MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation
Pith reviewed 2026-06-28 14:48 UTC · model grok-4.3
The pith
MCP-Persona shows that state-of-the-art LLM agents struggle significantly with personalized tool use in personal applications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MCP-Persona is the first benchmark specifically designed for evaluating agent performance on real-world, personalized MCP tools. It encompasses social media platforms like Reddit and Xiaohongshu along with enterprise suites such as Lark and Slack. Through environment simulation, the benchmark shows that state-of-the-art agents exhibit significant struggles with personalized tool use.
What carries the argument
MCP-Persona benchmark, which employs environment simulation to test LLM agents on personalized MCP tools that interact with individual accounts or local databases.
If this is right
- Agents must develop better mechanisms for managing account-specific permissions and data when using personalized tools.
- Benchmarking efforts should expand to cover additional personal applications beyond generic information retrieval.
- Progress on MCP-Persona can directly inform improvements in agent reliability for daily personal and collaborative workflows.
Where Pith is reading between the lines
- Agents that underperform here are likely to face similar issues in other domains involving private user data such as email or personal calendars.
- The simulation approach could be extended to train agents on privacy-preserving personalization before real deployment.
- Wider adoption of such benchmarks may push developers to prioritize tool-use safety features when handling individual accounts.
Load-bearing premise
The environment simulations used in MCP-Persona accurately capture the real practical challenges of interacting with personalized tools in applications such as Reddit and Slack.
What would settle it
A direct test showing that state-of-the-art agents achieve high success rates on MCP-Persona tasks without the reported struggles, or a comparison where real user interactions diverge substantially from the simulated results.
Figures
read the original abstract
The Model Context Protocol (MCP) has emerged as a transformative standard for connecting large language models (LLMs) with external data sources and tools, and has been rapidly adopted across personal applications and development platforms. However, existing benchmarks predominantly focus on generic information-seeking tools and fail to capture the practical challenges posed by personal social applications, where tools interact with individual accounts or local databases. To bridge this critical gap, we introduce MCP-Persona, the first benchmark specifically designed for evaluating agent performance on real-world, personalized MCP tools. MCP-Persona encompasses a diverse set of widely-used applications, ranging from social media platforms like Reddit and Xiaohongshu (Rednote) to enterprise collaboration suites such as Lark (Feishu) and Slack. Our extensive experiments on various state-of-the-art (SOTA) agents demonstrate their significant struggles with personalized tool use, thereby highlighting the benchmark's crucial role in identifying and addressing these limitations. MCP-Persona is publicly available at https://github.com/wwh0411/MCP-Persona}{https://github.com/wwh0411/MCP-Persona.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MCP-Persona, a benchmark for LLM agents on personalized MCP tools in real-world applications such as Reddit, Xiaohongshu (Rednote), Lark (Feishu), and Slack. It argues that prior benchmarks emphasize generic information-seeking tools and do not address challenges arising from interactions with individual accounts or local databases. The paper reports experiments showing that state-of-the-art agents struggle with personalized tool use in the simulated MCP-Persona environments and releases the benchmark at the provided GitHub repository.
Significance. If the simulated environments faithfully reproduce the practical challenges of real personalized MCP tool interactions, MCP-Persona would fill a clear gap by enabling targeted evaluation of agent limitations in personal and enterprise social applications. This could support more effective development of agents for user-specific tasks that current generic benchmarks overlook.
major comments (1)
- [Abstract and benchmark design] Abstract and benchmark design paragraph: The claim that MCP-Persona captures 'practical challenges posed by personal social applications' and that observed agent struggles reflect real limitations is load-bearing for the central contribution, yet no fidelity validation is described (e.g., no comparison of simulated tool responses, state transitions, error rates, or rate-limit behaviors against live APIs for Reddit or Slack). Without such checks, failures may arise from simulation simplifications rather than agent deficiencies.
minor comments (1)
- [Abstract] The GitHub URL in the abstract contains a duplicated and malformed link: 'https://github.com/wwh0411/MCP-Persona}{https://github.com/wwh0411/MCP-Persona'.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract and benchmark design] Abstract and benchmark design paragraph: The claim that MCP-Persona captures 'practical challenges posed by personal social applications' and that observed agent struggles reflect real limitations is load-bearing for the central contribution, yet no fidelity validation is described (e.g., no comparison of simulated tool responses, state transitions, error rates, or rate-limit behaviors against live APIs for Reddit or Slack). Without such checks, failures may arise from simulation simplifications rather than agent deficiencies.
