K-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts
Pith reviewed 2026-06-28 14:32 UTC · model grok-4.3
The pith
Korean web-browsing agent benchmark shows frontier models scoring only 30 to 46 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
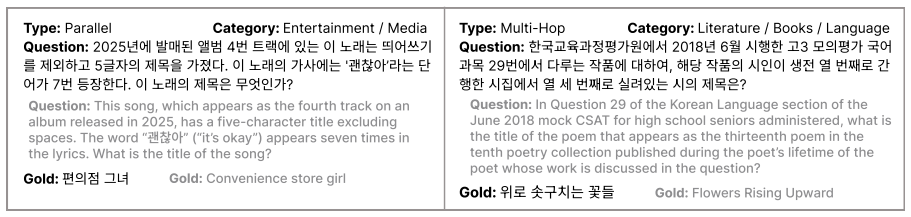
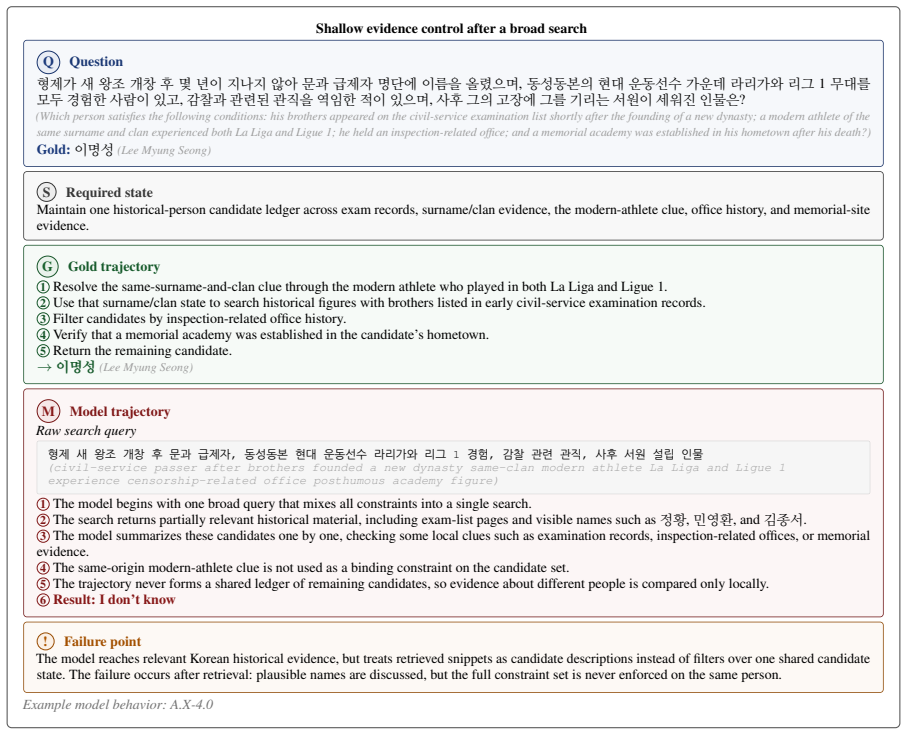
K-BrowseComp consists of 400 problems, with a 300-problem verified subset constructed and checked by native Korean speakers. On this subset frontier LLMs reach 30.00 to 45.67 percent while Korean LLMs reach 0.00 to 10.33 percent, a marked decline from results on the English BrowseComp benchmark. The 100-problem synthetic split, built with hard examples and targeted failure modes, yields a top score of 26 percent.
What carries the argument
K-BrowseComp-Verified, the 300-problem set of manually validated Korean web-browsing tasks that serves as the main evaluation measure for agent performance.
If this is right
- Frontier models must improve their ability to navigate and reason over Korean-language web content and contexts.
- Korean LLMs need targeted development to handle compositional agentic tasks at competitive levels.
- The synthetic diagnostic split can serve as a stress test to identify specific failure modes in browsing agents.
- Public release of the benchmark enables standardized comparison and progress tracking for multilingual agents.
Where Pith is reading between the lines
- Language-specific benchmarks may be necessary to reveal capabilities hidden by English-centric evaluations.
- Similar construction methods could be applied to create benchmarks for other underrepresented languages or cultures.
- The gap suggests that web agent performance depends heavily on training data distribution matching the target context.
- Future work could test whether fine-tuning on Korean web data closes the observed performance difference.
Load-bearing premise
The 300 problems, even after validation by native speakers, truly reflect the challenges and distribution of actual Korean web-browsing tasks without cultural or construction biases.
