From Zero to Hero: Training-Free Custom Concept Spawning in World Models
Pith reviewed 2026-06-28 15:09 UTC · model grok-4.3
The pith
Existing autoregressive world models support controllable concept spawning without training by temporarily swapping their pinned context memory anchor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
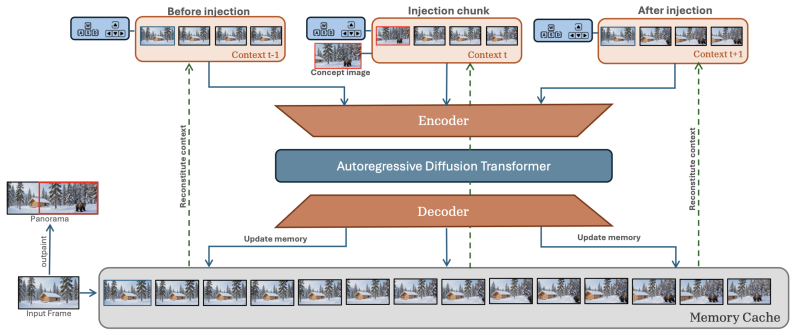
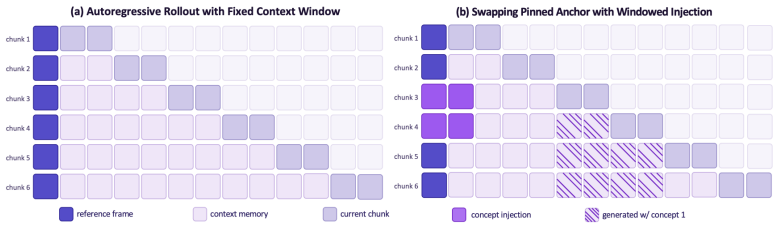
SPAWN enables concept spawning in autoregressive world models by swapping the pinned first slot of the context memory with an external concept latent over a short injection window and letting the original anchor return, which causes the concept to propagate naturally through subsequent rollouts via the model's own memory mechanism, achieving consistent integration of user-specified elements without any training.
What carries the argument
SPAWN (Swapping Pinned Anchor with Windowed iNjection), the temporary replacement of the foundational anchor slot in context memory that lets an external concept latent propagate through the model's generation process.
If this is right
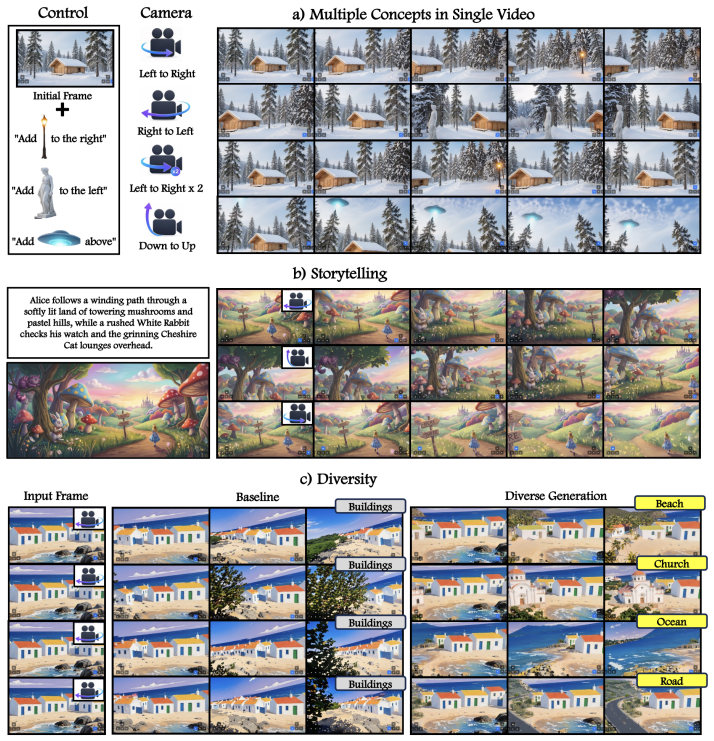
- User-specified concepts integrate into generated worlds with consistent lighting, scale, and perspective.
