Hallucination Is Linearly Decodable from Mid-Layer Hidden States in Quantized LLMs
Pith reviewed 2026-06-28 19:11 UTC · model grok-4.3
The pith
A linear probe on a single mid-network layer decodes hallucination from hidden states in quantized LLMs at 0.904-1.000 AUROC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
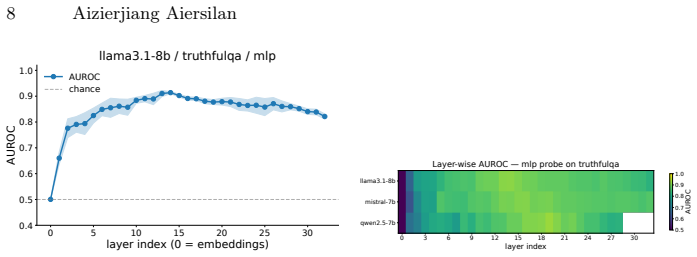
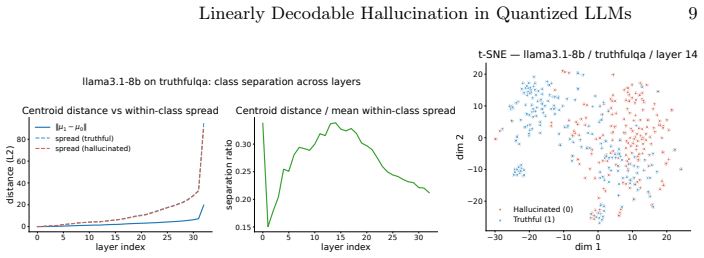
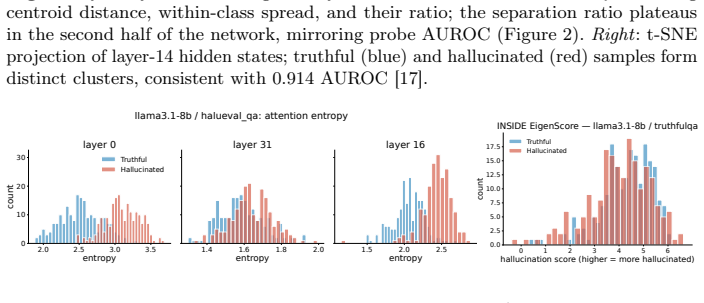
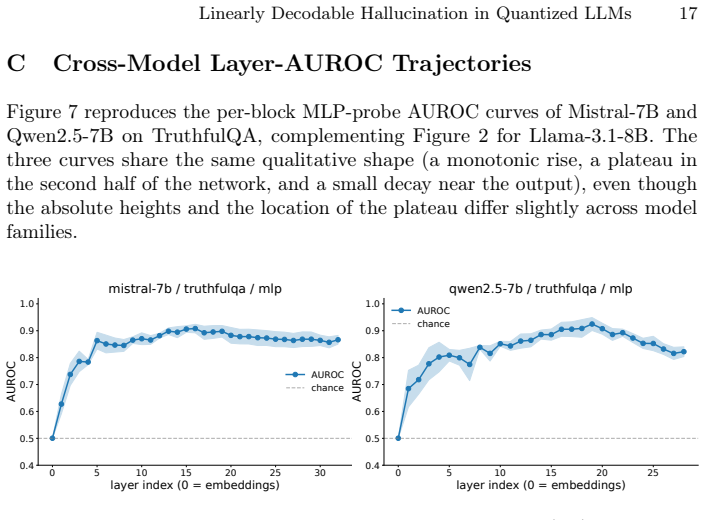
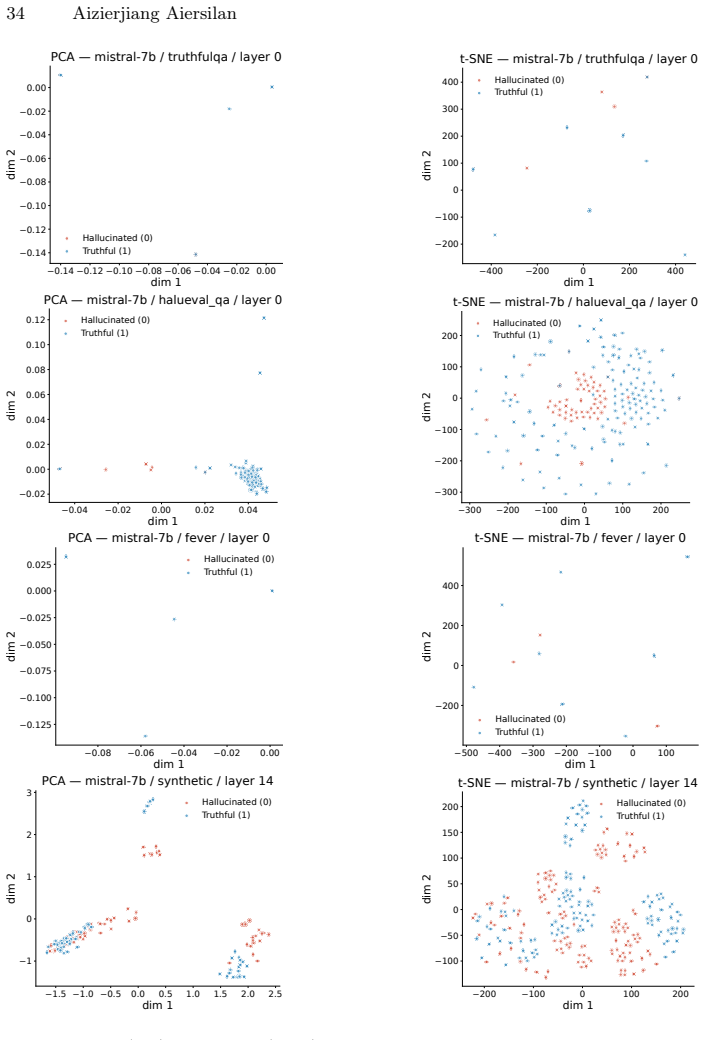
Across Llama-3.1-8B, Mistral-7B and Qwen2.5-7B in NF4 quantization, hidden states from a single mid-network layer (blocks 13-18 for Llama/Mistral, 19-25 for Qwen) allow a linear probe to achieve 0.904-1.000 AUROC for hallucination detection on held-out splits of TruthfulQA, HaluEval-QA, FEVER and a synthetic set, while sampling-based detectors remain below 0.541 AUROC; MLP probes add at most 0.01 AUROC and first-block attention entropy supplies a complementary zero-cost signal on knowledge-grounded tasks.
What carries the argument
Linear probe applied to per-layer hidden states, which extracts an approximately linear truthfulness signal whose strength peaks in a consistent mid-network band.
If this is right
- Detection requires only one forward pass plus a fixed linear classifier at a known layer.
- The location of the strongest signal remains stable across model families on natural-language benchmarks.
- Nonlinear probes add negligible value, confirming the signal is already linear.
- Attention entropy at the first block supplies an orthogonal signal at no added cost on knowledge tasks.
- Sampling methods appear weak here because paired-label evaluation does not match the information they use.
Where Pith is reading between the lines
- Real-time monitoring of the identified mid-layer could allow generation to be halted or corrected before output.
- Because the signal is linear, targeted activation editing at those layers might increase overall truthfulness.
- The same extraction method could be tested on other model behaviors such as confidence or refusal.
- If the probe generalizes across domains, it would reduce reliance on expensive sampling or external verifiers.
Load-bearing premise
The benchmark labels correctly mark whether each model response matches an internal truthfulness representation rather than reflecting prompt difficulty or annotation artifacts.
What would settle it
Retraining the probe on the same activations but with hallucination labels randomly shuffled or replaced by an independent external fact-check set yields AUROC near 0.5.
