Visual Graph Scaffolds for Structural Reasoning in Large Language Models
Pith reviewed 2026-06-28 14:52 UTC · model grok-4.3
The pith
Visual graphs act as internal scaffolds that organize multi-hop reasoning in LLMs more effectively than text versions of the same structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
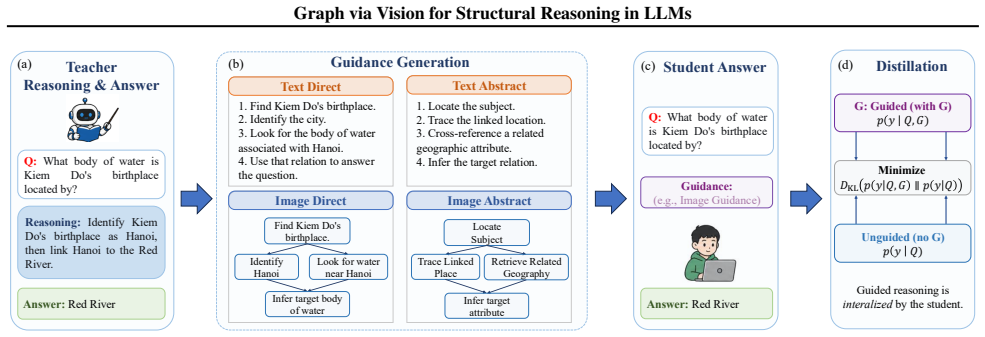
Graphs should be studied not only as external knowledge structures for LLMs, but also as visual scaffolds for organizing reasoning. On multi-hop QA tasks, teacher-provided reasoning traces rewritten as graph mind maps guide student models; flattened text versions lose most of their value once direct answer clues are removed, while visual graph guidance stays effective without those clues and the benefit persists after supervised fine-tuning and KL-based distillation.
What carries the argument
Visual graph mind maps derived from teacher reasoning traces, supplied as reasoning scaffolds rather than external facts.
If this is right
- Visual graph guidance improves both reasoning efficiency and answer quality on multi-hop questions when no direct answer clues are present.
- The performance gap between visual and text graph representations remains after supervised fine-tuning.
- The same gap remains after KL-based distillation of the student model.
- Graphs function as organizers of branching and converging thoughts inside the model, beyond simply supplying external information.
Where Pith is reading between the lines
- If visual scaffolds prove robust, training pipelines could incorporate rendered graphs at scale to reduce reliance on explicit answer supervision.
- The modality difference suggests testing whether other non-text structures, such as diagrams or timelines, produce similar gains on tasks that require tracking multiple dependencies.
- Extending the approach to open-ended generation tasks could reveal whether visual organization helps models maintain coherence across longer outputs.
Load-bearing premise
The student model can meaningfully interpret and use the rendered visual graphs as reasoning scaffolds.
What would settle it
A controlled test on held-out multi-hop questions where the same models receive either visual graphs or text-flattened graphs with all answer clues removed, and visual versions show no measurable gain in accuracy or step efficiency.
Figures
read the original abstract
Graphs have been used to enhance large language models (LLMs) for structured reasoning, mostly as external knowledge sources are provided to models at test time. In this paper, we take a different view: the value of graphs for LLMs lie not only in supplying information, but also in organizing reasoning. Inspired by how humans use graph-structured mind maps to organize branching and converging thoughts, we ask whether graphs can serve as an internal form of reasoning assistance. We study this question on multi-hop question answering tasks, where teacher-provided reasoning traces are rewritten as graph mind maps and used to guide a student model. Our experiments reveal a clear modality gap. When graph structures are flattened into text, their benefits become limited once direct answer hints are removed. Under this abstract guidance setting, both reasoning efficiency and answer quality degrade substantially. In contrast, visual graph guidance remains effective without direct answer clues, and its advantage persists after supervised fine-tuning and KL-based distillation. The above findings support the claim that graphs should be studied not only as external knowledge structures for LLMs, but also as visual scaffolds for organizing reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates using graph mind maps as internal reasoning scaffolds for LLMs on multi-hop QA tasks. Teacher-provided reasoning traces are rewritten as graphs and provided to a student model either as flattened text or as visual renderings. The central claim is that visual graph guidance remains effective even after removing direct answer clues, unlike text versions, and that this advantage persists after supervised fine-tuning and KL distillation, supporting graphs as visual scaffolds for organizing reasoning rather than solely as external knowledge sources.
