HERO'S JOURNEY: Testing Complex Rule Induction with Text Games
Pith reviewed 2026-06-28 14:48 UTC · model grok-4.3
The pith
Large language models show evidence of rule induction in text games but remain limited and uneven, with execution as a bottleneck.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
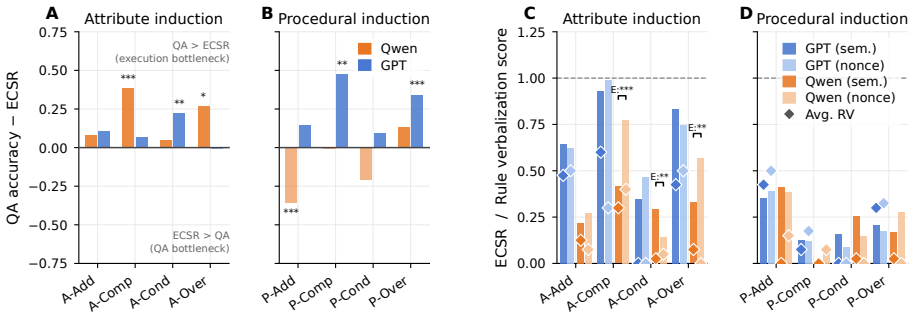
Models show evidence of rule induction from demonstrations in episodic text game tasks, yet this ability remains limited and varies unevenly across the eight tasks in the benchmark. Process execution introduces an execution bottleneck, while surface semantics has minimal effect on performance. Induction-specific steering improves results on attribute induction tasks but yields no reliable gains on procedural tasks.
What carries the argument
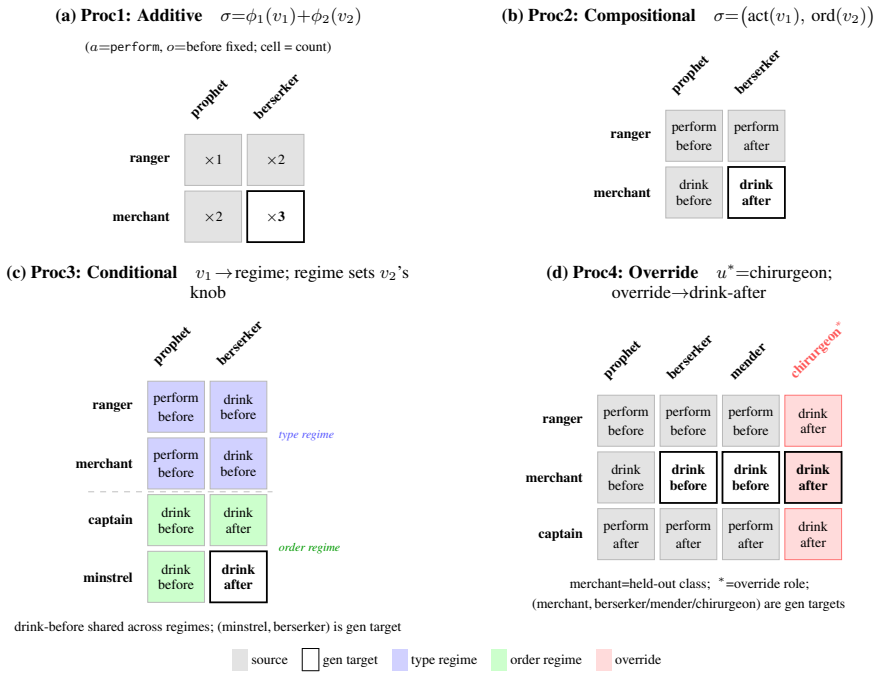
HERO'S JOURNEY benchmark of eight tasks across attribute and procedural induction families, each with four structural rule forms, controllable lexical grounding, and identifiability conditions.
If this is right
- Models that induce rules from demonstrations could generalize across new goal-directed scenarios within the same task families.
- The execution bottleneck implies that even correctly induced rules do not guarantee successful multi-step application.
- Steering methods effective only on attribute tasks indicate that procedural rule induction requires distinct techniques.
- Minimal effect of surface semantics suggests models rely primarily on structural patterns rather than lexical cues.
- The gap in procedural induction remains an open challenge for improving model performance on sequence-based rules.
Where Pith is reading between the lines
- The benchmark design could be adapted to test rule induction in partially observable or multi-agent text environments.
- Persistent procedural gaps may constrain AI agents that must chain actions in planning or game-like settings.