What would settle it
If independent evaluation on the publicly released K-BrowseComp-Verified problems produces scores for frontier models above 70 percent, the reported performance gap would not hold.
Figures













read the original abstract
Frontier model evaluations are shifting from foundational capabilities (e.g., instruction following and reasoning) toward compositional, agentic ones, but Korean agentic benchmarks remain scarce. We introduce K-BrowseComp, a web-browsing agent benchmark grounded in Korean contexts, consisting of 400 problems. The 300-problem K-BrowseComp-Verified subset is manually constructed and validated by native Korean speakers. On this subset, frontier LLMs, including GPT-5.5, DeepSeek-V4-Pro, and GLM-5.1, reach only 30.00--45.67\%, a substantial drop from BrowseComp, while Korean LLMs released through Korea's Proprietary AI Foundation Model program obtain only 0.00--10.33\%. We further construct a 100-problem synthetic split using hard few-shot exemplars and failure-mode-targeted generation to exploit the asymmetry between solving and creating web browsing problems. On the adversarially filtered synthetic diagnostic split, the strongest model reaches only 26.00\%, and we report this split separately as a targeted stress test. We publicly release our data and code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces K-BrowseComp, a web-browsing agent benchmark with 400 problems grounded in Korean contexts. The 300-problem K-BrowseComp-Verified subset was manually constructed and validated by native Korean speakers; on this subset frontier models (GPT-5.5, DeepSeek-V4-Pro, GLM-5.1) score 30.00–45.67 % (a substantial drop from BrowseComp) while Korean LLMs from the Proprietary AI Foundation Model program score 0.00–10.33 %. A 100-problem synthetic diagnostic split, generated via hard few-shot exemplars and failure-mode targeting, yields a maximum of 26.00 %. Data and code are released.
Significance. If the 300 verified problems constitute a representative and unbiased sample of Korean web-browsing tasks, the results would document a clear gap in current frontier-model agentic performance on non-English web navigation and would motivate targeted improvements for Korean-language agents. The public release of data and code is a concrete strength that enables direct replication and extension.
major comments (2)
- [Abstract / problem-construction section] Abstract and problem-construction section: the central performance claims rest on the 300-problem K-BrowseComp-Verified subset being a valid, unbiased measure of agent capability, yet the manuscript states only that the problems were “manually constructed and validated by native Korean speakers” with no quantitative details on sourcing criteria, task distribution across domains, inter-annotator agreement, or external grounding against real usage logs. This absence directly undermines interpretability of the reported 30–45 % and 0–10 % figures.
- [Abstract / evaluation section] Comparison to BrowseComp (abstract and evaluation section): the claim of a “substantial drop” from BrowseComp is load-bearing for the Korean-context argument, but no explicit side-by-side analysis of problem difficulty, linguistic complexity, or domain coverage is provided; without such controls the observed gap could arise from non-comparable task sets rather than language or cultural factors.
minor comments (1)
- [synthetic-split description] The synthetic-split generation procedure (hard few-shot exemplars and failure-mode targeting) is described at a high level; a short appendix table listing the exact failure modes targeted and the number of exemplars per mode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validity of our benchmark construction and the comparison to BrowseComp. We address each major comment below and outline planned revisions to improve clarity and interpretability.
read point-by-point responses
-
Referee: [Abstract / problem-construction section] Abstract and problem-construction section: the central performance claims rest on the 300-problem K-BrowseComp-Verified subset being a valid, unbiased measure of agent capability, yet the manuscript states only that the problems were “manually constructed and validated by native Korean speakers” with no quantitative details on sourcing criteria, task distribution across domains, inter-annotator agreement, or external grounding against real usage logs. This absence directly undermines interpretability of the reported 30–45 % and 0–10 % figures.
Authors: We agree that the current description is insufficient for full interpretability. The verified subset was constructed by selecting problems from Korean web domains (government portals, e-commerce, news, and local services) with explicit criteria for requiring multi-step navigation and Korean-language reasoning. Three native Korean speakers independently validated each problem for solvability and cultural grounding, achieving 92% agreement on final inclusion. In revision we will add a dedicated subsection with: (i) domain distribution table, (ii) inter-annotator agreement statistics, (iii) sourcing criteria, and (iv) explicit statement that real usage logs were not available and thus not used for grounding. This addresses the concern directly. revision: yes
-
Referee: [Abstract / evaluation section] Comparison to BrowseComp (abstract and evaluation section): the claim of a “substantial drop” from BrowseComp is load-bearing for the Korean-context argument, but no explicit side-by-side analysis of problem difficulty, linguistic complexity, or domain coverage is provided; without such controls the observed gap could arise from non-comparable task sets rather than language or cultural factors.