Significance. If the empirical modality gap holds under controlled conditions, the work would open a new direction for studying graphs as visual reasoning aids inside LLMs, distinct from knowledge-graph retrieval. The persistence after SFT and distillation would be a notable strength, indicating the benefit is not merely from surface-level prompting. However, the absence of any quantitative results, model details, or rendering procedures in the provided text leaves the claim currently unverifiable.
major comments (2)
- Abstract: the central claim of a 'clear modality gap' and persistent advantage after SFT/distillation rests on an empirical comparison, yet the text supplies no quantitative metrics, dataset names, model sizes, statistical tests, or even the student architecture. This omission makes the reported advantage impossible to assess or reproduce.
- Abstract (and implied experimental section): the interpretation that visual graphs function as 'structural reasoning scaffolds' rather than richer text carriers requires that the student model can extract topology from the image and that the rendering procedure does not leak answer paths. Neither the multimodal architecture nor the layout algorithm, node styling, or label placement is specified, rendering the scaffold hypothesis untestable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on verifiability. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the central claim of a 'clear modality gap' and persistent advantage after SFT/distillation rests on an empirical comparison, yet the text supplies no quantitative metrics, dataset names, model sizes, statistical tests, or even the student architecture. This omission makes the reported advantage impossible to assess or reproduce.
Authors: We agree the abstract is currently too high-level and lacks the requested specifics, making independent assessment difficult. The revised version will include key quantitative metrics from the experiments, dataset names, model sizes, statistical tests, and the student architecture to support the modality gap claim. revision: yes
-
Referee: Abstract (and implied experimental section): the interpretation that visual graphs function as 'structural reasoning scaffolds' rather than richer text carriers requires that the student model can extract topology from the image and that the rendering procedure does not leak answer paths. Neither the multimodal architecture nor the layout algorithm, node styling, or label placement is specified, rendering the scaffold hypothesis untestable.
Authors: We agree these details are required to substantiate the scaffold interpretation over a richer-text explanation. The revised manuscript will specify the multimodal architecture, graph rendering procedure (layout algorithm, node styling, label placement), and controls ensuring no direct answer-path leakage while permitting topology extraction from images. revision: yes
Circularity Check
No circularity detected; empirical comparison with no derivation chain or self-referential steps
full rationale
The paper advances an empirical claim based on experiments comparing flattened text graphs vs. visual graph guidance on multi-hop QA, with observations about modality gaps persisting after fine-tuning and distillation. The provided abstract and context contain no equations, no fitted parameters, no predictions derived from inputs, and no citations (self or otherwise) used to justify uniqueness, ansatz, or load-bearing premises. The derivation chain is absent; results are presented as experimental outcomes rather than reductions by construction. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
doi: 10.1609/AAAI.V38I16.29720. URL https: //doi.org/10.1609/aaai.v38i16.29720. DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models.CoRR, abs/2512.02556, 2025. doi: 10.48550/ARXIV .2512.02556. URL https:// doi.org/10.48550/arXiv.2512.02556. Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., and Larson, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai.v38i16.29720 2025
-
[2]
URL https://doi.org/10.24963/ijcai. 2020/501. Ma, S., Xu, C., Jiang, X., Li, M., Qu, H., Yang, C., Mao, J., and Guo, J. Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation. InThe Thirteenth Inter- national Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. ...
-
[3]
Mavromatis, C
URL https://openreview.net/forum? id=oFBu7qaZpS. Mavromatis, C. and Karypis, G. GNN-RAG: graph neural retrieval for efficient large language model reasoning on knowledge graphs. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Findings of the Associa- tion for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, ...
2025
-
[4]
URL https://aclanthology.org/2025. findings-acl.856/. Nezhurina, M., Cipolina-Kun, L., Cherti, M., and Jitsev, J. Alice in wonderland: Simple tasks showing complete reasoning breakdown in state-of-the-art large language models.CoRR, abs/2406.02061, 2024. doi: 10.48550/ ARXIV .2406.02061. URL https://doi.org/10. 48550/arXiv.2406.02061. 5 Graph via Vision f...
-
[5]
URL https://doi.org/10.18653/v1/ 2023.findings-emnlp.378. Qwen Team. Qwen3-vl technical report.CoRR, abs/2511.21631, 2025a. doi: 10.48550/ARXIV . 2511.21631. URLhttps://doi.org/10.48550/ arXiv.2511.21631. Qwen Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025b. doi: 10.48550/ARXIV . 2505.09388. URLhttps://doi.org/10.48550/ arXiv.2505.09388. Sinha, K...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/ 2023
-
[6]
Are they the same entity or concept with different names?
