
If this is right
- A short refresh on an earlier domain recovers performance by contracting the second-order damage term with limited collateral effects on other domains.
- Training-free rollback on a sparse proxy set of conflict coordinates can partially restore earlier-domain performance without further training.
- Interference persists even when full-model gradients are nearly orthogonal because shared routes determine synergy or conflict.
- The sparse, small-magnitude edits from single-domain RL create weak top-neuron overlap yet still produce route-level conflicts.
Where Pith is reading between the lines
- Monitoring activity along the identified conflict subspace during training could enable early detection and targeted interventions before full degradation occurs.
- The localized mechanism may extend to continual learning settings beyond RL where parameter updates remain sparse and route-overlapping.
- Proxy-level rollback on conflict coordinates suggests that low-rank approximations of the subspace could support efficient recovery methods at scale.
Load-bearing premise
The local perturbation model remains a valid approximation of the dominant parameter-update dynamics inside the observed sparse route structure.
What would settle it
An experiment measuring the second-order damage term after sequential domain training and finding that it does not concentrate in the predicted low-dimensional shared conflict subspace, or that a short refresh fails to contract the harmful component while preserving other domains.
Figures

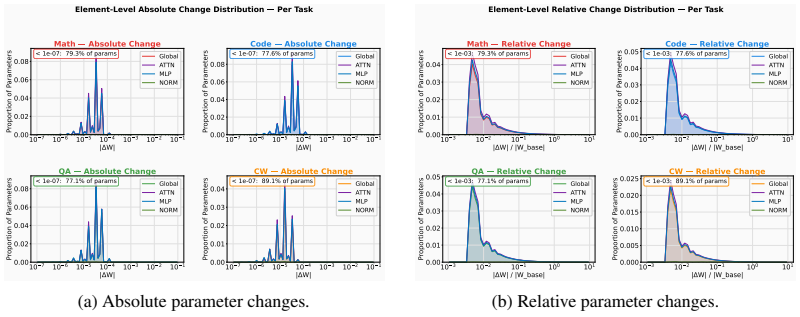
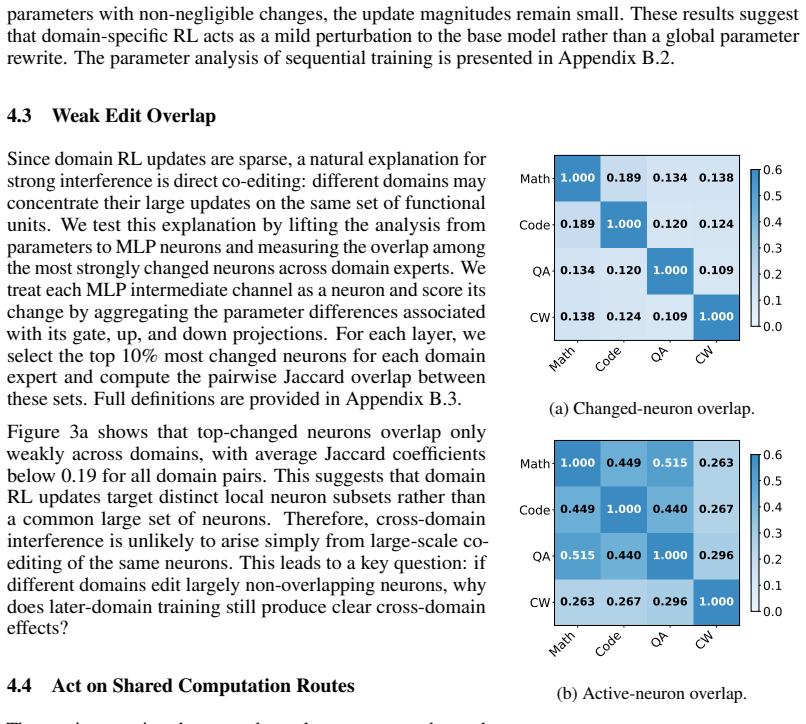
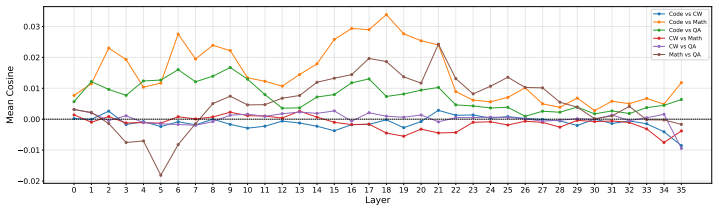


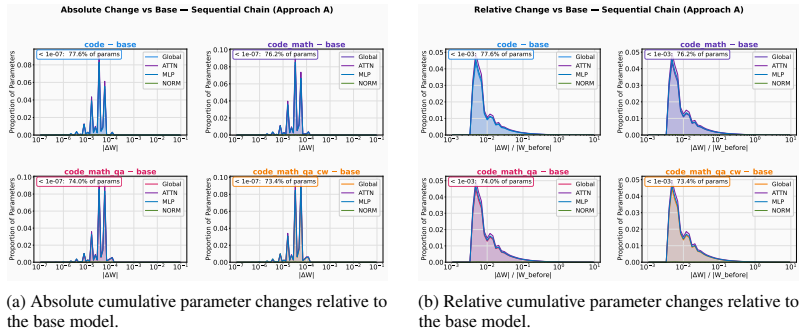






read the original abstract
Reinforcement learning (RL) post-training improves large language models (LLMs) on individual domains such as mathematical reasoning, code generation, question answering, and creative writing (CW), but training on one domain often degrades performance on others. Existing explanations based on catastrophic forgetting or global gradient conflict are incomplete: substantial interference can occur even when full-model gradients are nearly orthogonal. We show that single-domain RL produces sparse, small-magnitude parameter edits with weak overlap among top-changed neurons, while different domains still share substantial active computation routes on which update directions determine whether they act synergistically or conflict. Guided by this observation, we prove under a local perturbation model of multi-domain RL that later-domain training harms an earlier domain mainly through a second-order damage term, which under the observed sparse route structure concentrates in a low-dimensional shared conflict subspace. Moreover, a