- Identifiability conditions could inform construction of training curricula that strengthen rule extraction in LLMs.
- Results on steering suggest hybrid methods combining induction with explicit execution planning merit further tests.
Load-bearing premise
The eight tasks and their identifiability conditions isolate rule induction ability without confounding effects from prompting format, game length, or lexical choice.
What would settle it
If models achieve equal performance on procedural and attribute tasks when rules are induced from demonstrations, or if execution accuracy matches induction accuracy once rules are known, the claimed execution bottleneck and uneven induction would be undermined.
Figures


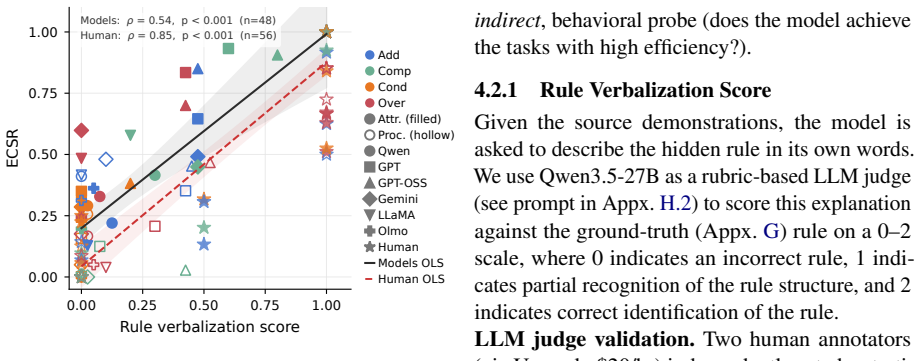
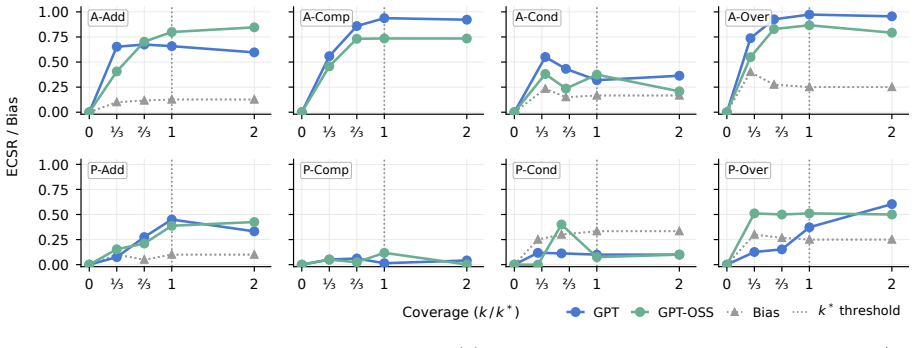
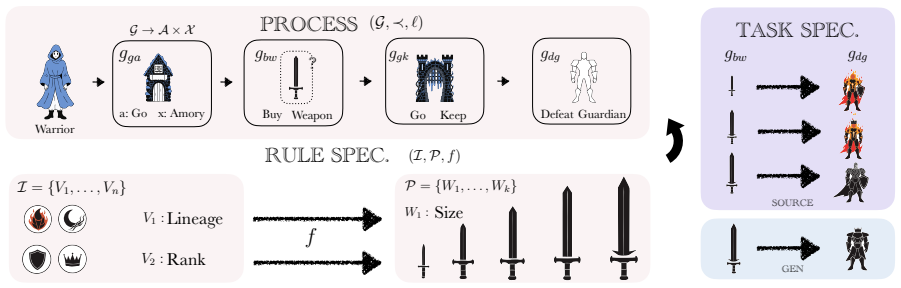
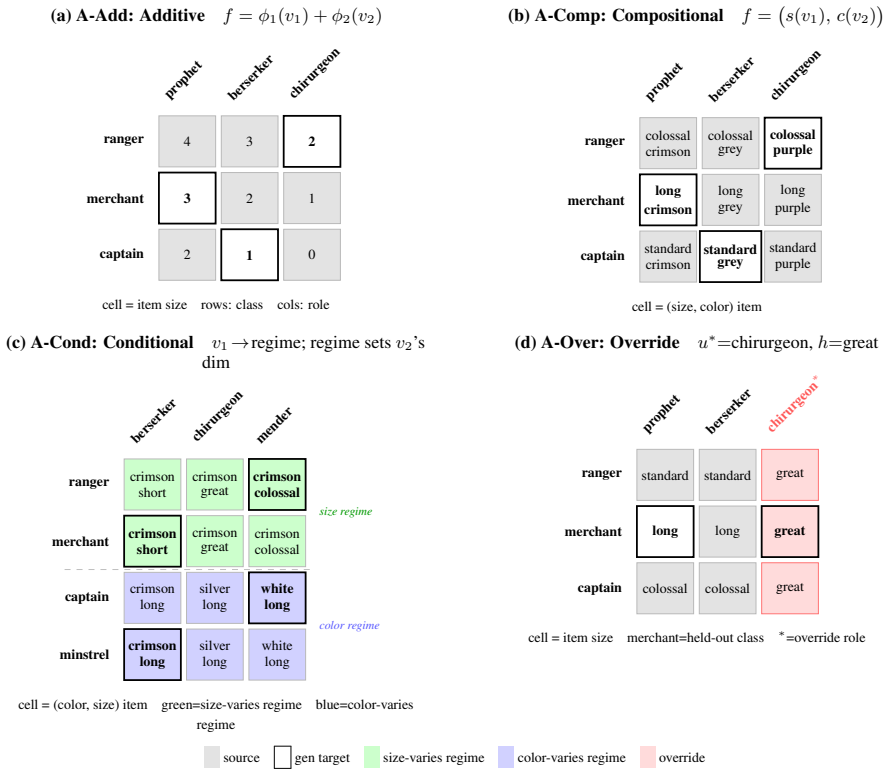


read the original abstract
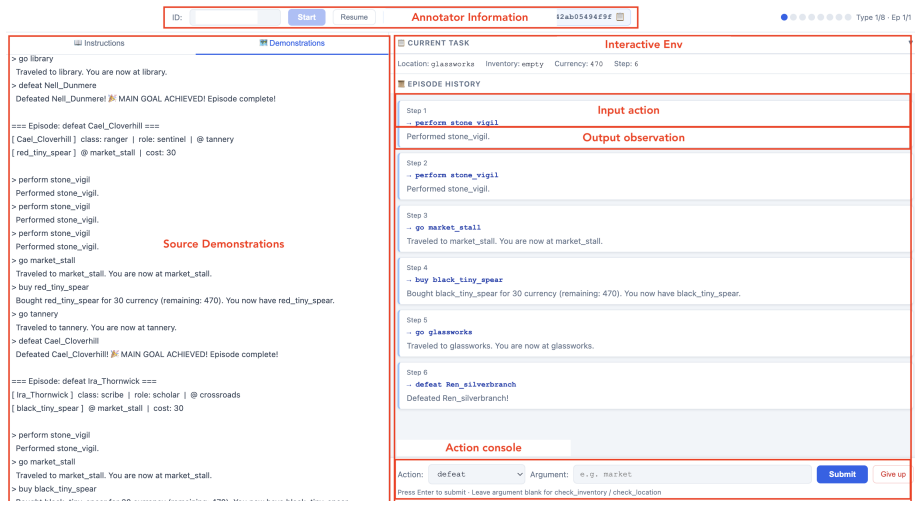
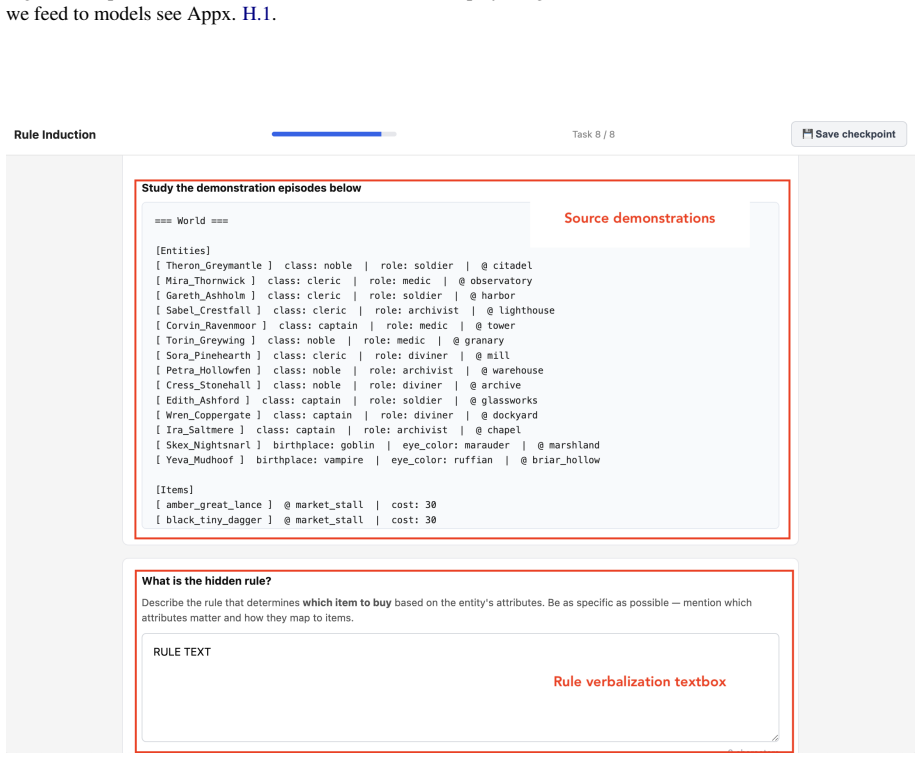
We introduce HERO'S JOURNEY, a benchmark for rule induction in goal-directed episodic tasks, where agents must infer hidden rules from demonstrations and act on them through multi-step execution. HERO'S JOURNEY covers eight tasks across attribute and procedural induction families, each with four structural rule forms, controllable lexical grounding, and identifiability conditions. Evaluating state-of-the-art LLMs, we find that models show evidence of rule induction, but the ability is limited and uneven across tasks. Meanwhile, process execution adds an execution bottleneck for models, whereas surface semantics has minimal effect. Induction-specific steering methods improve performance on attribute tasks but show no reliable gains on procedural tasks, suggesting the gap in procedural induction remains an open challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the HERO'S JOURNEY benchmark for evaluating rule induction in LLMs via eight goal-directed episodic text-game tasks spanning attribute and procedural induction