-
[7]
Are they semantically equivalent answers to the question?
-
[8]
Judgment: CORRECT
Is your answer a valid response even if phrased differently? Response format: - Briefly explain why your answer is or is not correct - End with exactly "Judgment: CORRECT" or "Judgment: INCORRECT" A.2.2. GUIDED RE-EVALUATION PROMPTS The re-evaluation stage uses chain-of-thought prompting for all guidance conditions. The only difference across conditions i...
-
[11]
8,8", dpi=
Content guidelines: - Allowed: specific hints, intermediate conclusions, key facts, reasoning steps - Forbidden: the final answer itself 10 Graph via Vision for Structural Reasoning in LLMs Generate only Graphviz DOT code: digraph ReasoningProcess { graph [size="8,8", dpi="150", rankdir=TB]; node [shape=box, style=rounded]; } Teacher image prompt: abstrac...
-
[12]
Structure: - Use < 15 nodes - Create a true graph with branches and convergence (not a linear chain) - Use top-to-bottom layout (rankdir=TB)
-
[14]
8,8", dpi=
Content guidelines: - Allowed: general reasoning strategies, meta-questions, logical operations - Forbidden: specific hints, intermediate conclusions, key facts, the final answer Generate only Graphviz DOT code: digraph ReasoningProcess { graph [size="8,8", dpi="150", rankdir=TB]; node [shape=box, style=rounded]; } Teacher text prompt: direct You are an e...
-
[16]
Teacher text prompt: abstract You are an expert teacher creating reasoning guidance for students
Content guidelines: 11 Graph via Vision for Structural Reasoning in LLMs - Allowed: specific hints, intermediate conclusions, key facts, reasoning steps - Forbidden: the final answer itself Generate text guidance. Teacher text prompt: abstract You are an expert teacher creating reasoning guidance for students. Based on your reasoning process above, create...
-
[17]
Structure: - Use < 15 steps - Create a reasoning flow with branches and convergence (not a linear chain)
-
[18]
Content guidelines: - Allowed: general reasoning strategies, meta-questions, logical operations - Forbidden: specific hints, intermediate conclusions, key facts, the final answer Generate text guidance. A.2.4. GRAPH-TO-TEXT CONTROL The graph-to-text control is produced by converting the generated DOT graph code into linear text with a separate prompt. Thi...
-
[19]
Clearly express relationships with ordered markers
-
[20]
Express branching explicitly
-
[21]
Express convergence explicitly
-
[22]
Do not introduce new content beyond the nodes
-
[23]
Input DOT code: <graph_code> Output a text description of the reasoning process
Keep the text concise but complete. Input DOT code: <graph_code> Output a text description of the reasoning process. 12 Graph via Vision for Structural Reasoning in LLMs A.2.5. ABLATION PROMPTS The ablation study keeps the same multi-turn teacher conversation and changes only the Round-2 graph-generation prompt. The cleaner main-text variants are the stru...
-
[24]
Structure: - Use < 15 nodes - Create a strictly linear chain (each node connects to exactly one next node) - No branching, no parallel paths, no merging - Use top-to-bottom layout (rankdir=TB)
-
[26]
Content: - Direct version: specific hints and key facts allowed - Abstract version: only general reasoning strategies allowed Ablation prompt: 5 nodes Requirements:
-
[27]
Structure: - Use exactly 5 nodes or fewer (strict limit; do not exceed) - Create a true graph with branches and convergence (not a linear chain) - Use top-to-bottom layout (rankdir=TB)
-
[29]
Content: - Direct version: specific hints and key facts allowed - Abstract version: only general reasoning strategies allowed Ablation prompt: 10 nodes Requirements:
-
[30]
Structure: - Use exactly 10 nodes or fewer (strict limit; do not exceed) - Create a true graph with branches and convergence (not a linear chain) - Use top-to-bottom layout (rankdir=TB)
-
[32]
Content: - Direct version: specific hints and key facts allowed - Abstract version: only general reasoning strategies allowed Ablation prompt: 10 nodes + chain Requirements:
-
[33]
Structure: 13 Graph via Vision for Structural Reasoning in LLMs - Use exactly 10 nodes or fewer (strict limit; do not exceed) - Create a strictly linear chain (each node connects to exactly one next node) - No branching, no parallel paths, no merging - Use top-to-bottom layout (rankdir=TB)
-
[34]
Node format: - Each node label < 10 words
-
[35]
Content: - Direct version: specific hints and key facts allowed - Abstract version: only general reasoning strategies allowed 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.