Figures










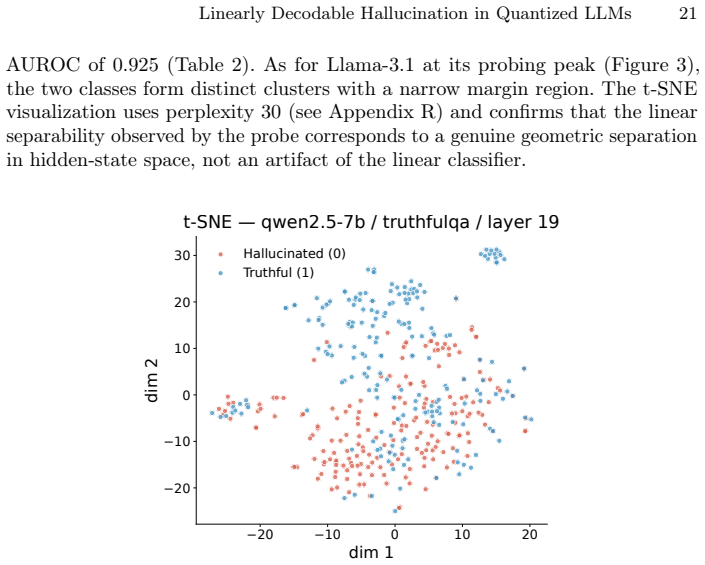




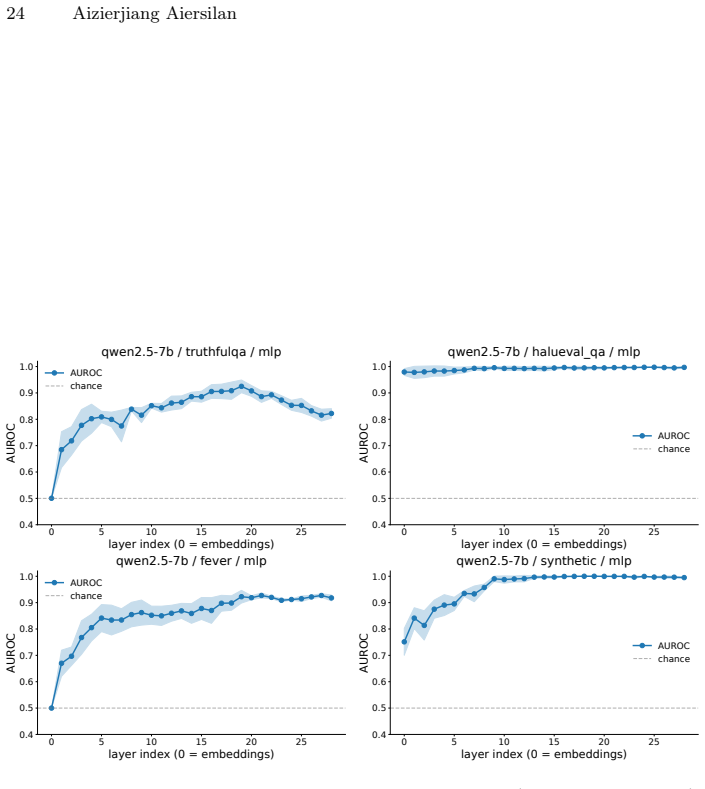

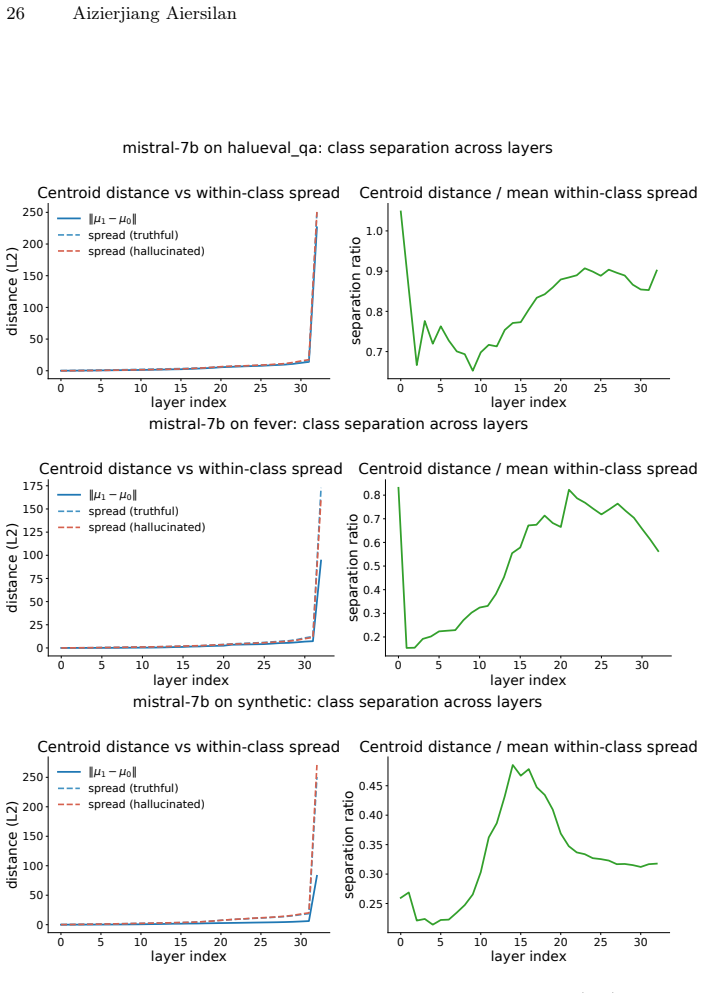







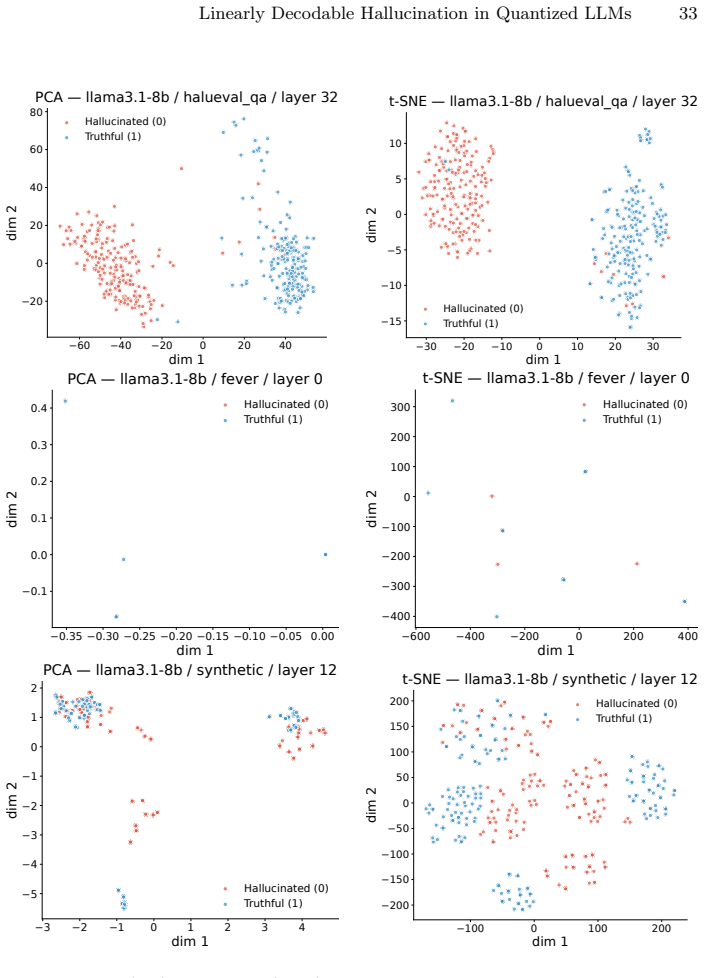




read the original abstract
We investigate whether open-source LLMs encode a linearly separable truthfulness signal in their hidden states, and at which network depth this signal is strongest. Across three $7$B--$8$B instruction-tuned models (Llama-3.1-8B, Mistral-7B, Qwen2.5-7B) loaded in $4$-bit NF4 quantization, we extract per-layer hidden states on four hallucination benchmarks (TruthfulQA, HaluEval-QA, FEVER, and a controlled synthetic set) and compare four detection approaches: linear and MLP probes, INSIDE EigenScore, self-consistency, and attention entropy. A linear probe on a single mid-network layer achieves $0.904$--$1.000$ AUROC on held-out splits, while sampling-based detectors do not exceed $0.541$ AUROC under the same protocol. The truthfulness signal is approximately linear: MLP probes rarely surpass linear probes by more than $0.01$ AUROC. Peak probing layers fall in a consistent band across model families on natural-language benchmarks -- blocks~$13$--$18$ of~$32$ for Llama and Mistral, and blocks~$19$--$25$ of~$28$ for Qwen. First-block attention entropy provides a complementary signal in knowledge-grounded settings ($0.866$--$0.941$ AUROC on HaluEval-QA) at no additional inference cost. The low discriminability of sampling methods under this protocol reflects a structural mismatch between paired-label evaluation and the information these methods access, rather than an inherent limitation of those methods. Code and data are released for full reproducibility on a single $8$\,GB GPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in 4-bit quantized 7-8B instruction-tuned LLMs (Llama-3.1-8B, Mistral-7B, Qwen2.5-7B), a linear probe trained on hidden states from a single mid-network layer achieves 0.904-1.000 AUROC for hallucination detection on held-out splits of TruthfulQA, HaluEval-QA, FEVER, and a synthetic benchmark, substantially outperforming sampling-based detectors (max 0.541 AUROC). It further claims the truthfulness signal is approximately linear (MLP probes add at most 0.01 AUROC), that peak layers are consistent across model families (blocks 13-18/32 for Llama/Mistral; 19-25/28 for Qwen), and that first-block attention entropy provides a complementary low-cost signal on knowledge-grounded tasks.