families. Each task includes four structural rule forms, controllable lexical grounding, and identifiability conditions. Evaluation of state-of-the-art models shows limited and uneven evidence of rule induction, with process execution as a bottleneck and minimal impact from surface semantics; induction-specific steering improves attribute tasks but yields no reliable gains on procedural tasks.
Significance. If the central empirical claims hold under the stated identifiability conditions, the benchmark offers a structured way to probe complex rule induction beyond surface patterns, with the distinction between attribute and procedural families and the steering results highlighting an open challenge in procedural induction. The design elements of controllable lexical grounding and multiple rule forms per task are positive features for systematic evaluation.
major comments (2)
- [Abstract] Abstract and the description of identifiability conditions: the central claim that performance differences can be attributed to rule induction (rather than prompting format, episode length, or lexical choice) rests on the assertion that the eight tasks plus identifiability conditions isolate the target construct; however, the manuscript provides no explicit ablations or quantitative checks demonstrating that these variables were held constant or shown to be inert, leaving the attribution of 'limited and uneven' induction and 'minimal effect' of surface semantics unsecured.
- [Abstract] Abstract, results on steering methods: the differential effect (gains on attribute tasks, none on procedural) is load-bearing for the conclusion that 'the gap in procedural induction remains an open challenge,' yet without reported statistical tests, error analysis, or controls confirming that the steering interventions were applied identically across families, the unevenness cannot be confidently localized to induction ability versus execution or prompting confounds.
minor comments (1)