- Both fine-grained entities like characters and large-scale elements like buildings can be spawned from either image or text input.
- Identity and temporal coherence are preserved across rollouts without retraining the base model.
- The approach works in existing autoregressive world models by relying on their built-in memory structure.
- Controllable scene composition becomes possible for applications such as gaming and interactive storytelling.
Where Pith is reading between the lines
- The same memory-swap pattern could be tested on other autoregressive video models that use similar context anchoring.
- Combining multiple sequential injections might allow dynamic changes to scene elements during a single long rollout.
- The method's reliance on short injection windows suggests it could pair with action-conditioned generation to let concepts respond to user controls.
- Extending the injection to multiple slots might support spawning several independent concepts at once.
Load-bearing premise
The first slot of the context memory functions as a pinned foundational anchor whose temporary replacement with an external concept latent will cause the concept to propagate naturally through subsequent rollouts via the model's own memory mechanism.
What would settle it
Generate a sequence of frames after the injection window closes and check whether the user-specified concept appears in newly generated regions with matching lighting and scale; consistent failure to appear or maintain properties would show the propagation does not occur.
Figures









read the original abstract
Autoregressive world models have emerged as a powerful paradigm for interactive video generation, allowing users to navigate dynamically generated environments through actions. These models are typically conditioned on a text prompt and/or a single reference frame, from which the entire world is generated. Yet the moment the user navigates beyond what is visible in that frame, the unseen regions are populated by the base model's priors, with no mechanism for the user to specify what should appear and where. This is a fundamental limitation for applications such as gaming, interactive storytelling, and simulation, where controllable scene composition is essential. We refer to this missing capability as concept spawning; introducing a user-specified visual concept into a world model, analogous to spawning in a game engine. We introduce SPAWN (Swapping Pinned Anchor with Windowed iNjection), a training-free method for concept spawning. SPAWN exploits a structural property of image-to-video backbones: the first slot of the context memory is pinned to the reference frame and acts as a foundational anchor for every generated chunk. By swapping this anchor with an external concept latent over a short injection window and letting the original anchor return, we cause the concept to propagate naturally through the rollout via the model's own memory. SPAWN supports concepts from fine-grained entities such as characters and props to large-scale elements such as buildings and landmarks, and accepts either a concept image or a text description as input. Experiments show that SPAWN integrates concepts with consistent lighting, scale, and perspective while preserving identity and temporal coherence, demonstrating that controllable concept spawning is achievable in existing autoregressive world models without any training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SPAWN (Swapping Pinned Anchor with Windowed iNjection), a training-free method for custom concept spawning in autoregressive image-to-video world models. It exploits the structural property that the first slot of the context memory is pinned to the reference frame, temporarily swapping it with an external concept latent (from image or text) over a short injection window so that the concept propagates through subsequent rollouts via the model's own memory mechanism. The central claim is that this enables integration of user-specified concepts (entities, props, buildings) with consistent lighting, scale, perspective, identity, and temporal coherence without any training or fine-tuning.
Significance. If the claims hold, the work is significant because it shows that controllable scene composition can be added to existing autoregressive world models by leveraging an already-present structural property rather than requiring new training or architectural changes. This directly addresses a practical limitation for interactive applications such as gaming and simulation. The training-free nature and support for both image and text concept inputs are clear strengths; the method is presented as a direct manipulation rather than a fitted or derived quantity.
major comments (2)
- [Experiments] Experiments section: the paper claims consistent integration with respect to lighting, scale, perspective, identity, and temporal coherence, yet provides no quantitative metrics (e.g., identity preservation scores, temporal consistency measures, or comparisons against baselines), ablation studies on injection-window length, or reported failure cases. Without these, it is difficult to assess whether the qualitative examples generalize or whether post-hoc selection occurred.