short domain refresh contracts the harmful component on this subspace, enabling selective recovery with limited collateral damage. Consistent with the theory, a brief Re-Math refresh after Code $\rightarrow$ Math $\rightarrow$ QA $\rightarrow$ CW recovers Math from 57.66 to 66.04 while largely preserving performance on the other domains, yielding the best average score of 66.39. Beyond refresh, a training-free rollback on a sparse proxy conflict coordinate set for the Math-QA pair partially restores Math, providing direct proxy-level evidence for localized damage. These results provide a localized mechanistic account of interference and recovery in multi-domain RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a local perturbation theory for cross-domain interference in multi-domain RL post-training of LLMs. Guided by empirical observations of sparse, small-magnitude parameter edits with weak neuron overlap but shared active computation routes, it proves under an explicit local perturbation model that later-domain training primarily harms earlier domains via a second-order damage term. This term concentrates in a low-dimensional shared conflict subspace due to the sparse route structure. The theory further predicts that a brief domain refresh contracts the harmful component for selective recovery with limited collateral effects. Experiments on Math, Code, QA, and CW domains show a Re-Math refresh recovering Math from 57.66 to 66.04 while preserving other domains (best average 66.39), with additional support from a training-free rollback on a sparse proxy conflict coordinate set.
Significance. If the local perturbation model is a valid approximation, the work supplies a mechanistic, localized account of interference that addresses gaps in catastrophic forgetting and global gradient conflict explanations. The derivation of the second-order term and its concentration in a low-dimensional subspace, combined with matching experimental recovery via refresh and rollback, offers both theoretical insight and practical recovery techniques for multi-domain LLM post-training. The explicit modeling choice tested against observed sparse edits and direct proxy-level evidence are strengths that could inform more targeted training strategies.
major comments (2)
- [Theory section] Theory section (local perturbation model and second-order derivation): The model is introduced as guided by the sparse-route observation to produce the claimed second-order term; the manuscript should add an explicit statement of the perturbation-size regime (e.g., relative to gradient norms or update magnitudes) under which the second-order approximation dominates and the subspace concentration holds, together with a boundary-case check against full-gradient computations.