Significance. If the central empirical result holds after addressing label validity, the work would demonstrate that hallucination-related information is linearly decodable from mid-layer activations in quantized models, offering a computationally cheap alternative to sampling-based detection. The release of code and data for single-GPU reproducibility is a clear strength that enables direct verification and extension.
major comments (2)
- [Evaluation on natural-language benchmarks (TruthfulQA, HaluEval-QA, FEVER)] The interpretation that high AUROC demonstrates a 'linearly decodable truthfulness signal' inside the model rests on the untested assumption that external benchmark labels (human judgments on TruthfulQA, fact-checker labels on FEVER, etc.) align with whatever the quantized model has internally represented. No analysis is provided showing that the probe is not instead capturing surface correlates such as answer length, lexical overlap, or prompt difficulty. This is load-bearing for the headline claim because the natural-language benchmarks drive the cross-model consistency result; the synthetic set alone is insufficient to support it.
- [Probe training and evaluation protocol] The abstract and reported results supply no information on the linear probe training procedure, exact train/test splits, regularization, optimization hyperparameters, or any control for post-hoc layer selection. Without these details the reported 0.904-1.000 AUROC values cannot be independently verified or reproduced from the released code alone.
minor comments (1)
- [Discussion of sampling-based detectors] The claim that 'the low discriminability of sampling methods ... reflects a structural mismatch' is asserted but would benefit from a short explicit comparison of what information each method has access to under the paired-label protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important aspects of interpretability and reproducibility. We address each below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation on natural-language benchmarks (TruthfulQA, HaluEval-QA, FEVER)] The interpretation that high AUROC demonstrates a 'linearly decodable truthfulness signal' inside the model rests on the untested assumption that external benchmark labels (human judgments on TruthfulQA, fact-checker labels on FEVER, etc.) align with whatever the quantized model has internally represented. No analysis is provided showing that the probe is not instead capturing surface correlates such as answer length, lexical overlap, or prompt difficulty. This is load-bearing for the headline claim because the natural-language benchmarks drive the cross-model consistency result; the synthetic set alone is insufficient to support it.
Authors: We agree that additional evidence is needed to rule out surface correlates as the primary driver of probe performance on the natural-language benchmarks. The synthetic benchmark provides controlled labels, but does not fully address this for the cross-model consistency results. In revision we will add an ablation that regresses out answer length, lexical overlap (Jaccard and TF-IDF), and prompt difficulty proxies (e.g., perplexity of the prompt) before training the probes, and report the resulting AUROC drop. If the drop is small, this will support the internal-signal interpretation; if large, we will qualify the claims accordingly. revision: yes
-
Referee: [Probe training and evaluation protocol] The abstract and reported results supply no information on the linear probe training procedure, exact train/test splits, regularization, optimization hyperparameters, or any control for post-hoc layer selection. Without these details the reported 0.904-1.000 AUROC values cannot be independently verified or reproduced from the released code alone.
Authors: The full manuscript contains a methods subsection on probe training (logistic regression via scikit-learn with L2 regularization, 5-fold cross-validation on the training portion, 80/20 stratified splits, and layer selection via validation AUROC), and the released repository includes the exact training scripts. However, we acknowledge that these details are insufficiently prominent. We will expand the methods section with all hyperparameters, split statistics, and the precise layer-selection protocol so that the paper is self-contained and the numbers are directly reproducible from the text alone. revision: yes
Circularity Check
No circularity: empirical AUROC results on external benchmarks with held-out evaluation
full rationale
The paper performs standard supervised probing: hidden states are extracted from fixed external benchmarks (TruthfulQA, HaluEval-QA, FEVER, synthetic set), linear classifiers are trained on train splits, and AUROC is measured on held-out test splits. No equations, predictions, or first-principles claims reduce the reported performance to quantities defined by the authors' own fitted parameters or self-citations. The protocol is externally falsifiable via the released code and data; the central claim (linear decodability) is a measured empirical outcome rather than a definitional or self-referential identity.