- The abstract refers to 'four structural rule forms' per task without enumerating or exemplifying them; adding a brief table or figure in the main text would improve clarity on how these forms vary across the attribute/procedural families.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address the major comments point by point below and will make the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of identifiability conditions: the central claim that performance differences can be attributed to rule induction (rather than prompting format, episode length, or lexical choice) rests on the assertion that the eight tasks plus identifiability conditions isolate the target construct; however, the manuscript provides no explicit ablations or quantitative checks demonstrating that these variables were held constant or shown to be inert, leaving the attribution of 'limited and uneven' induction and 'minimal effect' of surface semantics unsecured.
Authors: We agree that explicit ablations would provide stronger evidence that the identifiability conditions effectively isolate rule induction from confounds such as prompting format, episode length, and lexical choice. The manuscript describes the design elements intended to achieve this isolation, including controllable lexical grounding and the four structural rule forms. However, we acknowledge the absence of quantitative checks or ablations in the current version. In the revised manuscript, we will add ablations and analyses to verify that these variables are inert under the stated conditions. revision: yes
-
Referee: [Abstract] Abstract, results on steering methods: the differential effect (gains on attribute tasks, none on procedural) is load-bearing for the conclusion that 'the gap in procedural induction remains an open challenge,' yet without reported statistical tests, error analysis, or controls confirming that the steering interventions were applied identically across families, the unevenness cannot be confidently localized to induction ability versus execution or prompting confounds.