Authors: We agree that explicit fidelity validation against live APIs would strengthen the central claim. The current manuscript describes the environments as being built on the MCP standard to reproduce personalized tool interactions (account-specific data, local databases, collaboration features) but does not report side-by-side comparisons of simulated versus live responses, state transitions, error rates, or rate-limit behavior. In the revised manuscript we will add a new subsection under benchmark design that details the simulation construction process, including the sources used (official MCP specifications, public API documentation for Reddit, Xiaohongshu, Lark, and Slack) and the modeling choices for state transitions and error conditions. We will also include an explicit limitations paragraph discussing the absence of live-API validation and the potential impact of any simulation simplifications on the reported agent performance gaps. revision: yes
Circularity Check
No circularity: new benchmark construction with independent experimental reporting
full rationale
The paper introduces MCP-Persona as a new benchmark for personalized MCP tools and reports experimental outcomes on SOTA agents. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claim rests on the benchmark design and observed agent performance rather than reducing to any self-defined quantities or prior author work by construction. This is a standard empirical benchmark paper with self-contained evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated environments can faithfully represent the practical challenges of personalized tool interactions in real applications
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/2025. emnlp-main.1341/. Wang, W., Shi, H., Yuan, M., Lin, Y ., Tong, P., Zhou, H., Liu, G., Zhao, P., Wang, Y ., and Chen, S. Fedgui: Benchmarking federated gui agents across heterogeneous platforms, devices, and operating systems, 2026. URL https://arxiv.org/abs/2604.14956. Wang, Y ., Kordi, Y ., Mishra, S., Liu, A., Smith, N...
Pith/arXiv arXiv 2025
-
[2]
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.754. Wu, M., Zhu, T., Han, H., Tan, C., Zhang, X., and Chen, W. Seal-Tools: Self-Instruct Tool Learning Dataset for Agent Tuning and Detailed Benchmark, May 2024. xAI. Grok 4 Model Card. https://data.x.ai/ 2025-08-20-grok-4-model-card.pdf, 2025. Xu, Z., Soria, A. M., Tan, S., Roy, A...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.acl-long.754 2023
-
[3]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[4]
emnlp-main.1611/
URL https://aclanthology.org/2025. emnlp-main.1611/. 12 MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation
2025
-
[5]
lark_mcp:im_v1_ message_create
-
[6]
lark_mcp:im_v1_ chatMembers_get
-
[7]
lark_mcp:im_v1_ message_list
-
[8]
Project Meeting 2
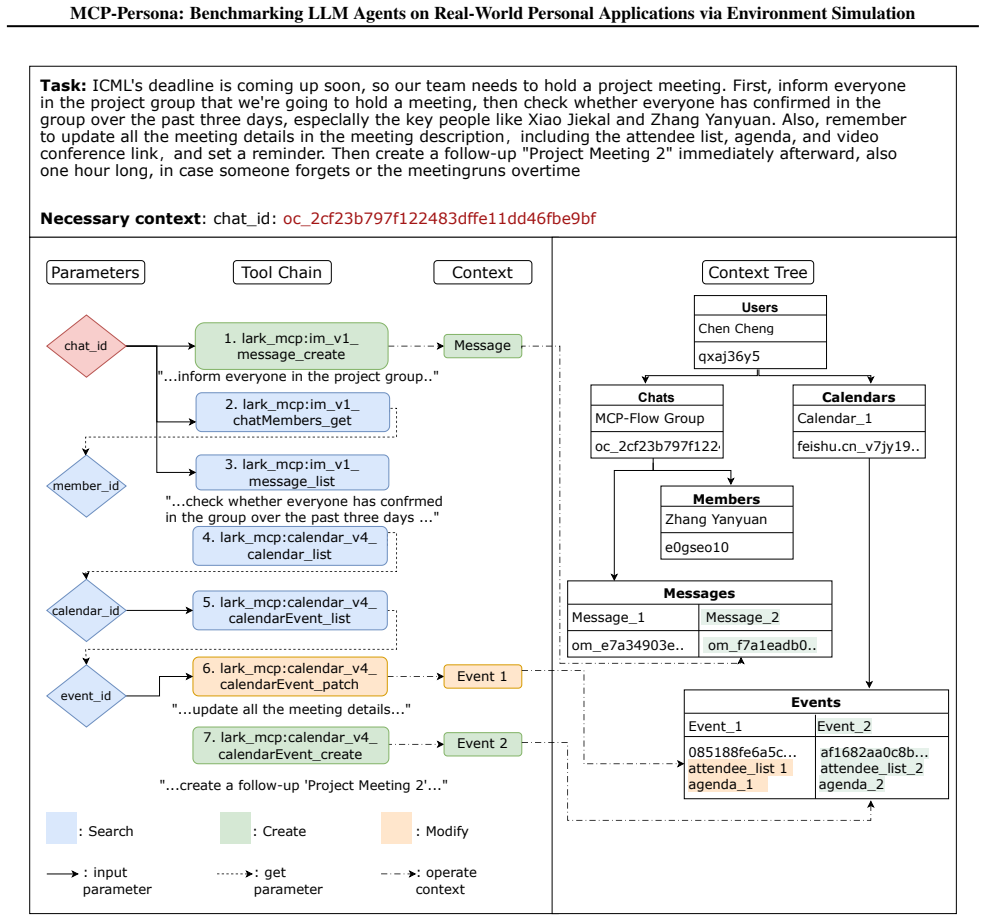
lark_mcp:calendar_v4_ calendarEvent_patch Task: ICML's deadline is coming up soon, so our team needs to hold a project meeting. First, inform everyone in the project group that we're going to hold a meeting, then check whether everyone has confirmed in the group over the past three days, especlally the key people like Xiao Jiekal and Zhang Yanyuan. Also, ...