- [Method] Method description (paragraph on the pinned-anchor property): the assumption that temporarily replacing the first context slot causes reliable propagation through the model's memory is central to the claim, but the manuscript does not specify how the injection window length is determined or provide evidence that the original anchor reliably returns without residual artifacts after the window closes.
minor comments (2)
- [Abstract] The acronym SPAWN is introduced without an explicit expansion in the abstract; a parenthetical expansion on first use would improve readability.
- [Figures] Figure captions should explicitly state whether the shown rollouts are single examples or representative of multiple runs, and whether any post-processing was applied.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for strengthening the presentation of SPAWN. We respond to each major comment below.
read point-by-point responses
-
Referee: Experiments section: the paper claims consistent integration with respect to lighting, scale, perspective, identity, and temporal coherence, yet provides no quantitative metrics (e.g., identity preservation scores, temporal consistency measures, or comparisons against baselines), ablation studies on injection-window length, or reported failure cases. Without these, it is difficult to assess whether the qualitative examples generalize or whether post-hoc selection occurred.
Authors: We agree that the current experiments section relies on qualitative results. While these demonstrate the core capability, quantitative evaluation would improve rigor. In revision we will add CLIP-based identity preservation, optical-flow temporal consistency scores, and an ablation study on injection-window length (e.g., 1–8 frames). We will also document observed failure modes such as lighting drift on highly textured concepts. These additions will be included in the revised manuscript. revision: yes
-
Referee: Method description (paragraph on the pinned-anchor property): the assumption that temporarily replacing the first context slot causes reliable propagation through the model's memory is central to the claim, but the manuscript does not specify how the injection window length is determined or provide evidence that the original anchor reliably returns without residual artifacts after the window closes.
Authors: The injection window is set to 3–5 frames, chosen to match the model’s typical context-chunk size while allowing the external latent to propagate before the pinned anchor is restored. We will add this explicit rule and the corresponding pseudocode in the revised method section. Visual evidence that the original anchor returns without persistent artifacts is present in the supplementary rollouts; we will highlight these frames and add a short quantitative check (anchor cosine similarity before/after injection) to substantiate the claim. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes SPAWN as a direct manipulation of an observed structural property (pinned first context slot in autoregressive image-to-video models) without any equations, fitted parameters, or derived quantities. The core mechanism is presented as an exploitation of existing model behavior rather than a result obtained from the paper's own outputs or self-citations. No load-bearing steps reduce to self-definition, fitted inputs renamed as predictions, or imported uniqueness theorems. The claim remains self-contained against the described experiments on consistency.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The first slot of the context memory remains pinned to the reference frame and serves as a foundational anchor for every generated chunk.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.08774 (2023)
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2311.15127 (2023)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
Pith/arXiv arXiv 2023
-
[3]
In: Forty-first International Conference on Machine Learning (2024)