- [Experimental results] Experimental results (recovery scores and validation): The reported improvements (Math 57.66 → 66.04, average 66.39) and rollback results are presented without error bars, number of runs, or comparisons to standard baselines such as experience replay or gradient-projection methods; this weakens the claim that the refresh achieves selective recovery consistent with the theory.
minor comments (2)
- [Theory section] Notation for the shared conflict subspace and active routes should be formally defined with symbols and dimensions when first introduced in the theory section to improve readability.
- [Abstract and results] The abstract and results section would benefit from a brief statement of how the sparse proxy coordinate set for rollback is constructed, including its dimensionality relative to the full parameter space.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments help clarify the conditions for the local perturbation model and strengthen the experimental validation. We respond to each major comment below.
read point-by-point responses
-
Referee: [Theory section] Theory section (local perturbation model and second-order derivation): The model is introduced as guided by the sparse-route observation to produce the claimed second-order term; the manuscript should add an explicit statement of the perturbation-size regime (e.g., relative to gradient norms or update magnitudes) under which the second-order approximation dominates and the subspace concentration holds, together with a boundary-case check against full-gradient computations.
Authors: We agree that an explicit statement of the perturbation-size regime is necessary. In the revised manuscript, we will add a paragraph in the Theory section defining the regime: the second-order approximation holds when update magnitudes are small relative to gradient norms (consistent with the observed sparse, small-magnitude edits), ensuring the second-order damage term dominates and concentrates in the low-dimensional shared conflict subspace. We will also include a boundary-case check comparing the local approximation against full-gradient computations on a subset of domains to delineate the validity range. revision: yes
-
Referee: [Experimental results] Experimental results (recovery scores and validation): The reported improvements (Math 57.66 → 66.04, average 66.39) and rollback results are presented without error bars, number of runs, or comparisons to standard baselines such as experience replay or gradient-projection methods; this weakens the claim that the refresh achieves selective recovery consistent with the theory.
Authors: We acknowledge that error bars and the number of runs were omitted. The reported scores were obtained over 3 random seeds; we will revise the Experimental Results section to report means and standard deviations. However, direct comparisons to experience replay or gradient-projection methods fall outside the paper's primary aim of testing consistency with the local perturbation predictions (subspace contraction and selective recovery). Such baselines would require substantial additional experiments, which we will flag as future work while retaining the rollback as direct proxy-level support for the theory. revision: partial
Circularity Check
No significant circularity; derivation self-contained under explicit model
full rationale
The paper states an empirical observation of sparse edits, then explicitly introduces a local perturbation model as an analytical device to derive the second-order damage term and subspace concentration. The derivation proceeds from the model's assumptions to the claimed results, with direct experimental tests of recovery via refresh and rollback. No load-bearing step reduces by construction to a self-definition, a fitted input renamed as prediction, or a self-citation chain; the model applicability is presented as a testable approximation rather than hidden. This is the normal case of a modeling paper whose central claim remains independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The local perturbation model accurately captures the dynamics of multi-domain RL parameter updates.
- domain assumption Single-domain RL produces sparse, small-magnitude parameter edits with weak overlap among top-changed neurons while domains share active computation routes.
invented entities (1)
-
low-dimensional shared conflict subspace
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aime problems and solutions
Art of Problem Solving. Aime problems and solutions. https://artofproblemsolving.com/ wiki/index.php/AIME_Problems_and_Solutions, 2024a. Accessed: 2025-12-18
2025
-
[2]
A. Bau, Y . Belinkov, H. Sajjad, N. Durrani, F. Dalvi, and J. R. Glass. Identifying and controlling important neurons in neural machine translation. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
2019
-
[3]
H. Chen, N. Razin, K. Narasimhan, and D. Chen. Retaining by doing: The role of on-policy data in mitigating forgetting.CoRR, abs/2510.18874, 2025
arXiv 2025
-
[4]
Z. Chen, V . Badrinarayanan, C. Lee, and A. Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In J. G. Dy and A. Krause, editors, Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stock- holmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 ofProceedings of Machine Lea...