Axiom & Free-Parameter Ledger
free parameters (1)
- Selected probe layer
axioms (1)
- domain assumption Hidden states at a given layer contain a linearly separable truthfulness signal that aligns with benchmark labels.
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Alain, G., Bengio, Y.: Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
In: Findings of the Association for Computational Linguistics: EMNLP 2023
Azaria, A., Mitchell, T.: The internal state of an llm knows when it’s lying. In: Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 967–976 (2023)
2023
-
[3]
Discovering Latent Knowledge in Language Models Without Supervision
Burns, C., Ye, H., Klein, D., Steinhardt, J.: Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
arXiv preprint arXiv:2402.03744 (2024)
Chen, C., Liu, K., Chen, Z., Gu, Y., Wu, Y., Tao, M., Fu, Z., Ye, J.: Inside: Llms’ internal states retain the power of hallucination detection. arXiv preprint arXiv:2402.03744 (2024)
-
[5]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Cohen, R., Hamri, M., Geva, M., Globerson, A.: Lm vs lm: Detecting factual errors via cross examination. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 12621–12640 (2023)
2023
-
[6]
int8 (): 8-bit matrix multiplication for transformers at scale
Dettmers, T., Lewis, M., Belkada, Y., Zettlemoyer, L.: Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in neural information processing systems35, 30318–30332 (2022)
2022
-
[7]
Advances in neural information processing systems36, 10088– 10115 (2023)
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems36, 10088– 10115 (2023)
2023
-
[8]
Nature630(8017), 625–630 (2024)
Farquhar, S., Kossen, J., Kuhn, L., Gal, Y.: Detecting hallucinations in large language models using semantic entropy. Nature630(8017), 625–630 (2024)
2024
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 12 Aizierjiang Aiersilan
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
ACM Transactions on Information Systems43(2), 1–55 (2025)
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al.: A survey on hallucination in large language models: Princi- ples, taxonomy, challenges, and open questions. ACM Transactions on Information Systems43(2), 1–55 (2025)
2025
-
[11]
ACM computing surveys55(12), 1–38 (2023)
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A., Fung, P.: Survey of hallucination in natural language generation. ACM computing surveys55(12), 1–38 (2023)
2023
-
[12]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.A., Stock, P., Le Scao, T., Lavril, T., Wang, T., Lacroix, T., El Sayed, W.: Mistral 7B. arXiv preprint arXiv:2310.06825 (2023),https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Kuhn, L., Gal, Y., Farquhar, S.: Semantic uncertainty: Linguistic invariances for un- certaintyestimation in natural languagegeneration. arXiv preprintarXiv:2302.09664 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Li,J.,Cheng,X.,Zhao,X.,Nie,J.Y.,Wen,J.R.:Halueval:Alarge-scalehallucination evaluation benchmark for large language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 6449–6464 (2023)
2023
-
[15]
Advances in Neural Information Processing Systems36, 41451–41530 (2023)
Li, K., Patel, O., Viégas, F., Pfister, H., Wattenberg, M.: Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems36, 41451–41530 (2023)
2023
-
[16]
In: Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers)
Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers). pp. 3214–3252 (2022)
2022
-
[17]
Journal of machine learning research9(11) (2008)
Van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research9(11) (2008)
2008
-
[18]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Manakul, P., Liusie, A., Gales, M.: Selfcheckgpt: Zero-resource black-box hallucina- tion detection for generative large language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 9004–9017 (2023)
2023
-
[19]
Advances in neural information processing systems35, 27730–27744 (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing systems35, 27730–27744 (2022)
2022
-
[20]
Qwen Team: Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2024), https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP)
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). pp. 3982–3992 (2019)
2019
-
[22]
In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
Thorne, J., Vlachos, A., Christodoulopoulos, C., Mittal, A.: Fever: a large-scale dataset for fact extraction and verification. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). pp. 809–819 (2018)
2018
-
[23]
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022) Linearly Decodable Hallucination in Quantized LLMs 13 Appendix Roadmap The eighteen appendices that follow provide exhaustive supporting evidence for every ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.