Bruce, J., Dennis, M.D., Edwards, A., Parker-Holder, J., Shi, Y ., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., et al.: Genie: Generative interactive environments. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[4]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ceylan, D., Huang, C.H.P., Mitra, N.J.: Pix2video: Video editing using image diffusion. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 23206–23217 (2023)
2023
-
[5]
arXiv preprint arXiv:2411.00769 (2024)
Che, H., He, X., Liu, Q., Jin, C., Chen, H.: Gamegen-x: Interactive open-world game video generation. arXiv preprint arXiv:2411.00769 (2024)
arXiv 2024
-
[6]
Advances in Neural Information Processing Systems37, 24081–24125 (2024)
Chen, B., Martí Monsó, D., Du, Y ., Simchowitz, M., Tedrake, R., Sitzmann, V .: Diffusion forcing: Next-token prediction meets full-sequence diffusion. Advances in Neural Information Processing Systems37, 24081–24125 (2024)
2024
-
[7]
arXiv preprint arXiv:2307.04725 (2023)
Guo, Y ., Yang, C., Rao, A., Liang, Z., Wang, Y ., Qiao, Y ., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
Pith/arXiv arXiv 2023
-
[8]
arXiv preprint arXiv:2508.13009 (2025)
He, X., Peng, C., Liu, Z., Wang, B., Zhang, Y ., Cui, Q., Kang, F., Jiang, B., An, M., Ren, Y ., et al.: Matrix-game 2.0: An open-source real-time and streaming interactive world model. arXiv preprint arXiv:2508.13009 (2025)
Pith/arXiv arXiv 2025
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Henschel, R., Khachatryan, L., Poghosyan, H., Hayrapetyan, D., Tadevosyan, V ., Wang, Z., Navasardyan, S., Shi, H.: Streamingt2v: Consistent, dynamic, and extendable long video gener- ation from text. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2568–2577 (2025)
2025
-
[10]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[11]
Advances in neural information processing systems35, 8633–8646 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Advances in neural information processing systems35, 8633–8646 (2022)
2022
-
[12]
arXiv preprint arXiv:2506.08009 (2025)
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
Pith/arXiv arXiv 2025
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Huang, Z., He, Y ., Yu, J., Zhang, F., Si, C., Jiang, Y ., Zhang, Y ., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y ., Chen, X., Wang, L., Lin, D., Qiao, Y ., Liu, Z.: VBench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[14]
Huang, Z., Zhang, F., Xu, X., He, Y ., Yu, J., Dong, Z., Ma, Q., Chanpaisit, N., Si, C., Jiang, Y ., Wang, Y ., Chen, X., Chen, Y .C., Wang, L., Lin, D., Qiao, Y ., Liu, Z.: VBench++: Comprehensive and versatile benchmark suite for video generative models. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025). https://doi.org/10.1109/TPAMI...
-
[15]
Advances in Neural Information Processing Systems37, 89834–89868 (2024)
Kim, J., Kang, J., Choi, J., Han, B.: Fifo-diffusion: Generating infinite videos from text without training. Advances in Neural Information Processing Systems37, 89834–89868 (2024)
2024
-
[16]
arXiv preprint arXiv:2412.03603 (2024)
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
Pith/arXiv arXiv 2024
-
[17]
arXiv preprint arXiv:2506.172012(3), 6 (2025)
Li, J., Tang, J., Xu, Z., Wu, L., Zhou, Y ., Shao, S., Yu, T., Cao, Z., Lu, Q.: Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition. arXiv preprint arXiv:2506.172012(3), 6 (2025)
arXiv 2025
-
[18]
arXiv preprint arXiv:2507.10496 (2025)
Li, R., Yi, B., Liu, J., Gao, H., Ma, Y ., Kanazawa, A.: Cameras as relative positional encoding. arXiv preprint arXiv:2507.10496 (2025)
arXiv 2025
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, R., Torr, P., Vedaldi, A., Jakab, T.: Vmem: Consistent interactive video scene generation with surfel-indexed view memory. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 25690–25699 (2025)
2025
-
[20]
arXiv preprint arXiv:2509.25161 (2025)
Liu, K., Hu, W., Xu, J., Shan, Y ., Lu, S.: Rolling forcing: Autoregressive long video diffusion in real time. arXiv preprint arXiv:2509.25161 (2025)
Pith/arXiv arXiv 2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, S., Zhang, Y ., Li, W., Lin, Z., Jia, J.: Video-p2p: Video editing with cross-attention control. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8599–8608 (2024)