Authors: The manuscript reports the raw score difference (30–45% vs. the higher BrowseComp numbers cited in the original work) but does not include controlled comparison. We acknowledge this limitation and will add a new paragraph in the evaluation section that (a) tabulates domain overlap, (b) reports average number of required actions and linguistic features (e.g., named-entity density), and (c) qualifies the “substantial drop” phrasing to note that part of the gap may reflect task-set differences. Where direct metrics are unavailable we will state the limitation rather than overclaim. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or fitted predictions
full rationale
The paper introduces K-BrowseComp as a manually constructed benchmark of 400 problems (300 verified by native speakers) and reports direct empirical accuracies for frontier and Korean LLMs. No equations, parameters, predictions, or first-principles derivations appear anywhere in the manuscript. Performance numbers are measured outputs on the released dataset rather than outputs derived from fitted inputs or self-referential definitions. No self-citation chains, uniqueness theorems, or ansatzes are invoked to support any claim. The work is self-contained empirical construction and evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Native Korean speaker validation produces problems that accurately reflect real Korean web contexts and agent tasks.
Reference graph
Works this paper leans on
-
[1]
Call for Proposals: Sovereign
-
[2]
2026 , url=
Eunbi Choi and Kibong Choi and Seokhee Hong and Junwon Hwang and Hyojin Jeon and Hyunjik Jo and Joonkee Kim and Seonghwan Kim and Soyeon Kim and Sunkyoung Kim and Yireun Kim and Yongil Kim and Haeju Lee and Jinsik Lee and Kyungmin Lee and Sangha Park and Heuiyeen Yeen and Hwan Chang and Stanley Jungkyu Choi and Yejin Choi and Jiwon Ham and Kijeong Jeon an...
2026
-
[3]
arXiv preprint arXiv:2601.07022 , year=
Solar Open Technical Report , author=. arXiv preprint arXiv:2601.07022 , year=
- [4]
-
[5]
Lee, Nahyun and Son, Guijin and Ko, Hyunwoo and Kim, Chanyoung and An, JunYoung and Han, Kyubeen and Kwak, Il-Youp , journal=
-
[6]
HAE - RAE Bench: Evaluation of K orean Knowledge in Language Models
Son, Guijin and Lee, Hanwool and Kim, Suwan and Kim, Huiseo and Lee, Jae cheol and Yeom, Je Won and Jung, Jihyu and Kim, Jung woo and Kim, Songseong. HAE - RAE Bench: Evaluation of K orean Knowledge in Language Models. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[7]
CLI c K : A Benchmark Dataset of Cultural and Linguistic Intelligence in K orean
Kim, Eunsu and Suk, Juyoung and Oh, Philhoon and Yoo, Haneul and Thorne, James and Oh, Alice. CLI c K : A Benchmark Dataset of Cultural and Linguistic Intelligence in K orean. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[8]
Dong, Yihong and Jiang, Xue and Liu, Huanyu and Jin, Zhi and Gu, Bin and Yang, Mengfei and Li, Ge. Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.716
-
[9]
arXiv preprint arXiv:2602.12413 , year=
Soft Contamination Means Benchmarks Test Shallow Generalization , author=. arXiv preprint arXiv:2602.12413 , year=
-
[10]
Aaditya Singh and Adam Fry and Adam Perelman and Adam Tart and Adi Ganesh and Ahmed El-Kishky and Aidan McLaughlin and Aiden Low and AJ Ostrow and Akhila Ananthram and Akshay Nathan and Alan Luo and Alec Helyar and Aleksander Madry and Aleksandr Efremov and Aleksandra Spyra and Alex Baker-Whitcomb and Alex Beutel and Alex Karpenko and Alex Makelov and Ale...