-
[9]
lark_mcp:calendar_v4_ calendarEvent_list
-
[10]
inform everyone in the project group
lark_mcp:calendar_v4_ calendar_list "...inform everyone in the project group.." "...check whether everyone has confrmed in the group over the past three days ..." calendar_id chat_id event_id Event 1 Event 2 member_id "...update all the meeting details..." "...create a follow-up 'Project Meeting 2'..." ContextParameters : Search : Create : Modify : input ...
-
[11]
om_f7a1eadb0
lark_mcp:calendar_v4_ calendarEvent_create Messages Message_1 Message_2 om_e7a34903e.. om_f7a1eadb0.. Figure 4.A visualized illustration of how tools and contexts interact in the simulated environments of MCP-Persona. Left: a representative Lark-MCP task where the agent progresses through a series of tool calls that either retrieve contextual information ...
-
[12]
Mingri Technology
as the LLM judge, following previous research (Mo et al., 2025; Yuan et al., 2025; Du et al., 2026). Tool Simulation Fidelity.For each trace, we replay the recorded input parameters against the simulated tools and compare the resulting response to the real one. Because boolean status flags are unreliable (a real server may return a wrapper-level success w...
2025
-
[13]
Key Steps
Instructions-ToolChains-Context Alignment Annotation Core Objective Ensure strict semantic consistency among the natural language instruction, decoupled context, and ground-truth tool chain, forming a coherent, solvable, and unambiguous personalized task. Key Steps
-
[14]
2.Instruction Optimization: • Increase task difficulty (e.g., scale query quantities)
Task Selection:Pick tasks with clear structure and logical tool chains from the candidate dataset, prioritizing those with linear dependencies. 2.Instruction Optimization: • Increase task difficulty (e.g., scale query quantities). • Refine the instruction structure to align with real usage scenarios. 3.Context Refinement: • Minimize necessary context: Rem...
-
[15]
Execution-Based-GT Annotation Core Objective Annotate ground-truth (GT) data to support execution-based evaluation, enabling accurate assessment of the agent’s ability to complete personalized tasks. Annotation Categories & Requirements GT is formatted as a list of checkpoints, with four checkpoint types: 1.Generic Search: • Definition: Web searches using...
-
[16]
•save context(path, data): Save context to JSON with indentation
Module Functions (Must implement all): •load context(path): Dict. •save context(path, data): Save context to JSON with indentation. 18 MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation •get entity by path(data, path, id): Retrieve specific entities. •list entities by path(data, path, filters, limit): Suppo...
-
[17]
•Rule:Parse brackets[...]FIRST to extract selectors, THEN split by.outside brackets
Path Parsing Rules (CRITICAL): • Must handle IDs containing dots (e.g.,user.name@domain.com). •Rule:Parse brackets[...]FIRST to extract selectors, THEN split by.outside brackets. • Example: calendars[user.name].events→ Token 1: calendars / user.name, Token 2: events
-
[18]
• Apply filters for wildcard paths; use path-IDs as strict filters for specific paths
ID Generation & Filtering: • Analyze context structure to generate appropriate IDs (e.g., UUID for events, email-like for calendars). • Apply filters for wildcard paths; use path-IDs as strict filters for specific paths
-
[19]
Implementation Details (Parse Logic):You must implement the parse path function following this logic to ensure dot-containing IDs are handled correctly: def parse_path(path: str) -> List[PathToken]: tokens = [] i = 0 while i < len(path): if path[i] == ’.’: i += 1; continue # Logic to find segment end, handling nested brackets # ... (Implementation details...
-
[20]
success": bool,
Function Structure: • Function name MUST be:def analyze response patterns(parameters used): • Return format:{"success": bool, "error": str|None, "result": dict|None}
-
[21]
CONTEXT ID
Dynamic Context Handler Integration: • Import: from dynamic context handler import load context, save context, get/list/create/update/delete entity by path •Loading:Load context at start. Select specific context based onos.environ.get("CONTEXT ID"). •Persisting:After ANY modification (Create/Update/Delete), you MUST callsave context
-
[22]
Validate references first
Tool Operation Logic: •List Tools:Uselist entities by path. Validate references first. Use large limit for pagination. •Create Tools:Usecreate entity by path. Validate parent entities exist (e.g., calendar id). •Update/Delete Tools:Validate entity existence before modification
-
[23]
• Reference Check:Use get entity by path to verify that referenced IDs (calendar IDs, folder IDs) actually exist in the current context context
Input & Reference Validation (CRITICAL): • Validate input format (required fields, types). • Reference Check:Use get entity by path to verify that referenced IDs (calendar IDs, folder IDs) actually exist in the current context context. • Handle special keywords like “primary” by resolving them against the context
-
[24]
• Failure: Return specific error messages in the error field
Response Format: • Success: Match the tool’s expected JSON structure (from examples). • Failure: Return specific error messages in the error field. OUTPUT RULES: • Generate ONLY the Python code. • The code must be ready to execute without markdown formatting. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.