Authors: We concur that statistical tests and additional controls are important to support the differential effects observed with steering methods. The current results indicate gains on attribute tasks but no reliable gains on procedural tasks. To address this, the revised version will include statistical significance tests, error analyses, and explicit confirmation that steering interventions were applied consistently across the attribute and procedural families. This will help localize the effects more confidently. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivation chain
full rationale
The paper introduces an empirical benchmark (HERO'S JOURNEY) consisting of eight tasks for evaluating LLM rule induction in text games, reports model performance results, and discusses effects of execution bottlenecks and surface semantics. No equations, fitted parameters, predictions derived from inputs, or mathematical derivations are present. The central claims rest on experimental measurements against external model evaluations rather than any self-referential reduction, self-citation chain, or ansatz smuggled via prior work. Identifiability conditions are design choices for the benchmark tasks, not a derivation that collapses to its own inputs. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R
Carlos E. Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R. Narasimhan , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[2]
Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[7]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[8]
Lake and Marco Baroni , editor =
Brenden M. Lake and Marco Baroni , editor =. Proceedings of the 35th International Conference on Machine Learning,. 2018 , url =
2018
-
[9]
Measuring Compositional Generalization:
Daniel Keysers and Nathanael Sch. Measuring Compositional Generalization:. 8th International Conference on Learning Representations,. 2020 , url =
2020
-
[11]
Lake , editor =
Laura Ruis and Jacob Andreas and Marco Baroni and Diane Bouchacourt and Brenden M. Lake , editor =. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[12]
The Thirteenth International Conference on Learning Representations,
Jiachun Li and Pengfei Cao and Zhuoran Jin and Yubo Chen and Kang Liu and Jun Zhao , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[13]
7th International Conference on Learning Representations,
Maxime Chevalier. 7th International Conference on Learning Representations,. 2019 , url =
2019
-
[15]
The Twelfth International Conference on Learning Representations,
Linlu Qiu and Liwei Jiang and Ximing Lu and Melanie Sclar and Valentina Pyatkin and Chandra Bhagavatula and Bailin Wang and Yoon Kim and Yejin Choi and Nouha Dziri and Xiang Ren , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[17]
Jerry A. Fodor and Zenon W. Pylyshyn , abstract =. Cognition , volume =. 1988 , issn =. doi:https://doi.org/10.1016/0010-0277(88)90031-5 , url =
-
[20]
2026 , eprint=
A Survey of Inductive Reasoning for Large Language Models , author=. 2026 , eprint=
2026
-
[21]
2019 , eprint=
On the Measure of Intelligence , author=. 2019 , eprint=
2019
-
[22]
Nature Communications , author =. 2024 , pages =. doi:10.1038/s41467-024-50966-x , abstract =
-
[24]
Honovich, Or and Shaham, Uri and Bowman, Samuel R. and Levy, Omer. Instruction Induction: From Few Examples to Natural Language Task Descriptions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.108
-
[25]
2026 , url=
Qizheng Zhang and Changran Hu and Shubhangi Upasani and Boyuan Ma and Fenglu Hong and Vamsidhar Kamanuru and Jay Rainton and Chen Wu and Mengmeng Ji and Hanchen Li and Urmish Thakker and James Zou and Kunle Olukotun , booktitle=. 2026 , url=
2026
-
[29]
2014 , url=
Kemp, Charles and Jern, Alan , journal=. 2014 , url=
2014
-
[30]
Rogers, Timothy T. and McClelland, James L. , title =. 2004 , month =. doi:10.7551/mitpress/6161.001.0001 , url =
-
[31]
Psychological Review , number =
Sudeep Bhatia and Russell Richie , doi =. Psychological Review , number =
-
[32]
2025 , eprint=
On Language Models' Sensitivity to Suspicious Coincidences , author=. 2025 , eprint=
2025
-
[34]
Psychological Review , number =
Sudeep Bhatia , doi =. Psychological Review , number =
-
[35]
2022 , volume=
Kanishka Misra and Julia Rayz and Allyson Ettinger , booktitle=. 2022 , volume=
2022
-
[36]
Rule, Joshua Stewart , year=
-
[37]
Sudeep Bhatia. 2024. https://doi.org/10.1037/rev0000446 Inductive Reasoning in Minds and Machines . Psychological Review, 131(6):1373--1391
-
[38]
Kedi Chen, Dezhao Ruan, Yuhao Dan, Yaoting Wang, Siyu Yan, Xuecheng Wu, Yinqi Zhang, Qin Chen, Jie Zhou, Liang He, Biqing Qi, Linyang Li, Qipeng Guo, Xiaoming Shi, and Wei Zhang. 2026. https://arxiv.org/abs/2510.10182 A survey of inductive reasoning for large language models . Preprint, arXiv:2510.10182
Pith/arXiv arXiv 2026
-
[39]
Maxime Chevalier - Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. 2019. https://openreview.net/forum?id=rJeXCo0cYX BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning . In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, Ma...