2025
-
[11]
2025 , url=
Wei, Jason and Sun, Zhiqing and Papay, Spencer and McKinney, Scott and Han, Jeffrey and Fulford, Isa and Chung, Hyung Won and Passos, Alex Tachard and Fedus, William and Glaese, Amelia , journal=. 2025 , url=
2025
-
[12]
2025 , url=
Peilin Zhou and Bruce Leon and Xiang Ying and Can Zhang and Yifan Shao and Qichen Ye and Dading Chong and Zhiling Jin and Chenxuan Xie and Meng Cao and Yuxin Gu and Sixin Hong and Jing Ren and Jian Chen and Chao Liu and Yining Hua , journal=. 2025 , url=
2025
-
[13]
2026 , url =
Introducing. 2026 , url =
2026
-
[14]
2026 , howpublished =
2026
-
[15]
2025 , howpublished =
2025
-
[16]
GitHub repository , publisher =
search\_evals: An Evaluation Framework for. GitHub repository , publisher =
-
[17]
Transactions of the Association for Computational Linguistics , volume =
Natural Questions: A Benchmark for Question Answering Research , author =. Transactions of the Association for Computational Linguistics , volume =. 2019 , doi =
2019
-
[18]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle =. 2018 , address =. doi:10.18653/v1/D18-1259 , url =
-
[19]
♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal=. 2022 , issn =. doi:10.1162/tacl_a_00475 , url =
-
[20]
Proceedings of the 34th International Conference on Machine Learning , editor =
World of bits: An open-domain platform for web-based agents , author=. Proceedings of the 34th International Conference on Machine Learning , editor =. 2017 , organization=
2017
-
[21]
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =
-
[22]
Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Sam and Wang, Boshi and Sun, Huan and Su, Yu , booktitle =
-
[23]
Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , booktitle=
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , booktitle=. 2024 , url =
2024
-
[24]
and Verme, Manuel Del and Marty, Tom and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre , title =
Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Verme, Manuel Del and Marty, Tom and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[25]
Proceedings of the 41st International Conference on Machine Learning , articleno =
L\`. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[26]
International Conference on Learning Representations , volume=
Mialon, Gr. International Conference on Learning Representations , volume=. 2024 , editor =
2024
-
[27]
2019 , url=
Lim, Seungyoung and Kim, Myungji and Lee, Jooyoul , journal=. 2019 , url=
2019
-
[28]
K o BEST : K orean Balanced Evaluation of Significant Tasks
Jang, Myeongjun and Kim, Dohyung and Kwon, Deuk Sin and Davis, Eric. K o BEST : K orean Balanced Evaluation of Significant Tasks. Proceedings of the 29th International Conference on Computational Linguistics. 2022
2022
-
[29]
KMMLU : Measuring Massive Multitask Language Understanding in K orean
Son, Guijin and Lee, Hanwool and Kim, Sungdong and Kim, Seungone and Muennighoff, Niklas and Choi, Taekyoon and Park, Cheonbok and Yoo, Kang Min and Biderman, Stella. KMMLU : Measuring Massive Multitask Language Understanding in K orean. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguist...
-
[30]
International Conference on Learning Representations , editor =
Romanou, Angelika and Foroutan, Negar and Sotnikova, Anna and Nelaturu, Sree Harsha and Singh, Shivalika and Maheshwary, Rishabh and Altomare, Micol and Chen, Zeming and Haggag, Mohamed and A, Snegha and Amayuelas, Alfonso and Amirudin, Azril Hafizi and Boiko, Danylo and Chang, Michael and Chim, Jenny and Cohen, Gal and Dalmia, Aditya K and Diress, Abraha...
-
[31]
The Fourteenth International Conference on Learning Representations , year=
Chenxi Whitehouse and Sebastian Ruder and Tony Zhiyang Lin and Oksana Kurylo and Haruka Takagi and Janice Lam and Nicol. The Fourteenth International Conference on Learning Representations , year=
-
[32]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A. and Khashabi, Daniel and Hajishirzi, Hannaneh. S elf- I nstruct: Aligning Language Models with Self-Generated Instructions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.754
-
[33]
Xu, Can and Sun, Qingfeng and Zheng, Kai and Geng, Xiubo and Zhao, Pu and Feng, Jiazhan and Tao, Chongyang and Lin, Qingwei and Jiang, Daxin , booktitle =
-
[34]
Adversarial NLI : A New Benchmark for Natural Language Understanding
Nie, Yixin and Williams, Adina and Dinan, Emily and Bansal, Mohit and Weston, Jason and Kiela, Douwe. Adversarial NLI : A New Benchmark for Natural Language Understanding. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.441
-
[35]
Measuring and Narrowing the Compositionality Gap in Language Models
Press, Ofir and Zhang, Muru and Min, Sewon and Schmidt, Ludwig and Smith, Noah and Lewis, Mike. Measuring and Narrowing the Compositionality Gap in Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.378
-
[36]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[37]
Autodata: an automatic data scientist to create high quality data. 2026
2026
-
[38]
arXiv preprint arXiv:2510.24684 , year=
Spice: Self-play in corpus environments improves reasoning , author=. arXiv preprint arXiv:2510.24684 , year=
-
[39]
The biggen bench: A principled benchmark for fine-grained evaluation of language models with language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.