2018
-
[5]
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. In I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V . N. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 20...
2017
-
[6]
T. Chu, Y . Zhai, J. Yang, S. Tong, S. Xie, D. Schuurmans, Q. V . Le, S. Levine, and Y . Ma. SFT memorizes, RL generalizes: A comparative study of foundation model post-training.CoRR, abs/2501.17161, 2025
Pith/arXiv arXiv 2025
-
[7]
D. Dai, L. Dong, Y . Hao, Z. Sui, B. Chang, and F. Wei. Knowledge neurons in pretrained transformers. In S. Muresan, P. Nakov, and A. Villavicencio, editors,Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 8493–8502. Association for Computatio...
2022
-
[8]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025. 10
2025
-
[9]
J. Dekoninck, N. Jovanovi´c, T. Gehrunger, K. Rögnvalddson, I. Petrov, C. Sun, and M. Vechev. Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms.CoRR, abs/2605.00674, 2026
Pith/arXiv arXiv 2026
-
[10]
C. He, R. Luo, Y . Bai, S. Hu, Z. L. Thai, J. Shen, J. Hu, X. Han, Y . Huang, Y . Zhang, J. Liu, L. Qi, Z. Liu, and M. Sun. Olympiadbench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. In L. Ku, A. Martins, and V . Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Comp...
2024
-
[11]
M. Huan, Y . Li, T. Zheng, X. Xu, S. Kim, M. Du, R. Poovendran, G. Neubig, and X. Yue. Does math reasoning improve general LLM capabilities? understanding transferability of LLM reasoning.CoRR, abs/2507.00432, 2025
Pith/arXiv arXiv 2025
-
[12]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025
2025
-
[13]
N. Jain, K. Han, A. Gu, W. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[14]
J. Kirkpatrick, R. Pascanu, N. C. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell. Overcoming catastrophic forgetting in neural networks.CoRR, abs/1612.00796, 2016
arXiv 2016
-
[15]
S. Lai, H. Zhao, R. Feng, C. Ma, W. Liu, H. Zhao, X. Lin, D. Yi, M. Xie, Q. Zhang, H. Liu, G. Meng, and F. Zhu. Reinforcement fine-tuning naturally mitigates forgetting in continual post-training.CoRR, abs/2507.05386, 2025
arXiv 2025
-
[16]
Leng and D
Y . Leng and D. Xiong. Towards understanding multi-task learning (generalization) of LLMs via detecting and exploring task-specific neurons. In O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, COLING 2025, Abu Dhabi, UAE, January 19-...
2025
-
[17]
D. Li, J. Zhou, A. Kazemi, Q. Sun, A. Ghaddar, M. A. Alomrani, L. Ma, Y . Luo, D. Li, F. Wen, J. Hao, M. Coates, and Y . Zhang. Omni-thinker: Scaling cross-domain generalization in llms via multi-task RL with hybrid rewards.CoRR, abs/2507.14783, 2025
arXiv 2025
-
[18]
Liang, L
X. Liang, L. Yang, J. Wang, R. Liu, Y . Lu, J. Zeng, H. Chen, D. Li, and J. Hao. Boosting multi-domain reasoning of LLMs via curvature-guided policy optimization. InInternational Conference on Learning Representations, 2026
2026
-
[19]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[20]
B. Liu, X. Liu, X. Jin, P. Stone, and Q. Liu. Conflict-averse gradient descent for multi-task learning. In M. Ranzato, A. Beygelzimer, Y . N. Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages ...