2019
-
[40]
François Chollet. 2019. https://arxiv.org/abs/1911.01547 On the measure of intelligence . Preprint, arXiv:1911.01547
Pith/arXiv arXiv 2019
-
[41]
Hausknecht, Layla El Asri, Mahmoud Adada, Wendy Tay, and Adam Trischler
Marc - Alexandre C \^ o t \' e , \' A kos K \' a d \' a r, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew J. Hausknecht, Layla El Asri, Mahmoud Adada, Wendy Tay, and Adam Trischler. 2018. https://doi.org/10.1007/978-3-030-24337-1\_3 TextWorld: A Learning Environment for Text-Based Games . In Computer Games - 7th Workshop, CGW 2...
-
[42]
Ransom, Andrew Perfors, and Charles Kemp
Simon Jerome Han, Keith J. Ransom, Andrew Perfors, and Charles Kemp. 2024. https://doi.org/10.1016/j.cogsys.2023.101155 Inductive reasoning in humans and large language models . Cognitive Systems Research, 83:101155
-
[43]
Hausknecht, Prithviraj Ammanabrolu, Marc - Alexandre C \^ o t \' e , and Xingdi Yuan
Matthew J. Hausknecht, Prithviraj Ammanabrolu, Marc - Alexandre C \^ o t \' e , and Xingdi Yuan. 2020. https://doi.org/10.1609/AAAI.V34I05.6297 Interactive Fiction Games: A Colossal Adventure . In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2...
-
[44]
Brett K. Hayes and Evan Heit. 2018. https://doi.org/10.1002/wcs.1459 Inductive reasoning 2.0 . WIREs Cognitive Science, 9(3):e1459
-
[45]
Kaiyu He, Mian Zhang, Shuo Yan, Peilin Wu, and Zhiyu Chen. 2025. https://doi.org/10.18653/v1/2025.findings-acl.698 IDEA : Enhancing the Rule Learning Ability of Large Language Model Agent through Induction, Deduction, and Abduction . In Findings of the Association for Computational Linguistics: ACL 2025, pages 13563--13597, Vienna, Austria. Association fo...
-
[46]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. https://openreview.net/forum?id=VTF8yNQM66 SWE-bench: Can Language Models Resolve Real-world Github Issues? In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[47]
Charles Kemp and Alan Jern. 2014. https://doi.org/10.3758/s13423-013-0467-3 A taxonomy of inductive problems . Psychonomic Bulletin & Review, 21(1):23--46
-
[48]
Daniel Keysers, Nathanael Sch \" a rli, Nathan Scales, Hylke Buisman, Daniel Furrer, Sergii Kashubin, Nikola Momchev, Danila Sinopalnikov, Lukasz Stafiniak, Tibor Tihon, Dmitry Tsarkov, Xiao Wang, Marc van Zee, and Olivier Bousquet. 2020. https://openreview.net/forum?id=SygcCnNKwr Measuring compositional generalization: A comprehensive method on Realistic...
2020
-
[49]
Najoung Kim and Tal Linzen. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.731 COGS : A Compositional Generalization Challenge Based on Semantic Interpretation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9087--9105, Online. Association for Computational Linguistics
-
[50]
Lake and Marco Baroni
Brenden M. Lake and Marco Baroni. 2018. http://proceedings.mlr.press/v80/lake18a.html Generalization without Systematicity: On the Compositional Skills of Sequence-to-Sequence Recurrent Networks . In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsm \" a ssan, Stockholm, Sweden, July 10-15, 2018 , Proceedings of ...