2024
-
[22]
arXiv preprint arXiv:2507.17744 (2025)
Mao, X., Lin, S., Li, Z., Li, C., Peng, W., He, T., Pang, J., Chi, M., Qiao, Y ., Zhang, K.: Yume: An interactive world generation model. arXiv preprint arXiv:2507.17744 (2025)
arXiv 2025
-
[23]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[24]
arXiv preprint arXiv:2603.06591 (2026)
Peng, R., Li, R., Chen, M., Zhou, Y ., Guo, Q., Qiu, X.: How attention sinks emerge in large language models: An interpretability perspective. arXiv preprint arXiv:2603.06591 (2026)
arXiv 2026
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qi, C., Cun, X., Zhang, Y ., Lei, C., Wang, X., Shan, Y ., Chen, Q.: Fatezero: Fusing attentions for zero-shot text-based video editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15932–15942 (2023)
2023
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[27]
arXiv preprint arXiv:2011.13456 (2020)
Song, Y ., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
Pith/arXiv arXiv 2011
-
[28]
arXiv preprint arXiv:2512.14614 (2025)
Sun, W., Zhang, H., Wang, H., Wu, J., Wang, Z., Wang, Z., Wang, Y ., Zhang, J., Wang, T., Guo, C.: Worldplay: Towards long-term geometric consistency for real-time interactive world modeling. arXiv preprint arXiv:2512.14614 (2025)
Pith/arXiv arXiv 2025
-
[29]
arXiv preprint arXiv:2511.23429 (2025)
Tang, J., Liu, J., Li, J., Wu, L., Yang, H., Zhao, P., Gong, S., Yuan, X., Shao, S., Zhang, L., et al.: Hunyuan-gamecraft-2: Instruction-following interactive game world model. arXiv preprint arXiv:2511.23429 (2025)
arXiv 2025
-
[30]
arXiv preprint arXiv:2503.20314 (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
Pith/arXiv arXiv 2025
-
[31]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y ., Chen, Y ., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y ., Zhang, Y ., Zhu, Y ., Wu, Y ., Cai,...
Pith/arXiv arXiv 2025
-
[32]
arXiv (2023)
Xiao, G., Tian, Y ., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. arXiv (2023)
2023
-
[33]
arXiv preprint arXiv:2504.12369 (2025)
Xiao, Z., Lan, Y ., Zhou, Y ., Ouyang, W., Yang, S., Zeng, Y ., Pan, X.: Worldmem: Long-term consistent world simulation with memory. arXiv preprint arXiv:2504.12369 (2025)
arXiv 2025
-
[34]
arXiv preprint arXiv:2104.10157 (2021)
Yan, W., Zhang, Y ., Abbeel, P., Srinivas, A.: Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157 (2021)
Pith/arXiv arXiv 2021
-
[35]
arXiv preprint arXiv:2509.22622 (2025)
Yang, S., Huang, W., Chu, R., Xiao, Y ., Zhao, Y ., Wang, X., Li, M., Xie, E., Chen, Y ., Lu, Y ., et al.: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025)
Pith/arXiv arXiv 2025
-
[36]
arXiv preprint arXiv:2408.06072 (2024)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y ., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
Pith/arXiv arXiv 2024
-
[37]
arXiv preprint arXiv:2512.05081 (2025)
Yi, J., Jang, W., Cho, P.H., Nam, J., Yoon, H., Kim, S.: Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081 (2025)
arXiv 2025
-
[38]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Yu, J., Bai, J., Qin, Y ., Liu, Q., Wang, X., Wan, P., Zhang, D., Liu, X.: Context as memory: Scene-consistent interactive long video generation with memory retrieval. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–11 (2025)
2025
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yu, J., Qin, Y ., Wang, X., Wan, P., Zhang, D., Liu, X.: Gamefactory: Creating new games with generative interactive videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11590–11599 (2025)
2025
-
[40]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[41]
Zhang, Y ., Peng, C., Wang, B., Wang, P., Zhu, Q., Kang, F., Jiang, B., Gao, Z., Li, E., Liu, Y ., et al.: Matrix-game: Interactive world foundation model. arXiv preprint arXiv:2506.18701 (2025) 12 Table of Contents A Supplementary material 14 A.1 Experiment Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 A.2 Additional Qual...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.