2021
-
[21]
Matena and C
M. Matena and C. Raffel. Merging models with fisher-weighted averaging. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022
2022
-
[22]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017. 11
Pith/arXiv arXiv 2017
-
[23]
Sener and V
O. Sener and V . Koltun. Multi-task learning as multi-objective optimization. In S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pages 525–536, 2018
2018
-
[24]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . K. Li, Y . Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300, 2024
Pith/arXiv arXiv 2024
-
[25]
I. Shenfeld, J. Pari, and P. Agrawal. RL’s razor: Why online reinforcement learning forgets less. CoRR, abs/2509.04259, 2025
Pith/arXiv arXiv 2025
-
[26]
Sheng, C
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu. Hybridflow: A flexible and efficient RLHF framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys 2025, Rotterdam, The Netherlands, 30 March 2025 - 3 April 2025, pages 1279–1297. ACM, 2025
2025
-
[27]
D. Shi, Z. Han, S. Ostermann, R. Jin, J. van Genabith, and D. Xiong. Why does reinforcement learning generalize? a feature-level mechanistic study of post-training in large language models. InProceedings of the 64th Annual Meeting of the Association for Computational Linguistics, 2026
2026
-
[28]
H. Shi, Z. Xu, H. Wang, W. Qin, W. Wang, Y . Wang, and H. Wang. Continual learning of large language models: A comprehensive survey.CoRR, abs/2404.16789, 2024
arXiv 2024
-
[29]
Stiennon, L
N. Stiennon, L. Ouyang, J. Wu, D. M. Ziegler, R. Lowe, C. V oss, A. Radford, D. Amodei, and P. F. Christiano. Learning to summarize with human feedback. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors,Advances in Neural Information Processing Sys- tems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 20...
2020
-
[30]
Z. Su, L. Pan, M. Lv, Y . Li, W. Hu, F. Zhang, K. Gai, and G. Zhou. Ce-gppo: Controlling entropy via gradient-preserving clipping policy optimization in reinforcement learning, 2025
2025
-
[31]
K. Team. Kimi k1.5: Scaling reinforcement learning with llms.CoRR, abs/2501.12599, 2025
Pith/arXiv arXiv 2025
-
[32]
M. Team. Supergpqa: Scaling LLM evaluation across 285 graduate disciplines.CoRR, abs/2502.14739, 2025
Pith/arXiv arXiv 2025
-
[33]
Q. Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025
Pith/arXiv arXiv 2025
-
[34]
X. Wang, K. Wen, Z. Zhang, L. Hou, Z. Liu, and J. Li. Finding skill neurons in pre-trained transformer-based language models. In Y . Goldberg, Z. Kozareva, and Y . Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 11132–11152. Asso...
2022
-
[35]
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In A. Globersons, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. M. Tomczak, and C. Zhang, editors,Advances in Neural ...
2024
-
[36]
Wortsman, G
M. Wortsman, G. Ilharco, S. Y . Gadre, R. Roelofs, R. Gontijo-Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y . Carmon, S. Kornblith, and L. Schmidt. Model soups: aver- aging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational Conference on Machine Learning, ICML 2022, 17-23 July 2022, Bal- timore, Ma...
2022
-
[37]
Y . Wu, J. Mei, M. Yan, C. Li, S. Lai, Y . Ren, Z. Wang, J. Zhang, M. Wu, Q. Jin, and F. Huang. Writingbench: A comprehensive benchmark for generative writing.CoRR, abs/2503.05244, 2025
arXiv 2025
-
[38]
Yadav, D
P. Yadav, D. Tam, L. Choshen, C. A. Raffel, and M. Bansal. Ties-merging: Resolving interfer- ence when merging models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems 36: Annual Confer- ence on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, D...
2023
-
[39]
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn. Gradient surgery for multi-task learning. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020
2020
-
[40]
forgetting A and then forgetting B
J. Zheng, X. Cai, S. Qiu, and Q. Ma. Spurious forgetting in continual learning of language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. 13 Table 4: Training hyperparameters. train batch size ppo mini batch size max prompt length max response length adv estimat...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.