2018
-
[51]
Lake, Ruslan Salakhutdinov, and Joshua B
Brenden M. Lake, Ruslan Salakhutdinov, and Joshua B. Tenenbaum. 2015. https://doi.org/10.1126/science.aab3050 Human-level concept learning through probabilistic program induction . Science, 350(6266):1332--1338
-
[52]
Kang-il Lee, Hyukhun Koh, Dongryeol Lee, Seunghyun Yoon, Minsung Kim, and Kyomin Jung. 2025. https://doi.org/10.18653/v1/2025.naacl-long.429 Generating Diverse Hypotheses for Inductive Reasoning . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volu...
-
[53]
Jiachun Li, Pengfei Cao, Zhuoran Jin, Yubo Chen, Kang Liu, and Jun Zhao. 2025. https://openreview.net/forum?id=tZCqSVncRf MIRAGE: evaluating and explaining inductive reasoning process in Language Models . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net
2025
-
[54]
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. 2026. https://doi.org/10.1038/s41586-026-10265-5 Towards end-to-end automation of AI research . Nature, 651(8107):914--919
-
[55]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.759 Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11048--11064, Abu Dhabi,...
-
[56]
Kanishka Misra, Julia Rayz, and Allyson Ettinger. 2022. https://escholarship.org/uc/item/6170h6nj A Property Induction Framework for Neural Language Models . In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 44
2022
-
[57]
Daniel N. Osherson, Edward E. Smith, Ormond Wilkie, and Alejandro L\' o pez. 1990. https://doi.org/10.1037/0033-295x.97.2.185 Category-based induction . Psychological Review, 97(2):185--200
-
[58]
Sriram Padmanabhan, Kanishka Misra, Kyle Mahowald, and Eunsol Choi. 2025. https://arxiv.org/abs/2504.09387 On language models' sensitivity to suspicious coincidences . Preprint, arXiv:2504.09387
arXiv 2025
-
[59]
Linlu Qiu, Liwei Jiang, Ximing Lu, Melanie Sclar, Valentina Pyatkin, Chandra Bhagavatula, Bailin Wang, Yoon Kim, Yejin Choi, Nouha Dziri, and Xiang Ren. 2024. https://openreview.net/forum?id=bNt7oajl2a Phenomenal yet puzzling: Testing inductive reasoning capabilities of language models with hypothesis refinement . In The Twelfth International Conference o...
2024
-
[60]
Laura Ruis, Jacob Andreas, Marco Baroni, Diane Bouchacourt, and Brenden M. Lake. 2020. https://proceedings.neurips.cc/paper/2020/hash/e5a90182cc81e12ab5e72d66e0b46fe3-Abstract.html A Benchmark for Systematic Generalization in Grounded Language Understanding . In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information ...
2020
-
[61]
Joshua Stewart Rule. 2020. https://dspace.mit.edu/entities/publication/5af05170-125e-401d-a8b7-fe1437468356 The child as hacker: building more human-like models of learning . Ph.D. thesis, Massachusetts Institute of Technology
2020
-
[62]
S.A. Sloman. 1993. https://doi.org/10.1006/cogp.1993.1006 Feature-Based Induction . Cognitive Psychology, 25(2):231--280
-
[63]
Tenenbaum, Charles Kemp, Thomas L
Joshua B. Tenenbaum, Charles Kemp, Thomas L. Griffiths, and Noah D. Goodman. 2011. https://doi.org/10.1126/science.1192788 How to Grow a Mind: Statistics, Structure, and Abstraction . Science, 331(6022):1279--1285
-
[64]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. https://openreview.net/forum?id=WE\_vluYUL-X ReAct: Synergizing Reasoning and Acting in Language Models . In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net
2023
-
[65]
Chi Zhang, Baoxiong Jia, Mark Edmonds, Song - Chun Zhu, and Yixin Zhu. 2021. https://doi.org/10.1109/CVPR46437.2021.01050 ACRE: Abstract Causal REasoning Beyond Covariation . In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021 , pages 10643--10653. Computer Vision Foundation / IEEE
-
[66]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. 2026. https://openreview.net/forum?id=eC4ygDs02R Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models . In The Fourteenth International Confere...
2026
-
[67]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. https://openreview.net/forum?id=oKn9c6ytLx WebArena: A Realistic Web Environment for Building Autonomous Agents . In The Twelfth International Conference on Learning Representations, ICLR 2024,...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.